KubeVela 稳定性及可扩展性评估
Posted 阿里系统软件技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KubeVela 稳定性及可扩展性评估相关的知识,希望对你有一定的参考价值。
作者:殷达
背景
随着 v1.8 的发布,基于 OAM 的应用程序交付项目 KubeVela 已经持续发展了 3 年多。目前已被各种组织采用并部署在生产环境中。无论是与托管定义一起使用还是在多个集群上进行管理,在单个 KubeVela 控制平面上运行数千个应用程序的情况并不少见。用户经常问的一个关键问题是 KubeVela 能否承载一定数量的应用程序。 为了回答这个问题,KubeVela 进行了负载测试实验,制定了性能调优策略,并为关心 KubeVela 稳定性和可扩展性的用户总结了本指南,以供各位参考。
概述
若需要寻求一个基准,如下简要的表格仅供参考。

尽管以上数据可能因各种因素(如应用程序大小)而有所不同,但此基准适用于大多数常见场景。
历史

KubeVela 负载测试历史
KubeVela 过去进行了多次负载测试:
1. 2021 年 8 月对简单应用进行了负载测试。这次负载测试验证了节点数量不影响 KubeVela v1.0 的性能。它在一个拥有 1 千个虚拟节点和 1.2 万个应用程序的单个集群上进行了测试。这表明 Kubernetes apiserver 的速率限制是 KubeVela 核心控制器的瓶颈之一。目前为止,负载测试数据被视为标准基准。参考文献 [ 1] 。
它有以下几个限制:
a.不包括在 v1.1 中发布的多集群和工作流。
b.仅测试应用程序的创建和状态保持,忽略应用程序的持续更新。
2. *2022 年 2 月 v1.2 版本对基于工作流的应用程序*(workflow-based application)进行的负载测试。此次负载测试主要侧重于如何在特定场景中微调应用程序控制器的性能,例如不需要 ApplicationRevision 的情况。开发几个可选的优化标志,并证明去掉某些功能以将性能提高 250% 以上。
3. *2022 年 8 月 v1.6 版本对工作流引* 擎(workflow engine)进行的负载测试。这次负载测试是在 KubeVela 将 cue 引擎从 v0.2 升级到 v0.4 时完成的。它主要发现了一些不必要的 cue 值初始化操作,这将导致额外的 CPU 使用成本。通过减少 75% 的 CPU 使用量进行修复。
*4. *2023 年 2 月对 KubeVela v1.8 进行的负载测试,下面将详细介绍。本次负载测试在简单应用程序、大型应用程序、多个分片、多个集群、持续更新等多个场景下进行。同时应用了几种优化方法来处理一般情况。
全面指南
Part 01. 初期
KubeVela 应用的基本流程

KubeVela 应用的基本流程
KubeVela 应用通常是 KubeVela 生态系统中最常用的对象。它由 vela-core 内部的应用程序控制器处理,并将使用集群网关进行多集群交付。KubeVela 应用正常处理主要流程如下:
- 用户通过 VelaCLI、kubectl、REST API、VelaUX 等向控制平面上的 Kubernetes apiserver 发送创建/更新/删除应用程序请求。
- 请求发送到变异 Webhook 并验证 Webhook 以进行验证和字段自动填充。
- 存储在 etcd 中的应用程序对象。vela-core 的 informer 接收到应用的创建/更新/删除事件,将其推送到队列中。
- vela-core 的应用控制器观察事件并开始协调。
- 对于新的应用程序,应用程序控制器会为其打上 Finalizer。
- 控制器计算应用程序的当前版本并在集群中创建/更新它。
- 控制器执行以工作流程为条件的工作流,运行状态维护和垃圾回收,最后,更新应用程序的状态。
应用程序工作流主要执行资源调度,为分析性能瓶颈并找到应对措施,因此有必要对整个处理流程进行概述。
如何配置高性能和鲁棒的 KubeVela?
除安装 KubeVela 之外,还有一些步骤建议用于设置高性能和鲁棒的 KubeVela 控制平面。请注意,这些步骤对于正常使用 KubeVela 并不是强制的,它们主要用于大规模场景,比如承载 2 千多个应用程序。
*1. *启用可观测性插件。要全面了解您的 KubeVela 控制平面,强烈建议安装可观测性插件,包括 kube-state-metrics,prometheus-server 和 grafana。
a.如果您已拥有这些基础设施,并且它们不是由 KubeVela 插件构建的,则可以将 Grafana 仪表板 [ 2] 安装到您的 Grafana 中,并获取类似于 KubeVela 系统仪表板的内容。

KubeVela 系统仪表板
b.启用这些插件需要一些额外的计算资源,如 CPU 和内存。
*2. *删除 Webhook。目前 KubeVela 的 Webhook 大大增加了应用程序变更请求的响应延迟。如果您已经安装了 KubeVela,请运行 kubectl delete mutatingwebhookconfiguration kubevela-vela-core-admission 和 kubectl delete validatingwebhookconfiguration kubevela-vela-core-admission 否则,添加 --set admissionWebhooks。
此步骤的负面影响包括以下几点:
a.无效应用程序在创建或更新期间不会被拒绝。相反,它将报告应用程序状态中的错误。
b.自动身份验证将会失效。替代方案是在应用程序应用时为其指定身份注释。
c.自动分片调度将会失效。替代方案是在应用程序应用时为其分配预定分片 ID。
*3. *【可选】启用 KubeVela 的多分片功能。通过使用 --set sharding.enabled=true 安装,并启用 vela-core-shard-manager 插件,可以运行多个分片(从 v1.8.0 开始)。通过分片,您可以对控制平面进行横向扩展,且不影响任何现有应用程序。
a.如果您在第 2 步中删除了 Webhook,则需要手动将应用程序的标签 controller.core.oam.dev/shard-id 设置为分片 ID(默认可以设置为 master 或 shard-0)。如果您没有删除 Webhook,应用程序将被平均分配。
b.vela-core-shard-manager 将使用相同的镜像、参数等从主分片中复制配置。如果您想使用不同参数,可以手动更改。
c.如果您没有大量的应用程序(10k+),并且您不需要对不同的应用程序进行隔离(例如按租户对他们进行分组),则不一定需要此步骤来实现高性能。

KubeVela 控制器分片架构
*4. *【推荐】如果可能,请在控制平面和托管的集群之间使用内网连接。建议参考此提示,但并不总是可行的。如果您的托管集群与 KubeVela 控制平面处于不同的网络区域(例如不同的地区或不同的云提供商),则无法执行此操作。内网带宽通常比互联网带宽更高,延迟也更低。因此,使用内网连接可以帮您获得更高的吞吐量和更快的跨集群请求响应速度。
如何进行负载测试

