python 爬虫 03-正则表达式
Posted 酸辣土豆皮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 爬虫 03-正则表达式相关的知识,希望对你有一定的参考价值。
1.正则表达式的简介
1.1 概念
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑
1.2 正则表达式的应用场景
- 表单验证(例如 : 手机号、邮箱、身份证.... )
- 爬虫
2. 正则表达式对Python的支持
2.1 普通字符
字母、数字、汉字、下划线、以及没有特殊定义的符号,都是"普通字符"。正则
表达式中的普通字符,在匹配的时候,只匹配与自身相同的一个字符。
例如:表达式c,在匹配字符串abcde时,匹配结果是:成功;匹配到的内容
是c;匹配到的位置开始于2,结束于3。(注:下标从0开始还是从1开始,因
当前编程语言的不同而可能不同)
match()函数
- match(pattern, string, flags=0)
- 第一个参数是正则表达式,如果匹配成功,则返回一个match对象,否则返回一个None
- 第二个参数表示要匹配的字符串
- 第三个参数是标致位用于控制正则表达式的匹配方式 如: 是否区分大小写,多行匹配等等
2.2 元字符
正则表达式中使⽤了很多元字符,⽤来表示⼀些特殊的含义或功能
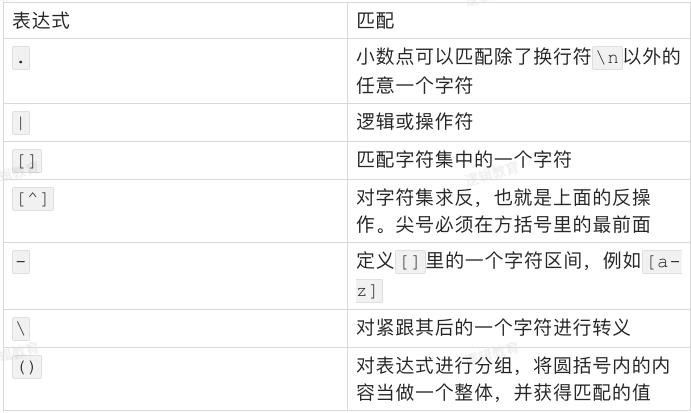
一些无法书写或者具有特殊功能的字符,采用在前面加斜杠""进行转义的方法。
例如下表所示
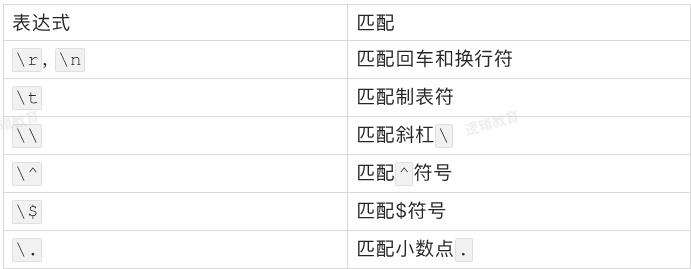
尚未列出的还有问号?、星号*和括号等其他的符号。所有正则表达式中具有特殊含义的字符在匹配自身的时候,都要使用斜杠进行转义。这些转义字符的匹配用法与普通字符类似,也是匹配与之相同的一个字符
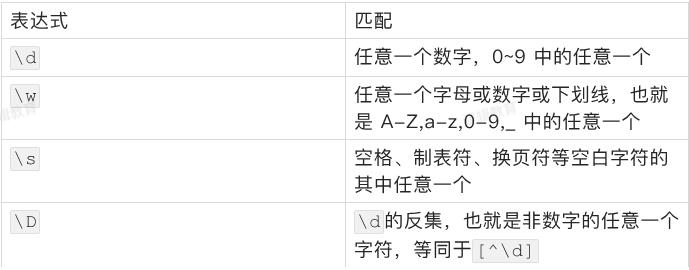
2.3 预定义匹配字符集
正则表达式中的一些表示方法,可以同时匹配某个预定义字符集中的任意一个字符。比如,表达式\\d可以匹配任意一个数字。虽然可以匹配其中任意字符,但是只能是一个,不是多个

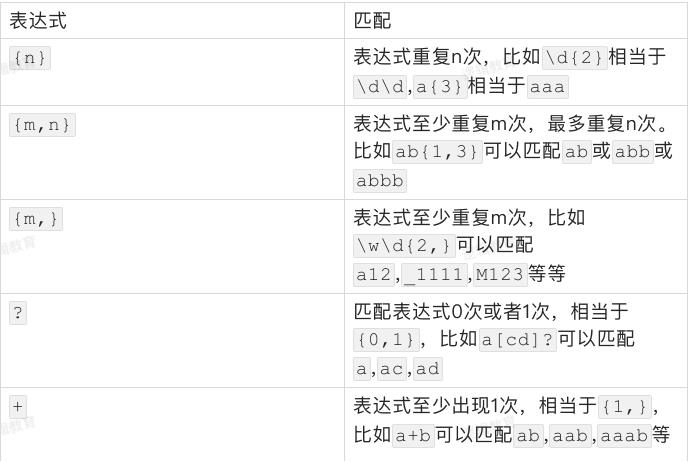
2.4 重复匹配
前面的表达式,无论是只能匹配一种字符的表达式,还是可以匹配多种字符其中任意一个的表达式,都只能匹配一次。但是有时候我们需要对某个字段进行重复匹配,例如手机号码13666666666,一般的新手可能会写成\\d\\d\\d\\d\\d\\d\\d\\d\\d\\d\\d(注意,这不是一个恰当的表达式),不但写着费劲,看着也累,还不⼀定准确恰当。
这种情况可以使用表达式再加上修饰匹配次数的特殊符号{},不但重复书写表达式就可以重复匹配。例如[abcd][abcd]可以写成[abcd]{2}

