腾讯音乐SQL题
Posted 王陸
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了腾讯音乐SQL题相关的知识,希望对你有一定的参考价值。
1. 计算歌曲完播率
请根据 user_listen_record、song_library计算出QQ音乐20230306歌曲完播率(播放时长>=听歌时长)输出表结构如下,其中完播率保留小数点后2位小数并按照完播率重小到大排序:
song_playback_history

已知QQ音乐部分用户听歌流水表格式和样例数据如下: user_listen_record  其中ftime为数据分区时间,uin为用户账号(唯一标识),os_type为设备端分类,song_id为歌曲id,app_ver为应用版本,play_duration为听歌时长(秒)
其中ftime为数据分区时间,uin为用户账号(唯一标识),os_type为设备端分类,song_id为歌曲id,app_ver为应用版本,play_duration为听歌时长(秒)
曲库信息表:song_library  其中song_id为歌曲id(唯一标识),song_name歌曲名称,duration为歌曲时长(秒),artist_id为歌手id,artist_name为歌手名
其中song_id为歌曲id(唯一标识),song_name歌曲名称,duration为歌曲时长(秒),artist_id为歌手id,artist_name为歌手名
示例1
输入例子:
-- ----------------------------
-- Table structure for user_listen_record
-- ----------------------------
DROP TABLE IF EXISTS `user_listen_record`;
CREATE TABLE `user_listen_record` (
`ftime` bigint(20) DEFAULT NULL,
`uin` varchar(255) DEFAULT NULL,
`os_type` varchar(255) DEFAULT NULL,
`song_id` bigint(20) DEFAULT NULL,
`app_ver` varchar(255) DEFAULT NULL,
`play_duration` bigint(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ----------------------------
-- Records of user_listen_record
-- ----------------------------
BEGIN;
INSERT INTO `user_listen_record` (`ftime`, `uin`, `os_type`, `song_id`, `app_ver`, `play_duration`) VALUES (20230306, \'a\', \'ios\', 1001, \'10.0.1\', 140);
INSERT INTO `user_listen_record` (`ftime`, `uin`, `os_type`, `song_id`, `app_ver`, `play_duration`) VALUES (20230306, \'s\', \'android\', 1001, \'10.0.1\', 170);
INSERT INTO `user_listen_record` (`ftime`, `uin`, `os_type`, `song_id`, `app_ver`, `play_duration`) VALUES (20230306, \'m\', \'ios\', 1003, \'10.0.5\', 100);
INSERT INTO `user_listen_record` (`ftime`, `uin`, `os_type`, `song_id`, `app_ver`, `play_duration`) VALUES (20230306, \'u\', \'android\', 1004, \'10.0.1\', 229);
