Python_DL_TensorFlow_03_卷积神经网络与图像识别
Posted tlfox_2006
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python_DL_TensorFlow_03_卷积神经网络与图像识别相关的知识,希望对你有一定的参考价值。
1. 神经网络与CNN的异同点
-
传统的神经网络的神经元、参数比较多,而CNN可以大大简化神经元和参数的数量。但计算量要大大的提高。
-
传统神经网络采用的是f(x) = wx+b。但CNN中虽保留了层级式的网络结构,但不同层次有不同的形式,即运算和功能。输出时做归一化,转化成概率向量,让CNN能最终知道它最可能的图片意思是什么?
2. CNN层级结构
- conv layer的工作原理:conv layer中的神经元看出做一个filter(3x3x3的矩阵,每个filter都带有不同的weights,即特征不同)。每个filter都要通过窗口滑动,并进行局部计算,分别得到每个位置的不同的feature maps(有多少个filter,就有多少了feature map)。
- conv layer运算操作demo:https://cs231n.github.io/assets/conv-demo/index.html 。其中输入数据做了zero-padding,有2个filter,每个filter有3个通道,y=wx+b,输出时深度为2的feature map,通过点乘以后得到的值。
- activation layer:


- pooling:本质是降维,在保证大多数的数据的情况下,把维度降下来有两种办法:1. 取max值,2. 求平均。
- FC layer:两层之间的所有神经元都有权重连接,并出现在CNN的尾部。
3. 卷积神经网络训练算法
- FP是利用y=(wx+b),再激励函数做激励。
- BP就是对激励函数后的值算dw和db的偏导,最终在BP传播的过程中利用SGD进行更新w和b。
4. 正则化,过拟合
- Regulation:L1&L2,防止overfitting
- Dropout:随机设置50%输出的值为0,而下一次再把设置改回来,再随机设置50%的输出值为0.
正文

1. 神经网络与卷积神经网络
神经网络可以处理各种数据,由文本数据、图像数据、语音数据和视频数据等等。在处理图像数据的神经网络就是CNN,它主要完成分类工作。

传统的神经网络的神经元、参数比较多,而CNN可以大大简化神经元和参数的数量。但计算量要大大的提高。
1)CNN层次结构
传统神经网络采用的是f(x) = wx+b。但CNN中虽保留了层级式的网络结构,但不同层次有不同的形式,即运算和功能。输出时做归一化,转化成概率向量,让CNN能最终知道它最可能的图片意思是什么?


CNN的核心三层:conv为convolution layer,ReLU为activation layer,Pool为pooling layer。有时,conv layer和ReLU一起叫做conv layer。
FC layer是全连接层,它的相邻层都是全连接。
Batch Normalization层是个高级层次(15年提出),主要是训练用的。


