过度学习对学习迁移有何影响?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了过度学习对学习迁移有何影响?相关的知识,希望对你有一定的参考价值。
深度学习在一些传统方法难以处理的领域有了很大的进展。这种成功是由于改变了传统机器学习的几个出发点,使其在应用于非结构化数据时性能很好。如今深度学习模型可以玩游戏,检测癌症,和人类交谈,自动驾驶。
深度学习变得强大的同时也需要很大的代价。进行深度学习需要大量的数据、昂贵的硬件、甚至更昂贵的精英工程人才。
在Cloudera Fast Forward实验室,我们对能解决这些问题的创新特别兴奋。我们最新的研究报告深入探讨了多任务学习,一种允许机器学习模型同时从多个任务中学习的方法。其中的一个好处就是可以减少训练数据需求。
在本文中,我们将讲述迁移学习,这是一种可以将知识从一项任务迁移到另一项任务的相关技术。迁移学习允许你从相关问题中转移知识而不是针对问题开发一个完全定制的解决方案,这能帮助你更轻松地解决特定问题。通过迁移这些知识,你可以减少很多开支,接下来看一下该方法如何有效地解决上述问题。
为什么深度学习不同于其他方法
迁移学习不是一种新技术,也不是专门针对深度学习的,但考虑到最近深度学习的进展,它是一种令人兴奋的新技术。首先,有必要说明深度学习与传统机器学习的不同之处。
深度学习是在较低的抽象层次上进行的
机器学习是机器自动学习函数权重的一种方式。
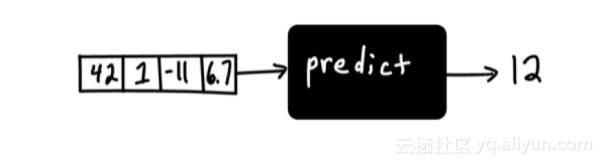
确定函数如何从提供的输入产生输出是比较困难的。如果对函数没有任何限制,那么可能性是无穷无尽的。为了简化这个任务,我们通常在功能上强加某种类型的结构——基于我们正在解决的问题的类型或者简单的尝试和误差。这种结构定义了一种机器学习模型。
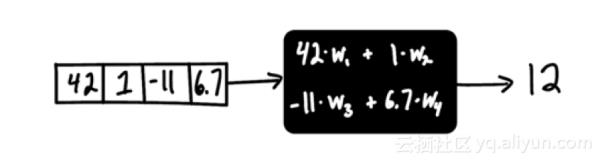
理论上,结构是无限的,但在实践中,大多数机器学习用例都可以通过应用少数的结构来解决:线性模型、树的集合和支持向量机。数据科学家的工作就是从这一小部分可能的结构中选择正确的结构使用。
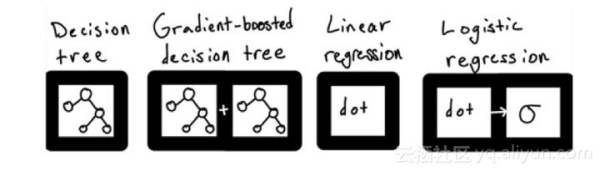
这些模型可以作为黑盒对象从各种成熟的机器学习库中获得,并且只需要几行代码就可以训练出来。例如,可以使用Python的scikit-learn来训练一个随机森林模型,如下所示:
clf = RandomForestClassifier()
clf.fit(past_data, labels)
predictions = clf.predict(future_data)
或R中的线性回归模型:
linearModel <- lm(y ~ X, data=pastData)
predictions <- predict(linearModel, futureData)
虽然深度学习是在较低的层次上进行的,但并不是在有限的模型结构中进行选择的,而是允许实践者加上自己设计的模型结构。构建块是可以认为是基本数据转换的模块。这意味着在应用深度学习时,我们需要打开黑盒子,而不是通过算法固定地实现。
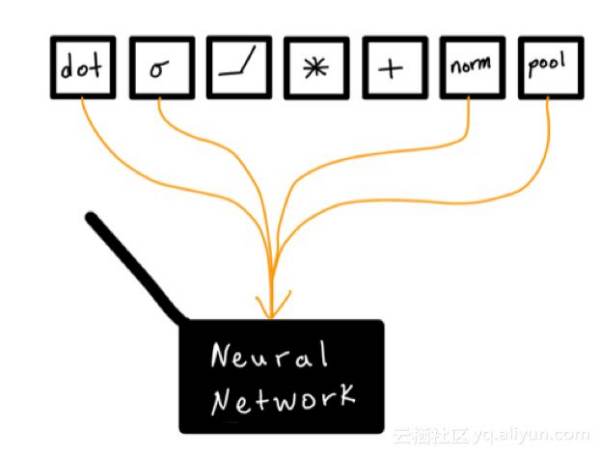