INSERT INTO `user_listen_record` (`ftime`, `uin`, `os_type`, `song_id`, `app_ver`, `play_duration`) VALUES (20230306, \'m\', \'ios\', 1002, \'10.0.5\', 230);
INSERT INTO `user_listen_record` (`ftime`, `uin`, `os_type`, `song_id`, `app_ver`, `play_duration`) VALUES (20230306, \'a\', \'ios\', 1003, \'10.0.1\', 257);
INSERT INTO `user_listen_record` (`ftime`, `uin`, `os_type`, `song_id`, `app_ver`, `play_duration`) VALUES (20230306, \'u\', \'android\', 1001, \'10.0.1\', 290);
INSERT INTO `user_listen_record` (`ftime`, `uin`, `os_type`, `song_id`, `app_ver`, `play_duration`) VALUES (20230306, \'s\', \'android\', 1003, \'10.0.1\', 170);
INSERT INTO `user_listen_record` (`ftime`, `uin`, `os_type`, `song_id`, `app_ver`, `play_duration`) VALUES (20230306, \'a\', \'ios\', 1004, \'10.0.1\', 229);
COMMIT;
DROP TABLE IF EXISTS `song_library`;
CREATE TABLE `song_library` (
`song_id` bigint(20) DEFAULT NULL,
`song_name` varchar(255) DEFAULT NULL,
`duration` bigint(20) DEFAULT NULL,
`artist_id` bigint(20) DEFAULT NULL,
`artist_name` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ----------------------------
-- Records of song_library
-- ----------------------------
BEGIN;
INSERT INTO `song_library` (`song_id`, `song_name`, `duration`, `artist_id`, `artist_name`) VALUES (1001, \'七里香\', 297, 1, \'周杰伦\');
INSERT INTO `song_library` (`song_id`, `song_name`, `duration`, `artist_id`, `artist_name`) VALUES (1002, \'逆战\', 230, 235, \'张杰\');
INSERT INTO `song_library` (`song_id`, `song_name`, `duration`, `artist_id`, `artist_name`) VALUES (1003, \'乌梅子酱\', 257, 23, \'李荣浩\');
INSERT INTO `song_library` (`song_id`, `song_name`, `duration`, `artist_id`, `artist_name`) VALUES (1004, \'倒数\', 229, 25, \'邓紫棋\');
COMMIT;
输出例子:
ftime|song_id|song_name|play_comp_rate
20230306|1002|逆战|1.00