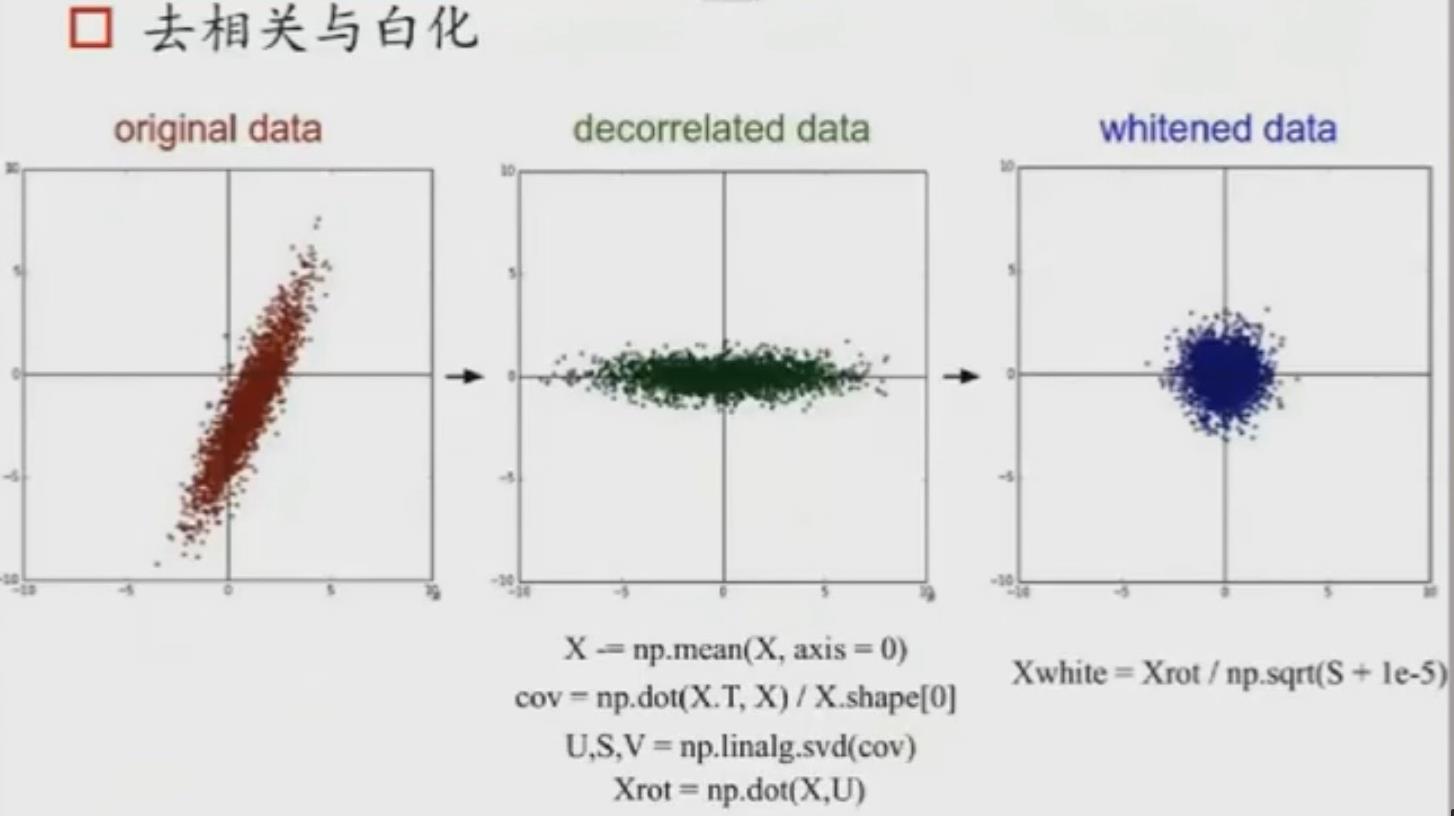
二维数据(x1,x2),做中心化就是把每个值减去相应的值,平移到原点。如果不做中心化,在工业上会发现它非常容易饱和。 中心化后,(x1,x2)的scale的幅度不一样,为了后面的计算更顺利,可以做normalization,即gaining除以它的方差。
- 饱和的概念:BP是链式求导法则。如果你的activation非常大,它的导数接近0, 意味着我用梯度下降学不到东西。它就饱和了。这叫做梯度消失或梯度弥散。

有可能(x1,x2)是有关联的数据,那么我们就会将数据做纵坐标和横坐标的投影,得到的(x1,x2)维度无相关。
以上都是数据的处理方式,但对于图像,我们大多只做去均值。因为图片的像素值在0~255之间的,所以不需要对它的幅度做调整。它的维度和幅度大小都一致。scanning的操作可做可不做,因为不做不会影响后续的工作,它的维度天生就限制在一个范围内了。
取均值有两种方式,Alexnet和VGG :
- Alexnet:一张彩色图片是227x227x3,它去均值有两种方式:把所有训练集里的1W张图片的227x227x3的矩阵加在一起,再除以1W,得到一个均值的矩阵227x227x3,后续利用这个mean matrix的减法。
- VGG:一张彩色图片是227x227x3,是三个通道,分别是RGB。可以简单认为 它是3维的向量,VGG是在这3个通道上,分别去剪掉这三个均值。
1.1) conv layer
conv layer的工作原理:conv layer中的神经元看出做一个filter(3x3x3的矩阵,每个filter都带有不同的weights,即特征不同)。每个filter都要通过窗口滑动,并进行局部计算,分别得到每个位置的不同的feature maps(有多少个filter,就有多少了feature map)。
- 深度表示有多少个filter参与了计算,就有多少个feature map,深度就是多少,也是下一层filter的个数。
- 步长表示窗口滑动的间隔大小。
- 填充值:有时候输入数据的窗口,不能被filter的窗口和步长整除,所以要做padding,在边缘补一圈0。


conv layer的数据处理:我们的filter是3x3的矩阵,利用filter和原始数据的相应位置上的矩阵做运算(Σwx),得到加权求和的值(-8),
conv layer参数共享机制:每个神经元连接数据窗的权重weights是固定的,可以看成是不同的模板,并且灭个weight值关注自己的特性。

