24 操作系统的网络架构
Posted xuan01
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了24 操作系统的网络架构相关的知识,希望对你有一定的参考价值。
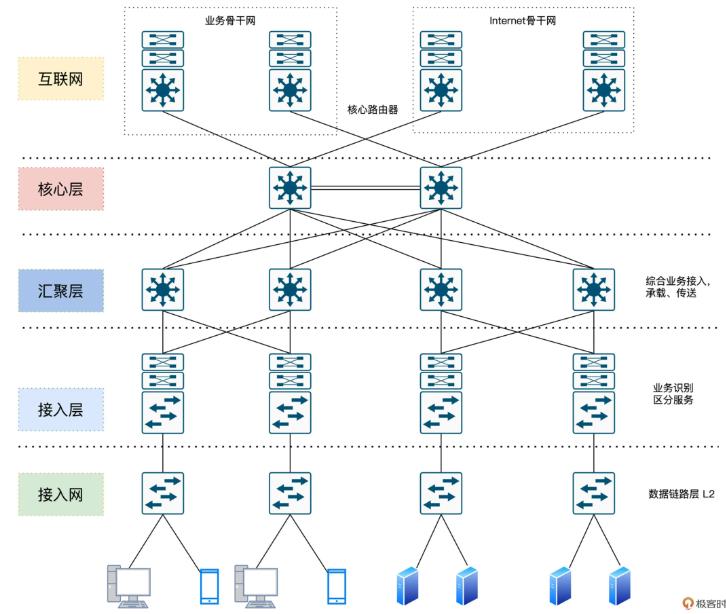
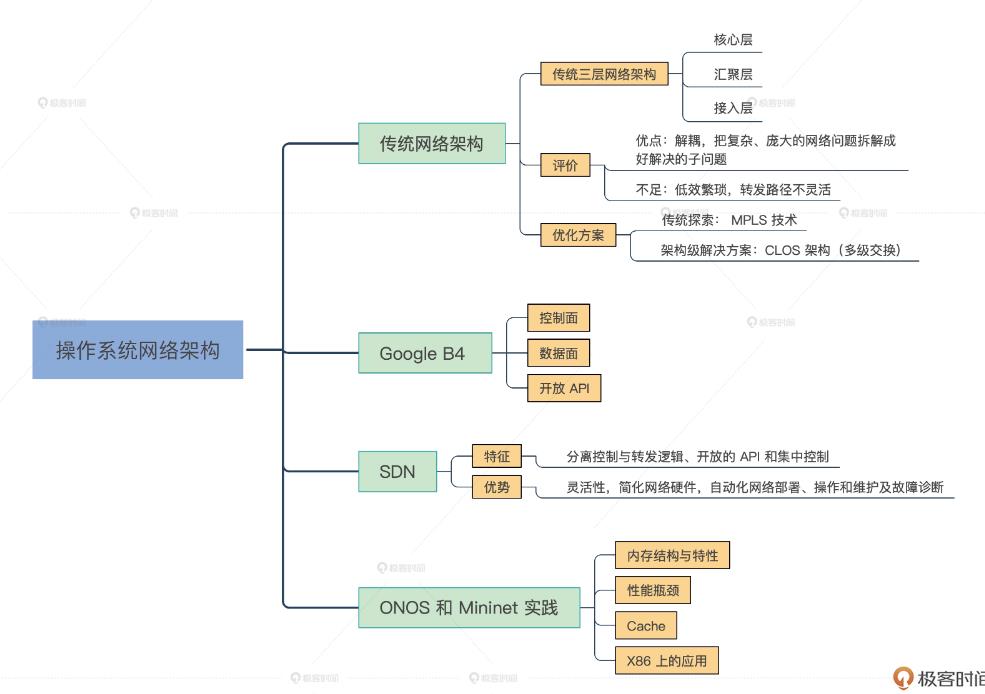
传统的网络架构:
三层:核心层、汇聚层、接入层;
核心层:高速转发、为多个汇聚层提供连通性,同时为整个网络提供灵活的L3路由网络;
汇聚层:提供防火墙、SSL卸载、入侵检测、网络分析等;
接入层:ToR交换机,与服务器物理连接;
经典的IP网络是逐跳转发数据的,转发数据时,每台路由器都要根据包头的目的地址查询路由表;
核心和汇聚之间需要高效率、高性能,进行优化:
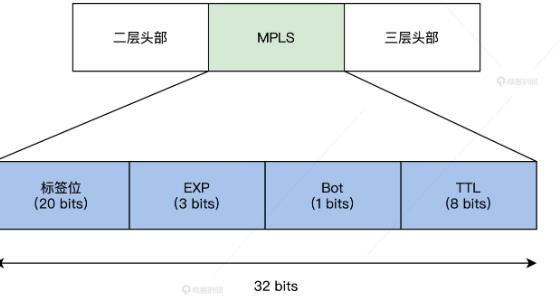
引入多协议标签交换技术(MPLS),通过 LDP 标签分发协议;好比快递盒子,后续只需要读取标签,避免了传统路由网络中,每一跳都要打开盒子查看的额外开销;
路径计算元素协议(RSVP-TE)最大的优点是:收集整个网络的拓扑 和 链路状态信息;
缺点:资源利用率低,复杂度高、价格昂贵;
借鉴胖树 Fattree 和 CLOS 模型思想,衍生了 叶脊 spine - leaf 网络架构;高带宽、低延迟、非阻塞、可扩展的服务器到服务器连接;代表之一: Google B4网络;
Google B4 网络:
实现数据在各个园区的实时复制;由控制软件和白盒交换机构成;
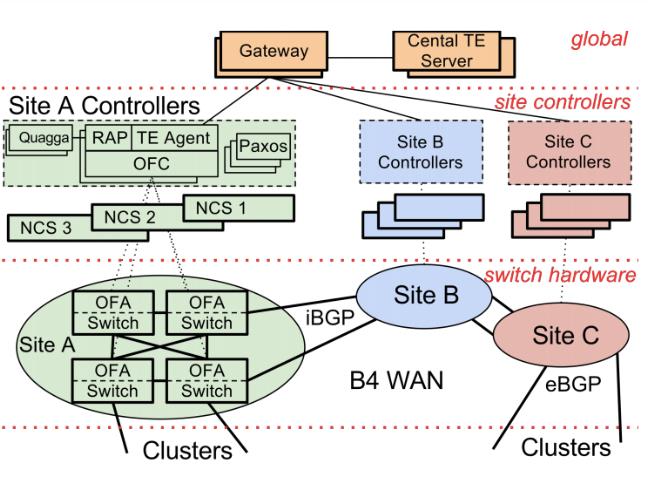
三层构成:物理设备层(Switch Hardware)、局部网络控制层(Site Controllers)和全局控制层(Global)。
SDN原理:
ONF开放网络基金会,将SDN分为三层;
应用层是由包含了各种不同的的业务逻辑的应用构成的。
控制层主要负责数据平面相关资源的编排、调度、网络拓扑的维护以及状态信息管理等工作。
数据层相对来说逻辑更轻,主要负责数据的转发、处理以及运行时的一些状态收集工作。
开放网络操作系统 ONOS 组网实践:
SDN 分为控制面和数据面,对应到开源实现中 ONOS 就是控制面的具体实现,而 Mininet 对应的就是数据面实现。Mininet 是由斯坦福大学基于 Linux 容器架构开发的一个云原生虚拟化网络仿真工具。
使用 ONOS+Mininet 我们可以快速创建一个包含主机、交换机、SDN 控制器以及链路的虚拟网络,并且 Mininet 创建的交换机也是支持上文讲到的 OpenFlow 协议的,这也使得它具备了高度的灵活性。使用这个工具,我们可以在本地轻松搭建一个 SDN 开发、调试环境。
1、下载镜像Mininet Download/Get Started With Mininet - Mininet;
2、解压之后,导入到VM;
3、用户名 / 密码:mininet/mininet 即可登录;
4、安装docker;
sudo apt-get update sudo apt install curl sudo apt install ssh curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