使用 KubeVela 进行负载测试的工具
在 Kubernetes 集群上设置 KubeVela 控制平面后,您可以尝试负载测试,查看您的 KubeVela 控制平面配置是否能满足您的业务需求。您可以根据使用场景从以下步骤开始。
*1. *【可选】设置 kubemark 来模拟 Kubernetes 节点。KubeVela 与 Kubernetes 集群的节点数无关,但如果你想尝试并验证这一点,可以使用 kubemark 模拟 Kubernetes 节点,这样允许你在不实际运行的情况下持有大量的 Pod。
a.每个 kubemark pod 都会向 Kubernetes apiserver 注册一个空节点,并将自己注册为一个节点,在此节点上分配的 Pod 不会实际执行,而是伪装自己正在运行。
b.你需要为这些空节点附加标签,并为负载测试创建的 Pod 设置节点亲和性。否则,它们可能会被分配到真实节点并实际运行,这将在负载测试期间产生巨大工作量,你应该避免这种情况。
c.你还应将污点附加到这些空节点,并为负载测试创建的 Pod 添加污点容忍。这样是为了防止将其他 Pod 分配到这些虚假节点上。例如,如果你在 Kubernetes 集群中将 Prometheus 服务器作为 Pod 运行以构建可观观测性,当它们被分配到空节点时,则不会实际运行,你将一无所获。
d.通常,一个 Kubernetes 集群中的每个节点最多可容纳数百个 Pod(这个数字在不同的配置中也有所不同),因此我们建议不要在每个空节点上运行太多的 Pod。20~40 个 Pod /节点可能是一个不错的选择。根据你想在负载测试中测试的 Pod 数量,应计算所需的空节点数。然后请记住,每个空节点都需要一个真正的 kubemark pod 来运行,因此您需要进一步估计运行一定数量的 kubemark pods 需要多少个真实节点。
e.结论:KubeVela 对一个集群的 1 千个空节点进行了负载测试,并验证了这个数字不会影响 KubeVela 的运行。有关更多实验细节,请参阅报告 [ 3] 。
*2. *【可选】设置 k3d/KinD 以模拟托管集群。KubeVela 与加入到控制平面的集群数也无关,除非您有超过数千个 Kubernetes 集群可供使用。如果您想验证这个事实,你可以设置 k3d 集群或 KinD 集群来模拟托管集群,并将它们加入到你的 KubeVela 控制平面。
a.托管集群使用的主要组件是 apiserver 和 etcd 。如果您不需要同时验证多个 pod 或节点的数量,则只需少量资源即可运行模拟的托管集群。就像您可以在 128 核 256 Gi 服务器上运行 200 多个 k3d 集群,并将它们加入到 KubeVela 控制平面中。
b.您可以为这些已加入的集群附加标签,并在应用程序交付期间测试选择集群的性能。例如,为每 5 个集群分配一个区域 ID。
c.托管集群上不会有实际负载运行(因为 KubeVela 主要关心应用交付,因此在多集群负载测试期间,我们主要调度零副本部署、configmaps 和 secrets)。但网络很重要,集群网关和托管集群的 apiserver 之间将有大量网络请求。因此,最好确保它们之间有足够的网络带宽和相对适中的延迟。否则,您将观察到网络 IO 速率限制。
d.结论:KubeVela 还对 200 个集群进行了负载测试,这些集群被均匀分布在 40 个区域。结果表明,控制平面能够以适当的配置处理这些集群上的应用程序。下面将进一步详细阐述。
*3. *使用脚本交付大量应用程序。有一个关于使用官方脚本部署负载测试应用程序的简单指南 [ 4] 。这些脚本会自动在多个并发线程中部署多个应用程序。它包含多个要设置的环境变量,包括要读取的应用程序模板、应用程序版本、应用程序的分片 ID 和集群 ID 等。您可以为负载测试创建自己的应用程序模板,并使用脚本进行实验。KubeVela 使用该脚本测试各种示例应用程序,并获取负载测试统计数据。
Part 02. 性能优化
在 KubeVela v1.8 中,我们添加了几种优化方法来提高应用程序控制器的性能。这些方法是通过实验完成的。
状态保持并行化
在 KubeVela v1.8 之前,应用程序的状态保持阶段,应用背后的资源是以逐一的状态保存的。我们将并行化添加到这个过程中,最大并发数为 5 。这会将状态保持的性能提高约 30%+,具体取决于每个应用程序需要保留的资源数量。

优化前后的状态保持时间消耗
参考链接:
https://github.com/kubevela/kubevela/pull/5504
为列表操作索引 AppKey
通过对 5 万多个应用程序的应用控制器进行 pprof 监视,我们发现大部分 CPU 时间都花在列举 ApplicationRevisions 和 ResourceTrackers 上。

KubeVela 核心控制器 CPU 使用情况火焰图
这是因为当我们需要为一个应用程序查找这些资源时,我们用标签选择器选出相匹配的资源。但在控制器运行时 controller-runtime 的 informer下,这是通过匹配每个对象的标签来完成的。我们通过为缓存添加额外的索引来优化它,这大大减少了列出应用程序和资源跟踪器所需的时间成本。对于单列表操作,时间成本从 40 毫秒降至 25 微秒,这是优化前状态保持的一个瓶颈。

优化前和优化后的对账指标
参考链接:
https://github.com/kubevela/kubevela/pull/5572
过滤不必要的更新
当一个应用程序达到稳定状态(已发布且没有进行中的更新或删除)时,每个协调操作的主要工作是探测底层资源并检测意外的偏移。通常,配置偏移不总是发生,因此我们不需要向底层资源发送空的补丁请求。我们观察到这可以将协调时间缩短 20%。

应用程序控制器和每个阶段的对账时间
此外,我们发现应用程序控制器的每次协调都会发出应用修订更新请求。然而,一旦工作流成功执行,应用修订就不会更新。因此,这些更新请求无需删除这些请求就可以在负载测试期间将性能提升 27%。

优化前(19:50之前)和优化后应用程序控制器的对账时间对比
类似的问题是,从 v1.6 开始升级工作流后,状态被压缩,但垃圾回收的执行没有被去重。因此,当删除重复的 gc 进程,应用程序进入稳定状态时,我们进一步实现了 23% 的性能优化,此时优化了应用程序控制器的运行。
参考链接:
直接连接到集群网关
在研究将资源交付到托管集群的应用程序时,我们会发现集群网关(cluster-gateway)成了另一个潜在的瓶颈。默认情况下,多集群请求是沿着 vela-core -> kubernetes apiserver (hub) -> cluster-gateway -> kubernetes apiserver (managed) 的流程进行。这是通过利用 Kubernetes 的聚合 API 机制完成的,我们可以通过允许应用程序控制器直接与集群网关通信来进行优化。

KubeVela 的多集群连接架构
这不仅能减轻 Kubernetes apiserver 的负担,还能减少多集群请求的网络跳数。通过这种方法我们减少了 40% 的延迟。

应用程序控制器的一个多集群请求延迟从 11 毫秒降到 6 毫秒
参考链接:
https://github.com/kubevela/kubevela/pull/5595
Informer cache 减少
默认的 controller-runtime informer 将缓存我们在控制器中使用的所有结构化对象。对 KubeVela 而言,这些对象是Application,ApplicationRevision,ResourceTracker 和 ConfigMap。通过控制器分片,KubeVela 能够将Application,ApplicationRevision 和 ResourceTracker 的缓存分成不同的分片。但随着应用程序的不断更新,累积的ApplicationRevision 会通过 informer cache 占用大量内存,尽管它们并不经常使用且内部有大量重复数据。因此,为了优化 informer cache 的大小,我们采取了以下几种方法。
1. 在将 managedFields 和 kubectl.kubernetes.io/last-applied-configuration 存储在 informer 中时,需要删除 managedFields 和 kubectl.kubernetes.io/last-applied-configuration。特别是对于复杂应用程序,它们可能会很大。它们或许对于 Kubernetes apiserver 和 CLI 工具很有用,但控制器中并不需要。因此在存储到缓存之前,我们需要在控制器中将它们删除。
2. 通过共享 ComponentDefinition、TraitDefinition 和 WorkflowStepDefinition 的存储空间来减少 ApplicationRevision 的内存使用量。大多数应用程序在系统中仅仅使用几个常见定义,如 webservice 或 scaler。这些定义分别存储在 ApplicationRevisions 中,并占用了大量空间。因此,在应用程序控制器中,我们设置了一个横向公共缓存,并让这些 ApplicationRevisions 指向存储在公共缓存中的定义,从而减少内存使用。