1.2) activation layer
通过卷积后,我们还需要利用激励函数对卷积(点乘,y=Σwx+b)的值进行激励。
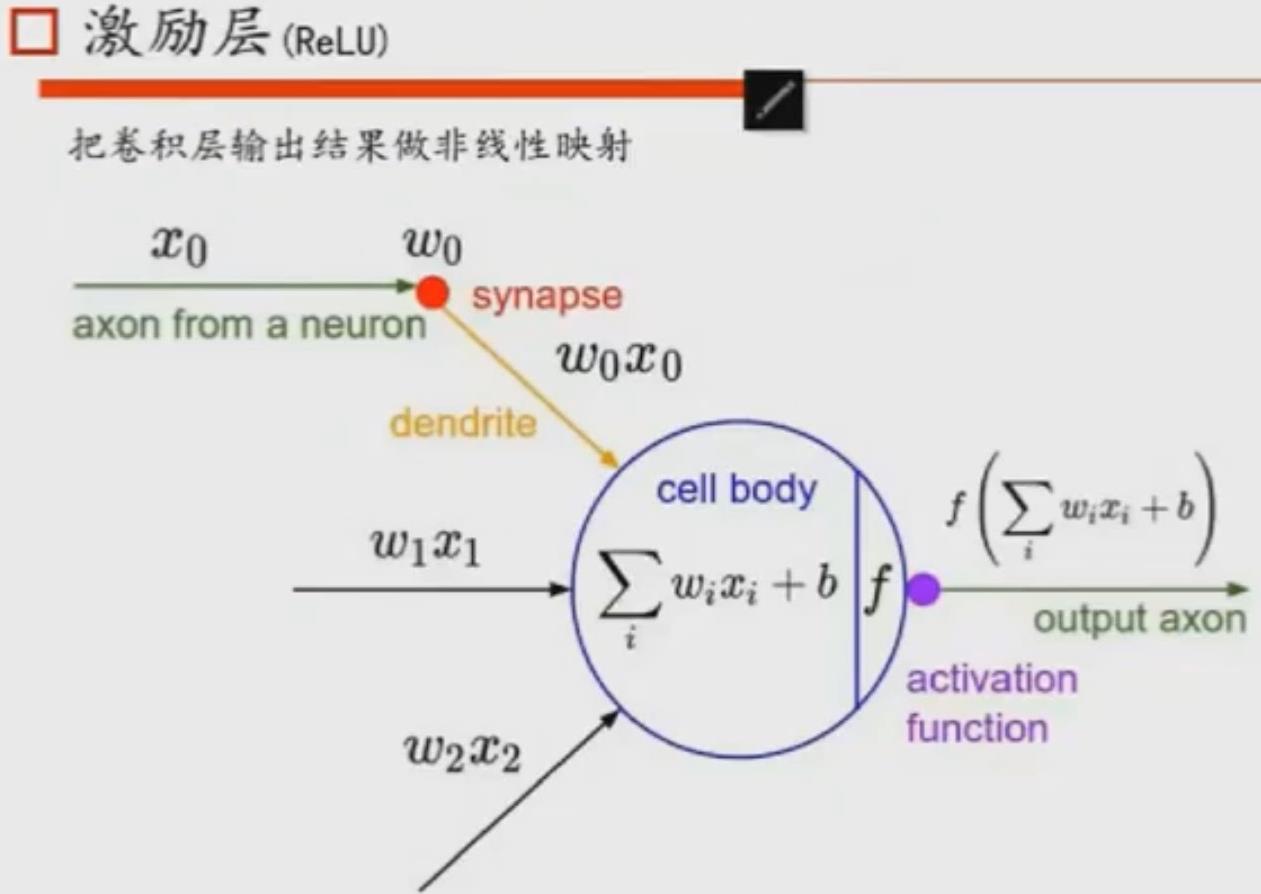
- sigmoid和tahn的缺点就是他们的梯度弥散问题(饱和)。
- ReLU:max(0,x),当输入是负数时,为0, 当输入是正数时,为输入值。
- leaky ReLu,当输入为负数时,权重为很小。
- ELU:当输入为负数时,激励函数为a(ex-1)