5、拉取onos的镜像;
sudo docker pull onosproject/onos
6、创建Mininet容器连接onos;
先把容器的网络映射到虚拟机,docker run 的时候加上-p 8000:80 这样的参数;
sudo docker run -t -d -p 8181:8181 --name onos1 onosproject/onos;

7、获取onos容器ID:

8、通过容器id获取onos容器的IP;

9、得到IP后,使用ssh登录 onos;用户名密码都是 karaf;
ssh -p 8101 karaf@172.17.0.2 app activate org.onosproject.openflow #启用openflow app activate org.onosproject.fwd #启用forward转发功能
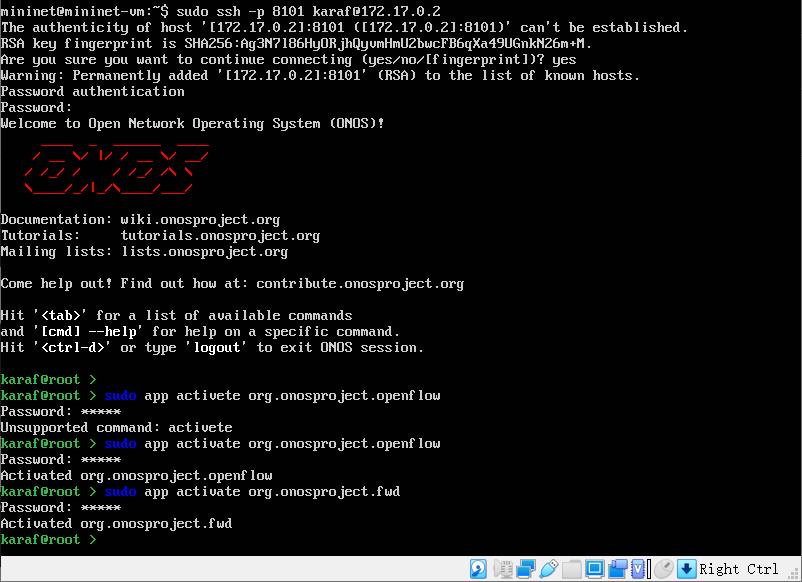
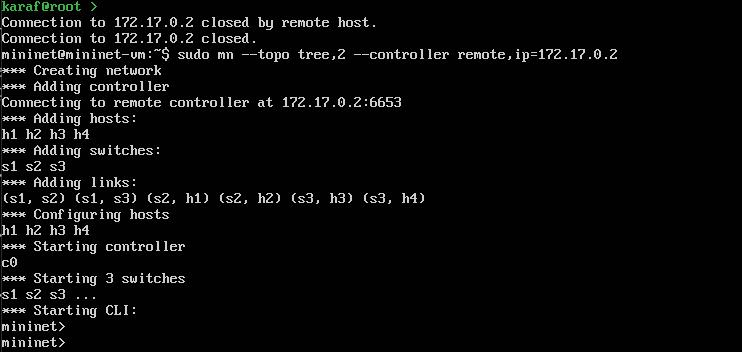
10、键盘CTRL+D退出onos登录,返回虚拟机,配置mininet,连接到onos;
sudo mn --topo tree,2 --controller remote,ip=172.17.0.2 #创建临时网络 pingall #网路连通性检测
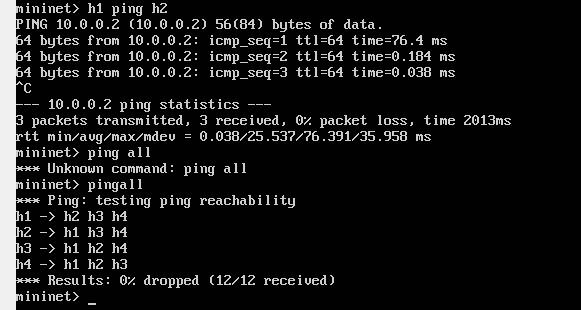
11、onos查看拓扑:
打开URL:http://172.17.0.2:8181/onos/ui/login.html
(说明:先把容器的网络映射到虚拟机,再把虚拟机的网络映射到本地即可。docker run 的时候加上 -p 8000:80 这样的参数,就可以映射到虚机了,然后再改一下 VBox 的网络设置。)
(网络配置有问题;后续更新)
总结:
[架构之路-127]-《软考-系统架构设计师》-计算机网络 -1- 协议栈网络规划与设计网络接入技术
前言:

第1章 TCP/IP协议族
1.1 计算机网络概述
计算机网络是计算机技术和通信技术相结合的产物。计算机网络是信息收集、分发、存储、处理和消费的重要载体。
“计算机网络”这一术语是指由通信线路互相连接的许多自主工作的计算机构成的集合体。这里强调构成网络的计算机是自主工作的,是为了和多终端分时系统相区别。在后一种系统中,终端无论是本地还是远程的,只是主机和用户之间的接口,它本身并不拥有计算资源,全部资源集中在主机中。主机以自己拥有的资源分时地为各终端用户服务。在计算机网络中的各个计算机(工作站)本身拥有计算资源,能独立工作,能完成一定的计算任务,同时,用户还可以共享网络中其他计算机的资源(CPU、大容量外存或信息等)
计算机网络的组成元素可以分为两大类,即网络节点和通信链路。
网络节点又分为端节点和转发节点。
端节点指信源和信宿节点,例如用户主机和用户终端;
转发节点指网络通信过程中控制和转发信息的节点,例如交换机、集线器、接口信息处理机等。
通信链路指传输信息的通道,可以是电话线、同轴电缆、无线电线路、卫星线路、微波中继线路和光纤缆线等。
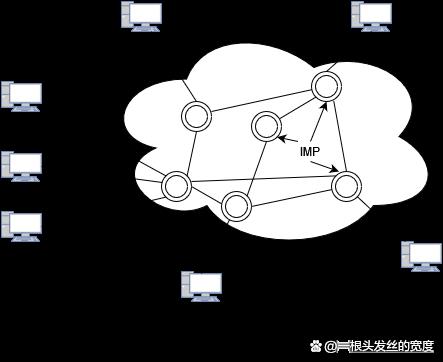
资源子网:
图中曲线框外的部分称为资源子网。资源子网中包括拥有资源的用户主机和请求资源的用户终端,它们都是端节点。
通信子网:
曲线框内的部分叫做通信子网,其任务是在端节点之间传送由信息组成的报文,主要由转发节点和通信链路组成。IMP是一种专用于通信的计算机,有些IMP之间直接相连,有些IMP之间必须经过其他IMP才能相连。当IMP收到一个报文后要根据报文的目标地址决定把该报文提交给与它相连的主机还是转发到下一个IMP,这种通信方式叫作存储-转发通信。在广域网中的通信方式一般都是采用这种方式。另外一种通信方式是广播通信方式,主要用于局域网中。
通信子网中转发节点的互连模式叫子网的拓扑结构。其中全连接型对于点对点的通信是最理想的,但由于连接数接近节点数的平方倍,所以实际上是行不通的。在广域网的常见的互连拓扑是树型和不规则型,而在局域网中常见的是星型、环型和总线型等规则型拓扑结构。

几种拓扑结构
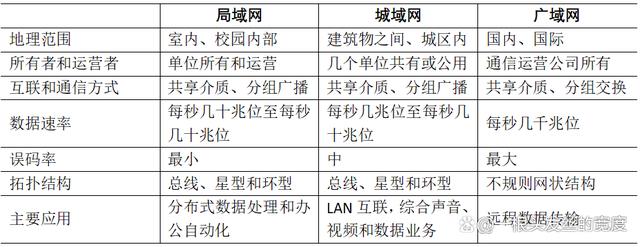
按照互连规模和通信方式,可以把网络分为局域网(LAN)、城域网(MAN)和广域网(WAN),这三种网络比较如下:
1.2 ISO 7层网络协议模型
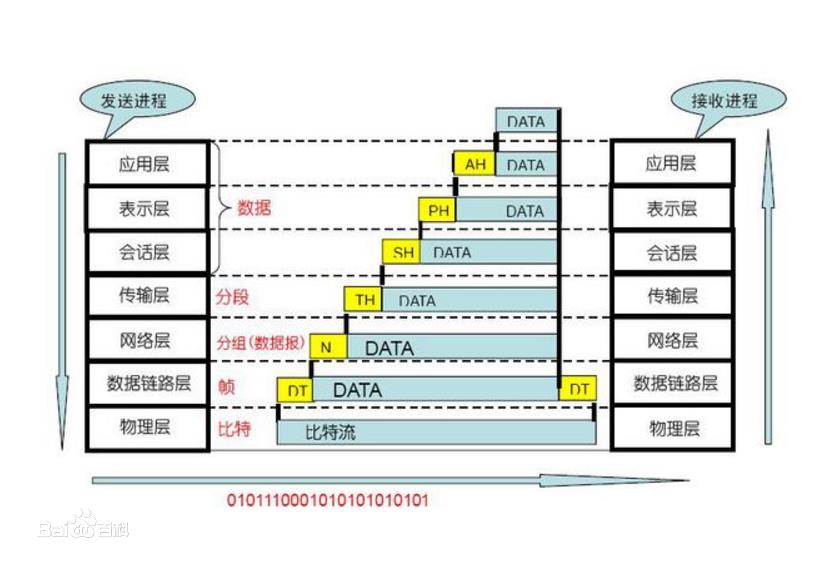
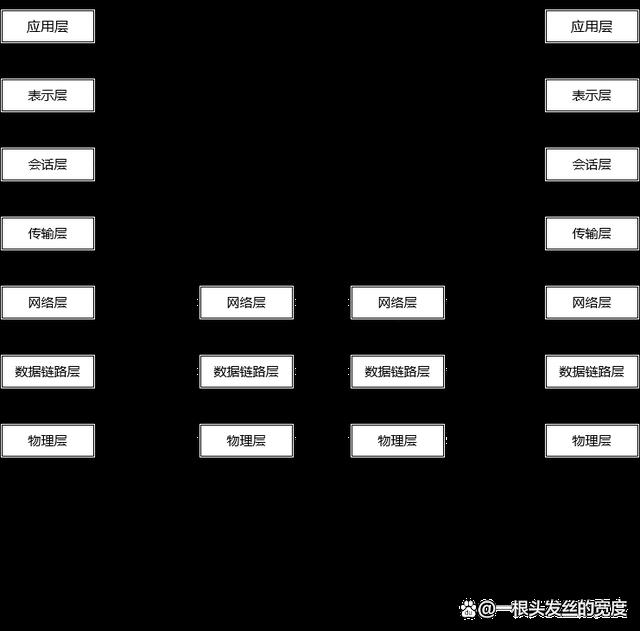
1.应用层:
这是OSI的最高层。这一层的协议直接为端用户服务,提供分布式处理环境。应用层管理开放系统的互连,包括系统的启动、维持和终止,并保持应用进程间建立连接所需的数据记录,其他层都是为支持这一层的功能而存在的。
2.表示层:
表示层的用途是提供一个可供应用层选择的服务的集合,使得应用层可以根据这些服务功能解释数据的含义。表示层以下各层只关心如何可靠地传输数据,而表示层关心的是所传输数据的表现方式、它的语法和语义。表示服务的例子有统一的数据编码、数据压缩格式和加密技术等。
3.会话层:
会话层支持两个表示层实体之间的交互作用。它提供的会话服务可分为以下两类。
(1)把两个表示实体结合在一起,或者把它们分开,这叫会话管理。
(2)控制两个表示实体间的数据交换过程,例如分段、同步等,这一类叫会话服务。
4.传输层:
这一层在低层服务的基础上提供一种通用的传输服务。会话实体利用这种透明的数据传输服务而不必考虑下层通信网络的工作细节,并使数据传输能高效地进行。传输层用多路复用或分流的方式优化网络的传输效率。传输层的服务可以提供一条无差错按顺序的端到端连接,也可能提供不保证顺序的独立报文传输,或多目标报文广播。传输层协议是真正的源端到目标端的协议,它由传输连接两端的传输实体处理。传输层下面的功能层协议都是通信子网中的协议。
5.网络层:
这一层的功能属于通信子网,它通过网络连接交换传输层实体发出的数据。网络层把上层传来的数据组织成分组在通信子网的节点之间交换传送。当传送的分组跨越一个网络的边界时,网络层应该对不同网络中分组的长度、寻址方式、通信协议进行变换,使得异构型网络能够互联互通。
6.数据链路层:
这一层的功能是建立、维持和释放网络实体之间的数据链路,这种数据链路对网络层表现为一条无差错的信道。相邻节点之间的数据交换是分帧进行的,各帧按顺序传送,并通过接收端的校验检查和应答保证可靠的传输。数据链路层对损坏、丢失和重复的帧应能进行处理,这种处理过程对网络层是透明的。
7.物理层:
这一层规定通信设备机械的、电气的、功能的和过程的特性,用于建立、维持和释放数据链路实体间的连接。
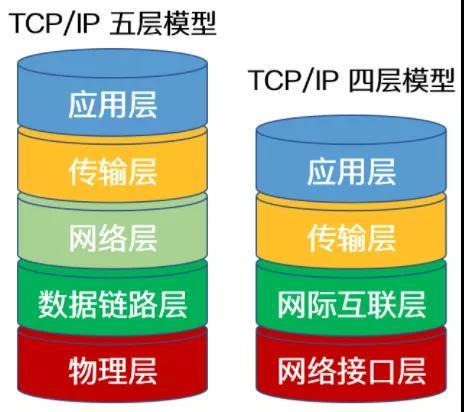
