python网络爬虫——requests模块(第二章)
Posted huoxc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python网络爬虫——requests模块(第二章)相关的知识,希望对你有一定的参考价值。
网络爬虫之requests模块
今日概要
- 基于requests的get请求
- 基于requests模块的post请求
- 基于requests模块ajax的get请求
- 基于requests模块ajax的post请求
- 综合项目练习:爬取国家药品监督管理总局中基于中华人民共和国化妆品生产许可证相关数据
知识点回顾
- 常见的请求头
- 常见的相应头
- https协议的加密方式
基于如下5点展开requests模块的学习
什么是requests模块
- requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求。功能强大,用法简洁高效。在爬虫领域中占据着半壁江山的地位。
为什么要使用requests模块
因为在使用urllib模块的时候,会有诸多不便之处,总结如下:
- 手动处理url编码
- 手动处理post请求参数
- 处理cookie和代理操作繁琐
使用requests模块:
- 自动处理url编码
- 自动处理post请求参数
- 简化cookie和代理操作
如何使用requests模块
安装: pip install requests
requests作用:
就是一个基于网络请求的模块,可以用来模拟浏览器发请求。
使用流程
- 指定一个字符串形式的url
- 发起请求(基于requests模块发起请求 )
- 获取响应对象中的数据值
- 持久化存储
通过基于requests模块的爬虫项目对该模块进行学习和巩固
基于requests模块的get请求
- 需求:爬取搜狗首页的页面源代码
import requests
#1以字符串的形式指定url
url = ‘https://www.sogou.com/‘
#2发送请求
response = requests.get(url=url)#get返回一个响应对象
#3获取响应数据,响应数据在响应对象中
page_text = response.text#获取字符串形式的响应数据
print(page_text)
#4持久化存储
with open(‘./sogou.html‘,‘w‘,encoding=‘utf-8‘) as fp:
fp.write(page_text)#将字符串写入到文件中
需求:实现一个简易的网页采集器,即可以在搜狗中录入任何一个关键字,点击搜索,就能得到响应的页面,(爬取到任意关键字对应的页面源码数据)
如下操作:
搜索:Jay,获取其中的一部分url也能访问,
https://www.sogou.com/web?query=jay
#1.以字符串的形式指定url
url = ‘https://www.sogou.com/web?query=jay‘
#2.发送请求
response = requests.get(url=url)#返回一个响应对象
#3获取响应数据
page_taxt = response.text#获取字符串形式的响应数据
#4持久化存储
with open(‘./jay.html‘,‘w‘,encoding=‘utf-8‘) as fp:
fp.write(page_text)
当运行时出现以下结果

问题总结:
- 出现了乱码问题
- 爬取的数据量级有问题
解决乱码问题:
#1.以字符串的形式指定url
url = ‘https://www.sogou.com/web?query=jay‘
#2.发送请求
response = requests.get(url=url)#返回一个响应对象
#response.encoding #可以返回原始数据的编码格式
response.encoding = ‘utf-8‘ #将编码改成utf-8的形式
#3获取响应数据
page_text = response.text#获取字符串形式的响应数据
#4持久化存储
with open(‘./jay.html‘,‘w‘,encoding=‘utf-8‘) as fp:
fp.write(page_text)
解决数据量的问题
其中给出了,数据量有问题的原因:

- 当次的请求被搜狗认定为是一个异常的请求
- 什么是异常的请求?
