骚话Python爬虫入门,教你刷网课丶刷文章阅读量丶刷刷刷
Posted sn8888
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了骚话Python爬虫入门,教你刷网课丶刷文章阅读量丶刷刷刷相关的知识,希望对你有一定的参考价值。
走过路过不要错过,学不会没关系,长点见识也是可以的啦。
简介
博主于17年开始自学的python, 期间做过各个领域的python开发,包括爬虫, web, 硬件, 桌面应用, AI, 数据分析。
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!??¤
QQ群:623406465
可能有人会问python能做硬件开发?可自行搜索pyboard丶树莓派丶MicroPython, 描述python最有精髓的一句话: python 除了不能生孩子, 啥都能干。
![]() ?
?
通过该篇文章,读者可以发现爬虫入门并不难,还可以知道那些大学生网络刷视频课程的实现原理,以及抢票工具的实现原理,并且可以自己动手编写一个简单爬虫。当然入门容易, 出来未并容易。
![]() ?
?
其实很多东西看似难,其实很容易,你觉得难的原因仅仅是因为你不知道它的原理, 奉劝读者学习的过程中多了解一下实现原理, 这也是我切身体会。
![]() ?
?
本质
- 爬虫是一种获取网络信息的脚本,方便帮助人们快速的丶大量的从网络上的获取一些信息。
- 简单地说,比如你在一个网站上看到很多坏坏的图,你好喜欢,想下载下来,但是一个个点太费劲了,如果你是个妹子,或许能喊来一群甜 dog帮你。

 ?
? - 但是像博主这种没人疼, 没人爱的单身dog, 只能靠自己的双手了,三下五除二, 撸了一段代码搞定,代码如下:
- 代码呢? 年轻人做事不能这么着急,慢慢来嘛, 讨厌。心急吃不了热豆腐。

![]() ?
?
- 紧接着,博主继续阐述爬虫的本质。上文说到爬虫是自动化获取网络信息的脚本。, 那么脚本操作的本质又是啥? 要知道脚本的操作本质,那么得知道你操作浏览器时,人家浏览器是怎么操作的,例如:
-
当你点击一个页面的时候,客户端浏览器向指定的服务器发送一个
GET请求,服务端接受到该请求之后便会返回响应内容,客户端浏览器接受到响应内容便会进行解析渲染,此时你就看到了页面上的内容。这期间还涉及客户端是如何找到服务端的(DNS协议), 客户端跟服务端是如何通信的(TCP协议), 这两个协议这里就不作解析了,再说就超纲了,博主是一个正直的男人(单身,划重点),违背伦理道德的事我不干,可以自行和百度老师好好深入交流。 -
当你想点赞我的文章时候,此时万恶的浏览器告诉你(其实罪魁祸首是服务器端代码),需要登录,你拒绝登录的话,那么我就损失了一个赞,所以你还是行行好,登录一下点赞吧, 你是个好人。
 ?
?
在登录的时候,发现你没有注册,不管注册还是登录,你需要在浏览器输入账号密码(扫码登录), 当你操作完成之后点登录,客户端浏览器会向服务端发送一个POST请求进行操作,服务端会进行一系列的操作然后响应给客户端,客户端浏览器会弹出提示告诉你操作状态(登录成功, 或者失败)。GET请求和POST请求有什么不同? GET请求的内容实体会带在网址的后面,POST请求的内容实体会带在请求体里面。还有XXX, 不告诉你(百度)。 -
了解了请求的GET和POST,对于本篇文章已经够用了(还有PUT,DELETE,OPTION), 如果想深入了解的可以百度搜索:
详解HTTP请求, 写太深入就没人看了。 ?
?
-
- 网络刷课,抢票软件,刷文章访问量等软件的实现原理也是基于网络请求的操作,只不过很多站点会增加一些反爬虫机制,如ip限制,登录加密,操作内容体加密,当然这些也是可以搞定的。
Python
也不知道我的读者有没有学过python, 甚至可能没有学过编程,但是没关系,很简单的。
接下来,带你如何快速入门python:
由于一篇文章的篇幅有限, 请自行查找python入门教程, 如果觉得不够骚,可以私信我写。
本人就是网上闷骚男, 网下腼腆男。
![]() ?
?
实战
-
各位看官,现在又到了紧张的实战环节, 我狂铁贼六,又狂又头铁, 进可一打五,退可六分投。
 ?
