Teachable Reinforcement Learning via Advice Distillation
Posted initial_h
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Teachable Reinforcement Learning via Advice Distillation相关的知识,希望对你有一定的参考价值。
发表时间:2021 (NeurIPS 2021)
文章要点:这篇文章提出了一种学习policy的监督范式,大概思路就是先结构化advice,然后先学习解释advice,再从advice中学policy。这个advice来自于外部的teacher,相当于一种human-in-the-loop decision making。另外这个advice不单单是reward的大小,可能具有更加实际的意义,比如告诉agent做什么动作。
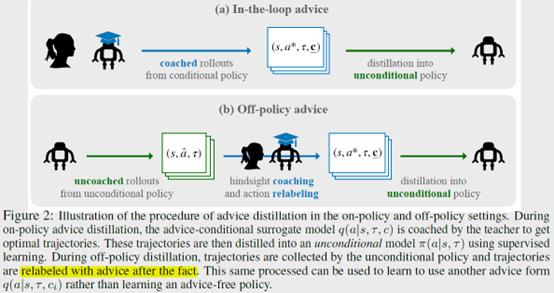
作者提出了一个Coaching Augmented Markov Decision Processes (CAMDPs)框架,在这个框架下,算法包括两个步骤,advice grounding and advice distillation。grounding phase,就是去学会理解teacher-provided advice和high-value actions之间的联系,也就是学会理解advice。Distillation phase就是根据advice去学策略。
具体的,先去学一个surrogate policy

这里c是advice,\\(\\tau\\)是具体的任务,s是状态。然后就用强化的方式,提供关于这个task的真实的reward来训。这个过程和标准的multi-task RL一样,只是多了一个advice作为输出入。有了这个之后,新任务来了就用这个surrogate policy根据新的advice来生成轨迹,然后用监督学习的方式学成一个不依赖于advice的policy

总结:感觉这个paper的点就在于如何学会理解advice,这样来了新的任务之后,可以直接根据teacher给的advice来产生policy适应新的任务。但是感觉这个理解还是主要局限在非常相似的任务上,不是很好泛化。
而且并不是真的zero-shot transfer,还是需要和环境再交互才能再用监督学一个policy,就感觉有点鸡肋了。
疑问:里面这个先学一个advice conditioned的policy,再在新任务上采样,再监督成一个不依赖advice的policy,是不是有点多此一举了啊。是不是还不如直接重新在新任务上训练啊,就先搞个meta learning的pretrained model,然后直接对新任务finetune就好了。
强化学习(Reinforcement Learning)是什么?强化学习(Reinforcement Learning)和常规的监督学习以及无监督学习有哪些不同?
强化学习(Reinforcement Learning)是什么?强化学习(Reinforcement Learning)和常规的监督学习以及无监督学习有哪些不同?
目录
以上是关于Teachable Reinforcement Learning via Advice Distillation的主要内容,如果未能解决你的问题,请参考以下文章