hive 分析结果导出到一个文本中
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive 分析结果导出到一个文本中相关的知识,希望对你有一定的参考价值。
在linuxhive客户端登录后去统计数据,如
hive> select channelname from huatong_aime1 where loglocation in('1') group by channelname, cdnid, cast(cast(reqtime as int) div 60 as string) limit 5;
这个分析结果导出在一个文本中,应该怎么写呢?
我用过这种方法去写
[root@HTCDN-ZJHZ-NOC-CLOUD-01 ~]# hive -e 'select channelname from huatong_aime1 where loglocation in('1') group by channelname, cdnid, cast(cast(reqtime as int) div 60 as string) limit 5;' >hive.log
没有把分析结果追到hive.log,求办法。因为这个数据经常要统计,要给别人看。
DIR e:\*.mp3 e:\*.wma /B /S > 1.txt
C中用system(...) 时 反斜杠要用 双反斜杠 e:\\*.mp3 e:\\*.wma
实在是不理解你意思。
Excel估计能完成你的要求,但麻烦你能再描述的清楚些吗? 参考技术A ll -aR > 001.txt
ll 查看
-a 现实所以文件
-R 递推查看
> 重定向
001.txt 这个文件
打开001.txt 就看到了 参考技术B 如果你想把查询的结果保存到linux系统上的某个文件中,可以执行这个HQL。
insert overwrite local directory '/tmp/output' select * from tablea;
这时查询的结果会被保存在HiveServer所在节点的的/tmp/output目录下。
如果你使用的Hive版本是0.11及以上,还可以指定列之间的分隔符,具体可以看这个问题单https://issues.apache.org/jira/browse/HIVE-3682本回答被提问者采纳
Hive编程指南学习03
文章目录
新建数据表employees
create table employees(
name string,
salary float,
subordinates array<string>,
deductions map<string,float>,
address struct<street:string,city:string,state:string,zip:int>
)
partitioned by (country string,state string);
向表中装载数据
load data local inpath '/opt/datafiles/employees.txt' overwrite into table employees partition (country='US',state='CA');
partition子句分区表,用户必须为每个分区的键指定一个值。
数据将会存放到这个文件夹
/user/hive/warehouse/learnhive.db/employees/country=US/state=CA
select name,salary from employees;
+-------------------+-----------+
| name | salary |
+-------------------+-----------+
| John Doe | 100000.0 |
| Mary Smith | 80000.0 |
| Todd Jones | 70000.0 |
| Bill King | 60000.0 |
| Boss Man | 200000.0 |
| Fred Finance | 150000.0 |
| Stacy Accountant | 60000.0 |
+-------------------+-----------+
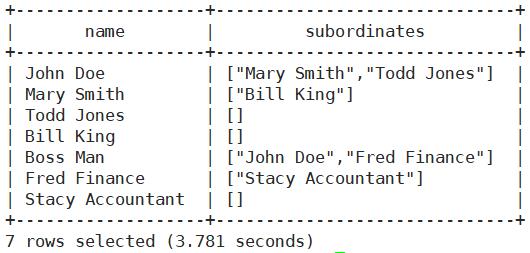
当用户选择的列是集合数据类型时,Hive会使用JSON语法应用于输出。subordinates列为一个数组,注意:集合的字符串元素是加上引号的,而基本数据类型string的列值是不加引号的。
select name,subordinates from employees;
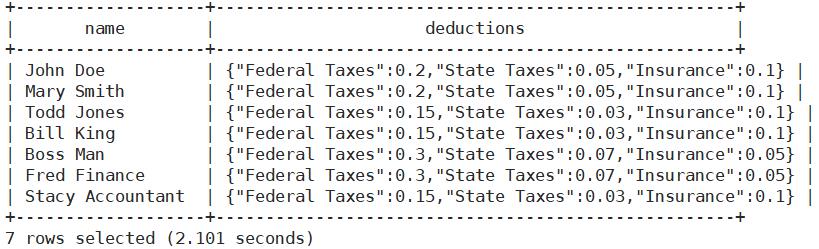
deductions列是一个MAP
select name,deductions from employees;
address列是一个struct
select name,address from employees;

引用集合类型中的元素
引用数组(选择数组subordinates的第2个元素)
select name,subordinates[1] from employees;

