Python数据可视化编程实战-1
Posted cucu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python数据可视化编程实战-1相关的知识,希望对你有一定的参考价值。
第1章
有两种方式更改运行参数:使用参数字典(rcparams)或调用matplotlib.rc()命令。第一种方式中,可以通过 rcparams字典访问并修改所有已经加载的配置项;第二种方式中,可以通过matplotlib.rc()传入属性的关键字元组来修改配置项。
使用 matplotlib. rcparams的例子。
import matplotlib as mpl
mpl. rcparams [ ‘lines.linewidth‘] = 2
mpl. rcparams [‘lines color‘] = ‘r‘
使用 matplotlib.rc()函数调用的例子。
import matplotlib as mpl
mpl. rc(‘lines‘, linewidth = 2, color= ‘r‘)
示例:
import matplotlib. pyplot as plt import numpy as np t = np. arange(0.0,1.0,0.01) s=np.sin(2 *np.pi *t) # 设置线为红色 plt.rcParams [‘lines.color‘] = ‘r‘ plt.plot(t, s) c=np.sin(2 *np.pi *t) # 设置线的宽度(3有无引号均可) plt. rcParams[‘lines.linewidth‘] = ‘3‘ plt.plot(t,c) plt.show()
1.9为项目设置参数
配置文件包括以下配置项:
◆ axes:设置坐标轴边界和表面的颜色、坐标刻度值大小和网格的显示。
◆ backend:设置目标输出 TkAgg和 GTKAgg。
◆ figure:控制dpi、边界颜色、图形大小和子区(subplot)设置。
◆ font:字体集( font family)、字体大小和样式设置。
◆ grid:设置网格颜色和线型。
◆ legend:设置图例和其中文本的显示。
◆ line:设置线条(颜色、线型、宽度等)和标记。
◆ patch: 是填充2D空间的图形对象,如多边形和圆。控制线宽、颜色和抗锯齿设置等。
◆ savefig:可以对保存的图形进行单独设置。例如,设置渲染的文件的背景为白色。
◆ text:设置字体颜色、文本解析(纯文本或 latex标记)等。
◆ verbose:设置 matplotlib在执行期间信息输出,如 silent、 helpful、 debug和debug- annoying。
◆ xticks和 yticks:为x、y轴的主刻度和次刻度设置颜色、大小、方向,以及标签大小。
第2章 了解数据
2.2 csv文件
import csv filename = "E:\\python_data_plot\\ch02\\ch02_data.csv" data = [] # 打开文件 with open(filename) as f: reader = csv.reader(f) header = next(reader) # 读取文件头 for row in reader: temp = int(row[1]) # 读取第二列的数据,原格式为字符串型,化为整型 data.append(row[1]) # 存入数组 print(data)
2.3 读取excel文件
xlrd模块使用的对象模型:每一个工作簿workbook中包含多个工作表sheet,每个工作表中有多个单元格对象cell,我们从单元格中将值提取出来。