? -
首先介绍两个Python的三方模块
requests,BeautifulSoup。 -
入门教程从简, 以一个斗图网的表情包套图页面为例,实现该页面下所有图片的下载, 点我查看网页。
-
先通过requests模块获取网页文本数据:
import requests # 导入模块 def get_html_text(url): # 获取html文本内容 """ 获取html文本 :param url: :return: """ return requests.get(url).text # 这里通过GET请求拿到返回的网页文本内容 if __name__ == ‘__main__‘: url = ‘http://www.bbsnet.com/xiongmaoren-18.html‘ html_text = get_html_text(url) print(html_text)
-
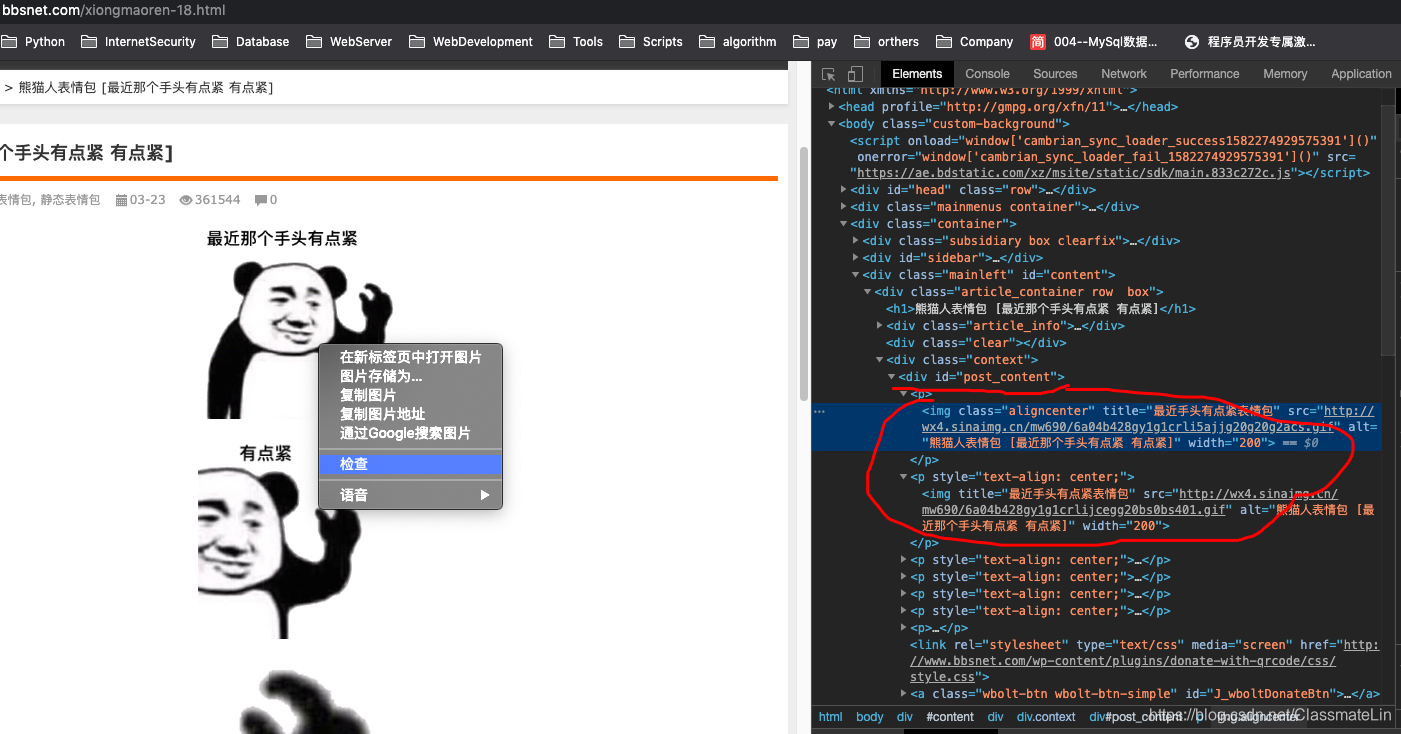
分析网页结构,鼠标对准图片,右键点检查元素, 如图:
 ?
?
