5月4日:unordermap/set,哈希以及哈希常用的拉链法,开放地址法,以及模板的特化相关应用
Posted qjwxlj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了5月4日:unordermap/set,哈希以及哈希常用的拉链法,开放地址法,以及模板的特化相关应用相关的知识,希望对你有一定的参考价值。
起处较为流行的数据储存方式为树形结构,再加上红黑树等优秀数据结构的发展,直到今天二叉平衡搜索树也经常被应用在各种方面,但是c++库里面还有两个与map/set很像的容器unorderedmap,他们的调用与普通的map几乎一样,有着非常优秀的查找时间复杂度,只是不能像二叉树哪样层序遍历得到顺序的排序结果。
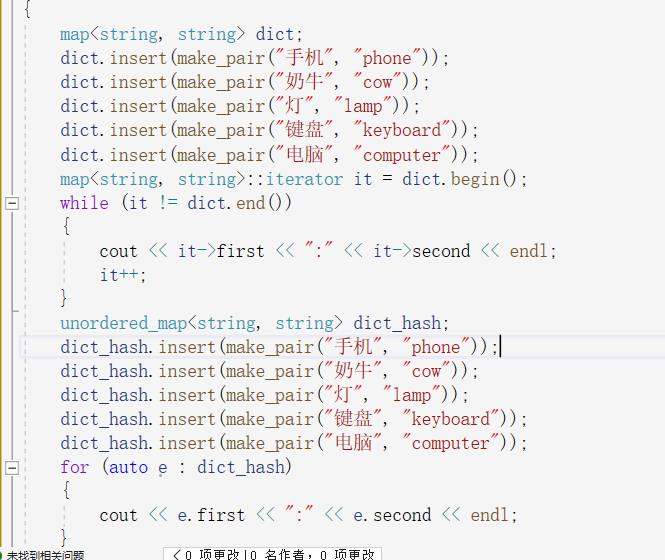
他们看着相似但是他们的底层却大不相同,unorderedmap(umap)底层为哈希表,哈希是一种映射关系。
首先提出一个问题,若将20.33.4444.5555.66666这些数字存起来,并且保证在查找时有着很优的查找时间复杂度,第一种方法就是开一个很大的数组,用下表直接访问,但是这样有着非常大的空间浪费,于是哈希中的除留余数法可以完美解决这个问题,数组中的每一个数对固定的数取余,可以得到很短的范围数据,将这几个数存入数组,当查找时也可以通过哈希映射查找。
但是因为树有很多但是格子就那么多,肯定免不了空间冲突,这是又有两种方法解决冲突:
1:开放地址法:这种方法时当发现取余数·后余数的位置已经有数据,于是可以向后检测,若后面的空间有空可以将数据放进去。这样就解决了冲突。
其中开放地址发包括开放地址发和二次探测法。
2:拉链法:数组中每个位置存放一个链地址,每次发生冲突时,将数据连在后面,这样也就解决了冲突。
实现哈希表:
首先是闭散列的开放地址法/链地址法:
1:大概架构:unordermap与map很像也是一个容器适配器,通过对容器中的容器修饰达到插入删除查找的目的,其中可以有开散列和闭散列两种选择,开散列就是利用vector容器存数据,用开放地址法解决冲突。闭散列也是用vector容器作为主要结构,其中vector中的数据类型是一个链式的结点,方便用链地址法解决冲突,这个也叫哈希桶。
首先定义一个vector作为map类的类成员变量,vector中存储要放的数据,
首先是往哈希表中插入数据,先得到数据的key值并且对其取余数,得到哈希表中下标的位置,并且检测此位置是否为空,不为空则向后探测,若探测到末尾,令index等于零,继续探测,不可能存在放不下的情况,因为哈希表本就是开了很大的空间,且再负载因子达到0.7左右时开始增容。要注意的是在插入时探测到与插入是key相同的值时返回插入失败,因为其性质与二叉搜索树一样,key值不能重复。
tips:插入时首先要检查负载因子是否达到增容的标准,若达到了进行增容,哈希表的增容与普通表的增容不一样,若只是普通的开辟空间,那么已有的表中数据就会不准确,所以需要重新将原表中的数据重新插入,因此哈希表的增容代价非常大,需要谨慎增容,增容的一般思路是另起一个vector将数据意义挪入新表中,如下图:
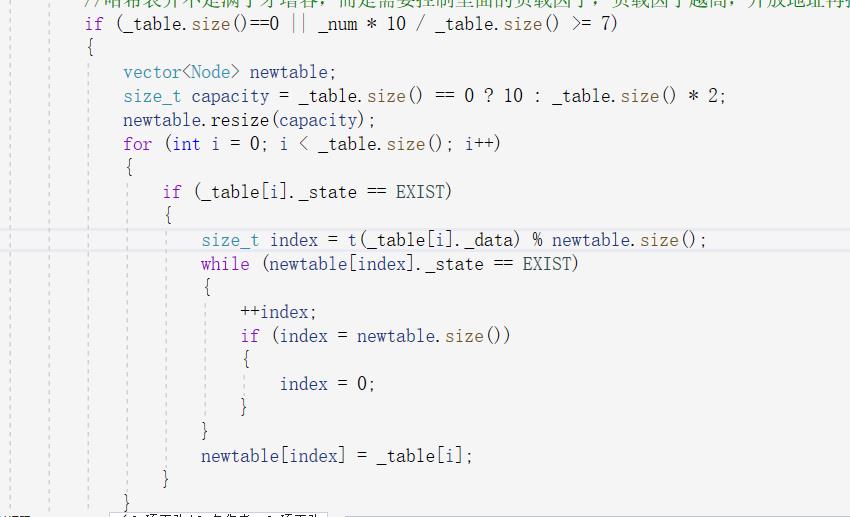
但是还有一种对人来说比较轻松的写法,就是直接开一个新的哈希表,对新表直接开辟足够的空间,调用已经实现的插入函数一一插入,然后将新表中的vector与旧表中的互换,因为新表是临时变量所以出了作用域会自动析构。所以对人来说很省事。