KubeVela 的 informer cache 架构
3. 禁用 ConfigMap 的 informer cache。ConfigMap 的缓存是由 Workflow Context 引起的。应用程序工作流将运行上下文存储在 ConfigMap 中,但 ConfigMap 的缓存不仅包含工作流程使用的 ConfigMap,还包括其他未使用的 ConfigMap,这可能会占用大量空间。

优化前后的内存使用情况
在负载测试中,我们发现这些方法结合在一起对内存使用情况进行了重大改进,特别是对于持续更新。以前的负载测试并不重点关注持续更新,但这会忽略应用程序控制器中实际使用的缓存内存的增加。
Go 程序的内存使用情况并不简单。上述内存统计数据是操作系统报告的 RSS 大小。Go 程序的实际内存使用量小于此。Go 未使用的内存并不总是立即返回给操作系统,并且存在内存碎片化,这将阻止它返回所有未使用的内存。因此,这里我们还比较了 Go 报告的 ALLOC 内存和 SYS 内存。ALLOC 内存可以视为实际使用的内存大小,SYS 内存表示 Go 从操作系统获得了多少内存。
通过 3000 个应用程序和 9000 个应用程序修订版本,我们在优化之前得到了 1.02G 的 RSS,897M 的 SYS 和 401M 的 ALLOC。优化后,我们得到了 739M 的 RSS ,707M 的 SYS 和 203M 的 ALLOC。可以看到使用中的内存减少了约 50%。总内存使用情况也减少了约 25%。
参考链接:
https://github.com/kubevela/kubevela/pull/5683
Part 03. 实验
多个分片
设置
KubeVela v1.8.0 支持 controller sharding [ 5] ,允许 KubeVela 控制平面进行水平扩展。它通过利用 ListWatch 请求中的标签选择器来实现 ,controller-runtime 将其用作 KubeVela 应用程序控制器后端。它不仅限制了每个分片要处理的应用程序数量,还通过分割减少了内存缓存的大小。

控制器分片的架构
为了验证 KubeVela 控制器的多个分片可以按预期工作,我们比较了以下三种情况性能:
- 单个分片,使用 0.5 核、1 Gi 内存。
- 三个分片,每个分片使用 0.5 核、1 Gi 内存。
- 使用 KubeVela v1.7.5 的单个分片,使用 0.5 核、1 Gi 内存。 我们在单个分片情况下测试了 3000 个小型应用程序(KubeVela 核心控制器的默认配置),在三个分片情况下测试了 9000 个小型应用程序(每个分片包含 3000 个应用程序,与单个分片情况相同)。
分析

实验表明,控制器分片可以横向扩展应用程序容量

与单个分片的情况相比,三个分片中每个分片的资源使用量相似
我们可以看到,在使用三个分片时,每个分片能够处理 3000 个 应用程序且不会互相干扰。在所有应用程序发布之后,每个分片的 RSS 内存使用量增加到 412 MiB,CPU 使用率为 0.1 核(平均协调延迟为 15 毫秒)。目前,该系统总共包含 9000 个应用程序。与单个分片相比,分片模式下的内存使用量和 CPU 使用量相对处于同一水平。运行 3000 个应用程序的单个分片,在所有发布之后使用大约 0.08 核,并使用 320 MiB 的内存。在使用分片和不使用分片之间也没有明显的 Reconcile 延迟差异(发布后约 40〜50 毫秒,发布后为 10〜15 毫秒)。

v1.8.0 的性能比 v1.7.5 好得多
对比优化后的单分片案例与未优化的案例(v1.7.5),我们可以看到平均 Reconcile 时间明显下降,特别是发布后的时间成本(从 55ms 降至 16ms)。发布后的 CPU 使用率从 0.13 核降至 0.08 核。内存使用量从 676 MiB 减少到 320 MiB。
总结
综上所述,我们通过这个实验得出以下结论:
- 与 v1.7.5 相比,v1.8.0 的性能有了很大的优化。
- 部署多个分片可以横向增加系统的应用容量,并且不会引入太多的开销。
具有持续更新的大型应用程序
设置
虽然之前的负载测试主要集中在应用程序的交付上,但在生产案例中,我们看到用户不断升级带有数十个修订版本的应用程序。应用程序的持续更新是否会影响控制平面的稳定性仍然存在疑问。因此,我们进行了这个实验,在部署应用程序之后进行了几次更新。我们发现,在优化之前的 v1.7.5 版本中,对应用程序的持续更新会导致 KubeVela 控制器的内存增加。这会使控制器更快地达到最大内存使用量。例如,部署 3000 个应用程序只用了大约 700 MiB,但将所有应用程序更新一次会使内存升至 900 MiB。将所有应用程序更新两次将导致控制器内存不足并崩溃。对于 v1.6 之前的版本来说,这种情况更糟,因为默认的应用程序修订版本限制很高,并且默认情况下系统中保留了大量修订版本。解决这个问题有多方法,一种是将修订版本限制设置为较小的数字。从 v1.7.0 开始,这个数字被设置为 2,这意味着每个应用程序最多可以保存 2 个历史修订版本。KubeVela 在 v1.8.0 中实现的另一种方法是减少内存消耗,特别是在持续更新期间增加内存使用量。如上面的章节所示,我们可以注意到部署 3000 个轻量级应用程序的内存使用已大大减少。我们测试了优化后的控制器性能,证明 0.5 核 1 Gi KubeVela 控制器可以处理 3000 个大型应用程序(每个应用程序带有 3 个部署、3 个密钥和 4 个配置映射)并持续更新。在实验中,我们在 17:11 部署了 3000 个应用程序,并在大约 1 小时后完成了所有发布。(如果我们增加负载测试客户端的部署速率,可能会更快。)然后我们在 19:05、20:05、20:55、22:00、23:27 更新了所有的应用程序。请注意,每个应用程序的历史修订版本数量的默认设置为 2 。因此,在前两次更新中,会生成新的应用程序修订版本,而在接下来的三次更新中,会创建新的修订版本并回收过时的修订版本。
分析

应用程序更新比应用程序创建慢
应用程序的更新比部署需要更多的时间,因为应用程序还需要处理过时资源的垃圾回收。因此,我们观察到控制器队列的增加,但这并会不持续很长时间。应用程序的平均工作流完成时间仍然保持在 1 分钟以下。

