当我学完 Python ,我学会了些什么
Posted qq3140781314
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了当我学完 Python ,我学会了些什么相关的知识,希望对你有一定的参考价值。

本文是本人学完Python后的一遍回顾,加深理解顺便留作手册以备查阅。
学习Python的这几天来,觉得Python还是比较简单,容易上手的,就基本语法而言,但是有些高级特性掌握起来还是有些难度,需要时间去消化。Python给我最大的印象就是语法简洁,就像写伪代码一样,很多其他语言要用很多行才能实现的操作Python可能几行就搞定了,这让人摆脱了繁杂的语法而专注于问题本身,这也正是我为什么不太喜欢Java的原因之一,虽然它很强大。
一、Python简介
Python是一种用来编写应用程序的高级程序设计语言,TIOBE程序语言排行榜2016年4月的排名如下:
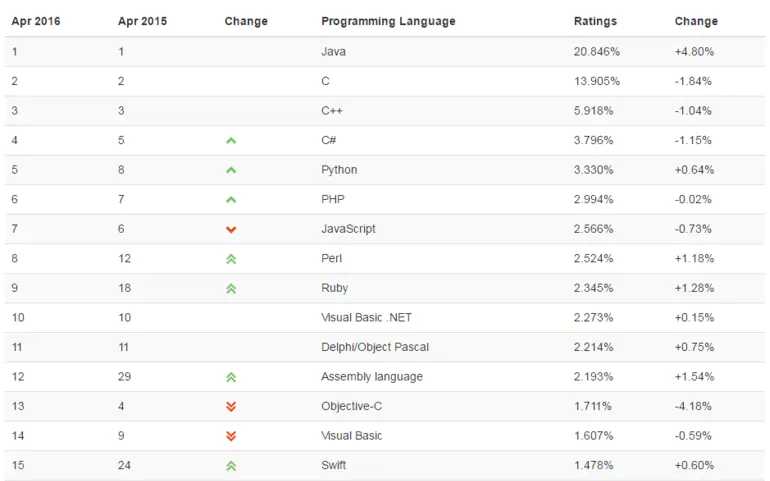
Python实现强势逆袭,而且我相信,随着时间的推移,国内Python语言未来前景也是一片向好。
Python的特点是优雅简单,易学易用(虽然我感觉还是有一些概念不容易理解),Python的哲学是尽量用最少的,最简单易懂的代码实现需要的功能。Python适宜于开发网络应用,脚本写作,日常简单小工具等等。Python的缺点是效率较低,但是在大量的场合效率却不是那么重要或者说Python不是其性能瓶颈,所以不要太在意。其次是2.x-3.x的过渡使得许多3.x还缺少很多2.x下的模块,不过也在完善中。其次就是源代码无法加密,发布Python程序其实就是发布源代码。
二、基础语法要点
1.如果一个字符串中有许多需要转义的字符,而又不想写那么多,那么可以用 r‘...‘ 表示 ‘...‘内的内容不转义。
2.Python可用‘‘‘...‘‘‘来表示多行内容,如:
>>> print(‘‘‘line1
line2
line3‘‘‘)
line1
line2
line3
3.Python的逻辑运算and, or, not 分别对应C语言中的&&, ||, !.
4.Python的整数与浮点数大小都没有范围。
5.Python中除法有两种: /除出来必是浮点数, //除出来是整数,即地板除。
6.Python中一切皆引用。每个对象都有一个引用计数器(内部跟踪变量)进行跟踪,引用计数值表示该对象有多少个引用,当初次产生赋给变量时,引用计数为1,其后没进行下列行为中的任意一种都会增加引用计数:
赋值: a = b
用作函数参数传递: func(a)
成为容器对象的一个元素: lis = [1,2,a]
以下任意一种行为都会减少引用计数:
del销毁: del a
变量另赋给其他对象:a = False
对象从容器中删除: lis.remove(a)
身在的容器被销毁: del lis
7.深拷贝与浅拷贝的概念与对比,有点复杂,看这篇文章
8.list,tuple和dict,set
list: 为列表,是一个有序集合,类似于数组但又比数组功能强大,可以随时append,pop元素,下标从0开始,且下标为加n模n制,即lis[-1] = lis[len-1],下标范围[-len,len-1].