插入函数到此为止:

然后是查找函数:
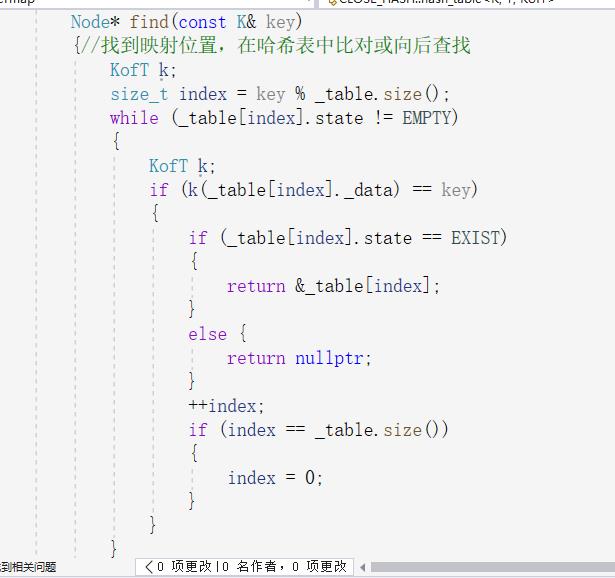
一样的思路找到key取余的值,定位到表中,若数值不匹配则继续往后找,因为可能被开放地址放到后面了,一旦遇到空就就结束,但是又有一个问题,若是数据被删除了,就不能确定这个地方曾将有没有过数据,可能曾经有过被删除了,但是被删除之前开放地址到后面去了,就会出错,。但是有一个很巧妙的解决方法,就是给每个数据加一个状态分别是删除,存在和空,这样在遇到空时直接结束,遇到存在和删除时继续向后探测。于是vector中的数据类型就变成了这样:一个有枚举类型构成的状态,和数据本身,