在更新过程中 CPU 使用率很高,成为瓶颈。内存仅在前两次更新时增加
(受 ApplicationRevision 的限制)
当我们查看 KubeVela 控制器的资源使用情况时,我们注意到在更新过程中,CPU 使用率已达到 0.5 核,这是使控制器工作变慢的主要原因之一。控制器只有在应用部署和状态保持资源时才支持并行执行,但目前不支持并行垃圾回收(我们希望在未来添加)。控制器的内存使用量在第一次发布后达到了 470 MiB。在前两次更新后,它上升到 580 MiB 和 654 MiB 。然后对于以下更新,它保持在690 MiB 左右(低于内存限制的 70%),并且没有进一步连续增加。 Go 的内存分配机制不会立即将未使用的内存返回给操作系统,也不是所有未使用的内存总是可以被返回。因此,内存的实际使用量(分配的内存)通常远低于常驻集大小。当 KubeVela 控制器的队列中有很高的负载和积累时,内存使用量可能会一度很高,但不会持续下去。有些人可能会问,这样的应用程序模板真的足够大?的确,我们已经看到有用户在一个应用程序中调度了 50 多个 Kubernetes 资源,这至少比我们在这里测试的应用程序的 5 倍。但平均而言,庞大的应用程序只是整个系统的一小部分,并且这里的测试将所有应用程序设置为相同的大小。此外,如果我们将这个实验与上一节中的测试(多分片中的单个分片案例)进行比较,其中,我们对 3000 个小应用程序(3 个资源)使用了相同的控制器配置,我们可以发现在这个实验中使用的应用程序大了 3 倍以上,但控制器的性能仅略有下降。
总结
总之,我们从实验中得知以下几点:
- 在标准控制器设置下,KubeVela 控制器能够容纳 3000 个大型应用程序并对其进行持续更新。
- 应用程序的更新速度比创建速度慢,它会消耗更多的计算资源。
- 与小型应用程序相比,大型应用程序对 KubeVela 控制器的性能影响不大。
多集群
设置
上述负载测试和 KubeVela 在历史上所做的所有负载测试都使用单集群架构来部署和管理应用程序。随着越来越多的用户开始在多个集群中管理应用程序,我们想要了解 KubeVela 在多集群场景下的表现。因此,我们设计了这个实验。在这个实验中,我们也使用了 KubeVela 控制器的默认配置,0.5 核 1 Gi,并使用 v1.8.0 中的集群网关的默认配置(0.5 核 200 MiB)。除了将这些资源部署到远程集群之外,我们还使用了小型应用程序模板(1 个部署,1 个配置映射和 1 个密钥)。我们进行这个实验是为了测试跨地区的性能。KubeVela 的控制平面部署在日本东京,而托管集群则部署在中国杭州。我们还比较了 v1.8.0 和 v1.7.5 的性能。v1.7.5 的集群网关默认配置使用 0.1 核 200 MiB,因此为了进行公平比较,我们将其改进为 v1.8.0 中给出的资源。
分析

v1.7.5 和 v1.8.0 都可以处理 3k 个多集群应用程序,但 v1.8.0 的性能更好

v1.8.0 控制器发送请求更少且速度更快
我们发现,在这两个版本中,KubeVela 都能够在远程集群中处理 3000 个应用程序和管理资源,但 KubeVela v1.8.0 的性能优于 v1.7.5,这要归功于我们上面提到的优化。 我们发现 v1.7.5 的控制器队列保持在高状态,这是由于较长的协调时间引起的,这可能会使控制器对应用程序突变的响应变慢。除了针对集群网关的优化外,所有其他针对单个集群情况的优化技巧在多集群情况下也同样适用。

多集群请求比单个集群请求慢得多,主要由控制平面和托管集群间的延迟引起
与单集群情况下的 3000 个小型应用程序相比,在远程集群中部署资源可能会大大增加 KubeVela 控制器的时间成本。从仪表盘中可以看出,控制器的请求延迟平均约为 77 毫秒(单集群情况下为 20 毫秒),而集群网关的延迟平均约为 72 毫秒,与集群间延迟相比开销很小。

CPU 使用率和内存使用率没有差异
尽管延迟比单集群情况更大,但如果我们看 KubeVela 控制器的计算资源使用情况,会发现 CPU 使用率和内存使用率并没有太大的差异。
总结
从这个实验我们一般可以了解到以下几点:
1.在多集群场景下,v1.8.0 KubeVela 的性能表现比 v1.7.5 好。
2.在多集群场景下,KubeVela 控制器的内存消耗接近单集群情况。
3.KubeVela v1.8.0 能够默认 处理包括单集群、大型应用程序、多集群部署、持续更新在内的 3k 个应用程序。
4.如果托管集群与控制平面之间的延迟较大,则 KubeVela 控制器的性能将会更差。
优化方法:
a.通过增加 CPU、并发和 QPS/Burst,提高 KubeVela 控制器的并行性。
b.减少跨集群的延迟。(检查网络带宽并确保没有速率限制)
大规模
设置
在测试了多集群和多个分片之后,我们现在知道 KubeVela 有能力处理跨集群的大量应用程序。我们设计了一个大规模的负载测试,以验证通过适当的配置,单个 KubeVela 控制平面可以满足管理海量集群的需要。我们通过 k3d 在 64 核 256 Gi 虚拟机(阿里云上的 ECS)上模拟了 200 个托管集群。对于控制平面,我们使用了大型 ACK 集群(阿里云上的 Kubernetes),其中有 8 个( 3 个主节点和 5 个工作节点)32 核 128 Gi 节点。我们运行了 5 个分片控制器,每个分片控制器都有 8 核 32 Gi,32 个并发协调器,4000 QPS 6000 Burst。 我们又运行了另外 5 个集群网关,每个都有 2 核 1 Gi。 请注意,我们允许托管集群位于在同一个 VPC 中,并使用内网连接。 这将减少控制平面和托管集群之间的延迟,并增加最大网络吞吐量。我们向系统部署了 40 万个小型应用程序。它们的资源被平均分配到了 200 个集群中。

控制平面上运行的应用程序和控制器数量
分析
这 40 万个应用程序的交付分为了几个阶段。首先,我们部署了 2 万个应用程序,以查看是否一切正常,并检查是否存在任何潜在瓶颈。其次,我们部署了另外 18 万个应用程序,以查看系统是否能够承载 20 万个应用程序。最后,我们将数量增加到 40 万。

随着多集群请求延迟增加,控制器表现不佳。
通过向集群网关添加更多 CPU 并消除 pod 间不平衡的工作负载来解决
当我们部署了 20 万个应用程序时,控制器的性能开始下降,你会发现在大约 2:00 时,控制器队列开始上升,平均调和时间大大增加。这是由 KubeVela 控制器的一个分片重新启动引起的,需要进一步调查。控制器本身的重启并没有影响应用程序的运行,但后来我们发现 cluster-gateway pod 的负载没有均衡分布。大量负载集中在两个 cluster-gateway pod 上,导致它们的 CPU 使用率达到 90% 以上。这大大降低了多集群请求的吞吐量,导致应用程序协调缓慢。大约在 10:00,我们注意到了该异常,并重新启动集群网关 pod 以提高它们的 CPU(4 核1 Gi * 5),这解决了暴露的瓶颈。后来我们又添加了另外 20 万个应用程序,响应延迟始终很低。发布了 40 万个应用程序后,平均调和时间(reconciliation time)为 70 毫秒,但在不同的分片间有所不同。一些分片具有较低的多集群请求延迟,例如每个请求 15 毫秒,而其他分片的延迟更高,可达 30 毫秒。原因还于集群网关的多个副本之间负载不平衡。但总的来说,如果您只有一个 cluster-gateway 副本,您将不会遇到此问题。