主要方法:
sheet.row_values(1) #读取第2行的值
sheet.cell(1, 1).value #读取特定单元格(第2行第2列)的值
import xlrd #读取excel文件一列数据 def excel(): # 1.打开Excel文件 wb = xlrd.open_workbook(‘E:\\python_data_plot\\ch02\\MK.xlsx‘) # 2.通过excel表格名称(rank)获取工作表 sheet = wb.sheet_by_name(‘Sheet1‘) dat = [] # 创建空list # 根据行数(nrows)和列数(ncols)读取单元格的内容 for a in range(1, sheet.nrows): # 从第二行开始,循环读取表格内容(每次读取一行数据) cells = sheet.row_values(a) # 每行数据赋值给单元格cells data = int(cells[0]) # 因为表内可能存在多列数据,0代表第一列数据,1代表第二列,以此类推 dat.append(data) # 把每次循环读取的数据插入到list
return dat a = excel() #返回整个函数的值 print(a)
2.10 读取大块文件数据
对于数据特别大的数据,如包含几千万行数据的,处理起来很困难。这类文件不能一次性把文件数据读取进内存中,而是分很多次。
这一类读取文件的函数有两个参数:chunksize,iterator
1)指定CHUNKSIZE分块读取文件
read_csv 和 read_table 有一个chunksize参数,用以指定一个块大小(每次读取多少行),返回一个可迭代的 TextFileReader 对象。
table=pd.read_table(path+‘kuaishou.txt‘,sep=‘ ‘,chunksize=1000000)
2)指定迭代=真
reader = pd.read_table(‘tmp.sv‘, sep=‘ ‘, iterator=True)
2020-06-28 18:11:12
2.13 生成可控的随机数据集合
标准差:表示个体和群体之间的差异。如果差异越大,标准差会越大;如果所有个体实验在整组范围内基本相同,标准差会比较小。
方差:标准差的平方。
总体
样本:总体的子集。
主要用python的random模块生成数据,其主要用法如下:
import random print(random.randint(1, 10)) # 产生 1 到 10 的一个整数型随机数 print(random.random()) # 产生 0 到 1 之间的随机浮点数 print(random.uniform(1.1, 5.4)) # 产生 1.1 到 5.4 之间的随机浮点数,区间可以不是整数 print(random.choice(‘tomorrow‘)) # 从序列中随机选取一个元素 print(random.randrange(1, 100, 2)) # 生成从1到100的步长为2的随机整数(如得到33,33-1=32,为2的倍数) print(random.sample(‘zyxwvutsrqponmlkjihgfedcba‘, 5)) # 多个字符中生成指定数量的随机字符 a = [1,3,5,6,7] # 将序列a中的元素顺序打乱 random.shuffle(a) print(a)
print(random.normalvariate(0.2, 1.2)) # 从中值为0.2,标准差为1.2的正态分布中选取一个随机值
创建一个均匀分布的样本:
(pylab库结合了pyplot和numpy,对交互式使用来说比较方便,既可以画图又可以进行简单的计算。)