然后就是一如既往的查找步骤,探测到vector末尾时将index置为一。继续探测,直到找到,或者为空。
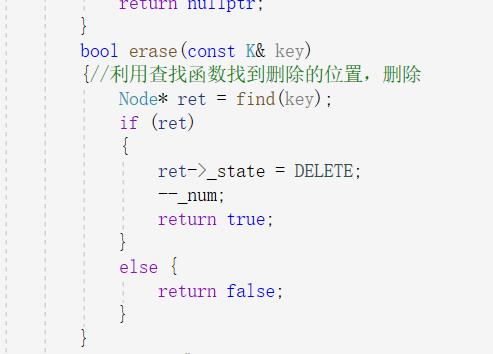
最后是删除:时最简便的:利用已经实现的查找函数找到位置将此位置的状态置为删除即可。
因为哈希表可能别map或者set复用所以数据类型应该用模板的范式编程。加入一个仿函数参数控制key的读取,若数据类型为map的pair则仿函数返回pair中的first若为set则返回本身。

开放地址法就这些,接下来主要实现哈希桶,然后复用哈希桶用实现unorderedmap
大致思路:首先用模板的范式编程实现闭散列的链地址法,在实现的过程中给这个哈希桶预留仿函数模板参数位,为后来的复用做准备。
首先定义一个vector作为类成员变量,然后定义一个struct公共类单链式结点作为vector的数据类型。struct中有一个指向像一个结点的指针变量,和要存储的数据。