20230306|1004|倒数|1.00
20230306|1003|乌梅子酱|0.33
20230306|1001|七里香|0.00
答案
select
ftime,
U.song_id as song_id,
song_name,
round(
avg(if (play_duration >= duration, 1, 0)),
2
) as play_comp_rate
from
user_listen_record U
join song_library S on U.song_id = S.song_id
where ftime = \'20230306\'
group by
ftime,
U.song_id,
song_name
order by
play_comp_rate desc
2. 听歌时长前3名
请根据 user_listen_record按照每个用户对歌曲的听歌时长,排出每个用户播放前3名歌曲(相同排名取song_id更小的歌曲),最后结果按用户账号(uin)从大到小,排名从1到3排序,输出表结构如下:
user_play_rank

输出例子:
uin|song_id|rank
u|1001|1
u|1004|2
s|1001|1
s|1003|2
m|1002|1
m|1003|2
a|1003|1
a|1004|2
a|1001|3
答案代码:
SELECT
uin,
song_id,
rank
FROM
(
SELECT
uin,
U.song_id,
row_number() over ( PARTITION BY uin ORDER BY total_time ) AS rank
FROM
(
SELECT
uin,
sum(play_duration) AS total_time,
U.song_id AS song_id
FROM
user_listen_record U
JOIN song_library S ON U.song_id = S.song_id
GROUP BY
uin,
U.song_id
) t1
) t2
WHERE
rank <= 3
3. 每个月Top3的周杰伦歌曲
输入例子:
drop table if exists play_log;
create table `play_log` (
`fdate` date,
`user_id` int,
`song_id` int
);
insert into play_log(fdate, user_id, song_id)
values
(\'2022-01-08\', 10000, 0),
(\'2022-01-16\', 10000, 0),
(\'2022-01-20\', 10000, 0),
(\'2022-01-25\', 10000, 0),
(\'2022-01-02\', 10000, 1),
(\'2022-01-12\', 10000, 1),
(\'2022-01-13\', 10000, 1),
(\'2022-01-14\', 10000, 1),
(\'2022-01-10\', 10000, 2),
(\'2022-01-11\', 10000, 3),
(\'2022-01-16\', 10000, 3),
(\'2022-01-11\', 10000, 4),
(\'2022-01-27\', 10000, 4),
(\'2022-02-05\', 10000, 0),
(\'2022-02-19\', 10000, 0),
(\'2022-02-07\', 10000, 1),
(\'2022-02-27\', 10000, 2),
(\'2022-02-25\', 10000, 3),
(\'2022-02-03\', 10000, 4),
(\'2022-02-16\', 10000, 4);
drop table if exists song_info;
create table `song_info` (
`song_id` int,
`song_name` varchar(255),
`singer_name` varchar(255)
);