在右图中可以看到,所有的图片均包含在id=post_content的div标签里面, 然后其下面是一些p标签,img中src有图片的链接,点进去可以直接看到一张图片。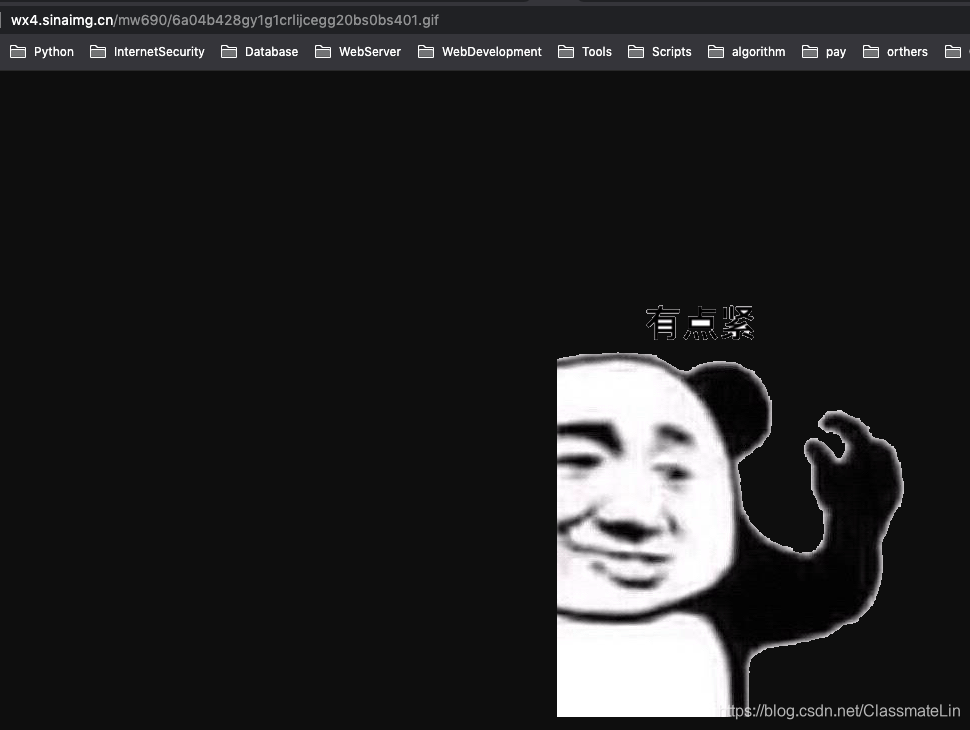 ?
?
现在要做的事情,就是提取这些图片链接,再通过GET请求和文件操作进行图片的保存。 -
用BeautifouSoup查找这些图片的链接地址, 定义一个函数来完成这件事情:
def get_images_urls(html_text): """ 获取图片链接 :param html_text: :return: """ urls = [] # 保存提取的url列表 soup = BeautifulSoup(html_text, ‘html.parser‘) # 创建一个soup对象,可以打印出来看看里面的内容 div_tag = soup.find(‘div‘, {‘id‘: ‘post_content‘}) # 查找id=post_content的标签 img_tag_list = div_tag.find_all_next(‘img‘) # 查找div下面的所有img标签 for img_tag in img_tag_list[:-4]: # 观察找到结果发现从倒数第四个开始并不是表情包,所以只迭代到倒数第四个 url = img_tag.attrs[‘src‘] # 提取img标题的src元素的值 urls.append(url) return urls
-
然后需要定义一段代码,来完成图片的保存, 如下:
def save_images(dir, urls): """ 保存图片 :param urls: :return: """ if not os.path.exists(dir): # 使用os模块来判断文件夹是否存在,不存在则创建 os.makedirs(dir) count = 1 for url in urls: print(‘正在下载第{}张图片...‘.format(str(count))) ext = url.split(‘.‘)[-1] # 拿到图片的扩展名 filename = dir + ‘/‘ + str(count) + ‘.‘ + ext # 拼接图片的存储路径 content = requests.get(url).content # 通过GET请求获取图片的二进制内容,注意拿网页源码时候是text with open(filename, ‘wb‘) as f: # 已写二进制的形式打开文件 f.write(content) # 将图片内容写入 count += 1 # count 用于图片命名和计数,递增1