这样以来就允许开发者构建更强大的模型,从另一个角度来看这也为模型构建添加了一个全新的维度。尽管大量的深度学习研究报告、实用指南被发表,但要有效地组织这些转变可能是一个困难的过程。
考虑一个极其简单的卷积神经网络图像分类器,它在流行的深度学习库PyTorch中定义:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5) self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
因为我们使用的是低级的构建块,所以我们可以更改模型的单个组件(例如F.relu,F.sigmoid)。这为我们提供了可能会产生不同结果的全新模型体系结构,而这种可能性是无限的。
深度学习尚未被充分理解
即使给定一个固定的神经网络架构,训练也是非常困难的。首先,深度学习损失函数不是一般的凸函数,这意味着训练不一定会产生最好的解决方案。其次,深度学习仍然是非常新的,它的许多组成部分还没有被很好地理解。例如,批处理归一化最近受到了关注,因为一些模型中它似乎对良好结果至关重要,但专家们无法就原因达成一致。研究员阿里·拉希米在最近的一次机器学习会议上把深度学习比作炼金术引起了一些争议。
自动特征工程
深度学习中增加的复杂性使一种称为表示学习的技术得以实现,这就是为什么神经网络经常被称为“自动特征工程”。总之,我们以这样一种方式构建模型而不需要从数据集中人工设计有用的特征,这样它们就可以学习任何必要的、对手头任务有用的特征。将特征工程放到模型上是非常强大的,但是需要大量数据和大量计算能力的模型成本。
你能做什么
与其他机器学习方法相比,深度学习显得很复杂,以至于它似乎难以融入你的业务。对于资源有限的组织来说,这种感觉更加强烈。
对于真正需要投入大量资源进行开发的组织,可能确实需要雇佣专家并购买专门的硬件。但在很多情况下,这是不必要的。有很多方法可以在不进行巨额投资的情况下有效地应用它,这就是迁移学习的由来。
转移学习是使知识从一种机器学习模式迁移到另一种机器学习模式的技术。这些模型可能是多年来对模型结构的研究、对庞大数据集的训练以及多年的计算时间进行优化的结果。通过迁移学习,你可以不用付出任何代价就能从这项工作中获得好处。
什么是转移学习?
大多数机器学习任务从零知识开始,这意味着模型的结构和参数开始是随机猜测的。

例如:检测猫模型是通过猜测开始训练的,它通过聚集它所见过的许多不同的猫的共同模式,逐渐了解猫是什么。
在这种情况下,模型学到的所有东西都来自所给出的数据。但这是解决问题的唯一方法吗?在某些情况下,好像是。
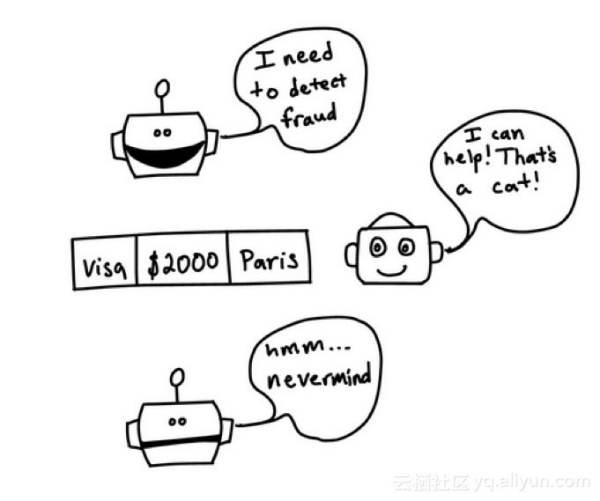
检测猫的模型在不相关的应用程序中可能是无用的,比如诈骗检测。它只知道如何理解猫的图片,而不是信用卡交易。
但在其他情况下,两个系统之间好像能够在任务之间共享信息。
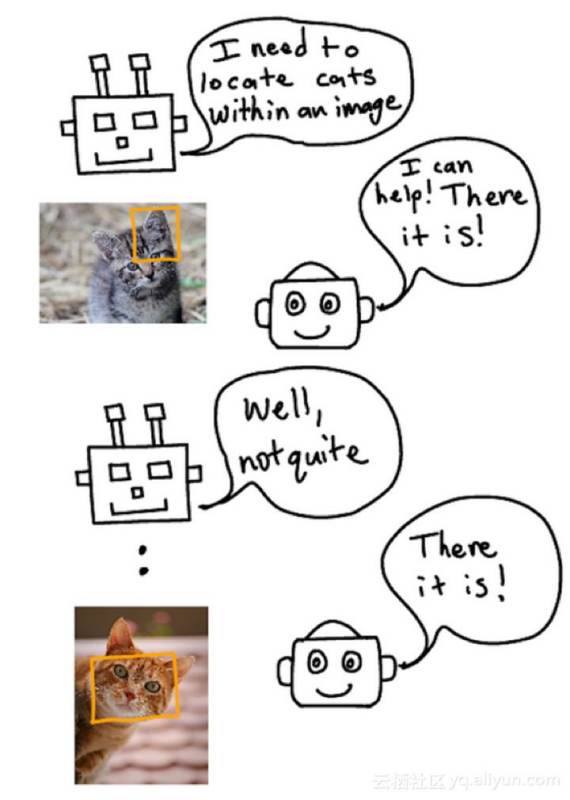
猫检测器在相关任务中很有用,比如猫的面部定位。检测器应该已经知道如何检测猫的胡须、鼻子和眼睛——所有这些东西在定位猫的脸时都很有用。
这就是转移学习的本质:采用一个已经学会如何很好地完成一项任务的模型,并将部分知识迁移到相关任务。