2.5 位置匹配和非贪婪匹配
位置匹配
有时候,我们对匹配出现的位置有要求,比如开头、结尾、单词之间等等
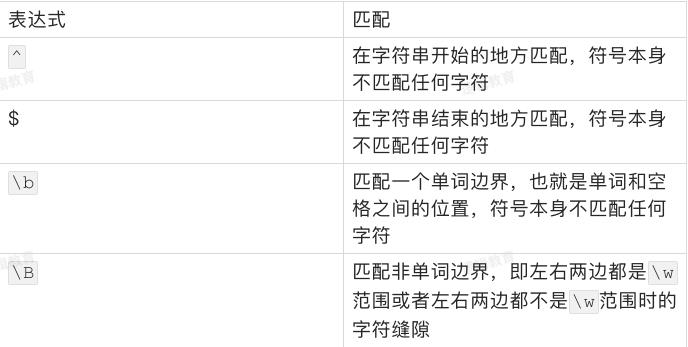
贪婪与非贪婪模式
在重复匹配时,正则表达式默认总是尽可能多的匹配,这被称为贪婪模式。例如,针对文本dxxxdxxxd,表达式(d)(\\w+)(d)中的\\w+将匹配第一个d和最后一个d之间的所有字符xxxdxxx。可见,\\w+在匹配的时候,总是尽可能多的匹配符合它规则的字符。同理,带有?、*和{m,n}的重复匹配表达式都是尽可能地多匹配
校验数字的相关表达式:
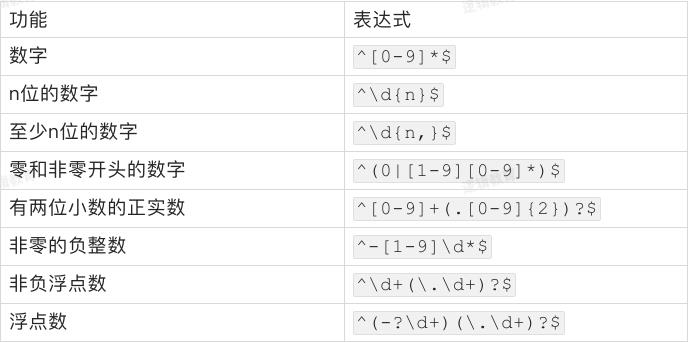
特殊场景的表达式:

总结所有的方法:

3. re模块常用方法

compile(pattern, flags=0)
这个⽅法是re模块的工厂法,⽤于将字符串形式的正则表达式编译为Pattern模式对象,可以实现更加效率的匹配。第二个参数flag是匹配模式 使用compile()完成一次转换后,再次使用该匹配模式的时候就不能进行转换了。经过compile()转换的正则表达式对象也能使用普通的re⽅法
flag匹配模式

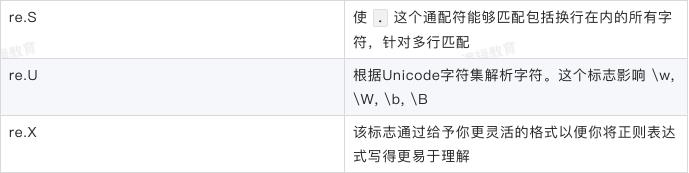
search(pattern, string, flags=0)
在文本内查找,返回第一个匹配到的字符串。它的返回值类型和使用方法与match()是一样的,唯一的区别就是查找的位置不用固定在文本的开头
findall(pattern, string, flags=0)
作为re模块的三大搜索函数之一,findall()和match()、search()的不同之处在于,前两者都是单值匹配,找到一个就忽略后面,直接返回不再查找了。而findall是全文查找,它的返回值是一个匹配到的字符串的列表。这个列表没有group()方法,没有start、end、span,更不是一个匹配对象,仅仅是个列表!如果一项都没有匹配到那么返回一个空列表
split(pattern, string, maxsplit=0, flags=0)
re模块的split()方法和字符串的split()方法很相似,都是利用特定的字符去分割字符串。但是re模块的split()可以使用正则表达式,因此更灵活,更强大
split有个参数maxsplit,用于指定分割的次数
sub(pattern, repl, string, count=0, flags=0)
sub()方法类似字符串的replace()方法,用指定的内容替换匹配到的字符,可以指定替换次数
4. 分组功能
Python的re模块有一个分组功能。所谓的分组就是去已经匹配到的内容再筛选出需要的内容,相当于二次过滤。实现分组靠圆括号(),而获取分组的内容靠的是group()、groups(),其实前面我们已经展示过。re模块里的积个重要方法在分组上,有不同的表现形式,需要区别对待
以上是关于python 爬虫 03-正则表达式的主要内容,如果未能解决你的问题,请参考以下文章