python学习(33)----Python 中 -m 的典型用法原理解析与发展演变(转)
Posted 咫片炫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python学习(33)----Python 中 -m 的典型用法原理解析与发展演变(转)相关的知识,希望对你有一定的参考价值。
转自:
https://zhuanlan.zhihu.com/p/91120727
-m 选项的两种原理解析
看了前面的几种典型用法,你是否开始好奇:“-m”是怎么运作的?它是怎么实现的?
对于“python -m name”,一句话解释:Python 会检索sys.path ,查找名字为“name”的模块或者包(含命名空间包),并将其内容当成“__main__”模块来执行。
1、对于普通模块
以“.py”为后缀的文件就是一个模块,在“-m”之后使用时,只需要使用模块名,不需要写出后缀,但前提是该模块名是有效的,且不能是用 C 语言写成的模块。
在“-m”之后,如果是一个无效的模块名,则会报错“No module named xxx”。
如果是一个带后缀的模块,则首先会导入该模块,然后可能报错:Error while finding module specification for ‘xxx.py‘ (AttributeError: module ‘xxx‘ has no attribute ‘__path__‘。
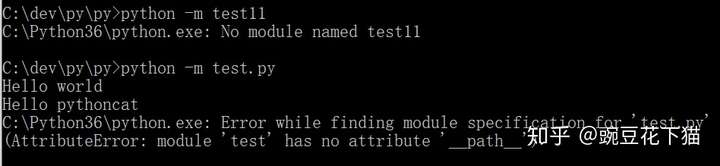
对于一个普通模块,有时候这两种写法表面看起来是等效的:
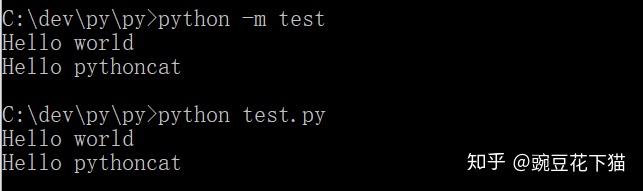
两种写法都会把定位到的模块脚本当成主程序入口来执行,即在执行时,该脚本的__name__ 都是”__main__“,跟 import 导入方式是不同的。
但它的前提是:在执行目录中存在着“test.py”,且只有唯一的“test”模块。对于本例,如果换一个目录执行的话,“python test.py”当然会报找不到文件的错误,然而,“python -m test”却不会报错,因为解释器在遍历sys.path 时可以找到同名的“test”模块,并且执行:
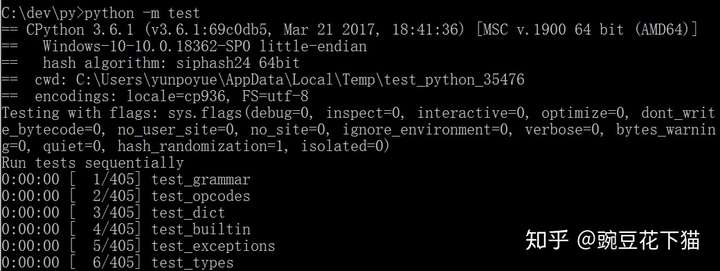
由此差异,我们其实可以总结出“-m”的用法:已知一个模块的名字,但不知道它的文件路径,那么使用“-m”就意味着交给解释器自行查找,若找到,则当成脚本执行。
以前文的“python -m http.server 8000”为例,我们也可以找到“server”模块的绝对路径,然后执行,尽管这样会变得很麻烦。

那么,“-m”方式与直接运行脚本相比,在实现上有什么不同呢?
- 直接运行脚本时,相当于给出了脚本的完整路径(不管是绝对路径还是相对路径),解释器根据文件系统的查找机制, 定位到该脚本,然后执行
- 使用“-m”方式时,解释器需要在不 import 的情况下,在所有模块命名空间 中查找,定位到脚本的路径,然后执行。为了实现这个过程,解释器会借助两个模块:
pkgutil和runpy,前者用来获取所有的模块列表,后者根据模块名来定位并执行脚本
2、对于包内模块
如果“-m”之后要执行的是一个包,那么解释器经过前面提到的查找过程,先定位到该包,然后会去执行它的“__main__”子模块,也就是说,在包目录下需要实现一个“__main__.py”文件。
换句话说,假设有个包的名称是“pname”,那么,“python -m pname”,其实就等效于“python -m pname.__main__”。
仍以前文创建 HTTP 服务为例,“http”是 Python 内置的一个包,它没有“__main__.py”文件,所以使用“-m”方式执行时,就会报错:No module named http.__main__; ‘http‘ is a package and cannot be directly executed。

作为对比,我们可以看看前文提到的 pip,它也是一个包,为什么“python -m pip”的方式可以使用呢?当然是因为它有“__main__.py”文件:
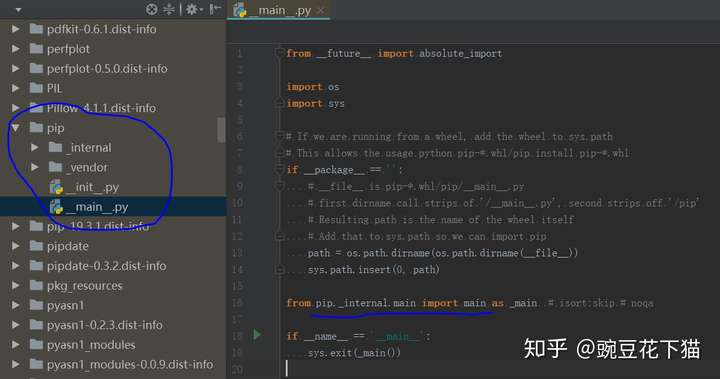
“python -m pip”实际上执行的就是这个“__main__.py”文件,它主要作为一个调用入口,调用了核心的"pip._internal.main"。
http 包因为没有一个统一的入口模块,所以采用了“python -m 包.模块”的方式,而 pip 包因为有统一的入口模块,所以加了一个“__main__.py”文件,最后只需要写“python -m 包”,简明直观。
以上是关于python学习(33)----Python 中 -m 的典型用法原理解析与发展演变(转)的主要内容,如果未能解决你的问题,请参考以下文章