动态物体追踪
Posted 九院不知名高手-猫吃耗子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了动态物体追踪相关的知识,希望对你有一定的参考价值。
动态物体追踪
闲话
我个人是比较喜欢捣鼓一些程序设计,算法之类的。但毕竟是人工智能专业的,电子类大赛也必须去打,起初是导师让我来打这个比赛,后面发现还是很有挑战,很有意思的。一开始我对全国大学生电子设计大赛真的一点不懂,之前也没了解过。后来听导师说,我们团队做的都是些控制类题,这我还算能接受。如果纯硬件,让我画电路,那我水平真的不太行。
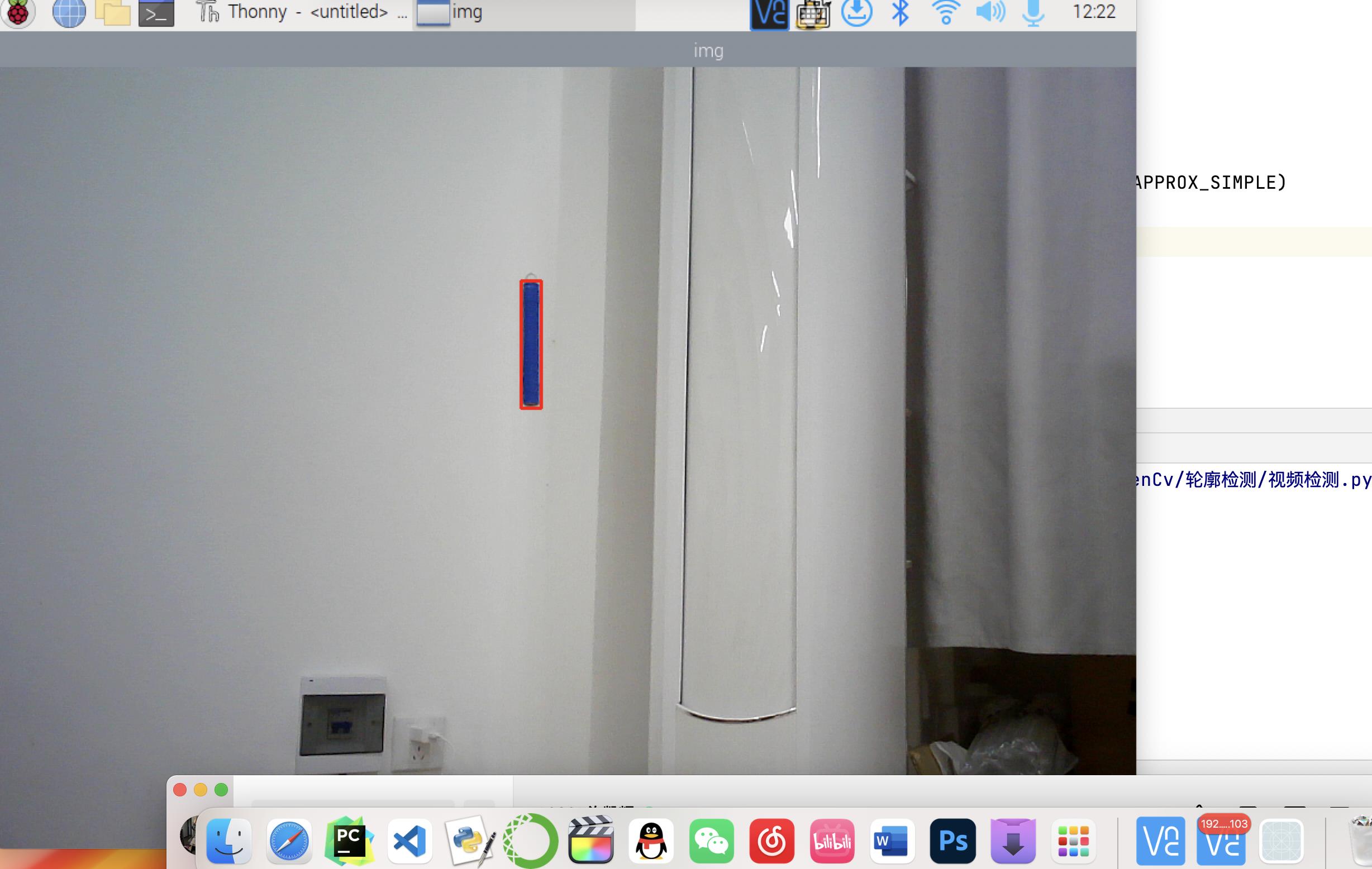
我拿到的是2021年国赛题——基于互联网的摄像测量系统。要求(1)是做两个独立摄像头出来,我直接用树莓派连摄像头,这也很简单。之前我也给树莓派装了系统,并且在树莓派里面装了OpenCV,后面肯定会用到机器视觉。要求(2)就是我这篇要写到的,两个摄像节点要实时检测摆动的激光笔,然后把激光笔的轮廓检测到并框出。
我一开始觉得,这也太没难度了吧,我随便一个二值化处理,然后对比度框一下。可是我看题目看到后面的时候我发现事情没那么简单!说明(4)中有一句话:拍摄背景为一般实验室场景,背景物体静止即可,不得要求额外处理;如果实验室背景很嘈杂的话,我的激光笔不是比较难检测,我用二值化处理了一下,果然并没有把背景和激光笔区分出来,我后续一顿操作都没有好的结果,虽然能把笔检测出来,但是如果有和笔相似的像素也会被误判。
然后我尝试用内置函数轮廓检测直接去用drawCoutours()画出来轮廓,效果不太行,还是那句话,背景太杂了,检测的轮廓太多了,检测的结果不是单一的激光笔。如果背景是纯白的话,那确实没什么难度!可惜如果背景嘈杂的话,检测一个物体还要精准的框出来确实不是那么容易。
之后我尝试读取视频的第一帧,把笔的样子保存下来,然后去匹配笔,实现单目标匹配。效果虽然还行,但是不确定太大了,如果是在比赛,匹配的结果不是那么好,直接原地退役。毕竟后面要算激光笔的摆长和角度。在检测上面不能有误差。
后面我找到一种比较好的方法,就是两帧画面作差。因为激光笔是不断摆动的,背景都是静止的,那差出来的像素就是激光笔的像素,然后我去把它用findCountours()框起来!这个效果在本地实现起来是很好的。然后我就去码通信部分了,我就用socket写了个客户端和服务端。然后发现大问题了!因为用的是帧差法,如果通信有一点网络波动两帧差的比较多,那么框出来的框就特别的“大“。如果出现这种情况,那误差……如果在本地的话我觉得这种方法真的是最优了!不管再多嘈杂的环境都没什么影响,就算放一万支一模一样的激光笔,我也能检测出动的那一支。只是有点可惜通信的话,不能采用这个方法。
后面我问了下学长,学长说背景肯定要是白色的呀,我当时的心情……我辛苦那么久想去处理背景的问题,没想到比赛的时候背景肯定要是全白!
那我还是回归老方法,直接去用内置函数去检测轮廓,不过有几个小细节。框的时候,如果有面积太小或者太大的噪点,直接给它Pass掉。还有就是检测的轮廓如果长宽比不是像笔那样的比例,也Pass掉。这样误差几乎降为0。