由于中心控制平面与托管集群之间的集群网关直接通过内网连接,多集群请求与控制平面内请求具有相似的延迟
同时值得注意的是,在这种大规模实验中,管理集群和控制平面彼此靠近,它们之间的流量传输也非常快。因此,与上面的多集群实验不同,我们可以保持与单集群情况相似的的低调谐时间(reconciliation time)。

随着应用数量的增加,内存和 CPU 的使用率增长的速度比应用数量的增长慢得多
40 万个应用程序并不是 KubeVela 控制平面可容纳的最大数量。每个控制器分片只使用了不到 20% 的 32 Gi 内存,CPU 使用率也远未满负荷。但由于在 hub Kubernetes 的 etcd 中存储了大量对象(Application、ResourceTracker、ApplicationRevision),因此 hub kube-apiserver 和其他原生组件(如 kube-controller-manager)开始使用大量计算资源,例如超过 90 Gi 的内存。系统的瓶颈逐渐落到 Kubernetes 本身。
为了进一步验证上述假设,我们将 KubeVela 控制器的内存从每个分片 8 个 核 32 Gi 缩减到每个分片的 8 核 16 Gi(总共 5 个分 片),并使用一个具有 16 核 4 Gi 的单个集群网关副本来消除工作负载的不平衡。我们将应用程序的数量增加到 50 万,发现所有分片都具有相似的性能。所有控制器分片的 CPU 和内存使用率均正常。控制器分片的工作队列为空,状态保留的平均协调时间平均约为 60 毫秒。群集网关 Pod 的负载较高,但可以将多集群请求的平均延迟保持在较低水平(23 毫秒)。

调整后所有分片的资源使用情况相似

当我们将应用程序数量从 40 万增加到 50 万时,发现对账时间没有显著增加
我们认为,40 万/50 万个应用程序的数量对于几乎所有的 KubeVela 用户已经足够大了,因此我们在这里停止了实验。
总结
总之,这个大规模实验表明,在特定条件下,KubeVela 控制平面具有扩展和容纳极大量应用程序的能力。
总结
通过一系列在不同场景下的实验,KubeVela v1.8.0 展示了其稳定性和可扩展性。与 v1.7.5 相比,其性能有相当大的提升,这为系统运维人员有信心让 KubeVela 管理大规模应用平台。现在,KubeVela 已经发展成为构建应用平台的综合解决方案。虽然进行的负载测试覆盖了 KubeVela 一些最流行的用例,但我们也看到了 KubeVela 许多更高级的用法,比如输入/输出复杂工作流、金丝雀发布、GitOps 等。根据用户使用 KubeVela 的方式,KubeVela 系统的性能可能会暴露出不同的瓶颈。 我们总结了一些微不足道的解决方案,如下所示。