tuple:为元组,类似于list,但list为可变类型,而tuple不可变,即没有append,pop等函数。一个建议是为了安全起见,能用tuple代替list尽量用tuple。如果tuple只有一个元素,要写成如(1,)以避免歧义。
dict:字典类型,存放key-value键值对,可以根据key迅速地找出value,当然,key必须是不可变类型,如下是错误的:
>>> dic = {[1,2]:‘value‘}
Traceback (most recent call last):
File "<pyshell#10>", line 1, in
dic = {[1,2]:‘value‘}
TypeError: unhashable type: ‘list‘
list与dict的优劣对比:
dict:
1.插入,查找速度快,跟key的数目无关
2.需占用大量内存,内存浪费严重
list:
1.插入,查找速度慢,O(n)的复杂度,随元素个数增加而增加
2.占用内存小
dict内部存放的顺序和key放入的顺序是没有关系的
set:set与dict类似,相当于只有key没有value的dict,每个key不同,set间有 &, | 等操作对应集合的交,并操作。
三、函数
1.函数是对象,函数名即是指向对应函数对象的引用,所以可以将函数名赋给一个变量,相当于给函数起一个‘别名’。
>>> mmm = max
>>> mmm(1,2,3)
32.Python函数可以返回“多个值”,之所以打引号,是因为实际上返回的多个值拼成了一个元组,返回这个元组。
3.定义默认参数需要牢记:默认参数必须指向不变对象。否则第一次调用和第二次调用结果会不一样,因为可变的默认参数调用后改变了。
4.可变参数:传入的参数个数是可变的,可以是0个或多个。可变参数会将你传入的参数自动组装为一个tuple。在你传入的list或tuple名字前加一个 * 即说明传入的是可变参数。习惯写法为*args。
5.关键字参数:传入0个或多个含参数名的参数,这些参数被自动组装成一个dict。习惯写法**kw,如**a表示把a中所有的键值对以关键字参数的形式传入kw,获得一个dict,这个dict是a的一份拷贝,对kw改动不会传递到a
6.命名关键字在函数定义中跟在一个*分割符后,如
def func(a,b,*,c,d):
pass
c,d为命名关键字参数,可以限制调用者可以传入的参数名,同时可以提供默认值。
7.参数定义顺序:必选参数,默认参数,可变参数/命名关键字参数,关键字参数。
8.切片操作格式为lis[首下标:尾下标:间隔],如果都不填,即lis[::]则代表整个容器lis
9.用圆括号()括起来一个列表生成式创建一个生成器generator,generator保存生成算法,我们可以用next(g)取得生成器g的下一个返回值。生成器的好处就是我们不需要提前生成所有列表元素,而是需要时再生成,这在某些情况下可以节省许多内存。算法也可以不是列表生成式而是自定义函数,只需在函数定义中包含yield关键字。
10.map()和reduce(): 二者都是高阶函数。map()接收两个参数,一个是函数,一个是Iterable序列,map将传入的函数依次作用在序列每一个元素上,并把结果作为新的Iterator返回。reduce()类似累积计算版的map(),把一个函数作用在一个序列上,每次接收两个参数,将结果继续与序列的下一个元素做累积计算。
利用map和reduce编写一个str2float函数,如把字符串‘123.456‘转换成浮点数123.456:
from functools import reduce
def str2float(s):
def f1(x,y):
return x*10 + y
def char2num(s):
return {‘0‘: 0, ‘1‘: 1, ‘2‘: 2, ‘3‘: 3, ‘4‘: 4, ‘5‘: 5, ‘6‘: 6, ‘7‘: 7, ‘8‘: 8, ‘9‘: 9}[s]
def f2(x,y):
return x*0.1 + y
a,b = s.split(‘.‘)
print(‘a=‘,a)
print(‘b=‘,b)
return reduce(f1, map(char2num,a)) + 0.1*reduce(f2, map(char2num,b[::-1]))
print(‘str2float(‘123.456‘) =‘, str2float(‘123.456‘))
11.fliter()函数过滤序列,类似于map()作用于每一元素,根据返回值是True或者False决定舍弃还是保留该元素。函数返回一个Iterator。
12.sorted()函数可实现排序,类似于C++库中的sort()函数,但是比其更加简洁,语法为sorted(lis,key=func,reverse=T/F)
key函数可实现自定义的排序规则,reverse表示升序还是降序。
13.一个函数可以返回一个函数,但是返回时该函数并未执行,所以返回函数中不要引用任何可能发生变化的变量,否则会出现逻辑错误。