insert into song_info(song_id, song_name, singer_name)
values
(0, \'明明就\', \'周杰伦\'),
(1, \'说好的幸福呢\', \'周杰伦\'),
(2, \'江南\', \'林俊杰\'),
(3, \'大笨钟\', \'周杰伦\'),
(4, \'黑键\', \'林俊杰\');
drop table if exists user_info;
create table `user_info` (
`user_id` int,
`age` int
);
insert into user_info(user_id, age)
values
(10000, 18)
输出例子:
month|ranking|song_name|play_pv
1|1|明明就|4
1|2|说好的幸福呢|4
1|3|大笨钟|2
2|1|明明就|2
2|2|说好的幸福呢|1
2|3|大笨钟|1
例子说明:
1月被18-25岁用户播放次数最高的三首歌为“明明就”、“说好的幸福呢”、“大笨钟”,“明明就”和“说好的幸福呢”播放次数相同,排名先后由两者的song_id先后顺序决定。2月同理。
答案:
select
month,
ranking,
song_name,
play_pv
from
(
select
month,
row_number() over (
partition by
month
order by
play_pv desc,
song_id
) as ranking,
song_name,
play_pv
from
(
select
month (fdate) as month,
song_name,
PS.song_id as song_id,
count(*) as play_pv
from
play_log PS
join song_info S on PS.song_id = S.song_id
join user_info U on PS.user_id = U.user_id
where
year (fdate) = 2022
and age >= 18
and age <= 25
and singer_name = \'周杰伦\'
group by
month,
song_name,
PS.song_id
) t1
) t2
where
ranking < 4
4. 语种播放量前三高所有歌曲
表:songplay
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| id | int |
| playcnt | int |
|languageid | int |
+--------------+---------+
id是该表的主键列。
languageid是songplay表中ID的外键。
该表的每一行都表示歌曲的ID、播放量,语种id。
表: language
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| name | varchar |
+-------------+---------+
Id是该表的主键列。
该表的每一行表示语种ID和语种名。
示例1
输入例子:
drop table if exists songplay;
create table `songplay`(
`id` int,
`playcnt` int,
`languageid` int
);
insert into songplay
values(1,85001,1);
insert into songplay
values(2,80001,2);
insert into songplay
values(3,60001,2);
insert into songplay
values(4,90001,1);
insert into songplay
values(5,69001,1);
insert into songplay
values(6,85001,1);
insert into songplay
values(7,70001,1);
drop table if exists language;
create table `language`(