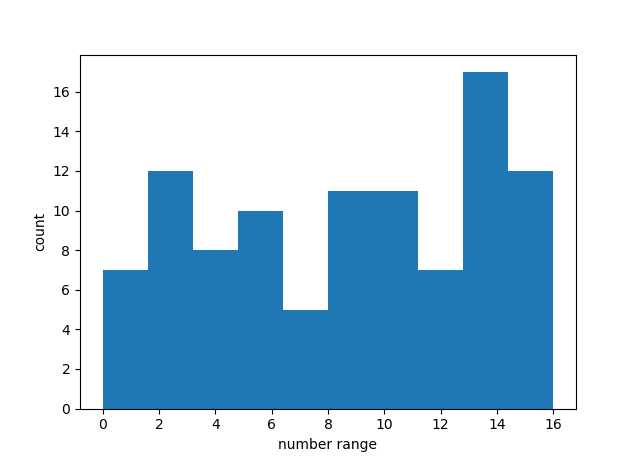
import pylab import random random.seed() real_vars = [] real_vars = [random.randint(0, 16) for val in range(100)] # 生成100个在0-16之间的随机整数 print(real_vars) # 创建分为10段的柱状直方图 pylab.hist(real_vars, 10) # 定义x轴和y轴的坐标轴标题 pylab.xlabel("number range") pylab.ylabel("count") # 显示图形 pylab.show()
第3章 绘制并定制化图表
3.2 定义图表类型----柱状图、线型图和堆积柱状图
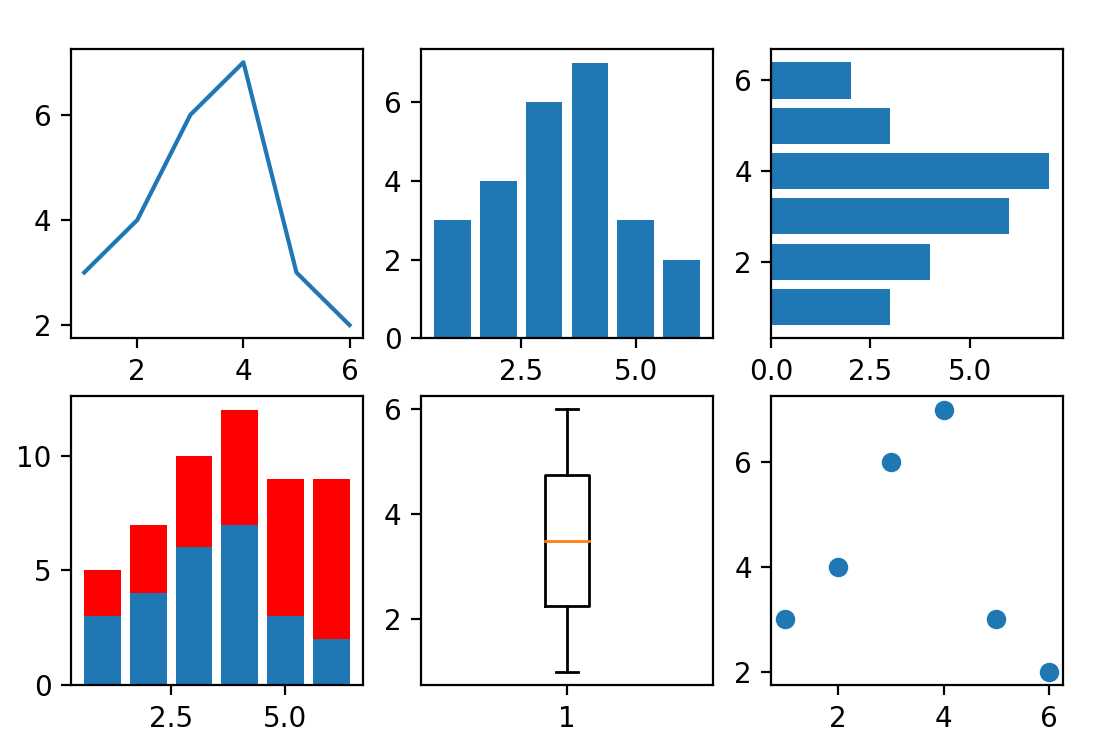
from matplotlib.pyplot import * # 数据 x = [1, 2, 3, 4, 5, 6] y = [3, 4, 6, 7, 3, 2] # 创建新图形 figure() # 把分区划分为2*3的网格,选择#1的位置 subplot(2, 3, 1) plot(x, y) # 柱状图,选择#2的位置 subplot(2, 3, 2) bar(x, y) # 水平(horizontal)柱状图,选择#3的位置 subplot(2, 3, 3) barh(x, y) # 叠加柱状图 subplot(2, 3, 4) bar(x, y) # 叠加柱状图所需要的补充数据 y1 = [2, 3, 4, 5, 6, 7] bar(x, y1, bottom=y, color=‘r‘) # 箱线图 subplot(2, 3, 5) boxplot(x) # 散点图 subplot(2, 3, 6) scatter(x, y) show()
补充说明:
figure():创建一个新的图表,给该方法传递字符串参数,这个字符串就会成为窗口的标题。
subplot(2, 3, 1):第一个参数是行数,第二个参数为列数,第三个参数表示图形的标号。
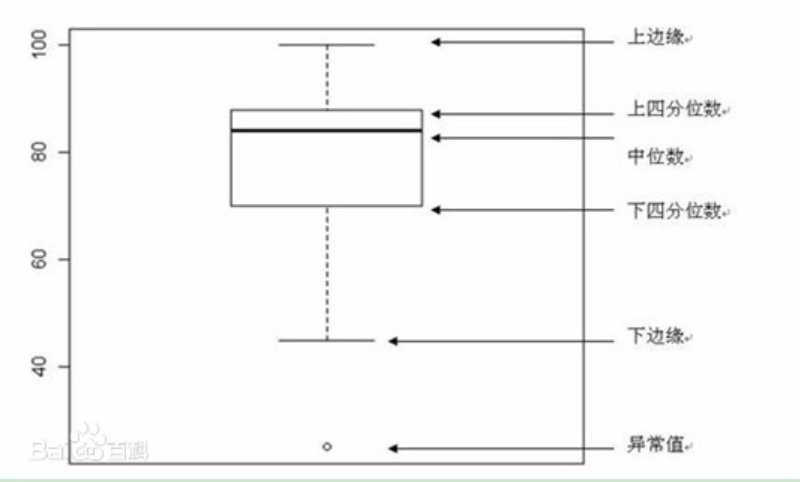
箱线图:一种用作显示一组数据分散情况资料的统计图。
3.3 简单的正弦图和余弦图
绘制的基本图表包含以下元素:
xlim()和ylim():坐标轴的最大和最小刻度。
xticks()和yticks():设置坐标轴的刻度间隔。
from matplotlib.pyplot import * import numpy as np # 取-pi到pi之间具有相同线性距离的256个点 x = np.linspace(-np.pi, np.pi, 256, endpoint=True) y = np.cos(x) # 计算正弦值和余弦值 y1 = np.sin(x) plot(x, y) # 画正弦图和余弦图 plot(x, y1) title("Function sin and cos") # 定义题目 xlim(-3.0, 3.0) # 设置x和y的范围 ylim(-1.0, 1.0) # 设置坐标轴的刻度间隔 xticks([-np.pi, -np.pi/2, 0, np.pi/2, np.pi]) yticks([-1, 0, +1]) show()
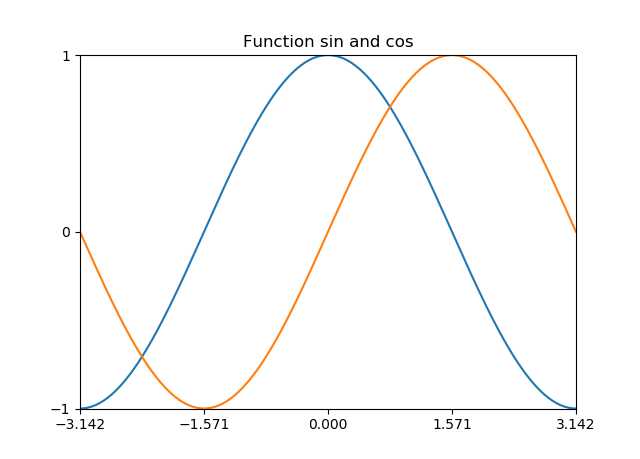
# xlim(-3.0, 3.0) # 设置x和y的范围 # ylim(-1.0, 1.0)
以上是关于Python数据可视化编程实战-1的主要内容,如果未能解决你的问题,请参考以下文章