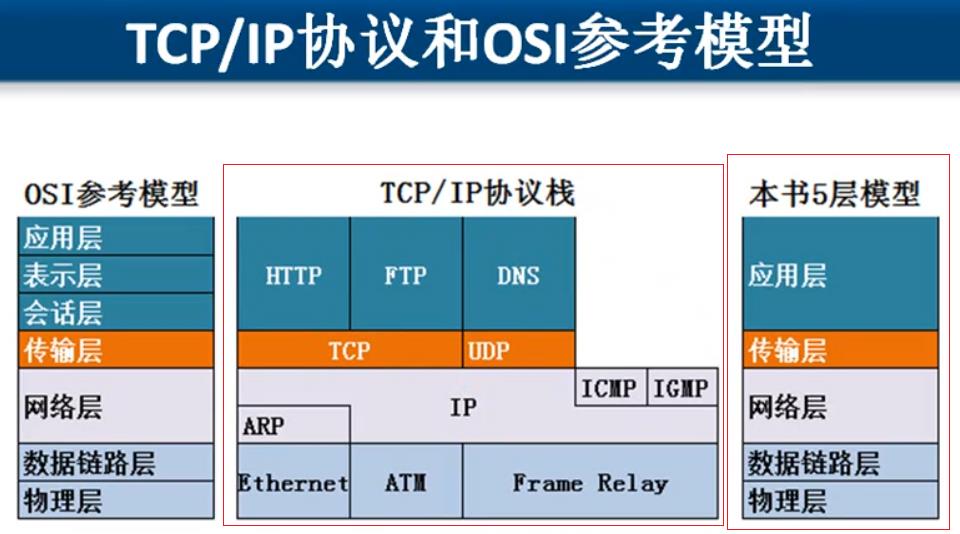
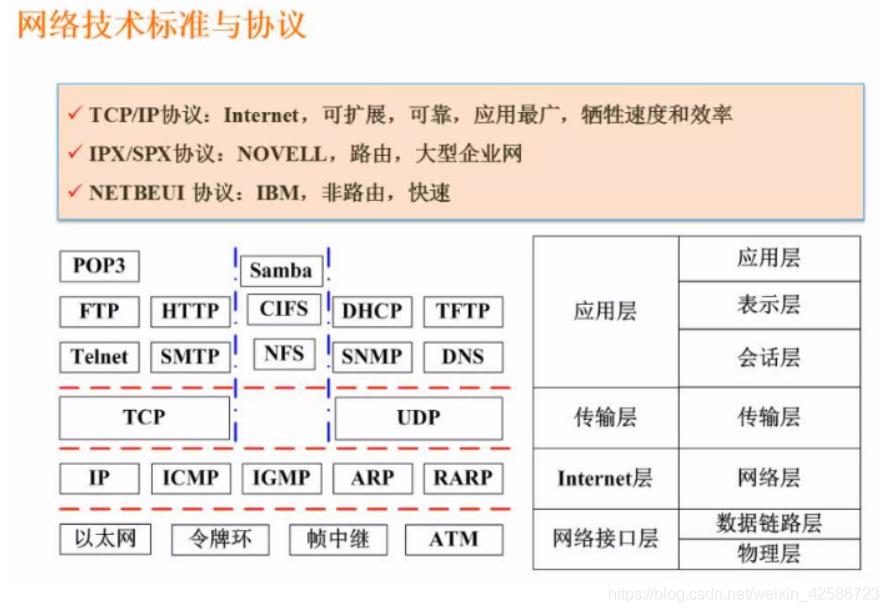
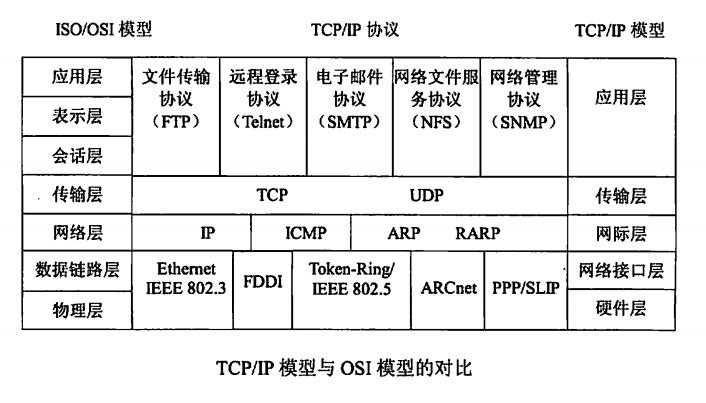
1.3 TCP/IP协议族与ISO 七层模型
1.4 DHCP 协议
1.4.1 Client-Server架构
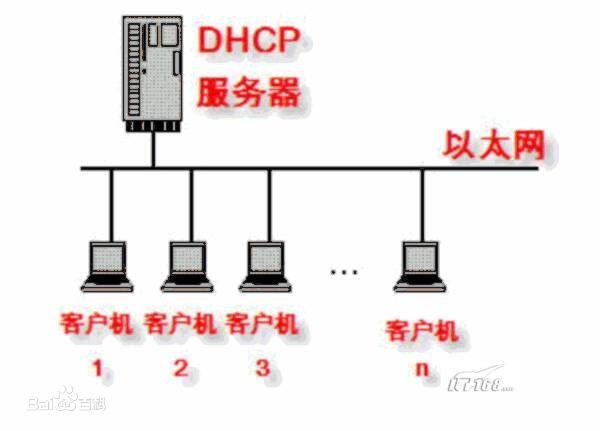
1.4.2 概述与定义
动态主机配置协议是一个局域网的网络协议。指的是由服务器控制一段IP地址范围,客户机登录服务器时就可以自动获得服务器分配的IP地址和子网掩码。担任DHCP服务器的计算机需要安装TCP/IP协议,并为其设置静态IP地址、子网掩码、默认网关等内容。
DHCP是由IETF(internet 工作任务小组)开发设计的,于1993年10月成为标准协议,其前身是BOOTP协议。当前的DHCP定义可以在RFC 2131中找到,而基于IPv6的建议标准(DHCPv6)可以在RFC 3315中找到。

两台连接到互联网上的电脑相互之间通信,必须有各自的IP地址,由于IP地址资源有限,宽带接入运营商不能做到给每个报装宽带的用户都能分配一个固定的IP地址(所谓固定IP就是即使在你不上网的时候,别人也不能用这个IP地址,这个资源一直被你所独占),所以要采用DHCP方式对上网的用户进行临时的地址分配。也就是你的电脑连上网,DHCP服务器才从地址池里临时分配一个IP地址给你,每次上网分配的IP地址可能会不一样,这跟当时IP地址资源有关。当下线的时候,DHCP服务器可能就会把这个地址分配给之后上线的其他电脑。这样就可以有效节约IP地址,既保证了网络通信,又提高IP地址的使用率。
在一个使用TCP/IP协议的网络中,每一台计算机都必须至少有一个IP地址,才能与其他计算机连接通信。为了便于统一规划和管理网络中的IP地址,DHCP(Dynamic Host Configure Protocol,动态主机配置协议)应运而生了。这种网络服务有利于对校园网络中的客户机IP地址进行有效管理,而不需要一个一个手动指定IP地址。
DHCP用一台或一组DHCP服务器来管理网络参数的分配,这种方案具有容错性。即使在一个仅拥有少量机器的网络中,DHCP仍然是有用的,因为一台机器可以几乎不造成任何影响地被增加到本地网络中。
甚至对于那些很少改变地址的服务器来说,DHCP仍然被建议用来设置它们的地址。如果服务器需要被重新分配地址(RFC2071)的时候,就可以在尽可能少的地方去做这些改动。对于一些设备,如路由器和防火墙,则不应使用DHCP。把TFTP或SSH服务器放在同一台运行DHCP的机器上也是有用的,目的是为了集中管理。
DHCP也可用于直接为服务器和桌面计算机分配地址,并且通过一个PPP代理,也可为拨号及宽带主机,以及住宅NAT网关和路由器分配地址。DHCP一般不适用于使用在无边际路由器和DNS服务器上。
1.4.3 分配方式
在DHCP的工作原理中,DHCP服务器提供了三种IP分配方式:
自动分配(Automatic allocation)、手动分配和动态分配(Dynamic Allocation)。
自动分配:是当DHCP客户端第一次成功的从DHCP服务器获取一个IP地址后,就永久的使用这个IP地址。