- 服务器端检测到该次请求不是基于浏览器访问。使用爬虫程序发起的请求就是异常的请求
- 对方的服务器怎么认定出当前请求是由浏览器发起的那,还是浏览器发起的那
用User- -Agent::
本身是请求头中的一个信息。
概念:请求载体的身份标识。
- 发起的请求的载体:可以是浏览器,可以是爬虫程序(请求载体是什么可以抓取数据包来观测)
- 抓包工具的使用:
右键——》审查元素——》NetWork——》重新回车就可以抓取数据
其中每一个数据包对应某一个请求的
捕获数据:
打开其中的任意的一个请求
即遇到了一个反爬机制,叫做UA检测:
UA检测:
- 对方服务器端会检测请求载体的身份标识,如果不是基于某一-款浏览器 的身份标识则认定为是一个异常请求,则不会响应会正常的数据
解决方法:反反爬策略: UA伪装
- 将爬虫程序发起的异常的请求载体标识伪装或者修改成某一款浏览 器的身份标识即可
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36
现在正确的爬取方式如下:
#1.以字符串的形式指定url
url = ‘https://www.sogou.com/web?query=jay‘
#使用UA伪装
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36‘
}
#2.发送请求
response = requests.get(url=url,headers=headers)#返回一个响应对象
#response.encoding #可以返回原始数据的编码格式
response.encoding = ‘utf-8‘ #将编码改成utf-8的形式
#3获取响应数据
page_text = response.text#获取字符串形式的响应数据
#4持久化存储
with open(‘./jay.html‘,‘w‘,encoding=‘utf-8‘) as fp:
fp.write(page_text)
参数动态化:可以动态的给请求指定请求参数
key = input("Enter a word:")
#将请求参数封装成键值对
params = {
‘query‘:key
}
#1.以字符串的形式指定url