`id` int,
`name` varchar(255)
);
insert into language
values(1,\'中文\');
insert into language
values(2,\'英文\');
输出例子:
language_name|songid|playcnt
中文|4|90001
中文|1|85001
中文|6|85001
中文|7|70001
英文|2|80001
英文|3|60001
代码:
开始搞错思路了,看这个样例还以为是求播放总量前三的语种下的所有歌曲,实际上是求每个语种播放量前三的歌曲(存在并列现象)
select
language_name,
songid,
playcnt
from
(
select
songplay.id as songid,
name as language_name,
playcnt,
dense_rank() over (
PARTITION BY
languageid
ORDER BY
playcnt desc
) AS rk
from
songplay
join language on songplay.languageid = language.id
)t1
where rk <=3
5. 最长连续登录天数
你正在搭建一个用户活跃度的画像,其中一个与活跃度相关的特征是“最长连续登录天数”, 请用SQL实现“2023年1月1日-2023年1月31日用户最长的连续登录天数”
示例1
输入例子:
drop table if exists tb_dau;
create table `tb_dau` (
`fdate` date,
`user_id` int
);
insert into tb_dau(fdate, user_id)
values
(\'2023-01-01\', 10000),
(\'2023-01-02\', 10000),
(\'2023-01-04\', 10000);
输出例子:
user_id|max_consec_days
10000|2
例子说明:
id为10000的用户在1月1日及1月2日连续登录2日,1月4日登录1日,故最长连续登录天数为2日
答案
SELECT
user_id,
max(consecutive_day) AS max_consec_days
FROM
(
SELECT
user_id,
count(diff) AS consecutive_day
FROM
(
SELECT
user_id,
fdate - rn AS diff
FROM
(
SELECT
user_id,
fdate,
row_number() over (PARTITION BY user_id ORDER BY fdate) AS rn
FROM
tb_dau
) t1
) t2
GROUP BY
user_id,
diff
) t3
GROUP BY
user_id
6.SQL实现文本处理
现有试卷信息表examination_info(exam_id试卷ID, tag试卷类别, difficulty试卷难度, duration考试时长):
+----+---------+------------------+------------+----------+---------------------+
| id | exam_id | tag | difficulty | duration |
+----+---------+------------------+------------+----------+---------------------+
| 1 | 9001 | 算法 | hard | 60 |
| 2 | 9002 | 算法 | hard | 80 |
| 3 | 9003 | SQL | medium | 70 |
| 4 | 9004 | 算法,medium,80 | | 0 |
+----+---------+------------------+------------+----------+---------------------+
录题同学有一次手误将部分记录的试题类别tag、难度、时长同时录入到了tag字段,
