Python实现YY评级分数的爬取,并保存数据(附代码)
Posted python0921
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python实现YY评级分数的爬取,并保存数据(附代码)相关的知识,希望对你有一定的参考价值。

前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
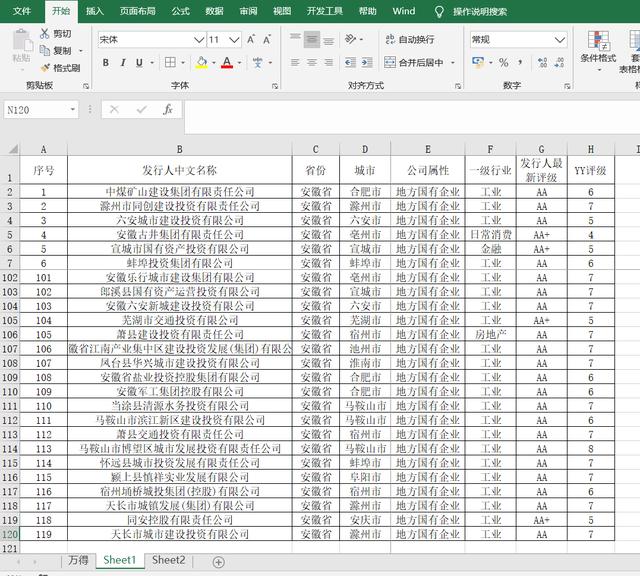
当需要进行大规模查询时(比如目前遇到的情形:查询某个省所有发债企业的YY评级分数),人工查询显然太过费时,那就写个爬虫吧。
由于该爬虫实在过于简单,就只简单概述下。
一、请求端
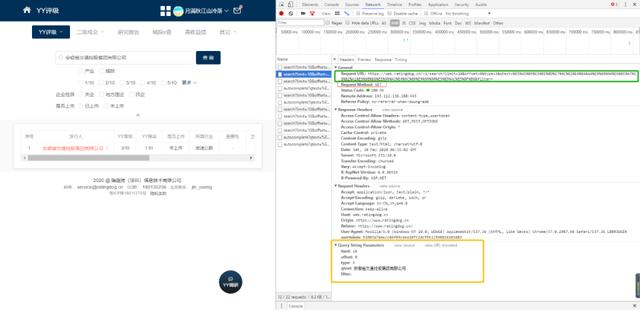
通过观察YY评级的网页信息,如下图(F12或右击进入检查,点击network—>XHR—>headers)。
红色框表明是个get请求(其实这种网页基本都是Ajax get,需要总结实际url的规律的)。
绿色框即为实际URL,通过分析该URL,其由两部分组成。前半部分为“
https://web.ratingdog.cn/v1/search?”,后半部分为黄色框内内容用“&”符号连接后的结果。黄色框内的内容,只有企业名称为变量,且为已知变量,那URL即可据此确定了。
另外需注意,YY评级需要登录才可查询数据,在构建头部信息进行访问时,一定要提前登录,并在头部信息中放入登录信息和登录状态。
二、响应端
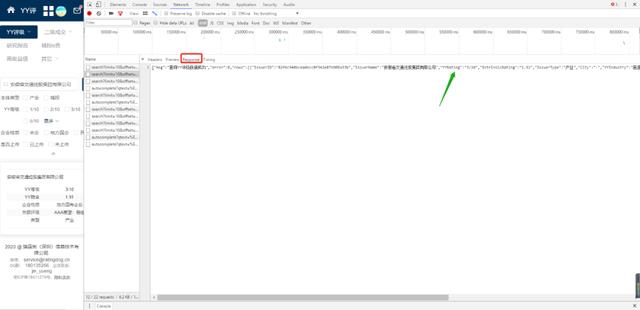
通过观察网页的响应信息(F12或右击进入检查,点击network—>XHR—>response),如下图。响应信息及其简单,我们所需要的YY评级分数安详地躺在那里,简单到一个正则表达式就可以提取出该数据。正则如下:
"msg".*?"IssuerName":"(.*?)","YYRating":"(.*?)/10","IntrinsicRating".*?"

三、代码
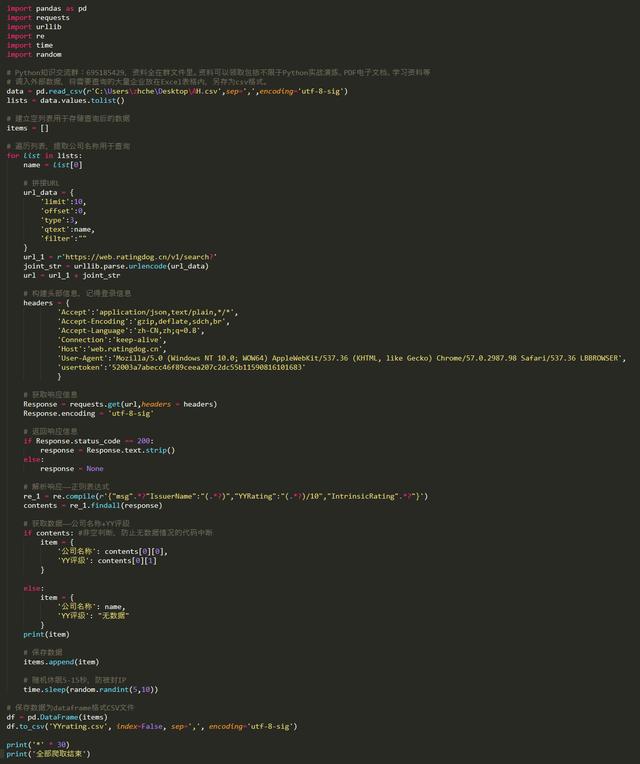
所需数据较少,代码相对简单,就不建立函数了,直接一路到底吧。如下:
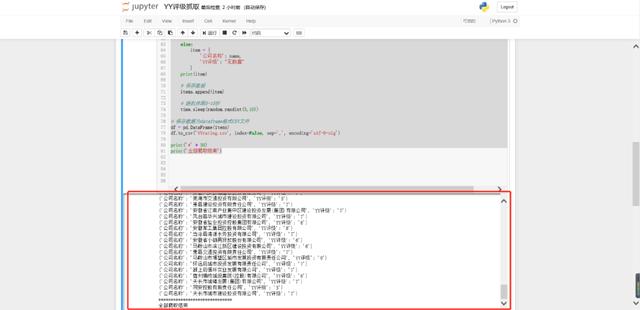
运行代码后,得到结果如下。安徽省的100多条数据,就到了本地了
以上是关于Python实现YY评级分数的爬取,并保存数据(附代码)的主要内容,如果未能解决你的问题,请参考以下文章