手动分配/静态分配:是由DHCP服务器管理员专门指定的IP地址
动态分配:是当客户端第一次从DHCP服务器获取到IP地址后,并非永久使用该地址,每次使用完后,DHCP客户端就需要释放这个IP,供其他客户端使用。
第三种是最常见的使用形式。
1.5 DNS
1.5.1 概述
域名系统(英文:Domain Name System,缩写:DNS)是互联网的一项服务。它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。DNS使用UDP端口53。当前,对于每一级域名长度的限制是63个字符,域名总长度则不能超过253个字符。
域名系统(Domain Name System,DNS)是Internet上解决网上机器命名的一种系统。就像拜访朋友要先知道别人家怎么走一样,Internet上当一台主机要访问另外一台主机时,必须首先获知其地址,TCP/IP中的IP地址是由四段以“.”分开的数字组成(此处以IPv4的地址为例,IPv6的地址同理),记起来总是不如名字那么方便,所以,就采用了域名系统来管理名字和IP的对应关系。
虽然因特网上的节点都可以用IP地址标识,并且可以通过IP地址被访问,但即使是将32位的二进制IP地址写成4个0~255的十位数形式,也依然太长、太难记。因此,人们发明了域名(Domain Name),域名可将一个IP地址关联到一组有意义的字符上去。用户访问一个网站的时候,既可以输入该网站的IP地址,也可以输入其域名,对访问而言,两者是等价的。例如:微软公司的Web服务器的IP地址是207.46.230.229,其对应的域名是www.microsoft.com,不管用户在浏览器中输入的是207.46.230.229还是www.microsoft.com,都可以访问其Web网站。
一个公司的Web网站可看作是它在网上的门户,而域名就相当于其门牌地址,通常域名都使用该公司的名称或简称。例如上面提到的微软公司的域名,类似的还有:IBM公司的域名是www.ibm.com、Oracle公司的域名是www.oracle.com、Cisco公司的域名是www.cisco.com等。当人们要访问一个公司的Web网站,又不知道其确切域名的时候,也总会首先输入其公司名称作为试探。但是,由一个公司的名称或简称构成的域名,也有可能会被其他公司或个人抢注。甚至还有一些公司或个人恶意抢注了大量由知名公司的名称构成的域名,然后再高价转卖给这些公司,以此牟利。已经有一些域名注册纠纷的仲裁措施,但要从源头上控制这类现象,还需要有一套完整的限制机制,这个还没有。所以,尽早注册由自己名称构成的域名应当是任何一个公司或机构,特别是那些著名企业必须重视的事情。有的公司已经对由自己著名品牌构成的域名进行了保护性注册。
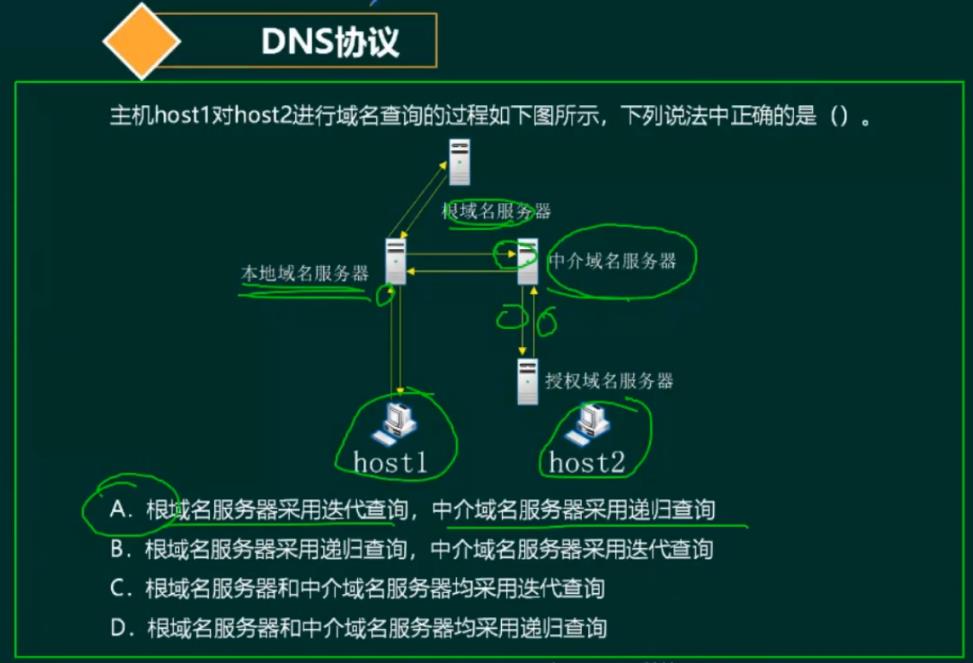
1.5.2 查询过程
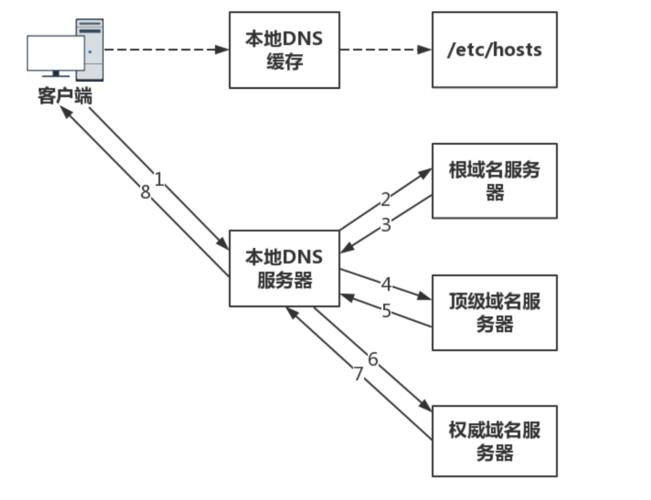
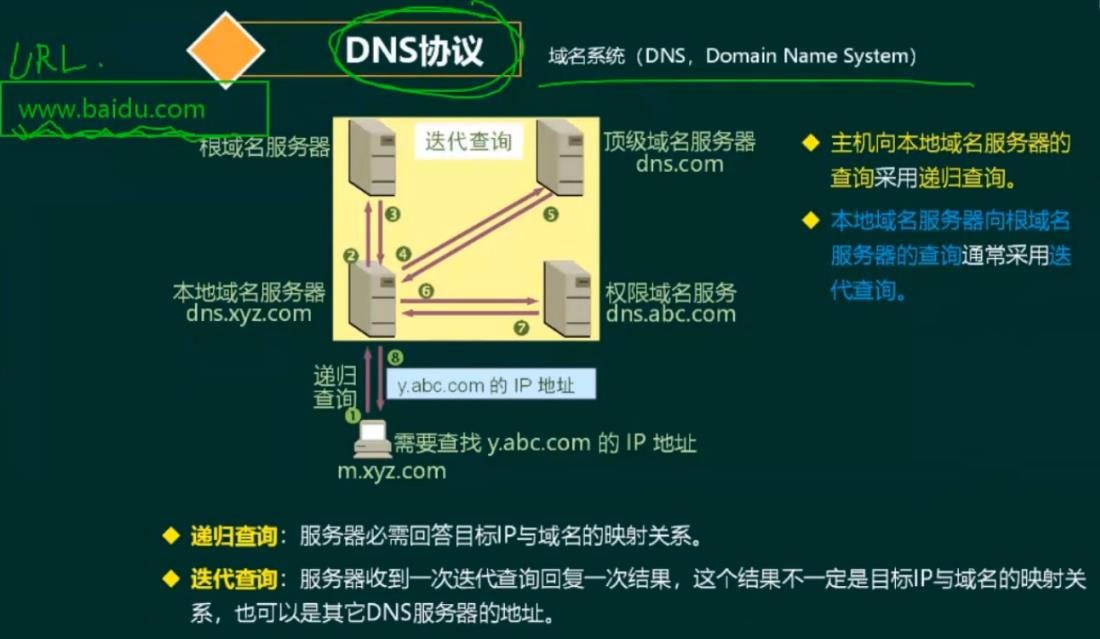
1.5.3 递归与迭代的区别
(1)递归: recursion,递推调用。
递归:想象成一个树结构,从字面可以其理解为重复“递推”和“回归”的过程,当“递推”到达底部时就会开始“回归”,其过程相当于树的深度优先遍历。
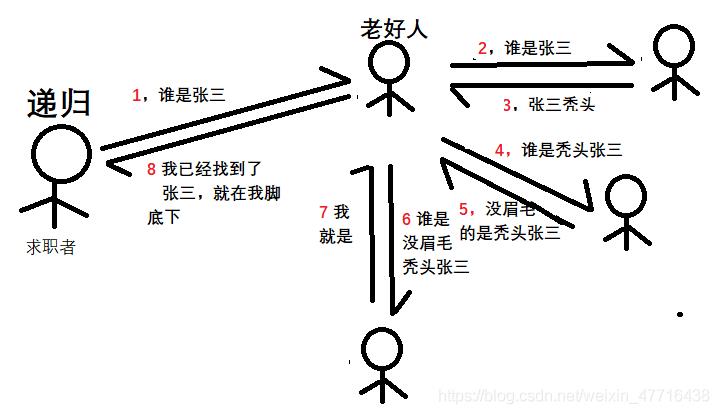