引用一个不存在的元素将会返回NULL。同时提取出的string数据类型的值不再加引号
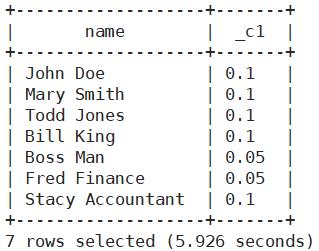
引用MAP元素
select name,deductions['Insurance'] from employees;
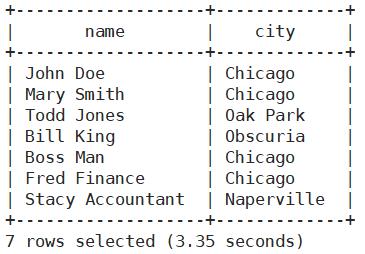
引用struct元素
select name,address.city from employees;
新建数据表stocks
create table stocks(
exchange_e string,
symbol string,
ymd string,
price_open float,
price_high float,
price_low float,
price_close float,
volume int,
price_adj_close float)
row format delimited fields terminated by ',';
装载数据
load data local inpath '/opt/datafiles/stocks.csv' overwrite into table stocks;
使用正则表达式来指定列
首先得执行这条语句
set hive.support.quoted.identifiers=none;
select symbol,`price.*` from stocks limit 5;

使用列值进行计算
select upper(name),salary,deductions["Federal Taxes"],round(salary*(1-deductions["Federal Taxes"])) from employees;

算术运算符
+,加
-,减
*,乘
/,除
%,求余
&,按位取与
|,按位取或
^,按位取亦或
~,按位取反
limit语句
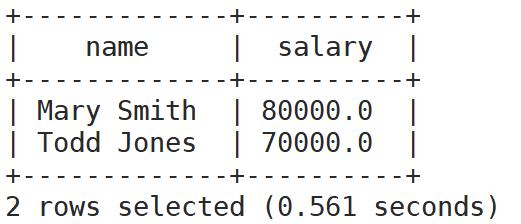
select name,salary from employees limit 2;
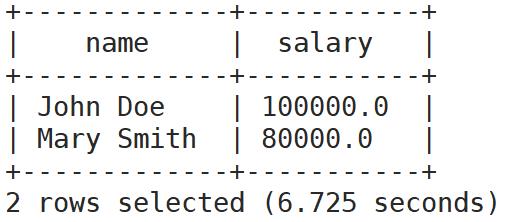
select name,salary from employees limit 1,2;
查询从第1列开始,返回2列
列别名
select name as n,salary from employees;