1.3) 池化/pooling layer
2012-》2013年的2Fnet的冠军没有结构上的改变,但是改变了filter的个数,所以利用pooling把大部分的信息留下就好,称为下采样。


pooling本质是降维,在保证大多数的数据的情况下,把维度降下来,有两种操作办法:1. 取max值,2. 求平均。
1.4) FC layer
FC layer:两层之间的所有神经元都有权重连接,并出现在CNN的尾部。

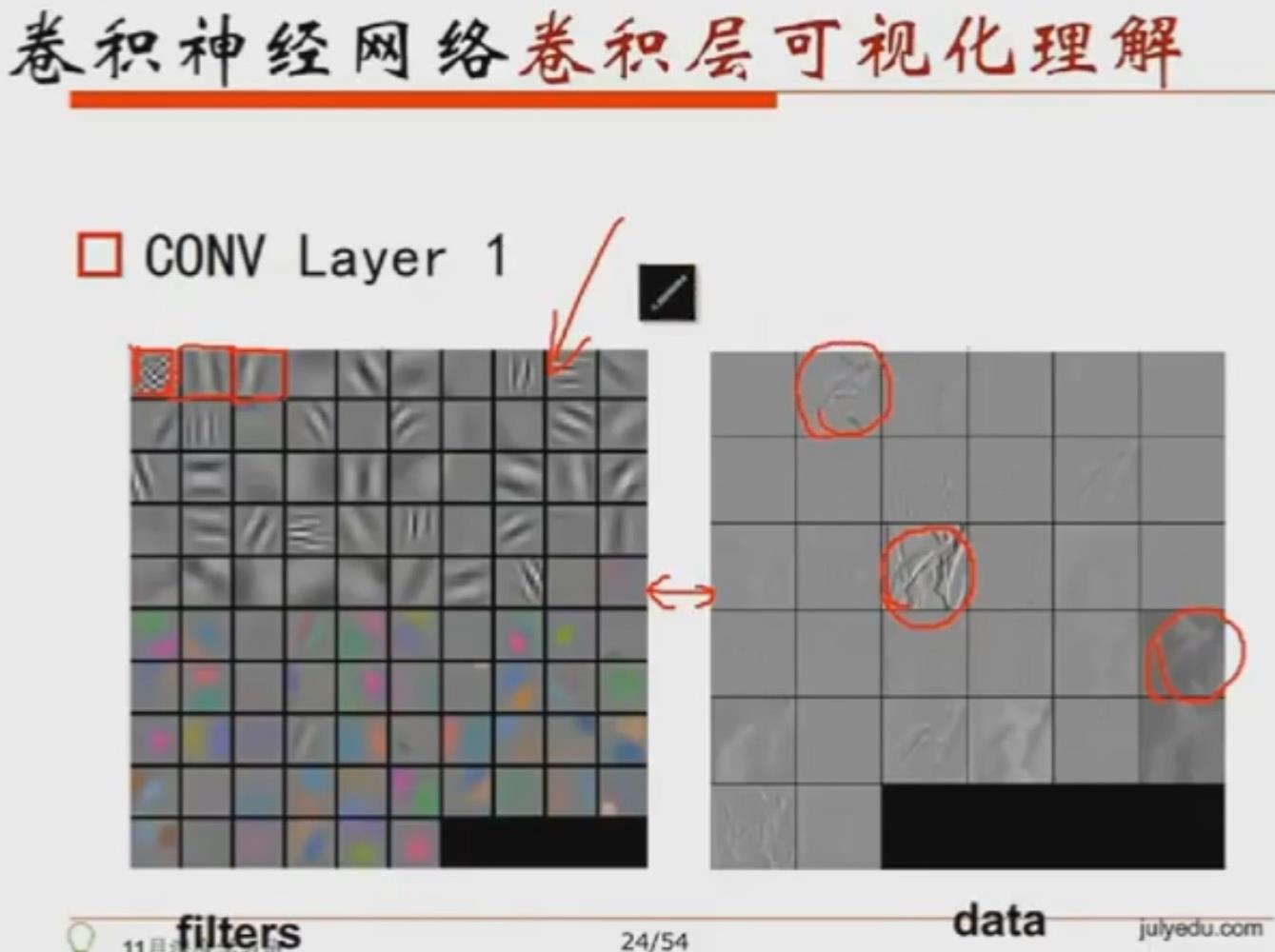
1.5) 卷积层可视化理解
图片为输入数据,每个卷积层的左图为filter,右图为通过卷积后的data。