诊断系统性能瓶颈及解决方法
有时,整个应用系统的瓶颈并不是 KubeVela 本身。例如,如果托管集群的响应速度缓慢或吞吐量有限,我们可以提高 KubeVela 控制器的吞吐量,但控制器本身无法减少延迟。由于插件带来的系统可观测性,在大多数情况下,您可以在仪表板上找到系统性能不佳的一些线索,并应用适当的策略进行优化。 未来,KubeVela 会持续关注整个系统的底层性能,并确保它始终能够为应用程序交付提供稳定、快速的功能。
您可以通过如下材料了解更多关于 KubeVela 以及 OAM 项目的细节:
- 项目代码库:https://github.com/kubevela/kubevela欢迎 Star/Watch/Fork!
- 项目官方主页与文档:kubevela.io,从 1.1 版本开始,已提供中文、英文文档,更多语言文档欢迎开发者进行翻译。
- 项目钉钉群:23310022;Slack:CNCF #kubevela Channel
相关链接:
CNCF 官网的英文博客原文地址: https://www.cncf.io/blog/2023/04/12/stability-and-scalability-assessment-of-kubevela/
[1] 参考文献
https://kubevela.net/blog/2021/08/30/kubevela-performance-test
[2] Grafana 仪表板
https://grafana.com/grafana/dashboards/18200-kubevela-system/
[3] 报告
https://kubevela.net/blog/2021/08/30/kubevela-performance-test
[4] 指南
[5] controller sharding
https://kubevela.net/docs/platform-engineers/system-operation/controller-sharding
点击此处查看 KubeVela 项目官网
KubeVela 插件指南:轻松扩展你的平台专属能力
KubeVela 插件(addon)可以方便地扩展 KubeVela 的能力。正如我们所知,KubeVela 是一个微内核高度可扩展的平台,用户可以通过模块定义(Definition)[1]扩展 KubeVela 的系统能力,而 KubeVela 插件正是方便将这些自定义扩展及其依赖打包并分发的核心功能。不仅如此,KubeVela 社区的插件中心也在逐渐壮大,如今已经有超过 50 款插件,涵盖可观测性、微服务、FinOps、云资源、安全等大量场景功能。
本文将会全方位介绍 KubeVela 插件的核心机制,教你如何编写一个自定义插件。在最后,我们将展示最终用户使用插件的体验,以及插件将如何融入到 KubeVela 平台,为用户提供一致的体验。
为什么要使用 KubeVela 插件
用户使用插件的一个典型方法是通过 KubeVela 团队维护的插件中心(addon catalog)[2] ,它包含了 KubeVela 团队与社区开发者精心编写的系统扩展功能,并以插件的形式发布于插件中心,这样你可以一键下载并安装这些插件。例如安装 FluxCD 可以快速给你的 KubeVela Application 提供部署 Helm Chart 的能力。
相较于使用 KubeVela 的插件功能,如果你自己的内部平台想要集成一个云原生的功能,你大概会这么做:
- 通过 Helm Chart 或者下载 yaml 文件手动安装 FluxCD 或类似的 CRD Operator。
- 编写系统集成的代码,让用户界面可以通过统一的方式使用 FluxCD 等 CRD 的功能,在 KubeVela 系统中就是通过编写模块定义(OAM Definition)完成。
实际上,在 KubeVela 1.1 版本之前,我们也是通过类似的方式完成的。这会带来如下问题:
- 操作繁琐:用户需要手动查阅文档如何安装 FluxCD 并处理可能发生的错误
- 资源分散:用户需要下载不同的文件,既需要安装 Helm 安装 FluxCD 还需要下载模块定义等系统扩展的集成配置
- 难以分发复用:用户需要手动下载模块定义就注定了这些资源难以以一个统一的方式分发给用户,也无法形成社区生态让不同的用户可以享受社区便利
- 缺少多集群支持:KubeVela 将多集群交付作为一等公民,而这样的手动安装系统扩展的方式显然难以维护多集群的环境
- 无版本管理:用户需要手动管理模块定义和 Controller 之间的版本
而 KubeVela 插件就是为了逐一解决这些问题而诞生的。
KubeVela 插件是如何工作的
KubeVela 的插件主要包含两部分:
- 一部分是安装能力的提供者,通常是一个 CRD Operator/Controller。这个安装过程实质上就是运行一个 OAM 应用,addon 交付中所使用的功能与普通应用能力完全等价。
- 另一部分就是扩展能力跟 KubeVela 体系的粘合层,也就是模块定义和其他的一些集成配置。OAM 模块定义为用户提供了插件扩展出的组件、运维特征以及工作流步骤等功能,也帮助 CRD Operator 提供用户友好的抽象,使得最终用户无需理解复杂的 CRD 参数,只需要根据最佳实践提供必要的参数。
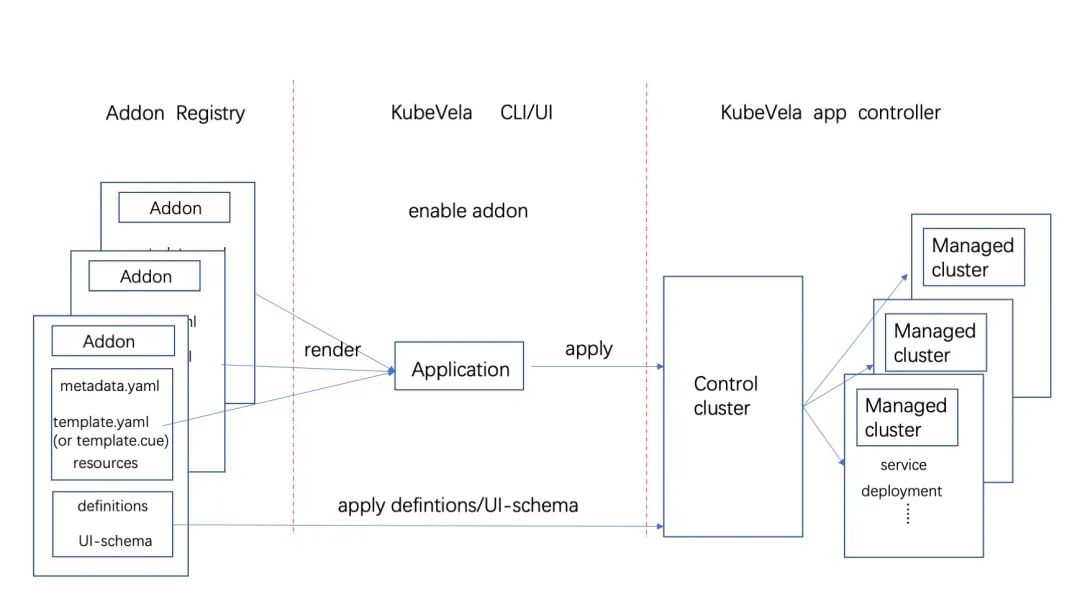
插件的工作机制如上图所示,KubeVela 的应用具备多集群交付的能力,所以也能帮助插件中的 CRD Operator 部署到这些集群中。模块定义文件仅需要在控制面被 KubeVela 使用,所以无需部署到被管控的集群中。
提示
一旦插件被安装,就会创建一个 KubeVela 应用,包含所有的相关资源和配置,这些配置都会设置 KubeVela 应用对外作为 OwnerReference(父节点)。当我们想要卸载一个插件时,只需要删除这个应用,Kubernetes 提供的资源回收机制会自动将标记了 OwnerReference 的资源一并删除。
例如一个 Redis 插件,它能让用户在自己的应用中使用 Redis 集群类型的组件(Component),这样可以快速创建 Redis 集群。那么这个插件至少会包括一个 Redis Operator 来提供创建 Redis 集群的能力(通过 Application 描述),还有一个组件的模块定义 (ComponentDefinition) 来提供 Redis 集群的组件类型。
所有整个插件的安装过程会将 Redis Operator 放在一个 KubeVela 应用中下发到多集群,而组件定义和 UI 扩展等配置文件则只部署到控制面集群并设置应用对象为 OwnerReference。
创建自己的插件
提示
为保证以下内容功能全部可用,请确保你的 KubeVela 版本 为 v1.5+。
我们将以 Redis 插件为例,讲解如何从头创建一个 KubeVela 插件的实际过程。本次完整的 Redis 插件代码见文末参考[3]。
提示
在这里我们会尽可能全面的介绍制作插件中涉及的核心知识,但是作为一个介绍性博客,我们会尽量避免讨论过深的细节以免篇幅过于膨胀,了解完整的功能及细节可以参考自定义插件文档[4]。
首先我们需要思考我们要创建的插件有什么作用?例如我们假设 Redis 插件可以提供 redis-failover 类型的 Component,这样用户只需在 Application 中定义一个redis-failover Component 即可快速创建 Redis 集群。
然后考虑如何达到这个目的?要提供 redis-failover 类型的 Component 我们需要定义一个 ComponentDefinition ;要提供创建 Redis 集群的能力支持,我们可以使用 Redis Operator[5]。那至此我们的大目标就明确了:
- 编写插件的应用描述文件(OAM Application),这将会用于安装 Redis Operator (完整代码可以到插件中心的 template.cue[6]及resources/目录[7]查看。)
- 编写 redis-failover 类型的 ComponentDefinition[8](完整代码请查看 definitions/目录[9])
不过在开始编写之前,我们首先需要了解一个 KubeVela 插件的目录结构。后续我们会在编写的过程中详细说明每个文件的作用,在这里只需大致了解有哪些文件即可。
提示
命令行工具 vela addon init 可以帮助你创建目录结构的初始化脚手架。
redis-operator/
├── definitions
│ └── redis-failover.cue
├── resources
│ ├── crd.yaml
│ ├── redis-operator.cue
│ └── topology.cue
├── metadata.yaml
├── parameter.cue
├── README.md
└── template.cue让我们逐一来解释它们:
1. redis-operator/ 是目录名,同时也是插件名称,请保持一致。
2. definitions/ 用于存放模块定义, 例如 TraitDefinition 和 ComponentDefinition。
3. redis-failover.cue 定义我们编写的 redis-failover 组件类型,包含了用户如何使用这个组件的参数以及这个组件与底层资源交互的细节。
4. resources/ 用于存放资源文件, 之后会在 template.cue 中使用他们共同组成一个 KubeVela 应用来部署插件。
5. crd.yaml 是 Redis Operator 的 Kubernetes 自定义资源定义,在 resources/ 文件夹中的 YAML 文件会被直接部署到集群中。
6. redis-operator.cue 一个 web-service 类型的 Component ,用于安装 Redis Operator。
7. topology.cue 是可选的,帮助 KubeVela 建立应用所纳管资源的拓扑关系。
8. metadata.yaml 是插件的元数据,包含插件名称、版本、维护人等,为插件中心提供了概览信息
9. parameter.cue 插件参数定义,用户可以利用这些参数在插件安装时做轻量级自定义
10. README.md 提供给最终用户阅读,包含插件使用指南等。
11. template.cue 定义插件最终部署时的完整应用形态,包含一个 OAM 应用模板以及对其他资源对象的引用。
提示
在插件中制作中我们会广泛使用 CUE 语言来编排配置,如果对 CUE 不熟悉,可以花 10 分钟快速查阅入门指南有一个基本了解。
parameter.cue
parameter:
//+usage=Redis Operator image.
image: *"quay.io/spotahome/redis-operator:v1.1.0" | string
// 其余省略
在 parameter.cue 中定义的参数都是用户可以自定义的(类似于 Helm Values),后续在 template.cue 或者 resources 中可以通过 parameter.<parameter-name> 访问参数。在我们的例子中,用户可以自定义 image ,这样后续我们创建 Redis Operator (redis-operator.cue) 的时候可以通过 parameter.image 使用用户指定的容器镜像。
参数不仅可以给用户预留安装时的自定义输入,还可以作为安装时的条件进行部分安装。比如fluxcd 插件有一个参数叫 onlyHelmComponents[10],它的作用就是可以帮助用户只部署用于安装 Helm Chart 的组件能力,而其他控制器就可以不安装。如果你对于实现细节感兴趣,可以参考fluxcd 插件的部分配置[11]。
在设计提供什么参数供用户自定义插件安装时,我们也应该遵循一下这些最佳实践来为用户提供更好的使用体验。
最佳实践
- 不要在 parameter.cue 中提供大量的细节参数,将大量细节抽象出少量参数供用户调节是一个更好的做法
- 为参数提供默认值(如样例中的 image 参数)或将参数标记为可选(如样例的 clusters 参数),确保用户仅使用默认值可以得到一个可用的配置
- 为参数提供使用说明(通过注释标记实现,见样例)
- 尽量保持插件不同版本间的参数一致,防止因为升级导致不兼容
template.cue 和 resources/ 目录
这是存放我们应用描述文件的地方,即一个 OAM Application 。这描述了实际的插件安装过程。我们主要会在这里包含 Redis Operator ,给集群提供管理 Redis 集群的能力。
template.cue 和 resources/ 目录本质上是相同的,都是构成 KubeVela 应用的组成部分,且都是在同一个 package 下的 CUE 文件。