当我们检查自己的学习经验时,也证明着迁移学习的正确性;我们定期会迁移过去学到的技能,以便更快地学习新的技能。例如,一个已经学会扔棒球的人不需要完全重新学习扔球的技巧来学习如何扔足球。这些事情是内在相关的,做好其中一件事的能力自然会转化为做好另一件事的能力。
在机器学习领域,没有比过去五年的计算机视觉领域更好的例子了。一开始训练模型是很少见的。相反,我们从一个预先训练好的模型开始,这个模型已经知道如何分类简单的物体,比如猫、狗和雨伞。学习对图像进行分类的模型首先要学习检测一般图像特征,如边缘、形状、文本和面孔。
预训练模型具有这些基本技能。通过在新数据集上添加层或重新训练,可以稍微修改预先训练的分类模型,将这些昂贵的基本技能迁移到新的专门化中,这就是迁移学习。
迁移学习需要更少的训练数据
当你在一个新的与猫相关的任务中再次用你的猫检测模型时,你的模型已经有了“认识一百万只猫的智慧”,这意味着你不需要使用几乎同样多的图片来训练新的任务。
通过迁移学习的模型泛化能力更好
迁移学习提高了泛化能力,或者提高了模型在未经训练的数据上表现良好的能力。这是因为预先训练的模型是有目的地训练任务,这些任务迫使模型学习在相关上下文中有用的通用特性。当模型迁移到一个新的任务时,很难对新的训练数据进行过度拟合,因为模型只能从一个非常一般的知识库中增量地学习。建立一个泛化能力好的模型是机器学习中最困难也是最重要的部分之一。
迁移学习训练过程并不那么脆弱
从一个预先训练好的模型开始有助于克服训练一个复杂模型的、令人沮丧的、脆弱的和混乱的过程。迁移学习将可训练参数的数量减少了100%,使训练更稳定,更容易调试。
转移学习使深度学习更容易
最后,迁移学习使深度学习更容易进行,因为不需要自己成为专家来获得专家级别的结果。比如流行的图像分类模型Resnet-50。

这个特定的架构是如何选择的?这是多年来各种深度学习专家的研究和实验的结果。在这个复杂的结构中有2500万个权重,如果没有对模型的每个组件的广泛了解,从头优化这些权重几乎是不可能的。幸运的是,通过迁移学习,可以重用复杂的结构和优化的权重,大大降低了深入学习的门槛。
结论
迁移学习是一种知识(权重)共享技术,它减少了构建深度学习模型所需的训练数据、计算能力和工程人才的数量。而且,由于深度学习能够比传统机器学习提供显著的改进,因此迁移学习是一个必不可少的工具。
参考技术A 过度学习会促使正迁移。中学生在数学课里学到的知识,在物理、化学等课程上也会有用。譬如:学会分数计算、函数、向量、矩阵和行列式,就会在许多课程上应用。从一种学科中学到的知识、技能,促进了另一学科的学习,这叫正迁移。 参考技术B过度学习的后果之一就是损害青少年的身体健康。有的资料认为“人的潜能是无限的。”,其实并不正确,人脑作为人体的一个生理器官,也有其生理负荷的极限,超过这个极限,短时间可以恢复,时间一长,就会形成疲劳性损伤,如神经衰弱,头晕,呕吐,...
2017-09-18 回答者: ____e小调 8个回答 103
为什么过度学习而适得其反?
答:虽然社会各界对暑期补习班的批评越来越多,但仍有许多家长从心理上不愿意放弃针对学生的各种暑期补习班、辅导班。针对这种现象,有关专家提醒,家长要及时扭转这种不当心理。因为过度学习容易适得其反,要把假期真正还给学生。 家住兰州的一位学...