3)卷积神经网络训练算法
BP就是对激励函数算dw和db的偏导,最终在BP传播的过程中利用SGD进行更新w和b。


4) 卷积神经网络优缺点:

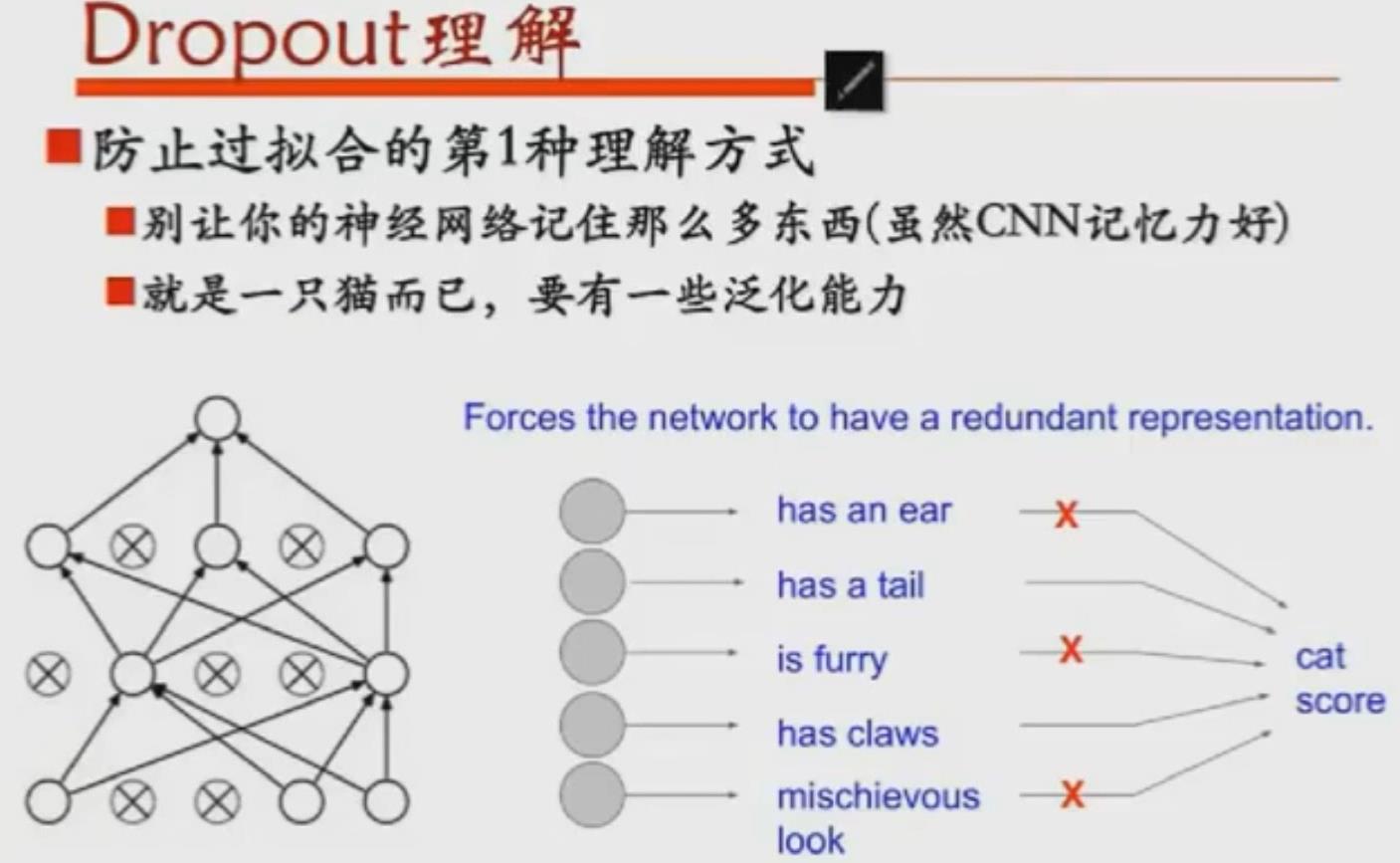
2. 正则化
Regulation:L1&L2,防止overfitting
Dropout:随机设置50%输出的值为0,而下一次再把设置改回来,再随机设置50%的输出值为0.


3. 经典结构与训练





AlexNet为了得到很多的信息,把步长设置为1,这样扫图就会更仔细。
以上是关于Python_DL_TensorFlow_03_卷积神经网络与图像识别的主要内容,如果未能解决你的问题,请参考以下文章