匹配法(效果差)
代码给我删掉了,不贴出来了
帧差法(本机效果好)
import cv2
def fitter_img(frame):
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 转成灰度图像
blur = cv2.GaussianBlur(gray, (5, 5), 0) # 高斯模糊
t, thresh = cv2.threshold(blur, 20, 255, cv2.THRESH_BINARY) # 二值化
dilated = cv2.dilate(thresh, None, iterations=3) # 膨胀
return dilated
cap = cv2.VideoCapture(0)
ret, frame1 = cap.read()
ret, frame2 = cap.read()
while cap.isOpened():
diff = cv2.absdiff(frame1,frame2)
mask = fitter_img(diff)
# 寻找轮廓
contours, her = cv2.findContours(mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
for i in contours:
x, y, w, h = cv2.boundingRect(i)
if cv2.contourArea(i) < 200:
continue
cv2.rectangle(frame1, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.imshow("diff", diff)
cv2.imshow("frame1", frame1)
# cv2.imshow("mask", mask)
# 前面一帧转成后面一帧
frame1 = frame2
ret, frame2 = cap.read()
if cv2.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
cv2.destroyAllWindows()
直接检测轮廓
这段代码我直接写在socket的服务端的,我直接贴出来。
import socket
import time
import cv2
import numpy
def ReceiveVideo():
# IP地址\'0.0.0.0\'为等待客户端连接
address = (\'0.0.0.0\', 8002)
# 建立socket对象,参数意义见https://blog.csdn.net/rebelqsp/article/details/22109925
# socket.AF_INET:服务器之间网络通信
# socket.SOCK_STREAM:流式socket , for TCP
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 将套接字绑定到地址, 在AF_INET下,以元组(host,port)的形式表示地址.