url = ‘https://www.sogou.com/web?query=jay‘
#使用UA伪装
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36‘
}
#2.发送请求
response = requests.get(url=url,headers=headers,params=params)#返回一个响应对象
#response.encoding #可以返回原始数据的编码格式
response.encoding = ‘utf-8‘ #将编码改成utf-8的形式
#3获取响应数据
page_text = response.text#获取字符串形式的响应数据
fileName = key+‘.html‘
#4持久化存储
with open(‘fileName‘,‘w‘,encoding=‘utf-8‘) as fp:
fp.write(page_text)
print(fileName,‘爬取成功!!!‘)
爬取动态加载的数据
什么是动态加载的数据:
- 需求:爬取豆瓣中更多的电影详情
- 为什么叫更多的:
因为:当滚轮拖动到底部,回弹之后加载出了更多的电影,滑动可以获取更多的数据
说明:发送了ajax请求该次请求会加载出更多的数据(其中的url,我们只能获取一屏高度的数据)
- 如果想要获取更多的数据,那么捕获这个ajax请求
- 其中如果不在第一页中的电影数据,get请求是获取不到的,其中《阿凡达》就获取不到,如果想要获取,即动态加载,通过了ajax请求,才给我们加载了一组新的数据,这组数据一定不存在,当前地址栏输入对应的url所对应的数据,所以这部阿凡达被称之为动态加载数据。
动态加载数据:所谓动态加载的数据是指不是通过浏览器地址栏的url请求到的数据。
怎样捕获动态加载数据:
抓包工具的使用:
右键——》审查元素——》NetWork——》刷新页面,发送请求
首先找到地址栏URL所对应的的数据包:
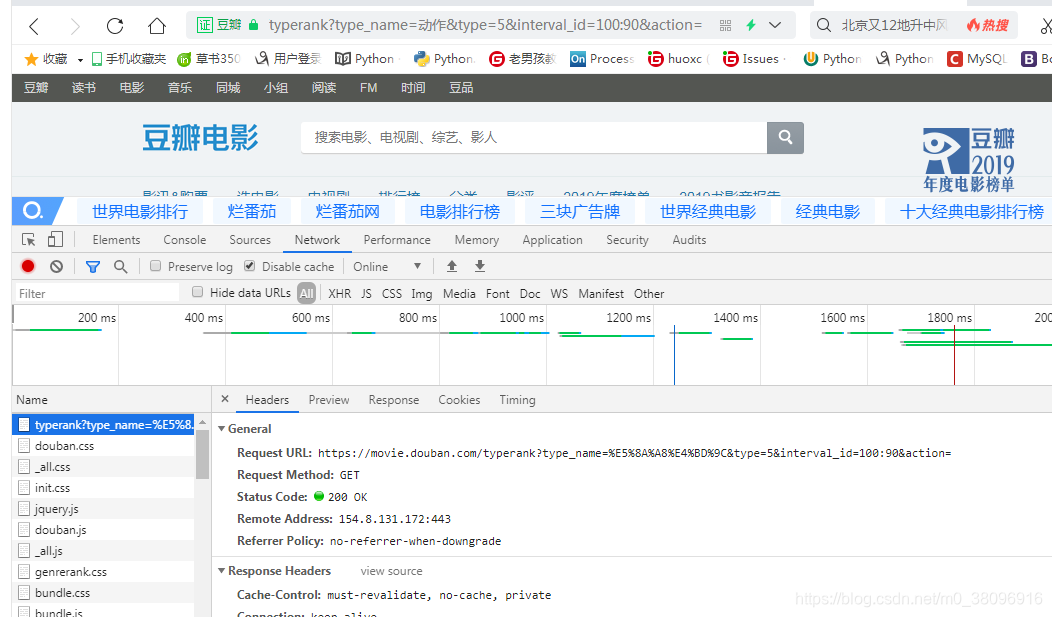
说明地址栏URL所对应的数据包,
其中response代表:requests.get()方法请求到的,页面数据,在这组数据中搜索,有没有《阿凡达》,用Ctrl+F搜索
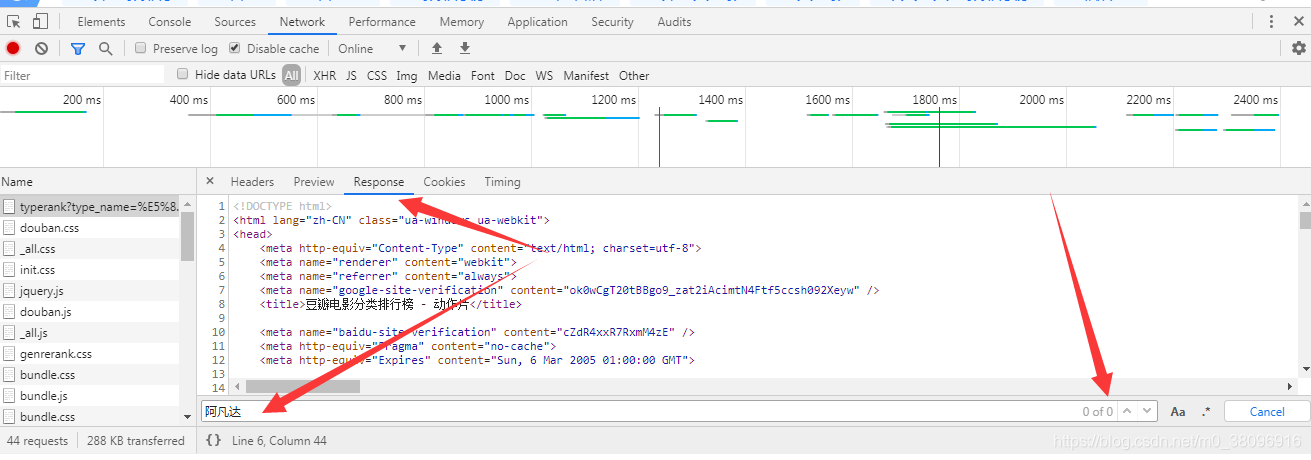