递归就是,每次循环都包含自己的请求,子问题必须携带原始问题,且一次一次缩小范围,最终找到结果。
递归就简单很多了,你还是一个求职者,你进入了一家公司,面前还是50个人,但你这次不需要一个一个自己找人问,你身边有一个老好人,他即使不知道你要找的是哪一个,也不会直接返回值告诉你他不知道,而是会去帮你问别人,注意,迭代里的你是自己去一个一个找,递归里的你,是别人帮你一个一个找,虽然这个老好人返回的结果可能还是找不到谁是张三,但是他有去帮你查找的过程
递归就是,代理执行很多次,每次都能排除一个,直到找到结果,把最终的结果返回给你。
递归是直接向请求者给出答案,至于如何获得答案,是服务者的职责。
这种方式对服务器的能力有很高的压力,加重了服务器的负载。
(2)迭代: Iterative, for 循环调用
迭代:从初始状态开始,每次迭代都遍历这个环,并更新状态,多次迭代直到到达结束状态。这里可以看为 for (i=1 , i<100 , i++)
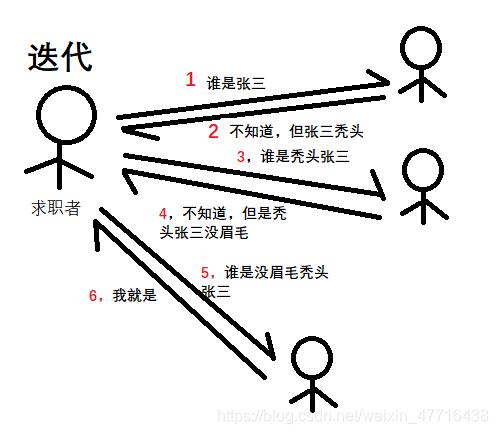
迭代:你现在是一个求职者,你进入了一家公司,你知道你面前50个人里有一个是你要找的HR,但你不知道他长什么样子,只知道他叫“张三”于是你就开始问公司里的其他职员,张三长什么样子,第一个说,张三是秃头,你排除了25个人,第二个说张三没眉毛,你又排除了10个人,经过几遍排除,你终于确定了你要找的目标。
迭代就是,自己执行很多次,每次都能排除一个,直到找到结果。
迭代不是直接向请求者给出答案,而是给出获得答案的下一个方式,至于如何获得答案,是请求者的责任。
1.6 HTTP协议
1.6.1 概述
超文本传输协议(Hyper Text Transfer Protocol,HTTP)是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。请求和响应消息的头以ASCII形式给出;而 [9] 消息内容则具有一个类似MIME的格式。这个简单模型是早期Web成功的有功之臣,因为它使开发和部署非常地直截了当。
HTTP是一个客户端终端(用户)和服务器端(网站)请求和应答的标准(TCP)。通过使用网页浏览器、网络爬虫或者其它的工具,客户端发起一个HTTP请求到服务器上指定端口(默认端口为80)。我们称这个客户端为用户代理程序(user agent)。应答的服务器上存储着一些资源,比如HTML文件和图像。我们称这个应答服务器为源服务器(origin server)。在用户代理和源服务器中间可能存在多个“中间层”,比如代理服务器、网关或者隧道(tunnel)。
尽管TCP/IP协议是互联网上最流行的应用,HTTP协议中,并没有规定必须使用它或它支持的层。事实上,HTTP可以在任何互联网协议上,或其他网络上实现。HTTP假定其下层协议提供可靠的传输。因此,任何能够提供这种保证的协议都可以被其使用。因此也就是其在TCP/IP协议族使用TCP作为其传输层。
通常,由HTTP客户端发起一个请求,创建一个到服务器指定端口(默认是80端口)的TCP连接。HTTP服务器则在那个端口监听客户端的请求。一旦收到请求,服务器会向客户端返回一个状态,比如"HTTP/1.1 200 OK",以及返回的内容,如请求的文件、错误消息、或者其它信息。
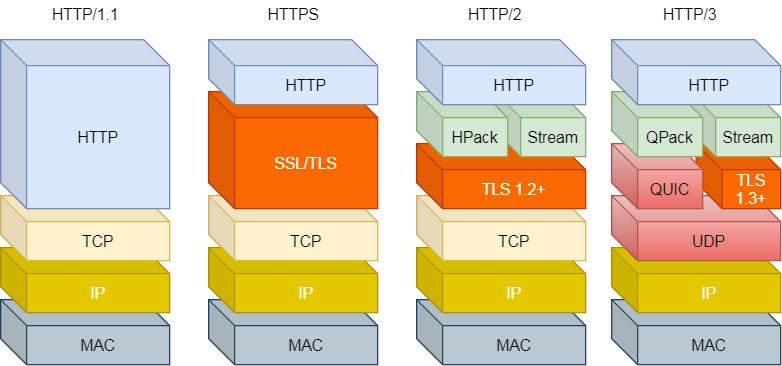