s.bind(address)
# 开始监听TCP传入连接。参数指定在拒绝连接之前,操作系统可以挂起的最大连接数量。该值至少为1,大部分应用程序设为5就可以了。
s.listen(1)
def recvall(sock, count):
buf = b\'\' # buf是一个byte类型
while count:
# 接受TCP套接字的数据。数据以字符串形式返回,count指定要接收的最大数据量.
newbuf = sock.recv(count)
if not newbuf: return None
buf += newbuf
count -= len(newbuf)
return buf
# 接受TCP连接并返回(conn,address),其中conn是新的套接字对象,可以用来接收和发送数据。addr是连接客户端的地址。
# 没有连接则等待有连接
conn, addr = s.accept()
print(\'connect from:\' + str(addr))
while 1:
start = time.time() # 用于计算帧率信息
length = recvall(conn, 16) # 获得图片文件的长度,16代表获取长度
stringData = recvall(conn, int(length)) # 根据获得的文件长度,获取图片文件
data = numpy.frombuffer(stringData, numpy.uint8) # 将获取到的字符流数据转换成1维数组
decimg = cv2.imdecode(data, cv2.IMREAD_COLOR) # 将数组解码成图像
# cv2.imshow(\'SERVER\', decimg) # 显示图像
img = decimg
# 进行下一步处理
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
t, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
coutours, h = cv2.findContours(binary, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
for i in coutours:
# 排除掉面积过大或过小的区域
if cv2.contourArea(i) < 1000 or cv2.contourArea(i) > 5000:
continue
x, y, w, h = cv2.boundingRect(i)
# 排除不正确的面积比
if h < 2 * w or h > 8 * w: continue
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.imshow("img", img)
# 将帧率信息回传,主要目的是测试可以双向通信
end = time.time()
seconds = end - start
fps = 1 / seconds;
conn.send(bytes(str(int(fps)), encoding=\'utf-8\'))
k = cv2.waitKey(30) & 0xff
if k == ord(\'q\'):
break
s.close()
cv2.destroyAllWindows()
if __name__ == \'__main__\':
ReceiveVideo()
客户端代码
上面有服务端的代码,怎么能少了客户端的呢?