DML数据操作
数据导入
load
load data [local] inpath '数据的path' [overwrite] into table student [partition (partcol1=val1,…)];
(1)load data:表示加载数据
(2)local:表示从本地加载数据到hive表;否则从HDFS加载数据到hive表
(3)inpath:表示加载数据的路径
(4)overwrite:表示覆盖表中已有数据,否则表示追加
(5)into table:表示加载到哪张表
(6)student:表示具体的表
(7)partition:表示上传到指定分区
insert
insert into或overwrite table student_par values(1,'wangwu'),(2,'zhaoliu');
insert into:以追加数据的方式插入到表或分区,原有数据不会删除
insert overwrite:会覆盖表中已存在的数据
insert overwrite table student_par select id, name from student ;
(根据单张表查询结果插入)
根据查询结果创建表
create table if not exists student3 as select id, name from student;
创建表时通过Location指定加载数据路径
create external table if not exists student5(
id int, name string
)
row format delimited fields terminated by '\\t'
location '/student;
数据导出
Insert导出
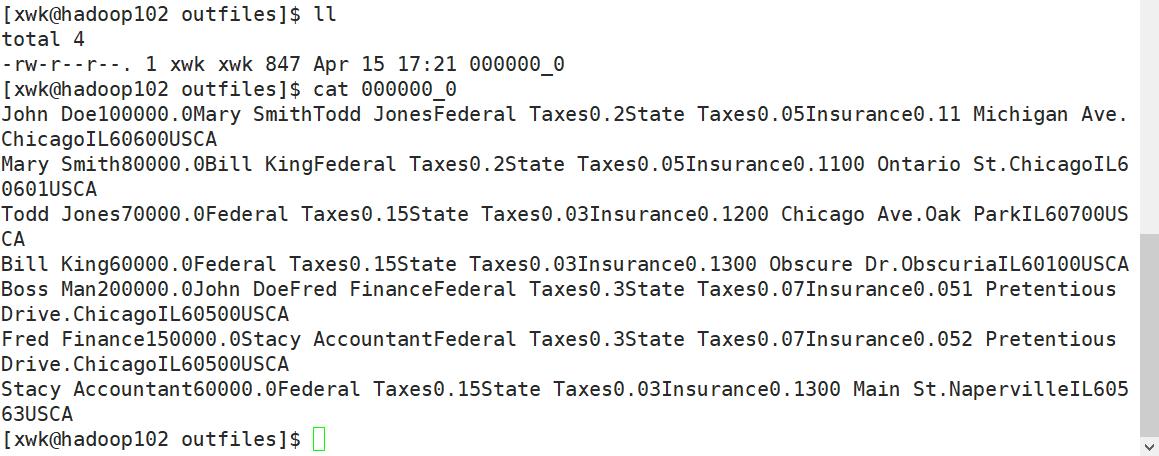
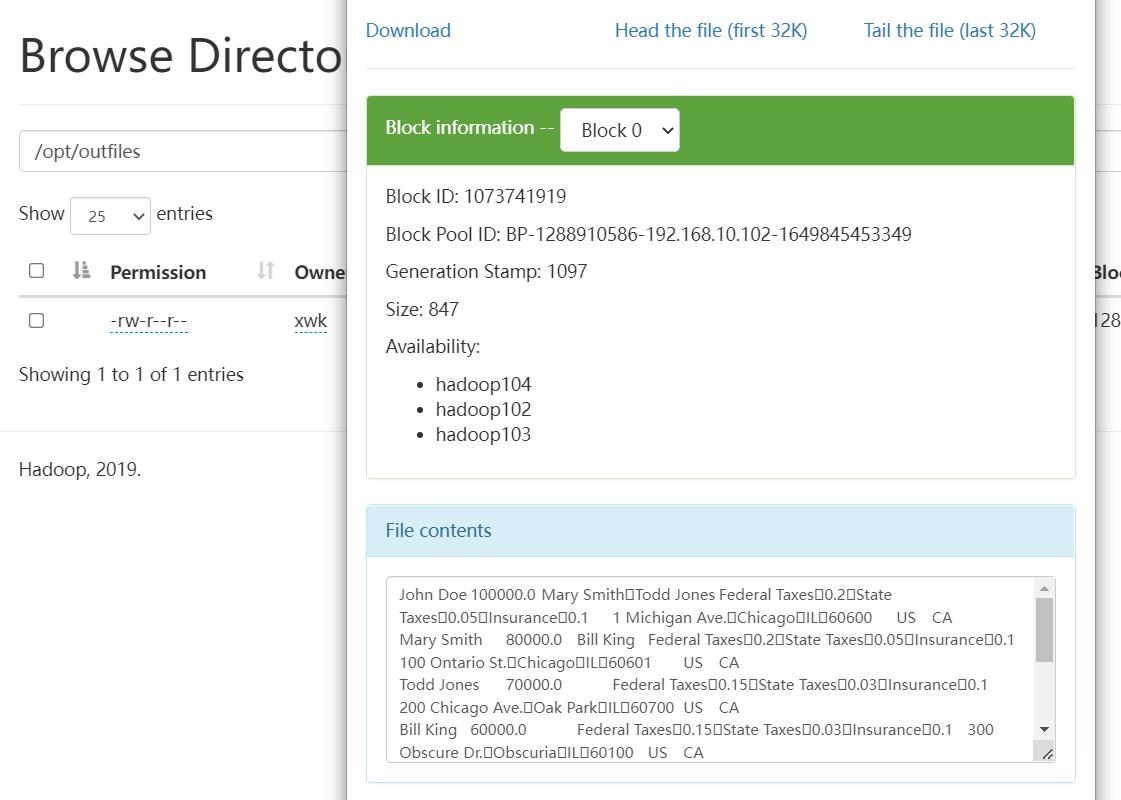
1)将查询的结果导出到本地
insert overwrite local directory '/opt/outfiles' select * from employees;
2)将查询的结果格式化导出到本地
insert overwrite local directory '/opt/outfiles'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
select * from employees;