结果没有
总结:-基于抓包工具做局部搜索(在抓包工具中找到地址栏ur1对应的数据包,在其response这个选项卡下进行搜索爬取数据的关键字)
如何爬取动态加载的数据?
基于抓包工具做全局搜索
all代表捕获全部数据,其中XHR代表,凡是发送ajax请求数据全部能捕获到
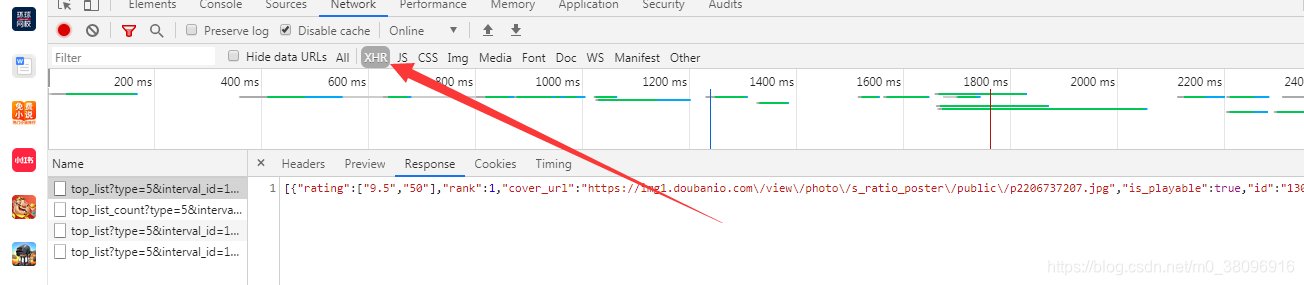
当滚轮向下滑动的时候,就会捕获到相应的数据
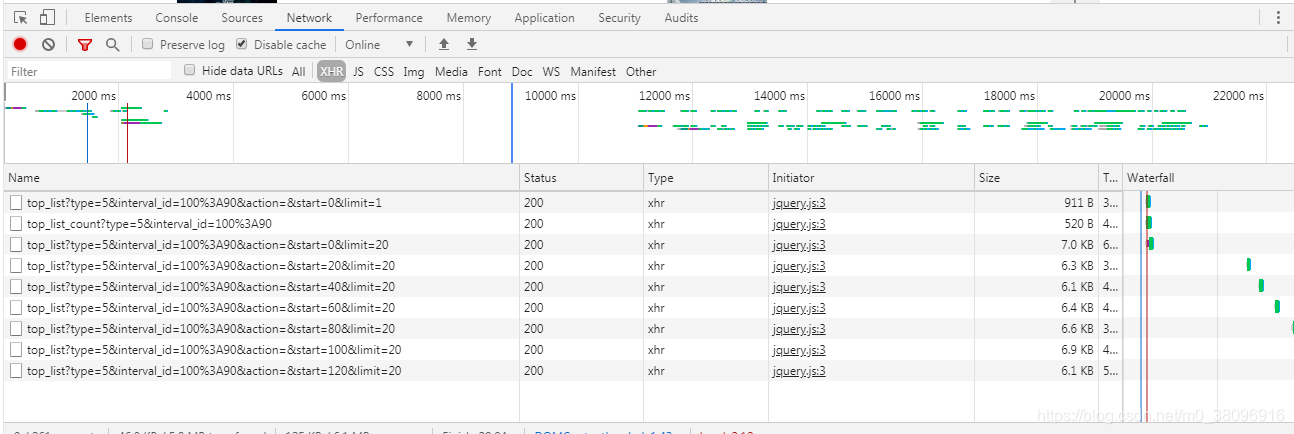
然后就会获取到对应的url
在response中是请求到的数据
其中所需要的数据是在哪一个数据包中,怎么找
选中其中的某一个,再Ctrl+f搜索就可以了
则会显示存在哪一个数据包中
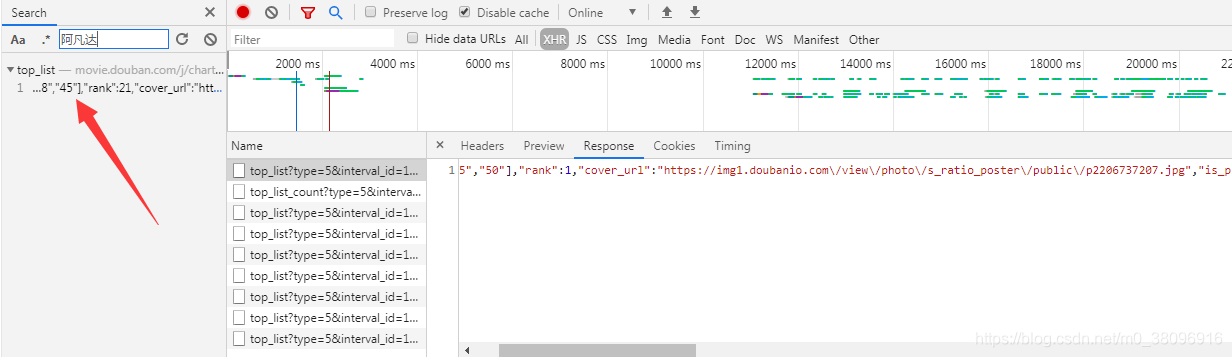
基于抓包工具做全局搜索,可以帮我们定位到动态加载的数据到底是存在于哪一一个数据
包中,定位到之后,就可以对该数据包的url进行请求发送捕获数据。
地址;

参数:
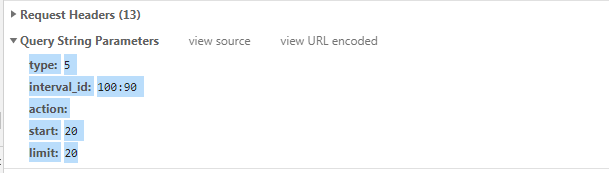
url = ‘https://movie.douban.com/j/chart/top_list‘
params = {
‘type‘: ‘5‘,
‘interval_id‘: ‘100:90‘,
‘action‘: ‘‘,
‘start‘: ‘20‘,
‘limit‘: ‘20‘,
}
#使用UA伪装
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36‘
}
#返回的数据为json字符串,当用.json时返回列表对象
data_list = requests.get(url=url,headers=headers,params=params).json()
#做解析
for dic in data_list:
title = dic[‘title‘]
score = dic[‘score‘]
print(title,score)
问题:怎么判断是json数据;
动态加载数据的生成方式:
- ajax请求
- . js
日后对一个陌生的网站进行数据爬取,在编码之前必须要做的一件事情是什么?