14.装饰器(decorator): 当需要增强函数的功能却不希望修改函数本身,那么可以采用装饰器这种运行时动态增加功能的方式,增加的功能卸载装饰器函数中。如在执行前后打印‘begin call‘和‘end call‘,可以这样做:
import functools
def log(func):
@functools.wraps(func) #为了校正函数签名,最好写上
def wrapper(*args,**kw):
print(‘begin call‘)
f = func(*args,**kw)
print(‘end call‘)
return f
return wrapper
@log
def hah():
print(‘hahahaha‘)
hah()
---
begin call
hahahaha
end call
15.偏函数: functools.partial(),作用是将一个函数的某些参数固定住,作为新函数的参数,即固定住该参数,返回一个新函数,使调用更简单。
四、面向对象编程
1.Python实例变量可以自由地绑定任何属性
2.为了不让内部属性不被外部访问,在属性的名称前加上两个下划线__,这样就变成了一个私有变量(private),注意,不能直接访问不代表一定不能访问,事实上,加双下划线后Python就会将其改名为_class名__name,所以还是可以这样来访问这个‘私有’变量。
3.对于静态语言,如果要求传入一个class类型的对象,那么传入的对象必须是class类型或者其子类,否则将无法调用class中的方法,而Python这样的动态语言有‘鸭子类型’一说,即不一定要传入class类型或其子类,而只要保证传入的对象中有要使用的方法即可。
4.如果想要限制实例可以绑定的属性,那么在定义class时定义一个__slots__变量即可,例如:
class Student(object):
__slots__ = (‘name‘,‘age‘)
注意,__slots__限制的属性对当前类实例起完全限制作用,且与子类共同定义其__slots__,也就是说子类可以定义自己的__slots__,子类实例允许定义的属性就是自身的__slots__加上父类的__slots__,即并集。
5.@ property装饰器可以使一个getter方法变成属性,如果方法名为me,那么@me.setter装饰器则可使一个setter方法变成属性。这样可以使代码更简短,同时可对参数进行必要的检查。
6.通过多重继承,可使子类拥有多个父类的所有功能。
7.在类中__call__方法可使实例对象像函数那样直接调用,作用即是该方法定义的过程。
8.ORM(Object Relational Mapping 对象关系映射),就是把关系数据库的一行映射为一个对象,也就是一个类对应一个表。ORM的实现需要通过metaclass元类修改类的定义。元类可以改变类创建时的行为。
五、调试
1.Python调试方法:
- 直接打印
- 断言
- pdb
- IDE
六、IO编程
1.序列化: 把变量从内存中变成可存储或传输的过程称之为序列化。Python用pickle模块实现序列化。序列化之后,就可以把序列化后的内容存储到磁盘上或者通过网络进行传输。pickle.dumps()将对象序列化成一个bytes,而pickle.loads()可以根据bytes反序列化出对象。
2.pickle虽好,但是它专为Python而生,所以要在不同语言间传递对象,最好还是xml或者json,而json表示格式是一个字符串,更易读取,且比xml快,所以更加适宜于对象序列化。Python内置了json模块,相应方法仍然是dumps()和loads()。
3.但是在默认情况下,有些对象是无法序列化的,所以我们有时还需要定制转换方法,告诉json该如何将某类对象转换成可序列为json格式的{}对象。如下即是一个转换方法:
def mantodict(std):
return {
‘name‘: std.name,
‘age‘: std.age,
‘id‘: std.id
}七、进程与线程
1.Python用mutiprocessing模块来实现多进程。
2.如果要大量创建子进程,可以使用进程池,示例如下:
from multiprocessing import Pool
....
p = Pool(4)
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print(‘Waiting for all subprocesses done...‘)
p.close()
p.join()
print(‘All subprocesses done.‘)
要使用进程池需新建Pool对象,对Pool对象调用join()使等待池中所有子进程运行完毕,调用join()方法之前必须调用close(),且此后无法再新加子进程。
3.使用subprocess模块可以方便的启动并管理一个子进程,控制其输入输出。
4.进程间通信使用Queue,Pipes实现。
5.threading模块管理线程。threading.lock()创建线程锁,防止同时访问互斥资源造成的错误,示例如下:
lock = threading.Lock()
...
lock.acquire()
...
change(mutex)
...