请帮忙找出这些录错了的记录,并拆分后按正确的列类型输出。
由示例数据结果输出如下:
+---------+--------+------------+----------+
| exam_id | tag | difficulty | duration |
+---------+--------+------------+----------+
| 9004 | 算法 | medium | 80 |
+---------+--------+------------+----------+
示例1
输入例子:
drop table if exists examination_info,exam_record;
CREATE TABLE examination_info (
id int PRIMARY KEY AUTO_INCREMENT COMMENT \'自增ID\',
exam_id int UNIQUE NOT NULL COMMENT \'试卷ID\',
tag varchar(32) COMMENT \'类别标签\',
difficulty varchar(8) COMMENT \'难度\',
duration int NOT NULL COMMENT \'时长\',
release_time datetime COMMENT \'发布时间\'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
INSERT INTO examination_info(exam_id,tag,difficulty,duration,release_time) VALUES
(9001, \'算法\', \'hard\', 60, \'2020-01-01 10:00:00\'),
(9002, \'算法\', \'hard\', 80, \'2020-01-01 10:00:00\'),
(9003, \'SQL\', \'medium\', 70, \'2020-01-01 10:00:00\'),
(9004, \'算法,medium,80\',\'\', 0, \'2020-01-01 10:00:00\');
输出例子:
exam_id|tag|difficulty|duration
9004|算法|medium|80
答案代码
牛客原题:https://www.nowcoder.com/practice/a5475ed3b5ab4de58e2ea426b4b2db76
SELECT
exam_id,
-- 查找字段tag中\',\'这个字符的每一个位置并排序,截取第一个\',\'向左所有的字符。
substring_index (tag, \',\', 1) as tag,
-- difficult在中间位置,需要截取2次
substring_index (substring_index (tag, \',\', 2), \',\', -1) as difficult,
-- 查找字段tag中\',\'这个字符的每一个位置并排序,截取最后1个\',\'向右所有的字符。并且转换数据格式。
substring_index (tag, \',\', -1) as duration
from
examination_info
where
-- 定位到出现串列的数据
tag like \'%,%\'
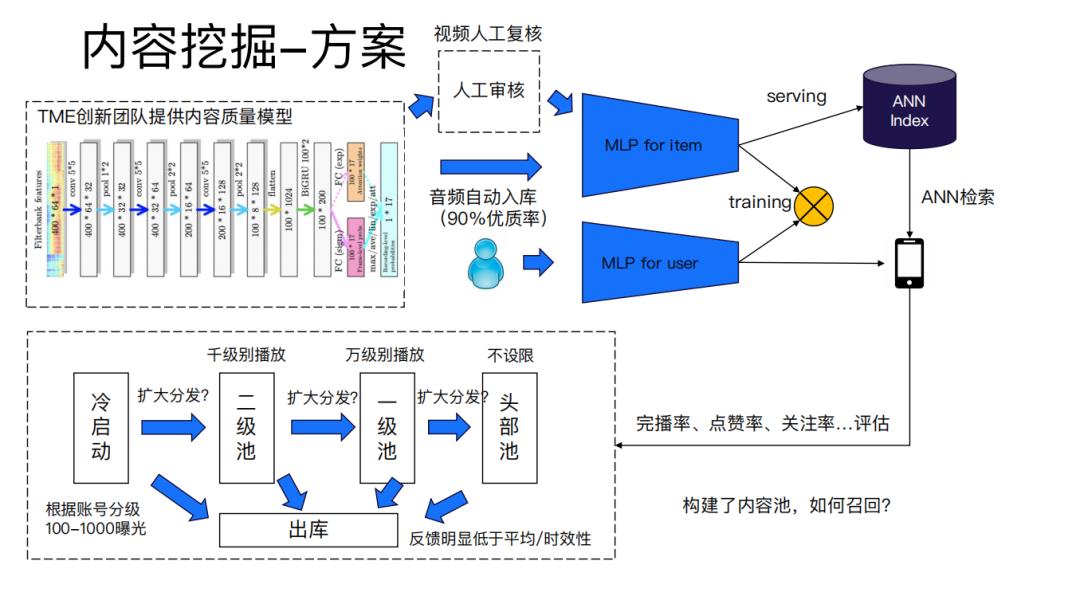
PPT下载 | 腾讯音乐 :全民K歌推荐系统详解
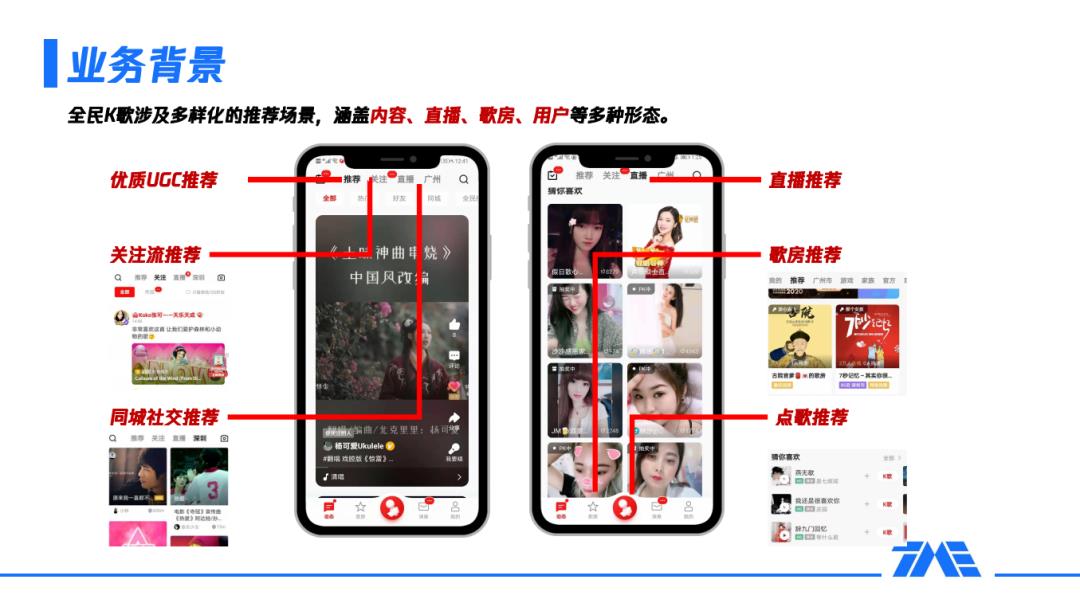
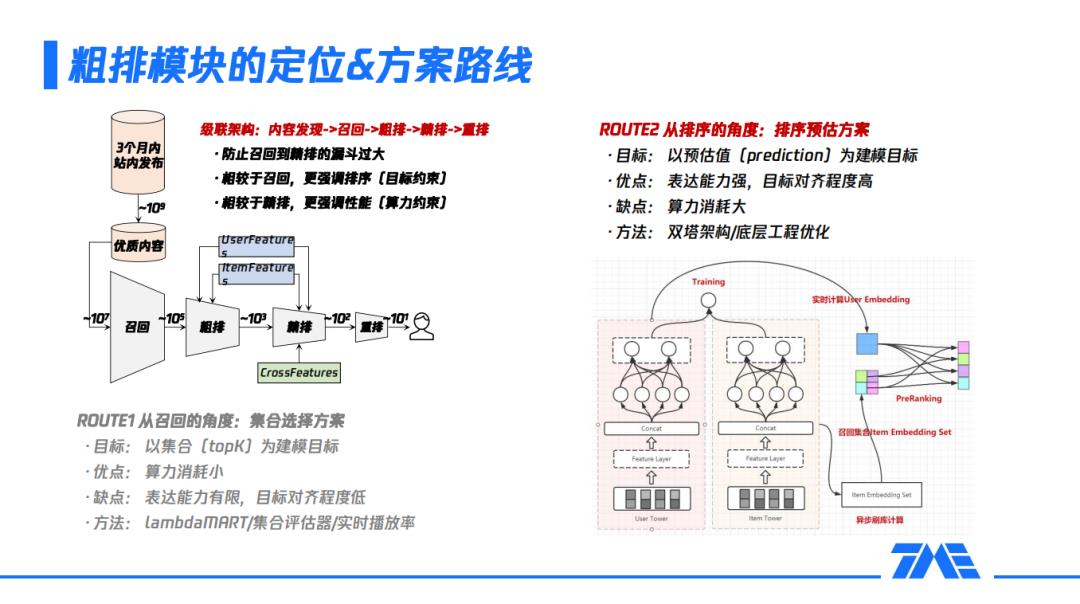
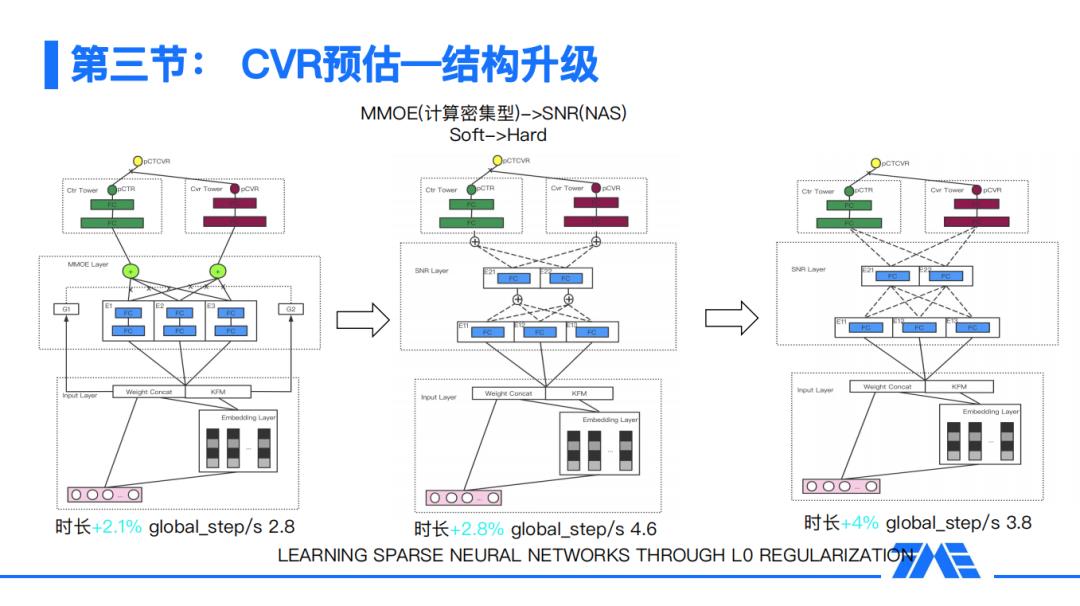
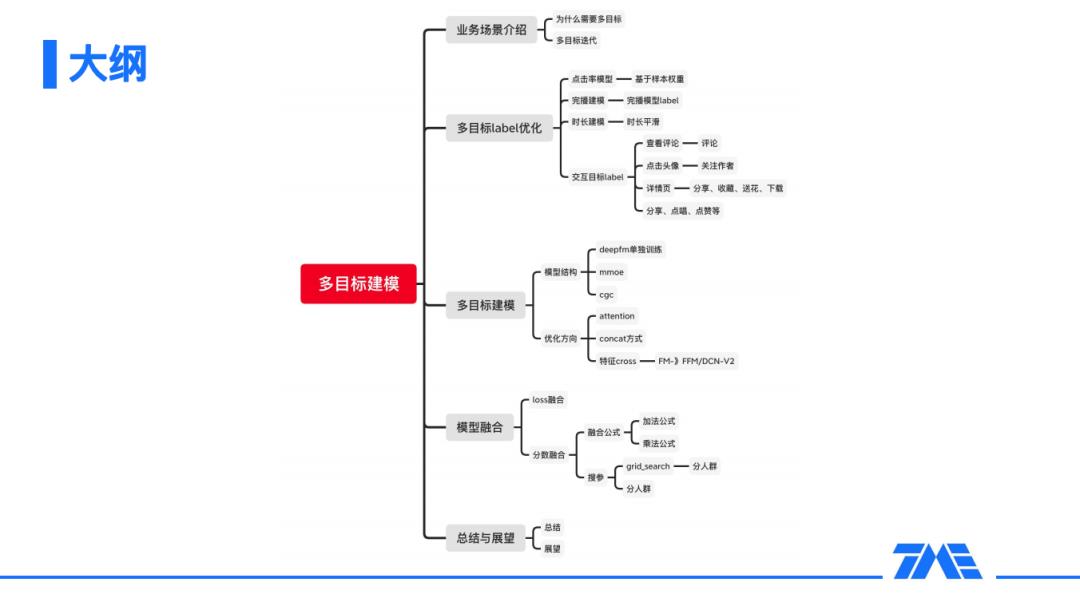
1月9日,《腾讯音乐:全民K歌推荐系统详解》在DataFunTalk直播间成功举办,吸引了数千位小伙伴收看,今天就为大家带来本次分享的PPT,目录如下:

下载方式(7天内有效):

精华速浏览:




以上是关于腾讯音乐SQL题的主要内容,如果未能解决你的问题,请参考以下文章