检测你要爬取的数据是否为动态加载的数据:
- 如果不是动态加载数据就可以直接对地址栏的url发起请求爬取数据
- 如果是动态加载数据就需要基于抓包工具进行全局搜索爬取数据
需求:-
http: //www.kfc.com.cn/kfccda/storelist/index.aspx
将北京所有肯德基餐厅的位置信息进行爬取
- 首先:输入网址,搜索:北京
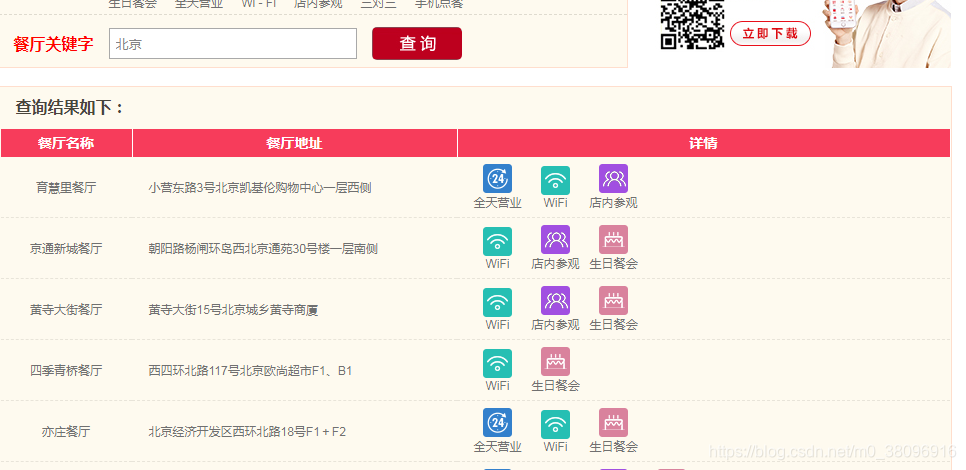
2:判断是不是动态加载的,怎么检测,打开抓包工具;
做一个局部搜索,如果搜不到,那就意味着数据是动态加载的
首先加载数据:
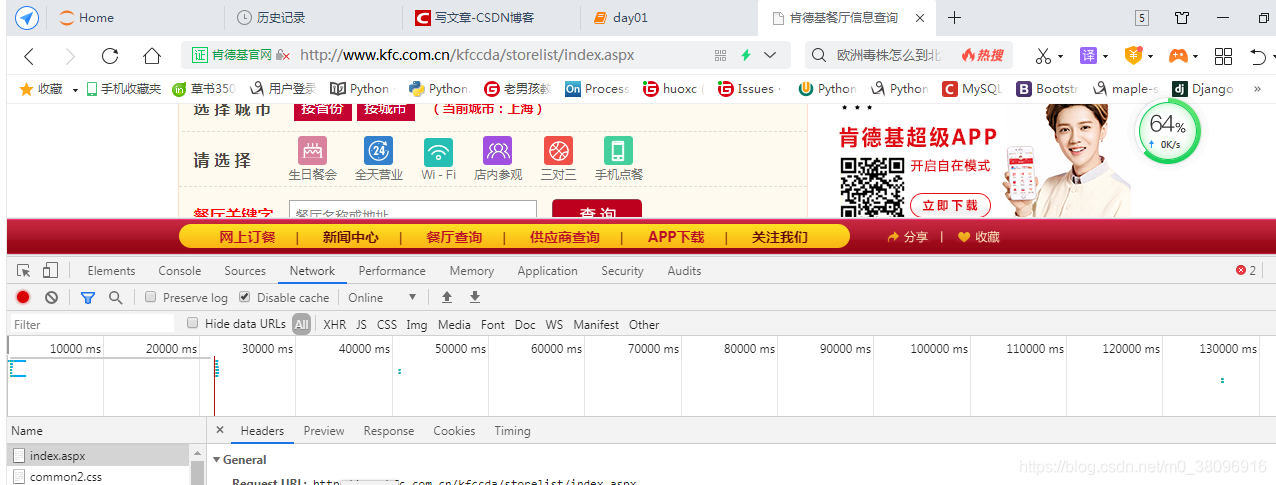
第二:找到与地址栏中相同的URL
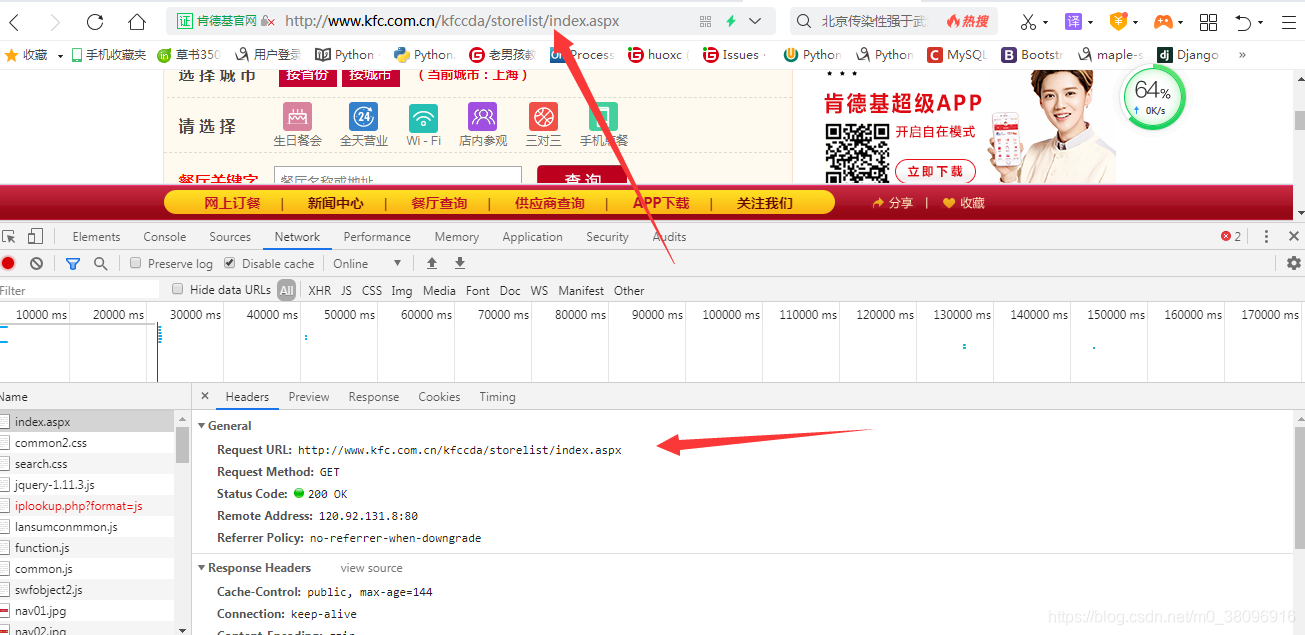