2019-04-12 回答者: 易书科技 1个回答 1
简述什么是过度学习,它有什么作用
答:超过刚能背诵的程度之后的重复学习,回浪费时间
2014-12-22 回答者: 青封鱼羽 2个回答 1
高中作文:过度学习对我们影响的
答:要明白和界定啥事过度学习和你自己的理解。到底是好还是不好还是需要辩证地一分为二地看。这就决定你写作的路径和选取论据的方向。具体的作文其实对你参考价值不大。我是一个高中政治教员,个人觉得把哲学的思维引入作文和不露痕迹地把辩证的思...
2016-01-09 回答者: wzkhjw 1个回答 1
过度学习的基本规律
答:过度学习效应一般发生在识记学习和辨别学习中。在识记学习中,W·E·克留格做了一项著名的实验,在完全学会12个单间节后再进行50%至100%过度学习,1天、2天、4天、7天、14天及28天后所进行再学习中测不定期的保持量,显示出过度学习使保持量增加,...
2016-05-30 回答者: 奈落乓 1个回答
过度学习的现状和阐释
答:20世纪60年代后,关于辨别学习的研究,大多是进行人的辨别学习研究。除了上面的辨别反应说,还出现了位置习性说、消去说、负反应回避说、诱因说、二要素说、观察反应、注意说等等。虽然上述各种学说还在争议,但无论如何,“过度学习”的效果也有...
2016-05-30 回答者: 神i射龙171 1个回答 1
过度学习的好处和坏处英语作文
答:Advantages and disadvantages of having school uniform Some people think that students should wear school uniform.Because it can not only save students'money but also reduce the psychological comparisons which can make a differe...
2014-12-23 回答者: 狮子座0715 1个回答
急需一个“过度学习而适得其反”的故事
问:辨论赛急用
答:虽然现在各方面对暑期补习班的批评越来越多,但仍有很多家长从心理上不愿意放弃针对孩子的各种暑期补习班、辅导班。针对这种现象,有关专家提醒,家长要及时扭转这种不当心理。因为过度学习容易适得其反,要把假期真正还给孩子。 家住兰州的一位...
向下转换对性能有何影响?
【中文标题】向下转换对性能有何影响?【英文标题】:What is the performance hit with downcasting? 【发布时间】:2008-11-20 15:51:17 【问题描述】:只是想通过阅读this enlightening article by Juval Lowy 来了解泛型
释义.. 当您定义一个 Generic 类定义时,它会被编译成 IL。
对于值类型,只要您请求特定的值类型,它就会将 T 替换为您的特定值类型,以获得该特定配置的 IL,例如MyList<int> 好处:没有装箱和拆箱处罚。
很好.. 对于引用类型,编译器将定义中的所有 T 实例替换为 Object 并创建用于所有引用类型的 IL。然而,实例是根据实际请求的 ref 类型分配的,例如MyList<String>
现在我们可以编写带有Object 参数的预泛型方法。泛型声称性能提高了 100%,因为“它避免了在你想使用它时将对象类型向下转换为特定类型时所招致的性能损失”
// assume GetItem returns an Object
string sMyPreciousString = (string) obList.GetItem();
当您从 Object 向下转换为特定引用类型时,这种性能会受到什么影响?此外,似乎向上转换为 Object(即使泛型也会这样做)不会影响性能。为什么?
【问题讨论】:
【参考方案1】:向上转换到对象不需要执行时间检查 - 它始终有效,并且基本上只是一个无操作。
向下转换需要执行时间检查,以确保您没有将流转换为字符串。这是一个很小的惩罚,而且不太可能成为瓶颈 - 但避免它只是泛型的一个额外好处。
【讨论】:
当你知道它时简单... 【参考方案2】:性能损失来自对运行时类型检查的需要。如果 B 是 A 的子类,那么当您将 B 转换为 A 时,您在编译时就知道它是安全的,因为所有 B 都是 As。因此,您无需生成任何运行时代码来检查类型。
但是,当您将 A 转换为 B 时,您在编译时并不知道 A 是否实际上是 B。它可能只是一个 A,也可能是 C 类型,是 A 的不同子类型。因此,您需要生成运行时代码,以确保对象实际上是 B,如果不是则抛出异常。
泛型没有这个问题,因为编译器在编译的时候就知道,只有Bs被放入了数据结构中,所以当你拉出一些东西的时候,编译器就知道它会是B,所以没有需要在运行时进行类型检查。
【讨论】:
【参考方案3】:阅读生成的 IL(article 提到了它)...啊哈 - isinst。
如果你不沮丧,你就不必打电话给isinst。
【讨论】:
以上是关于过度学习对学习迁移有何影响?的主要内容,如果未能解决你的问题,请参考以下文章