首先是插入函数:
老方法用除留余数法得到vector中的位置,将此位置赋给一个临时变量,用while迭代这个临时变量检查数据是否重复,然后插入,

然后是查找:还是老方法,找到位置返回这个结点,没找到返回空;
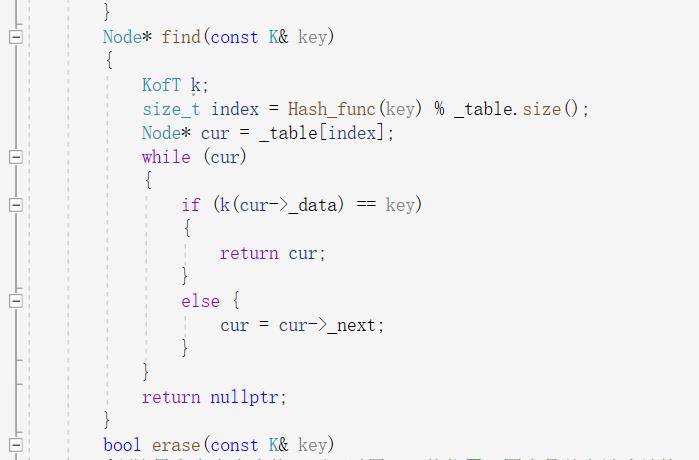
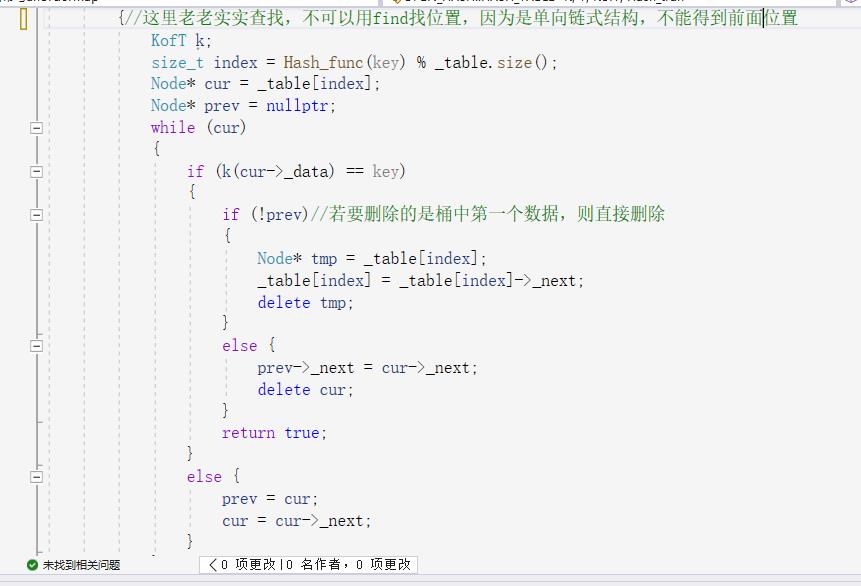
最后时删除:这个删除和之前的开散列不一样不可以用find函数直接找到删除,因为这里是单向链表,需要保留前一个结点来保存数据然后删除
tips:这里若删除的节点是第一个结点,就需要单独处理,+_table[i直接指向下一个然后释放空间。
储存结构时不能没有遍历函数的。然而遍历函数又少不了迭代器所以接下来是迭代器的实现:
与之前红黑树相差不多,先弄一个begin函数返回哈希表中的第一个不为空的数据。然后是end返回一个空指针构造的迭代器,
定义一个迭代器类型,里面存放结点指针,重载解引用运算符和指针访问变量箭头运算符,和不等运算符,以及自增运算符,
比较重要的是自增运算符,这个比价麻烦,因为当vector中一个结点访问完后需要vector向后移动一位,这个比较难处理,于是往迭代器中需要多传一个哈希表的指针。。。。。。
2018年3月19日推荐文章精选 “一周好文,一文打尽”
区块链,工作证明(POW)代码+原理 golang版剖析
作者:64180190
简介:在本文中,我们将讨论哈希值。哈希是获取指定数据的哈希值的过程。 哈希值是对其计算的数据的唯一表示。 哈希函数是一个获取任意大小的数据并产生固定大小的哈希的函数。 以下是哈希的一些主要功能:
“深入浅出”来解读Docker网络核心原理
作者:甘兵
简介:在深入Docker内部的网络原理之前,我们先从一个用户的角度来直观感受一下Docker的网络架构和基本操作是怎么样的。
GTID!MySQL复制中的核武器
作者:superZS
简介:GTID又叫全局事务ID(Global Transaction ID),是一个已提交事务的编号,并且是一个全局唯一的编号。MySQL5.6版本之后在主从复制类型上新增了GTID复制。
Docker高级网络实践之 玩转Linux network namespace & pipework
作者:甘兵
简介:假设需要运营一个数据中心的网络,我们有许多的宿主机,每台宿主机上运行了成千上万个Docker容器,如果使用4种网络驱动的话会是怎么样的呢,我们来分析一下
GreenPlum数据库故障恢复测试
作者:ylw6006
简介:本文介绍gpdb的master故障及恢复测试以及segment故障恢复测试。
百万级别长连接,并发测试指南
作者:youerning
简介:都说haproxy很牛x, 可是测试的结果实在是不算满意, 越测试越失望,无论是长连接还是并发, 但是测试的流程以及工具倒是可以分享分享。也望指出不足之处。
"三剑客”之Swarm集群架构、集群管理 、服务管理
作者:youerning
简介:本文的重点内容在于分享Swarm;可能有些朋友会问,为什么不分享一下Kubernetes呢,别着急。常言道:路得一步一步走,饭要一口一口吃。Kubernetes比较难理解,所以咋们先把Swarm玩明白了之后在来玩Kubernetes会顺畅很多。
Nginx+Tomcat+memcached高可用会话保持
作者:dyc2005
简介:本文通过 Tomcat Session Replication Cluster(tomcat自带)和tomcat结合memcat及第三方组件实现Tomcat Memcache Session Server高可用会话缓存服务
记录一次邮件容灾恢复过程
作者:Juck_Zhang
简介:客户目前使用的是Exchange Server 2013,两前两后,数据盘是存储挂载过来的,邮件备份使用的是NBU,由于机房漏水,导致存储服务器宕机。导致绝大部分数据丢失。
最后的最后:

以上是关于5月4日:unordermap/set,哈希以及哈希常用的拉链法,开放地址法,以及模板的特化相关应用的主要内容,如果未能解决你的问题,请参考以下文章