第三步:来到response中,进行局部搜索,也可以点击preview,因为preview是可也做response的展示,如果在preview中没有数据则表明数据是动态加载的
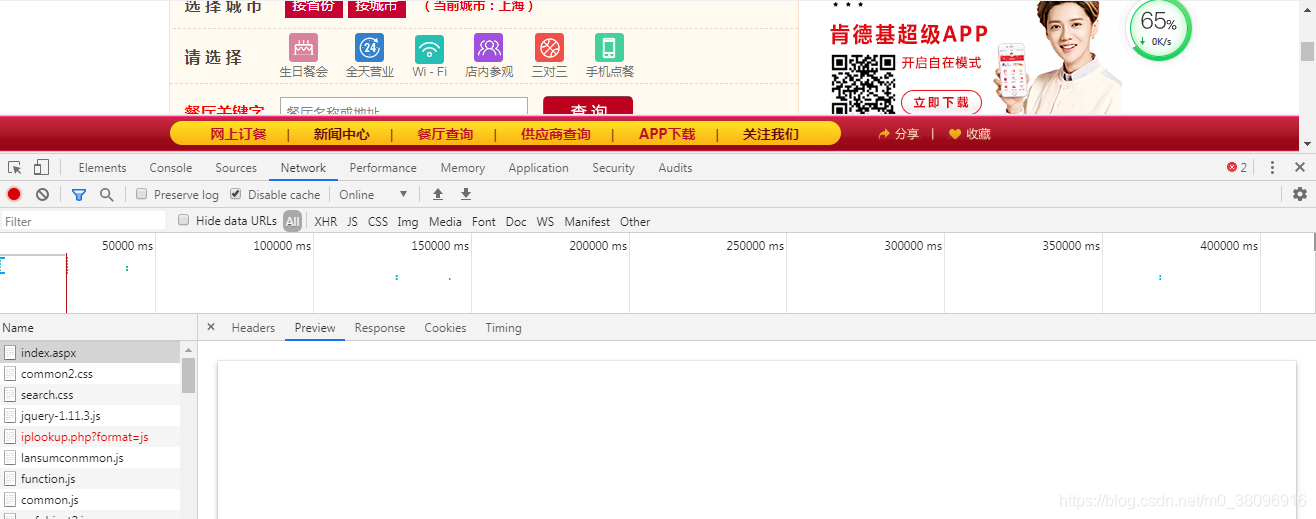
当输入北京时定位到XHR,就会发现,它发的是ajax请求
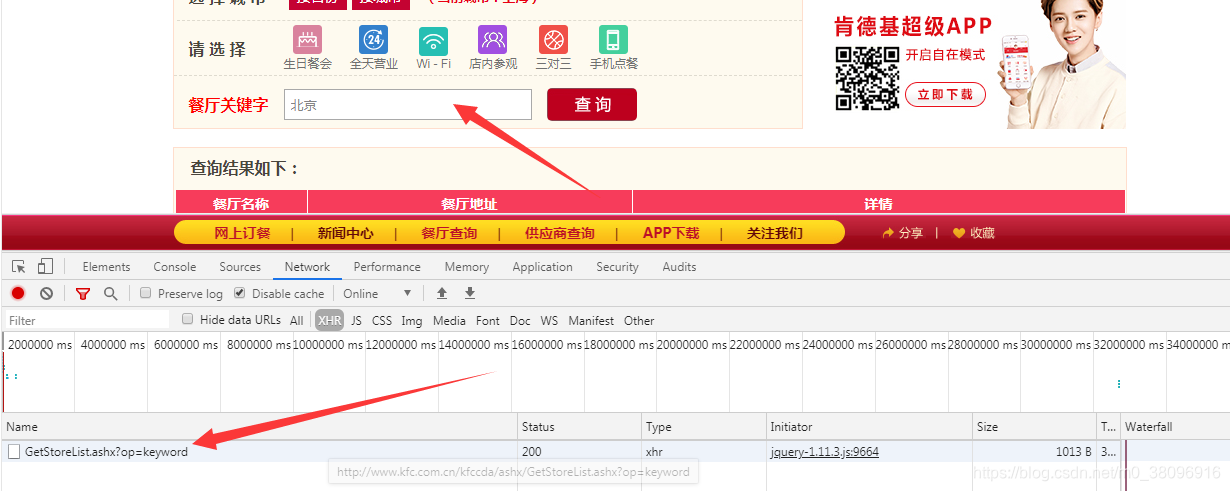
点击查看对应的请求的url,请求的方式,以及响应的数据,其中post会携带请求的参数,则需要做参数动态化
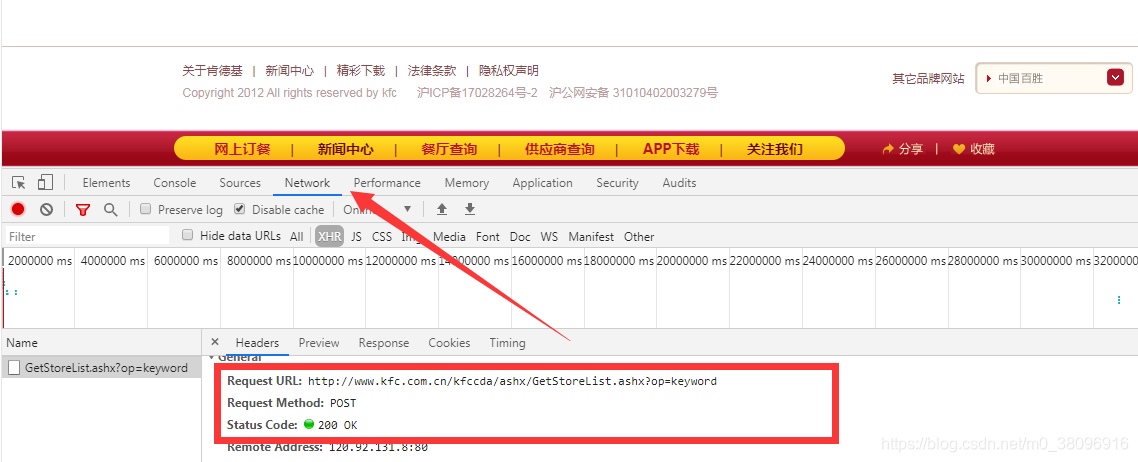
#1.以字符串的形式指定URL
url = ‘http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword‘
#参数动态化
data = {
‘cname‘:‘‘ ,
‘pid‘:‘‘ ,
‘keyword‘: ‘北京‘,
