Python 爬虫数据解析--正则(爬取糗图)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 爬虫数据解析--正则(爬取糗图)相关的知识,希望对你有一定的参考价值。
案例:使用正则爬取糗图百科图片
单页面的代码
import re
import requests
import os
#创建文件夹
if not os.path.exists(‘./qiutu‘):
os.mkdir(‘./qiutu‘)
headers = {
‘user-agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ‘
‘Chrome/57.0.2987.98 Safari/537.36‘}
url=‘https://www.qiushibaike.com/imgrank/page/‘
#使用通用爬虫对url对应的一整张页面进行爬取
page_text=requests.get(url=url,headers=headers).text
#使用聚焦爬虫将页面中所有的糗图进行解析/提取
ex =‘<div class="thumb">.*?<img src="(.*?)" alt.*?</div>‘
img_list=re.findall(ex,page_text,re.S)
for src in img_list:
#拼接出一个完整的图片url
src=‘https:‘+src
#请求到了图片的二进制数据
img_data=requests.get(url=src,headers=headers).content
#生成图片名称
img_name=src.split(‘/‘)[-1]
#图片存储的路径
img_path=‘./qiutu/‘+img_name
with open(img_path,‘wb‘) as f:
f.write(img_data)
print(img_name,‘下载成功‘)完整页面代码
#导入模块
import re
import requests
import os
#创建文件夹
if not os.path.exists(‘./qiutu‘):
os.mkdir(‘./qiutu‘)
#模仿浏览器访问
headers = {
‘user-agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ‘
‘Chrome/57.0.2987.98 Safari/537.36‘}
#网站访问地址
url=‘https://www.qiushibaike.com/imgrank/page/‘
#多页访问
for page in range(1,3):
new_url=url+ str(page) #新url地址
page_text=requests.get(url=new_url,headers=headers).text #页面内容下载
#正则匹配图片路径
ex =‘<div class="thumb">.*?<img src="(.*?)" alt.*?</div>‘
img_list=re.findall(ex,page_text,re.S)
#图片保存
for src in img_list:
src=‘https:‘+src #图片下载路径
img_data=requests.get(url=src,headers=headers).content #二进制保存
img_name=src.split(‘/‘)[-1] #图片名字
img_path=‘./qiutu/‘+img_name #图片保存路径
with open(img_path,‘wb‘) as f1:
f1.write(img_data)
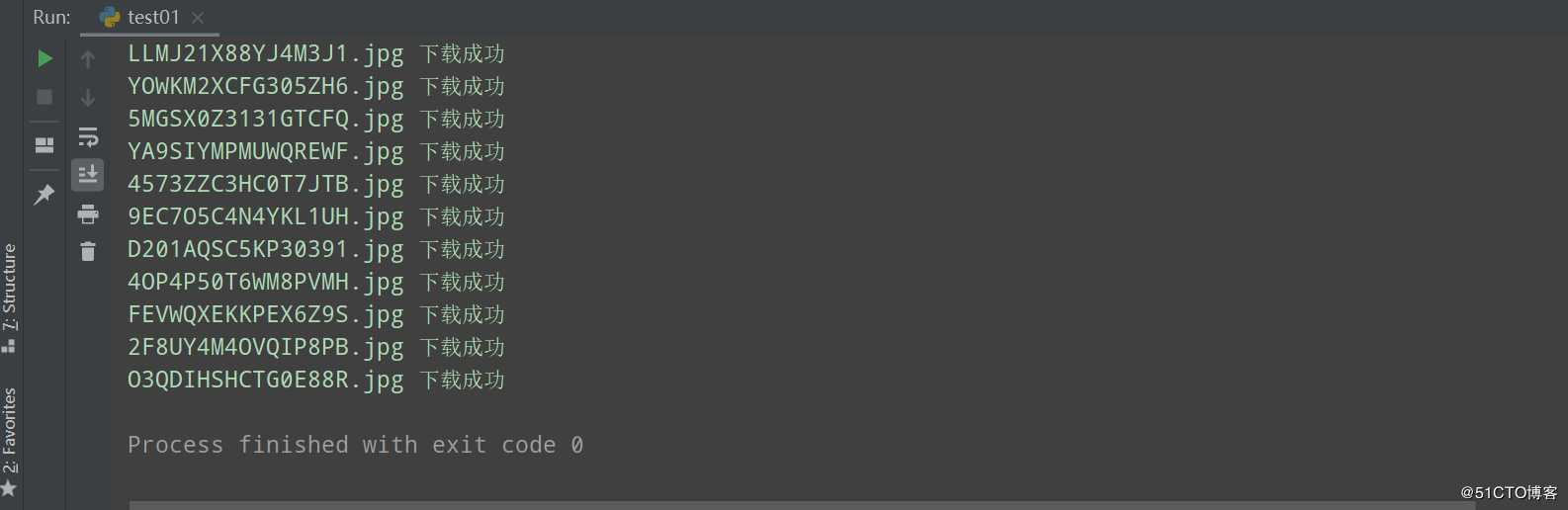
print(img_name,‘下载成功‘)运行结果:
正则解析知识点:
<div class="thumb">
<a href="/article/121721100" target="_blank">
<img src="//pic.qiushibaike.com/system/pictures/12172/121721100/medium/DNXDX9TZ8SDU6OK2.jpg" alt="指引我有前进的方向">
</a>
</div>
ex = ‘<div class="thumb">.*?<img src="(.*?)" alt.*?</div>‘
#第一个.*?表示<a href="/article/121721100" target="_blank">
#第二个.*?表示pic.qiushibaike.com/system/pictures/12172/121721100/medium/DNXDX9TZ8SDU6OK2.jpg (图片路径,是要匹配的目标)
#第三个.*?表示 "指引我有前进的方向"以上是关于Python 爬虫数据解析--正则(爬取糗图)的主要内容,如果未能解决你的问题,请参考以下文章