import socket
import cv2
import numpy
import time
import sys
def SendVideo():
# 建立sock连接
# address要连接的服务器IP地址和端口号
address = (\'192.168.31.110\', 8002)
try:
# 建立socket对象,参数意义见https://blog.csdn.net/rebelqsp/article/details/22109925
# socket.AF_INET:服务器之间网络通信
# socket.SOCK_STREAM:流式socket , for TCP
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 开启连接
sock.connect(address)
except socket.error as msg:
print(msg)
sys.exit(1)
# 建立图像读取对象
capture = cv2.VideoCapture(0)
# 读取一帧图像,读取成功:ret=1 frame=读取到的一帧图像;读取失败:ret=0
ret, frame = capture.read()
# 压缩参数,后面cv2.imencode将会用到,对于jpeg来说,15代表图像质量,越高代表图像质量越好为 0-100,默认95
encode_param = [int(cv2.IMWRITE_JPEG_QUALITY), 15]
while ret:
# 停止0.1S 防止发送过快服务的处理不过来,如果服务端的处理很多,那么应该加大这个值
time.sleep(0.01)
# cv2.imencode将图片格式转换(编码)成流数据,赋值到内存缓存中;主要用于图像数据格式的压缩,方便网络传输
# \'.jpg\'表示将图片按照jpg格式编码。
result, imgencode = cv2.imencode(\'.jpg\', frame, encode_param)
# 建立矩阵
data = numpy.array(imgencode)
# 将numpy矩阵转换成字符形式,以便在网络中传输
stringData = data.tostring()
# 先发送要发送的数据的长度
# ljust() 方法返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串
sock.send(str.encode(str(len(stringData)).ljust(16)));
# 发送数据
sock.send(stringData);
# 读取服务器返回值
receive = sock.recv(1024)
if len(receive): print(str(receive, encoding=\'utf-8\'))
# 读取下一帧图片
ret, frame = capture.read()
if cv2.waitKey(10) == 27:
break
sock.close()
if __name__ == \'__main__\':
SendVideo()
总结
其实我当时想这个背景问题,想了很久,用了10几种方法吧,但是其他的方法简直太不科学了!还是老老实实用库函数吧!不过我真的是喜欢帧差法,效果真的很棒!可惜通信太拉了!
效果图
物体追踪实战:使用 OpenCV实现对指定颜色的物体追踪
本文实现对特定颜色的物体追踪,我实验用的是绿萝的树叶。
新建脚本ball_tracking.py,加入代码:
import argparse
from collections import deque
import cv2
import numpy as np
导入必要的包,然后定义一些函数
def grab_contours(cnts):
# 如果 cv2.findContours 返回的轮廓元组的长度为“2”,那么我们使用的是 OpenCV v2.4、v4-beta 或 v4-official
if len(cnts) == 2:
cnts = cnts[0]
# 如果轮廓元组的长度为“3”,那么我们使用的是 OpenCV v3、v4-pre 或 v4-alpha
elif len(cnts) == 3:
cnts = cnts[1]
else:
raise Exception(("Contours tuple must have length 2 or 3, "
"otherwise OpenCV changed their cv2.findContours return "
"signature yet again. Refer to OpenCV's documentation "
"in that case"))
return cnts
def resize(image, width=None, height=None, inter=cv2.INTER_AREA):
dim = None
(h, w) = image.shape[:2]
# 如果高和宽为None则直接返回
if width is None and height is None:
return image
# 检查宽是否是None
if width is None:
# 计算高度的比例并并按照比例计算宽度
r = height / float(h)
dim = (int(w * r), height)
# 高为None
else:
# 计算宽度比例,并计算高度
r = width / float(w)
dim = (width, int(h * r))
resized = cv2.resize(image, dim, interpolation=inter)
# return the resized image
return resized
grab_contours 对于opencv不同版本做了兼容处理。
resize等比例改变图片的大小。
命令行参数
ap = argparse.ArgumentParser()
ap.add_argument("-v", "--video", help="path to video")
ap.add_argument("-b", "--buffer", type=int, default=64, help="max buffer size")
args = vars(ap.parse_args())
# 绿色树叶的HSV色域空间范围
greenLower = (29, 86, 6)
greenUpper = (64, 255, 255)
pts = deque(maxlen=args["buffer"])
vs = cv2.VideoCapture(0)