‘pageIndex‘: ‘1‘,
‘pageSize‘: ‘10‘,
}
#发送请求:在post请求中,参数动态化使用的是data
data_dict = requests.post(url=url,headers=headers,data=data).json()
print(data_dict)
其中拿到的是第一页的数据

如果想要获取所有的数据怎么办,当点击第二页的数据,获取到了第二个ajax的请求,只有请求的参数不一样,其他都一样,写for循环就可以了
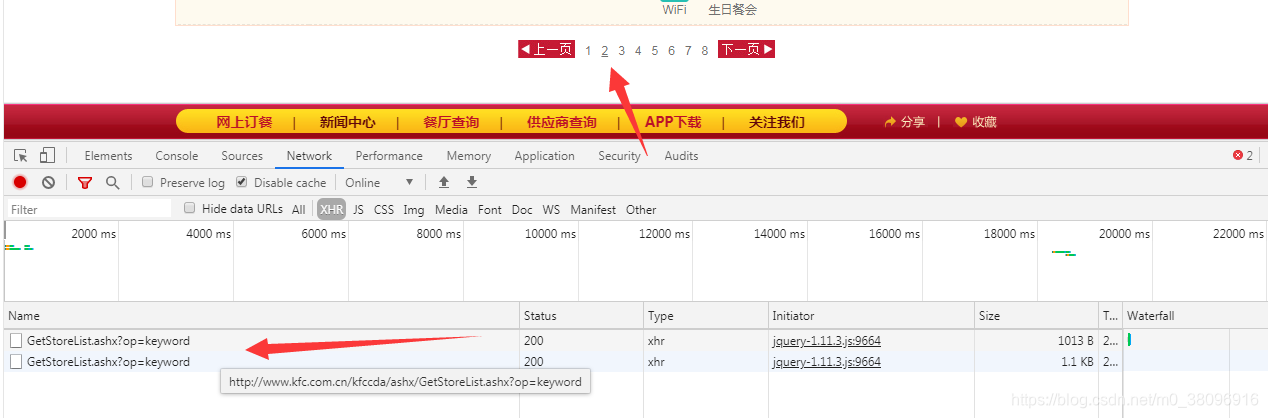

import requests
#1.以字符串的形式指定URL
url = ‘http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword‘
city = input(‘Enter you city:‘)
for page in range(5):
#参数动态化
data = {
‘cname‘: ‘‘ ,
‘pid‘: ‘‘ ,
‘keyword‘: ‘北京‘,
‘pageIndex‘: str(page),
‘pageSize‘: ‘10‘,
}
#发送请求:在post请求中,参数动态化使用的是data
data_dict = requests.post(url=url,headers=headers,data=data).json()
print(data_dict)
总结:两步操作
1:局部搜索检测是否是动态加载的;
2:如果是动态加载的,那么要全局搜索搜数据;搜数据的目的是为了能够定位到,咋们动态加载数据所对应的的数据包到底是哪一个,对数据包中的URL和请求参数做一个提取,就可以对其请求发送
以上是关于python网络爬虫——requests模块(第二章)的主要内容,如果未能解决你的问题,请参考以下文章