3)将查询的结果导出到HDFS上(没有local)
insert overwrite directory '/opt/outfiles'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
select * from employees;
Hadoop命令导出到本地
dfs -get /user/hive/warehouse/learnhive.db/test2/test.txt /opt/outfiles/out_test.txt;
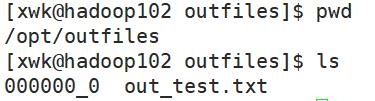
Hive Shell 命令导出
[xwk@hadoop102 outfiles]$ cd /opt/software/hive/
[xwk@hadoop102 hive]$ ./bin/hive -e 'select * from learnhive.test2;' > /opt/outfiles/out_test01.txt;

Export导出到HDFS上
export和import主要用于两个Hadoop平台集群之间Hive表迁移。
export table learnhive.test2 to '/opt/outfiles';
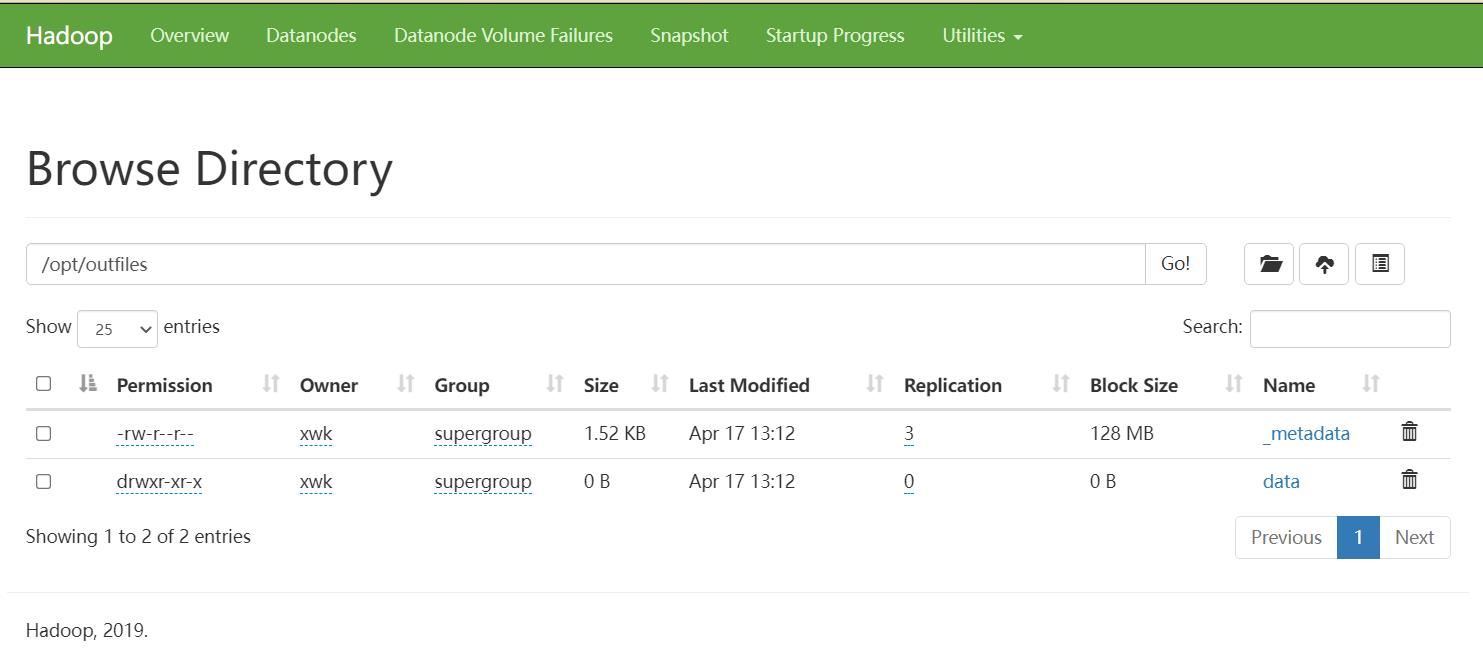
Import数据到指定Hive表中
注意:先用export导出后,再将数据导入。
先删除数据

import table test2 from '/opt/outfiles';

清除表中数据(Truncate)
注意:Truncate只能删除管理表,不能删除外部表中数据
truncate table test2;
select * from test2;
+-------------+----------------+-----------------+----------------+
| test2.name | test2.friends | test2.children | test2.address |
+-------------+----------------+-----------------+----------------+
+-------------+----------------+-----------------+----------------+
以上是关于hive 分析结果导出到一个文本中的主要内容,如果未能解决你的问题,请参考以下文章