lock.release()
6.ThreadLocal可以解决参数在一个线程中各个函数之间互相传递的问题。
7.managers模块实现分布式进程。
八、正则表达式与常用内建模块
1.re模块进行正则表达式编译和匹配,如果该表达式需要匹配很多次,那么最好进行编译从而大大节省时间。
正则表达式匹配邮箱例子:
import re
hah = re.compile(‘[0-9a-zA-Z]+[.[0-9a-zA-Z]+]*@[0-9a-zA-Z]+.[a-z]{2,3}‘)
print(hah.match(‘someone@gmail.com‘).group())
print(hah.match(‘bill.gates@microsoft.com‘).group())
i = 1
while i < 10:
r = input(‘请输入邮箱:‘)
print(hah.match(r).group())
i = i+1
2.datetime模块进行日期和时间的处理,每一个时间对应一个timestamp,我们把1970年1月1日 00:00:00 UTC+00:00时区的时刻称为epoch time,记为0(1970年以前的时间timestamp为负数),当前时间就是相对于epoch time的秒数,称为timestamp。字符串和datetime也可以相互转换,采用strptime()方法,字符串转换为datetime时需要设定一个识别格式,其中
%Y-%m-%d %H:%M:%S
分别表示年-月-日 时-分-秒。
从datetime得出月份,星期等字符串用strftime()方法,其中:
%a, %b %d %H:%M
分别表示星期, 月份 日期 时:分。
示例:
from datetime import datetime
r = ‘2015-11-23 12:01‘
dt = datetime.strptime(r, ‘%Y-%m-%d %H:%M‘)
print(dt)
week = dt.strftime(‘%a %b %d, %H:%M‘)
print(week)
2015-11-23 12:01:00
Mon Nov 23, 12:01
3.datetime与timestamp的相互转换
有时候我们为了方便表示和存储时间,常将它转化为一个timestamp,即用一个唯一的数来表示时间,也方便看出时间早晚,有时候我们也需要将timestamp转化回我们惯常的时间格式,这就需要在timestamp和datetime之间相互转换,转换示例如下,主要函数为timestamp()和fromtimestamp():
>>> from datetime import datetime
>>> dtime = datetime(2016,5,20,16,13)
>>> dtime.timestamp()
1463731980.0
>>> tstamp = dtime.timestamp()
>>> normaltime = datetime.fromtimestamp(tstamp)
>>> normaltime
datetime.datetime(2016, 5, 20, 16, 13)
>>> print(normaltime)
2016-05-20 16:13:00
>>>
4.collections是Python内建的一个集合模块,提供了许多有用的集合类。
5.Base64是一种任意二进制到文本字符串的编码方法,常用于在URL、Cookie、网页中传输少量二进制数据。
6.struct模块用来解决bytes和其他二进制数据类型的转换。
7.Python的hashlib提供了常见的哈希算法,如MD5,SHA1等等。hashlib实现简单登录:
import hashlib
db = {
‘michael‘: ‘e10adc3949ba59abbe56e057f20f883e‘,
‘bob‘: ‘878ef96e86145580c38c87f0410ad153‘,
‘alice‘: ‘99b1c2188db85afee403b1536010c2c9‘
}
def get_md5(ostr):
md5 = hashlib.md5()
md5.update(ostr.encode())
return md5.hexdigest()
def login(user, password):
r = get_md5(password)
for name in db:
if db[name] == r:
return True
return False
print(login(‘bob‘,‘abc999‘))
True
8.Python的内建模块itertools提供了非常有用的用于操作迭代对象的函数。
9.urllib提供了一系列用于操作URL的功能。如GET,POST…
10.PIL(Python Imaging Library Python图像库)是一个强大的图像处理标准库,功能强大却又简单易用。现在的名字叫做Pillow。可以如下安装Pillow:
pip3 install pillow
从下面生成数字验证码的程序可以窥其一斑:
from PIL import Image, ImageDraw, ImageFont, ImageFilter
import random
# 随机字母:
def rndChar():
return chr(random.randint(48, 57))
# 随机颜色1:
def rndColor():
return (random.randint(64, 255), random.randint(64, 255), random.randint(64, 255))
# 随机颜色2:
def rndColor2():
return (random.randint(32, 127), random.randint(32, 127), random.randint(32, 127))
# 240 x 60:
width = 60 * 4
height = 60
image = Image.new(‘RGB‘, (width, height), (255, 255, 255))
# 创建Font对象:
font = ImageFont.truetype(‘ariblk.ttf‘, 40)
# 创建Draw对象:
draw = ImageDraw.Draw(image)
# 填充每个像素:
for x in range(width):
for y in range(height):
draw.point((x, y), fill=rndColor())
# 输出文字:
for t in range(4):
draw.text((60 * t + 10, 10), rndChar(), font=font, fill=rndColor2())
# 模糊:
image = image.filter(ImageFilter.BLUR)
image.save(‘code.jpg‘, ‘jpeg‘)
效果:

九、网络编程和电子邮件
1.网络编程主要是TCP和UDP的编程
2.SMTP是发送邮件的协议,Python内置对SMTP的支持,可以发送纯文本邮件、HTML邮件以及带附件的邮件。Python对SMTP支持有smtplib和email两个模块,email负责构造邮件,smtplib负责发送邮件。Python内置一个poplib模块,实现了POP3协议,可以直接用来收邮件。由于现在绝大多数大型邮件服务商都采取了反垃圾邮件措施,所以这部分的简单实验并没有成功,还需进一步研究,等遇到具体情况再说。
3.Python内嵌了sqlite数据库,还可以自行安装连接mysql,MySQL是当前最流行的开源数据库,在行业内有着广泛的应用。
十、Web开发和异步IO
1.WSGI(Web Server Gateway Interface) 服务器网关接口。
2.Python web 开发框架:
- Flask:流行的Web框架
- Django:全能型Web框架 中文文档
- web.py:一个小巧的Web框架
- Bottle:和Flask类似的Web框架
- Tornado:Facebook的开源异步Web框架 文档
3.协程
欢迎各位前来交流群1125760266交流,分享经验~
以上是关于当我学完 Python ,我学会了些什么的主要内容,如果未能解决你的问题,请参考以下文章