fps = 30 #保存视频的FPS,可以适当调整
size=(600,450)
fourcc=cv2.VideoWriter_fourcc(*'XVID')
videowrite=cv2.VideoWriter('output.avi',fourcc,fps,size)
定义参数
–video :视频文件的路径或者摄像头的id
–buffer 是 deque 的最大大小,它维护我们正在跟踪的球的先前 (x, y) 坐标列表。 这个双端队列允许我们绘制球的“轨迹”,详细说明它过去的位置。 较小的队列将导致较短的尾部,而较大的队列将产生较长的尾部
定义hsv空间的上限和下限
启动摄像头0
最后是保存定义VideoWriter对象,实现对视频的写入功能
while True:
ret_val, frame = vs.read()
if ret_val is False:
break
frame = resize(frame, width=600)
# 通过高斯滤波去除掉一些高频噪声,使得重要的数据更加突出
blurred = cv2.GaussianBlur(frame, (11, 11), 0)
# 将图片转为HSV
hsv = cv2.cvtColor(blurred, cv2.COLOR_BGR2HSV)
# inRange的作用是根据阈值进行二值化:阈值内的像素设置为白色(255),阈值外的设置为黑色(0)
mask = cv2.inRange(hsv, greenLower, greenUpper)
# 腐蚀(erode)和膨胀(dilate)的作用:
# 1. 消除噪声;
# 2. 分割(isolate)独立的图像元素,以及连接(join)相邻的元素;
# 3. 寻找图像中的明显的极大值区域或极小值区域
mask = cv2.erode(mask, None, iterations=2)
mask = cv2.dilate(mask, None, iterations=2)
开启一个循环,该循环将一直持续到 (1) 我们按下 q 键,表明我们要终止脚本或 (2) 我们的视频文件到达终点并用完帧。
读取一帧,返回两个参数,第一个参数是否成功,第二个参数是一帧图像。
如果失败则break。
对图像进行了一些预处理。首先,我们将框架的大小调整为 600 像素的宽度。缩小帧使我们能够更快地处理帧,从而提高 FPS(因为我们要处理的图像数据更少)。然后我们将模糊框架以减少高频噪声,并使我们能够专注于框架内的结构物体,例如球。最后,我们将帧转换为 HSV 颜色空间。
通过调用 cv2.inRange 处理帧中绿球的实际定位。首先为绿色提供下 HSV 颜色边界,然后是上 HSV 边界。 cv2.inRange 的输出是一个二进制掩码,

# 寻找轮廓,不同opencv的版本cv2.findContours返回格式有区别,所以调用了一下imutils.grab_contours做了一些兼容性处理
cnts = cv2.findContours(mask.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = grab_contours(cnts)
center = None
# only proceed if at least one contour was found
if len(cnts) > 0:
# find the largest contour in the mask, then use it to compute the minimum enclosing circle
# and centroid
c = max(cnts, key=cv2.contourArea)
((x, y), radius) = cv2.minEnclosingCircle(c)
M = cv2.moments(c)
# 对于01二值化的图像,m00即为轮廓的面积, 一下公式用于计算中心距
center = (int(M["m10"] / M["m00"]), int(M["m01"] / M["m00"]))
# only proceed if the radius meets a minimum size
if radius > 10:
# draw the circle and centroid on the frame, then update the list of tracked points
cv2.circle(frame, (int(x), int(y)), int(radius), (0, 255, 255), 2)
cv2.circle(frame, center, 5, (0, 0, 255), -1)
pts.appendleft(center)
for i in range(1, len(pts)):
# if either of the tracked points are None, ignore them
if pts[i - 1] is None or pts[i] is None:
continue
# compute the thickness of the line and draw the connecting line
thickness = int(np.sqrt(args["buffer"] / float(i + 1)) * 2.5)
cv2.line(frame, pts[i - 1], pts[i], (0, 0, 255), thickness)
cv2.imshow("Frame", frame)
videowrite.write(frame)
key = cv2.waitKey(1) & 0xFF
if key == ord("q"):
break
videowrite.release()
vs.release()
cv2.destroyAllWindows()
计算图像中对象的轮廓。在接下来的行中,将球的中心 (x, y) 坐标初始化为 None。
检查以确保在掩码中至少找到一个轮廓。假设至少找到一个轮廓,找到 cnts 列表中最大的轮廓,计算 blob 的最小包围圆,然后计算中心 (x, y) 坐标(即“质心”)。
快速检查以确保最小包围圆的半径足够大。如果半径通过测试,我们然后画两个圆圈:一个围绕球本身,另一个表示球的质心。
然后,将质心附加到 pts 列表中。
循环遍历每个 pts。如果当前点或前一个点为 None(表示在该给定帧中没有成功检测到球),那么我们忽略当前索引继续循环遍历 pts。
如果两个点都有效,我们计算轨迹的厚度,然后将其绘制在框架上。
运行结果:
以上是关于动态物体追踪的主要内容,如果未能解决你的问题,请参考以下文章