python爬取微博热搜
Posted b1ing丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬取微博热搜相关的知识,希望对你有一定的参考价值。
功能
利用python爬取新浪微博热搜,并设置为定时任务,每天定时自动运行。
源代码
1 import requests 2 import re 3 import bs4 4 import os 5 import datetime 6 7 url="https://s.weibo.com/top/summary" 8 headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3756.400 QQBrowser/10.5.4039.400"} 9 try: 10 r=requests.get(url,headers=headers) 11 except: 12 print("出现了不可预期的错误") 13 14 hotPattern=re.compile(\'(<tr class="">[\\s,\\S]*?</tr>)\') 15 hotList=re.findall(hotPattern,r.text) 16 if hotList==[]: 17 print("匹配模式可能出了问题") 18 else: 19 #接下来开始提取热搜数据 20 dataList=[] 21 for hotPoint in hotList: 22 data=[] 23 hotSoup=bs4.BeautifulSoup(hotPoint,\'html.parser\') 24 #获取排名 25 #print(hotSoup.tr.contents[1]) 26 rank=hotSoup.tr.contents[1].string 27 if rank==None: 28 data.append("速升") 29 else: 30 data.append(rank) 31 32 #获取热搜名称 33 #print(hotSoup.tr.contents[3]) 34 name=hotSoup.tr.contents[3].a.string 35 data.append(name) 36 37 dataList.append(data) 38 39 #创建文件夹 40 cwd=os.getcwd() 41 time=datetime.datetime.now().strftime(r\'%Y\\%m\') #以【年/月/】作为目录 42 day=datetime.datetime.now().strftime(r\'\\%d\') #以【日.txt】作为文件名 43 file=cwd+\'\\\\\'+time 44 if not(os.path.exists(file)): 45 os.makedirs(file) 46 with open(file+day+\'.txt\',\'w\') as f: 47 for data in dataList: 48 tmp="" 49 for da in data: 50 tmp+=da.ljust(10) 51 tmp+=\'\\n\' 52 f.write(tmp) 53 54 55
设置定时任务
打开控制面板——》选择系统和安全——》选择管理工具——》打开任务计划程序
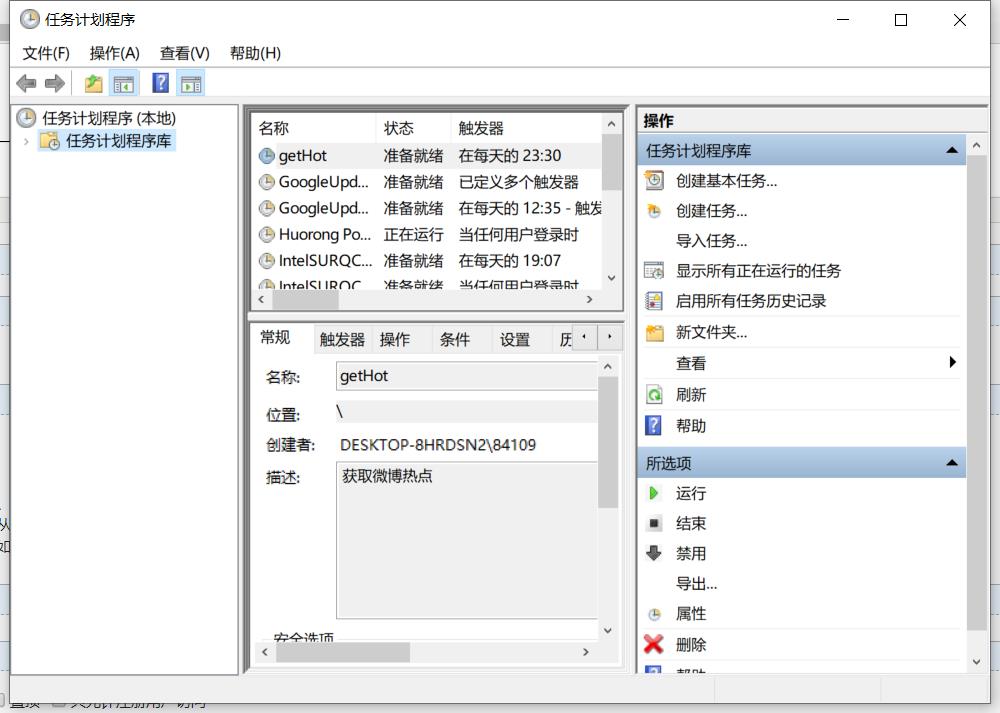
选择创建任务
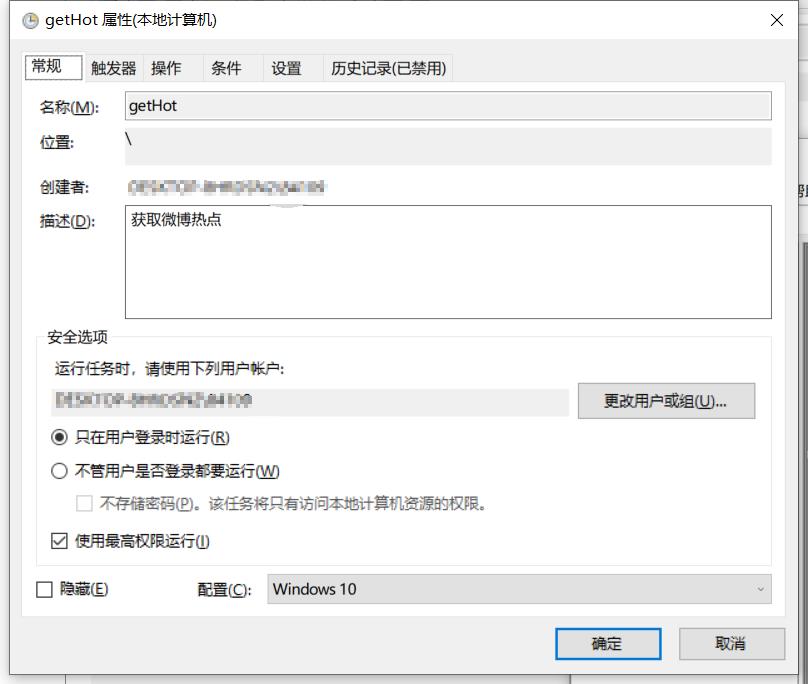
设置基本属性
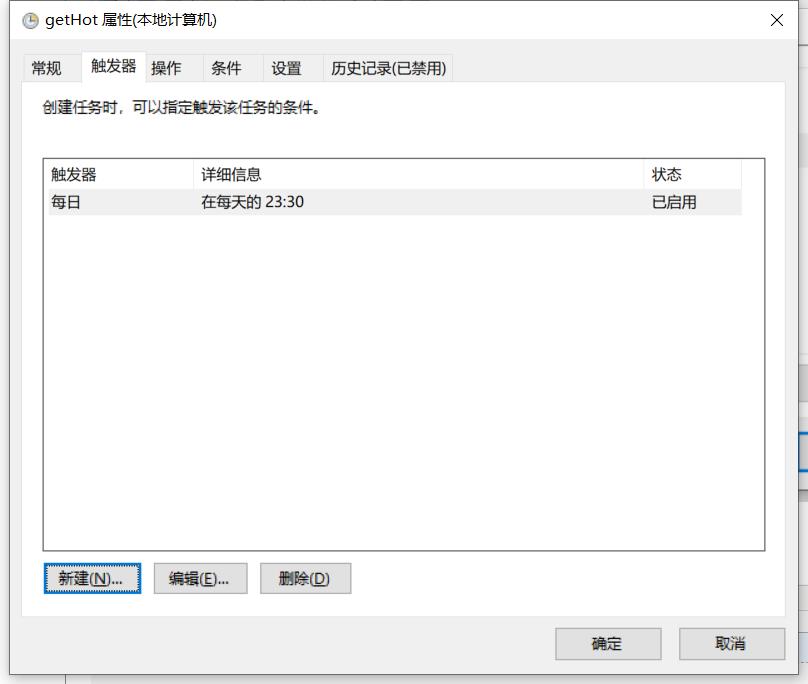
设置触发器
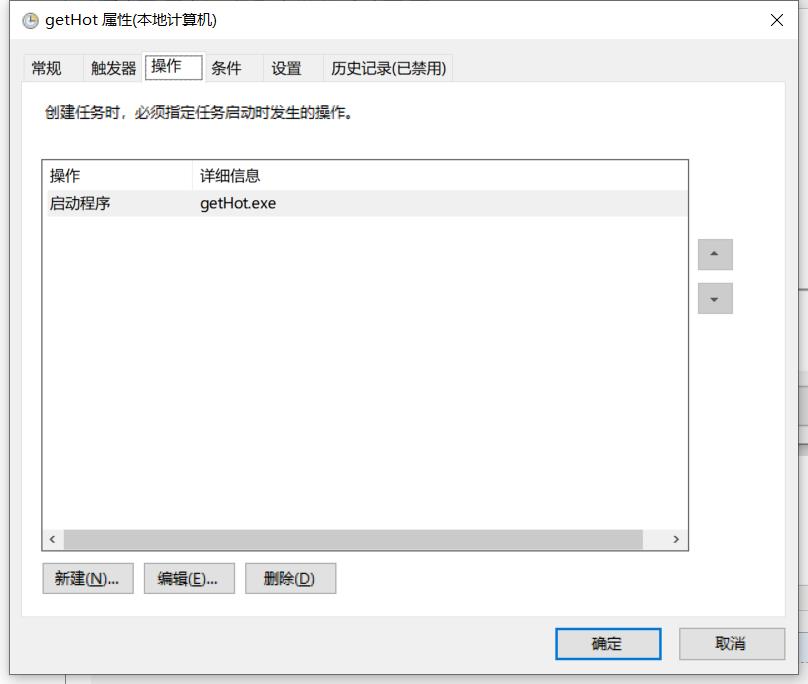
设置操作(注意要设置起始位置为文件所在目录)
设置条件
以上是关于python爬取微博热搜的主要内容,如果未能解决你的问题,请参考以下文章