1.6.2 HTTP协议族与对应的协议栈
1.6.3 HTTP工作原理
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
以下是 HTTP 请求/响应的步骤:
(1)客户端连接到Web服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.baidu.com。
(2)发送HTTP请求
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
(3)服务器接受请求并返回HTTP响应
Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
(4)客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
(5)释放连接TCP连接
若connection 模式为close,则每一次请求操作完成后,服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;
若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
1.6.4 HTTP请求方法
HTTP/1.1协议中共定义了八种方法(也叫“动作”)来以不同方式操作指定的资源:
GET
向指定的资源发出“显示”请求。使用GET方法应该只用在读取数据,而不应当被用于产生“副作用”的操作中,例如在Web Application中。其中一个原因是GET可能会被网络蜘蛛等随意访问。
HEAD
与GET方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的Body部分,只传送资源的头信息。
它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中“关于该资源的描述性的信息”(元信息或称元数据)。
POST
向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。
数据被包含在请求本文中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。
PUT
向指定资源位置上传其最新内容。
DELETE
请求服务器删除Request-URI所标识的资源。
TRACE
回传服务器收到的请求,服务器收到请求后,并不处理数据,直接回传,IP层的Ping功能,主要用于测试或诊断。
OPTIONS
这个方法可使服务器传回该资源所支持的所有HTTP请求方法。用'*'来代替资源名称,向Web服务器发送OPTIONS请求,可以测试服务器功能是否正常运作。
CONNECT
HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。通常用于SSL加密服务器的链接(经由非加密的HTTP代理服务器)。
1.6.5 put与post的区别
PUT请求是向服务器端发送数据的,从而改变信息,该请求就像数据库的update操作一样,用来修改数据的内容,但是不会增加数据的种类等,也就是说无论进行多少次PUT操作,其结果并没有不同。
POST请求同PUT请求类似,都是向服务器端发送数据的,但是该请求会改变数据的种类等资源,就像数据库的insert操作一样,会创建新的内容。几乎目前所有的提交操作都是用POST请求的。