那为什么需要 resources 目录呢?除去历史原因,这主要是为了可读性的考虑,在 Application 中包含大量资源的时候 template.cue 可能变得很长,这时我们可以把资源放置在 resource 中增加可读性。一般来说,我们将 Application 的框架放在 template.cue 中,将 Application 内部的 Components、Traits 等信息放在 resource 目录中。
- template.cue
template.cue 定义了应用的框架,绝大多数内容都是固定写法,具体的作用可以参考代码块中的注释。
// template.cue 应用描述文件
// package 名称需要与 resources 目录中 cue 的 package 一致,方便引用 resources 目录中的内容
package main
// Application 模板中多数字段均为固定写法,你需要注意的只有 spec.components
output:
// 这是一个经典的 OAM Application
apiVersion: "core.oam.dev/v1beta1"
kind: "Application"
// 不需要 metadata
spec:
components: [
// 创建 Redis Operator
redisOperator // 定义于 resources/redis-operator.cue 中
]
policies: [
// 这里会指定安装插件的 namespace ,是否安装至子集群等
// 多为固定写法,无需记忆,可查阅本次样例的完整代码
// https://github.com/kubevela/catalog/blob/master/experimental/addons/redis-operator/template.cue
// 文档可参照 https://kubevela.net/zh/docs/end-user/policies/references
]
// 定义资源关联规则,用于将资源粘合在一起。后续会着重介绍
// Documentation: https://kubevela.net/zh/docs/reference/topology-rule
outputs: topology: resourceTopology // 定义于 resources/topology.cue 中在插件安装时,系统主要关注两个关键字:
- 一是 output 字段,定义了插件对应的应用,在应用内部 spec.components 定义了部署的组件,在我们的例子中引用了存放在 resources/ 目录中的 redisOperator 组件。output 中的 Application 对象不是严格的 Kubernetes 对象,其中 metadata 里的内容(主要是插件名称)会被插件安装的过程自动注入。
- 另一个是 outputs 字段,定义了除了常规应用之外的配置,任何你想要跟插件一同部署的额外 Kubernetes 对象都可以定义在这里。请注意 outputs 中的这些对象必须遵循 Kubernetes API。
- resources/ 资源文件
我们这里使用一个webservice类型的 Component 来安装 Redis Operator。当然,如果你可以接受依赖 FluxCD 的话,你也可以使用 helm 类型的 Component 直接安装一个 Helm Chart(因为 helm 类型的 Component 主要由 FluxCD 插件提供)。不过编写 addon 的一个原则是尽量减少外部依赖,所以我们这里使用 KubeVela 内置的 webservice 类型,而不是 helm。
// resources/redis-operator.cue
// package 名称与 template.cue 一致,方便在 template.cue 中引用以下的 redisOperator
package main
redisOperator:
// 这是 OAM Application 中的 Component ,它将会创建一个 Redis Operator
// https://kubevela.net/zh/docs/end-user/components/references
name: "redis-operator"
type: "webservice"
properties:
// Redis Operator 镜像名称,parameter.image 即在 parameter.cue 中用户可自定义的参数
image: parameter.image
imagePullPolicy: "IfNotPresent"
traits: [
// 略
]
你可以阅读代码块中的注释了解字段的具体作用。
- KubeVela 提供的资源粘合能力
值得注意的一个功能是资源关联规则 (Resource Topology)[12]。虽然它不是必须的,但是它能帮助 KubeVela 建立应用所纳管资源的拓扑关系。这就是 KubeVela 如何将各种各样的资源粘合成 Application 的。这在我们使用 Kubernetes 自定义资源(CR)的时候特别有用。
// resources/topology.cue
package main
import "encoding/json"
resourceTopology:
apiVersion: "v1"
kind: "ConfigMap"
metadata:
name: "redis-operator-topology"
namespace: "vela-system"
labels:
"rules.oam.dev/resources": "true"
"rules.oam.dev/resource-format": "json"
data: rules: json.Marshal([
parentResourceType:
group: "databases.spotahome.com"
kind: "RedisFailover"
// RedisFailover CR 会创建以下三类资源
childrenResourceType: [
apiVersion: "apps/v1"
kind: "StatefulSet"
,
// KubeVela 内置 Deployment 等资源的拓扑,因此无需继续向下编写
apiVersion: "apps/v1"
kind: "Deployment"
,
apiVersion: "v1"
kind: "Service"
,
]
])
在本例中,redis-failover 类型的 Component 会创建一个 CR ,名为 RedisFailover 。但是在没有资源关联规则的情况下,假设在你的 Application 中使用了 RedisFailover ,虽然我们知道 RedisFailover 管控了数个 Redis Deployment ,但是 KubeVela 并不知道 RedisFailover 之下有 Deployment 。这时我们可以通过 资源关联规则 将我们对于 RedisFailover 的了解告诉 KubeVela,这样 KubeVela 可以帮助我们建立起整个应用下面纳管资源的拓扑层级关系。此时你将获得 KubeVela 提供的许多有用功能,效果见运行插件[13]。
提示
资源的拓扑关联功能给我们带来了许多有用的功能,最重要的是为 KubeVela 最终用户使用扩展能力提供了统一体验:
- VelaUX 资源拓扑视图,从应用到底层资源 Pod 的关联关系一应俱全,包括多集群
- 统一的 vela exec 命令可以在不同应用组件类型关联的底层容器中执行命令,包括多集群
- 统一的 vela port-forward 转发不同类型应用组件关联的底层容器端口,包括多集群
- 统一的 vela log 查看不同类型应用组件关联的底层容器日志,包括多集群
- 统一的 vela status --pod/--endpoint 查看不同类型应用组件关联的底层容器日志,获得可供访问的地址等,包括多集群
definitions/ 目录
Definitions 目录存放 KubeVela 模块定义(Definition)[14],包括组件定义(ComponentDefinition)、策略定义(TraitDefinition)等。这是插件中最重要的部分,因为它包含了最终用户安装这个插件以后可以获得哪些功能。有了这里定义的组件、运维特征、工作流等类型,最终用户就可以在应用中使用他们了。
在插件中编写模块定义跟常规的编写流程一致,这是一个很大的话题,在这里我们就不详细展开了。你可以通过阅读模块定义对应的文档了解其中的细节:
- 自定义组件 Component Definition[15]
- 自定义运维特征 Trait Definition[16]
- 自定义策略 Policy Definition[17]
- 自定义工作流步骤 Workflow Step Definition。[18]
在本例中,我们编写 Redis 组件类型主要参照自定义组件[19]与 Redis Operator 使用文档[20],我们将组件类型命名为 redis-failover,它会创建一个 RedisFailover 的 CR ,这样刚刚添加的 Redis Operator 就可以帮助创建 Redis 集群,见文末完整代码[21]。
metadata.yaml
这里包含了插件的元数据,即插件的名称、版本、系统要求等,可以参考文末文档[22]。需要注意的是,本次介绍的为 KubeVela v1.5 之后的新写法,因此需要避免使用某些不兼容的元数据字段,以下样例中包含了所有的可用元数据。
提示
例如传统的 deployTo.runtimeCluster (安装至子集群)等元数据在新写法中已有代替(使用 topology Policy),应当使用新写法。可见完整代码中的 template.cue[23]
# 插件名称,与目录名一致
name: redis-operator
# 插件描述
description: Redis Operator creates/configures/manages high availability redis with sentinel automatic failover atop Kubernetes.
# 展示用标签
tags:
- redis
# 插件版本
version: 0.0.1
# 展示用图标
icon: https://xxx.com
# 插件所包含项目的官网地址
url: https://github.com/spotahome/redis-operator
# 可能依赖的其他插件,例如 fluxcd
dependencies: []
# 系统版本要求
system:
vela: ">=v1.5.0"
kubernetes: ">=1.19"运行插件
至此我们已经将插件的主要部分编写完成,下载文末完整代码[24]补全部分细节后,即可尝试运行。
下载得到 redis-operator 目录后,我们可以通过 vela addon enable redis-operator 安装本地的 redis-operator 插件,这种本地安装插件的方式也可以方便你再制作时做一些调试。安装完成后就可以参考插件的 README[25]试用我们的 Redis 插件了!
提示
这里也体现出插件的 README 的重要性,其中需要包括插件的作用、详细使用指南等,确保用户可以快速上手。
在用户使用你编写的插件时,只需如下 4 行 yaml 即可在 Application 中创建包含 3 个 Node 的高可用 Redis 集群!相比于手动安装 Redis Operator 并创建 CR ,甚至逐一手动配置 Redis 集群,插件的方式极大地方便了用户。
apiVersion: core.oam.dev/v1beta1
kind: Application
metadata:
name: redis-operator-sample
spec:
components:
# This component is provided by redis-operator addon.
# In this example, 2 redis instance and 2 sentinel instance
# will be created.
- type: redis-failover
name: ha-redis
properties:
# You can increase/decrease this later to add/remove instances.
replicas: 3只需 apply 仅仅数行的 yaml 文件,我们就轻松创建了如下图所示的整个复杂的资源。并且由于我们编写了资源关联规则 (Resource Topology) ,用户可以通过 VelaUX 轻松获得刚刚创建的 Redis 集群的资源拓扑状态,了解 Application 底层资源的运行状况,不再受限于 Application Component 级别的可观测性。如图我们能直接观测到整个 Application 的拓扑,直至每个 Redis Pod ,可见图中部分 Pod 仍在准备中:

在执行 vela exec/log/port-forward 等命令时也可以精确地看到 Application 底层包含的资源(即支撑 Redis 集群的 3 个 Redis Pod 和 3 个 Sentinel Pod)。

如果你在使用单集群,乍一看你可能不会觉得 exec 进一个 Pod 是很特殊的功能。但是一旦考虑到多集群,能够在横跨多个集群的资源中跟单集群一样以统一的方式进行选择查看能够极大的节省时间。
使用 vela status 命令能获取这个 Application 的运行状态,有了资源关联规则后可以更进一步,直接通过 vela 寻找出 Redis Sentinel 的 Endpoint 来访问 Redis 集群:

结语
通过本文,相信你已经了解插件的作用及制作插件的要点。通过插件体系,我们将获得如下优势
- 将平台的能力打包成一个易于安装、便于分发复用、且可以形成社区生态的插件市场。
- 充分复用 CUE 和 KubeVela 应用通过的强大能力,将基础设施资源灵活定义并进行多集群分发。
- 无论扩展的资源类型是什么,均可以接入应用体系,为最终用户提供一致的体验。
最后,如果你成功制作了属于自己的插件,KubeVela 社区非常欢迎开发者贡献插件至插件中心[26],这样你的插件还能够被其他 KubeVela 社区用户发现并使用!
戳此处:查看 KubeVela 项目官网!!
相关链接
[1] 模块定义(Definition)
https://kubevela.net/zh/docs/platform-engineers/oam/x-definition
[2] 插件中心(addon catalog)
https://github.com/kubevela/catalog
[3] catalog/redis-operator
https://github.com/kubevela/catalog/tree/master/experimental/addons/redis-operator
[4] 自定义插件文档
https://kubevela.net/zh/docs/platform-engineers/addon/intro
[5] Redis Operator
https://github.com/spotahome/redis-operator
[6] template.cue
https://github.com/kubevela/catalog/blob/master/experimental/addons/redis-operator/template.cue
[7] resources/
https://github.com/kubevela/catalog/tree/master/experimental/addons/redis-operator/resources
[8] ComponentDefinition
https://kubevela.net/zh/docs/platform-engineers/components/custom-component
[9] definitions/目录
https://github.com/kubevela/catalog/tree/master/experimental/addons/redis-operator/definitions
[10] onlyHelmComponents
https://github.com/kubevela/catalog/blob/master/addons/fluxcd/parameter.cue
[11] fluxcd 插件部分配置
https://github.com/kubevela/catalog/blob/master/addons/fluxcd/template.cue#L25
[12] 资源关联规则 (Resource Topology)
https://kubevela.net/zh/docs/reference/topology-rule
[13] 运行插件
[14] 模块定义(Definition)
https://kubevela.io/docs/getting-started/definition
[15] 自定义组件 Component Definition
https://kubevela.io/docs/platform-engineers/components/custom-component
[16] 自定义运维特征 Trait Definition
https://kubevela.io/docs/platform-engineers/traits/customize-trait
[17] 自定义策略 Policy Definition
https://kubevela.io/docs/platform-engineers/policy/custom-policy
[18] 自定义工作流步骤 Workflow Step Definition
https://kubevela.io/docs/platform-engineers/workflow/workflow
[19] 自定义组件
https://kubevela.net/zh/docs/platform-engineers/components/custom-component
[20] Redis Operator 使用文档
https://github.com/spotahome/redis-operator/blob/master/README.md
[21] 完整代码
[22] 文档
[23] template.cue
[24] 完整代码
https://github.com/kubevela/catalog/tree/master/experimental/addons/redis-operator
[25] README
https://github.com/kubevela/catalog/tree/master/experimental/addons/redis-operator/README.md
[26] 插件中心
https://github.com/kubevela/catalog
作者:姜洪烨
本文为阿里云原创内容,未经允许不得转载。
以上是关于KubeVela 稳定性及可扩展性评估的主要内容,如果未能解决你的问题,请参考以下文章