-
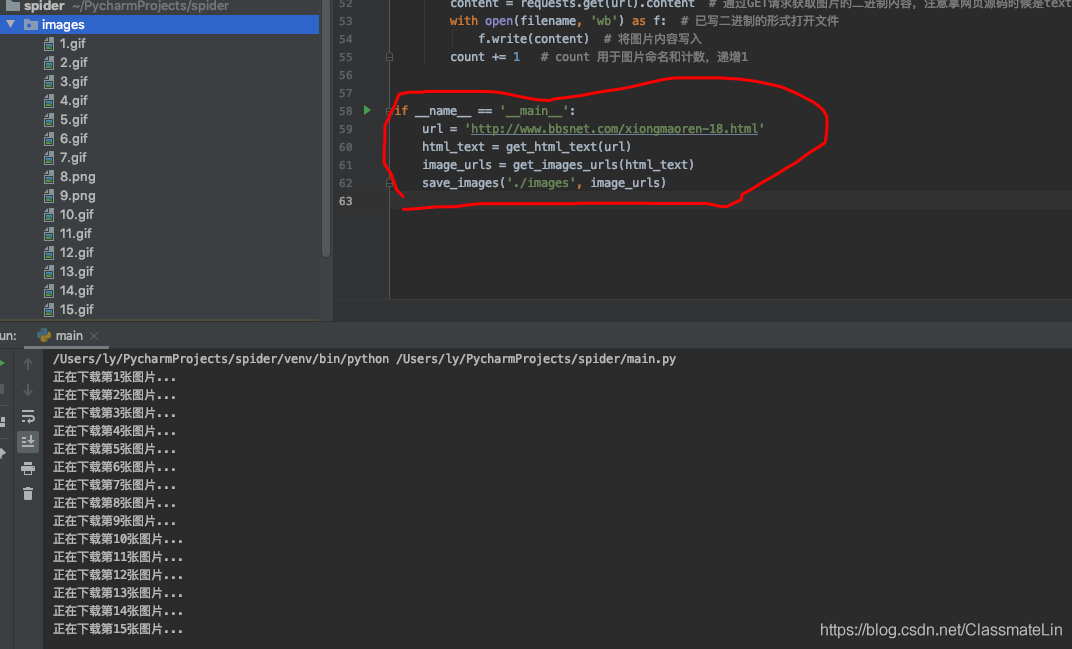
代码运行结果:
 ?
? -
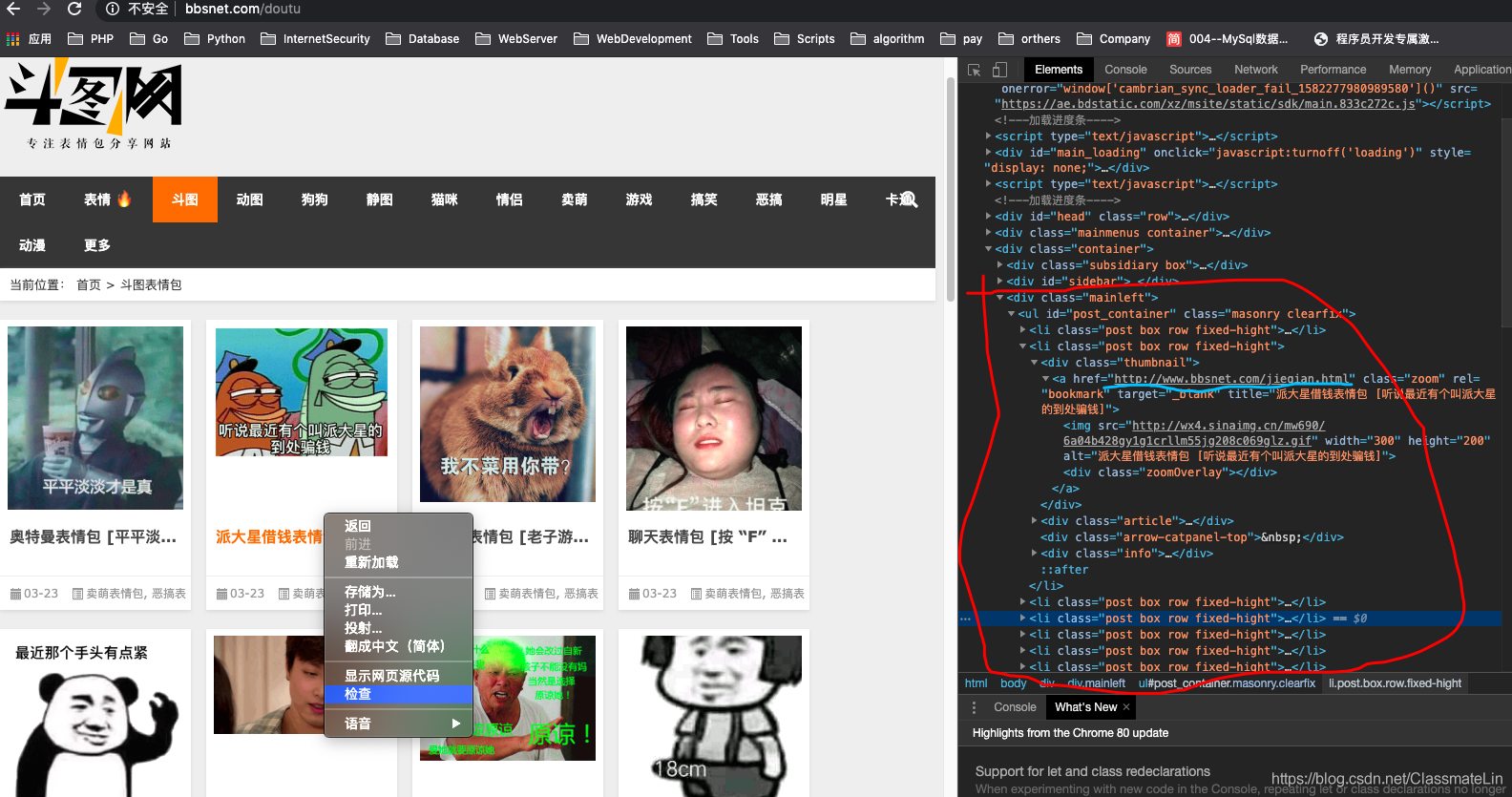
这时候就会有杠精说: 这一页不就15个图片嘛,我点几下就完事了,写个代码时间还比较长时间。又或者有虚心向学者问: 怎样爬取整个网站的图片或者某一分类下所有的图片。那么已斗图表情包分类下的图片为例子, 参照之前讲述的步骤, 看下网页结构:
 ?
?
可以看到右侧我圈红的框内容包含了一些li标签,li标签对应的就算每一个封面图, 我们要找到的就是蓝钱画出来的url,对应之前代码的url, 只要我们把这些url都找出来,再调用我们之前的代码就可以下载所有的图片了, 当然这里还涉及分页, 分页的操作方法也是一样的,只要我们把下一页的链接找出来,再进行访问,直到找不到下一页为止。 -
贴上爬取单个页面的完整代码,爬取分类的读者自己琢磨怎么去实现。
# _*_coding:utf8_*_ # Project: spider # File: main.py # Author: ClassmateLin # Email: 406728295@qq.com # 有项目的可以滴滴我, Python/Java/PHP/Go均可。WX: ClassmateYue # Time: 2020/2/21 4:54 下午 # DESC: import requests import os from bs4 import BeautifulSoup def get_html_text(url): """ 获取html文本 :param url: :return: """ return requests.get(url).text def get_images_urls(html_text): """ 获取图片链接 :param html_text: :return: """ urls = [] # 保存提取的url列表 soup = BeautifulSoup(html_text, ‘html.parser‘) # 创建一个soup对象,可以打印出来看看里面的内容 div_tag = soup.find(‘div‘, {‘id‘: ‘post_content‘}) # 查找id=post_content的标签 img_tag_list = div_tag.find_all_next(‘img‘) # 查找div下面的所有img标签 for img_tag in img_tag_list[:-4]: # 观察找到结果发现从倒数第四个开始并不是表情包,所以只迭代到倒数第四个 url = img_tag.attrs[‘src‘] # 提取img标题的src元素的值 urls.append(url) return urls def save_images(dir, urls): """ 保存图片 :param urls: :return: """ if not os.path.exists(dir): # 使用os模块来判断文件夹是否存在,不存在则创建 os.makedirs(dir) count = 1 for url in urls: print(‘正在下载第{}张图片...‘.format(str(count))) ext = url.split(‘.‘)[-1] # 拿到图片的扩展名 filename = dir + ‘/‘ + str(count) + ‘.‘ + ext # 拼接图片的存储路径 content = requests.get(url).content # 通过GET请求获取图片的二进制内容,注意拿网页源码时候是text with open(filename, ‘wb‘) as f: # 已写二进制的形式打开文件 f.write(content) # 将图片内容写入 count += 1 # count 用于图片命名和计数,递增1 if __name__ == ‘__main__‘: url = ‘http://www.bbsnet.com/xiongmaoren-18.html‘ html_text = get_html_text(url) image_urls = get_images_urls(html_text) save_images(‘./images‘, image_urls)
-
以上是关于骚话Python爬虫入门,教你刷网课丶刷文章阅读量丶刷刷刷的主要内容,如果未能解决你的问题,请参考以下文章
完全机器模拟浏览器操作自动刷网课!不怕被封!!-----python基于selenium实现超星学习通刷视频网课