就像前面所讲的一样,既然PUT和POST操作都是向服务器端发送数据的,那么两者有什么区别呢。
PUT主要作用在一个具体资源之上的(url/xxx),通俗一下讲就是,如URL可以在客户端确定,那么可使用PUT,否则用POST。
POST主要作用在一个集合资源之上的(url),
综上所述,可理解为以下:
PUT /url/xxx 更新
POST /url 创建
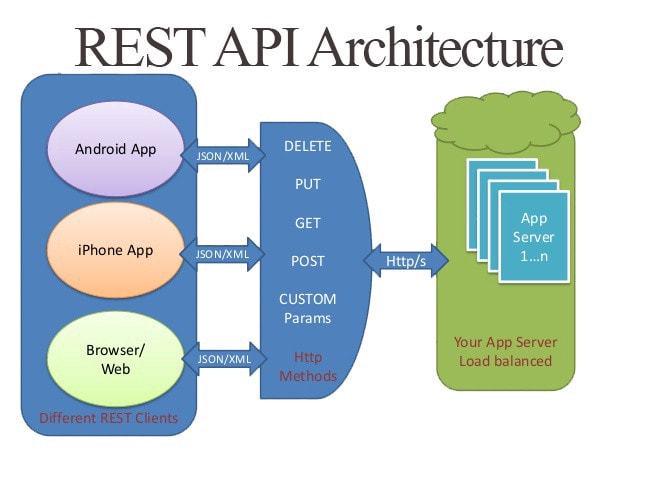
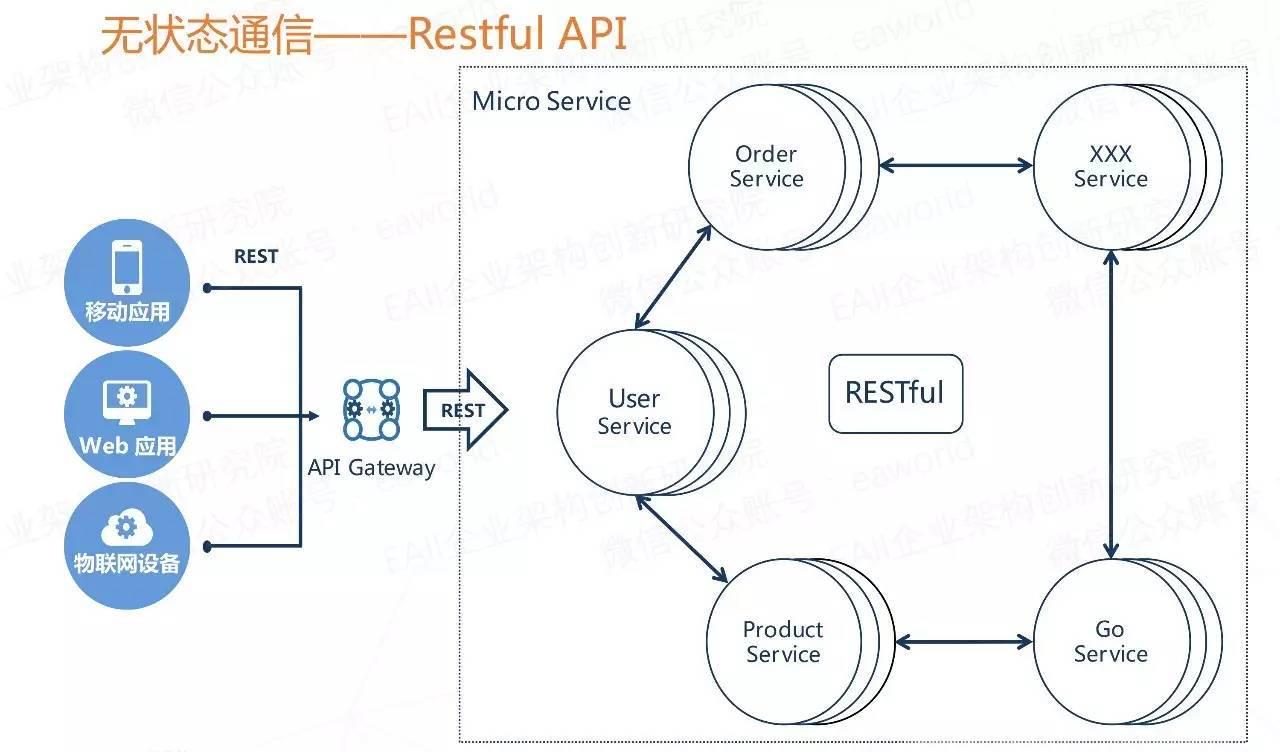
1.7 RESTFUL
1.7.1 概述
RESTFUL是一种网络应用程序的设计风格和开发方式,基于HTTP,可以使用XML格式定义或JSON格式定义。
RESTFUL适用于移动互联网厂商作为业务接口的场景,实现第三方OTT调用移动网络资源的功能,动作类型为新增、变更、删除所调用资源。
REST(英文:Representational State Transfer,简称REST)描述了一个架构样式的网络系统,比如 web 应用程序。它首次出现在 2000 年 Roy Fielding 的博士论文中,Roy Fielding是 HTTP 规范的主要编写者之一。在目前主流的三种Web服务交互方案中,REST相比于SOAP(Simple Object Access protocol,简单对象访问协议)以及XML-RPC更加简单明了,无论是对URL的处理还是对Payload的编码,REST都倾向于用更加简单轻量的方法设计和实现。值得注意的是REST并没有一个明确的标准,而更像是一种设计的风格。
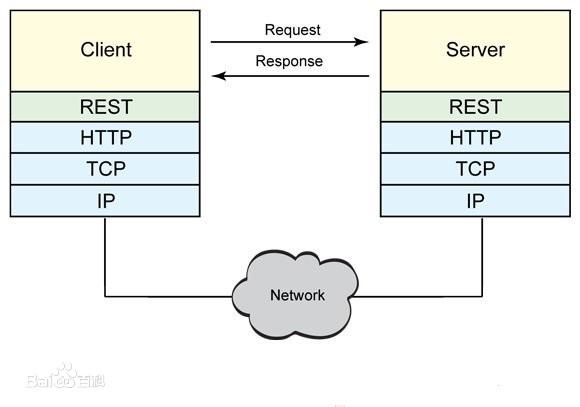
1.7.2 协议栈
1.7.3 原则条件
REST 指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是 RESTful。
Web 应用程序最重要的 REST 原则是:客户端和服务器之间的交互在请求之间是无状态的。从客户端到服务器的每个请求都必须包含理解请求所必需的全部信息。如果服务器在请求之间的任何时间点重启,客户端不会得到通知。此外,无状态请求可以由任何可用服务器回答,这十分适合云计算之类的分布式应用环境。客户端可以缓存数据以改进性能,也即说由应用程序记录状态。
在服务器端,应用程序状态和功能可以分为各种资源。资源是一个有趣的概念实体,它向客户端公开。资源的例子有:应用程序对象、数据库记录、算法等等。每个资源都使用 URI (Universal Resource Identifier) 得到一个唯一的地址。所有资源都共享统一的接口,以便在客户端和服务器之间传输状态。
使用的是标准的 HTTP 方法,比如 GET、PUT、POST 和 DELETE。Hypermedia 是应用程序状态的引擎,资源表示通过超链接互联。
1.7.4 RESTFUL 架构
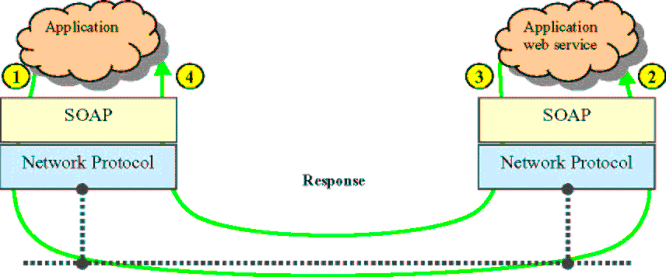
1.8 简单对象访问协议 SOAP
1.8.1 概述
简单对象访问协议是交换数据的一种协议规范,是一种轻量的、简单的、基于XML(标准通用标记语言下的一个子集)的协议,它被设计成在WEB上交换结构化的和固化的信息。
1.8.2 协议栈