节)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了节)相关的知识,希望对你有一定的参考价值。
Book-Linux/UNIX 系统编程手册-上册(部分章节)
Linux的广受欢通只是原因之一,而有时出于性能方面的考虑,或是需要访问标准UNIX编程接口所不支持功能时,使用非标准扩展(正因如此,所有UNIX实现都提供有非标准扩展)就显得至为重要综上所述,在构思本书时,作者不但力图使其对在各种 UNIX 实现中编程的程序员有帮助,还全面介绍了Linux专有的编程特性,如下所示。
epoll,获取文件I/O事件通知的一种机制。
inotify,监控文件和目录变化的一种机制。
capabilities,为进程赋予超级用户的部分权限的一种机制。
扩展属性。
i-node 标记。
clone()系统调用。
/proc 文件系统。
在文件I/O、信号、定时器、线程、共享库、进程间通信以及套接字方面,Linux所
有的实现细节。
~
本书各章可分为以下几个部分。
1. 背景知识及概念:UNIX、C语言以及Linux的历史回顾,以及对UNIX标准的概述(第1章);以程序员为对象,对Linux和UNIX的概念进行介绍(第2章);Linux和UNIX系统编程的基本概念(第3章)。
2. 系统编程接口的基本特性:文件VO(第4章、第5章),进程(第6章),内存分配(第7章),用户和组(第8章),进程凭证(process credential)(第9章),时间(第10章),系统限制和选项(第11章),以及获取系统和进程信息(第12章)。
3. 看统编程接口的高级特性:文件VO缓冲(第13章),文件系统(第14章),文件属性(第15章),扩展属性(第16章),访间控制列表(第17章),目录和链接(第18章),监控文件事件(第19章),信号(signals)(第20~22章),以及定时器(第23章)。
4. 进程、程序及线程:进程的创建、终止,监控子进程,执行程序(第24~28章),以及POSIX线程(第29~33章)。
5. 进程及程序的高级主题:进程组、会话以及任务控制(第34章),进程优先级和进程调度(第35章),进程资源(第36章),守护进程(第37章),编写安全的特权程序(第38章),能力(capability)(第39章),登录记账(第40章),以及共享库(第41章和第42章)。
6. 进程间通信(IPC):IPC概览(第43章),管道和FIFO(第44章),系统V IPC消息队列、信号量(semaphore)及共享内存(第45~48章),内存映射(第49章),虚拟内存操作(第50章),POSIX消息队列、信号量及共享内存(第51~54章),以及文件锁定(第55章)。
7. 套接字和网络编程:使用套接字的IPC和网络编程(第56~61章)。
8. 8.高级I/O主题:终端(第62章),其他I/O模型(第63章),以及伪终端(第64章)。
~
POSIX (Portable Operating System Interface)可移植操作系统接口
~
内核 狭义,指管理和分配计算机资源(即CPU、RAM和设备)的核心层软件
内核所能执行的主要任务:
-进程调度
-内存管理
-文件系统
-创建和终止进程
-对设备访问
-联网
-提供系统调用应用编程接口
~
内核态和用户态
~
shell 一种具有特殊用途的程序,主要用于读取用户输入的命令,并执行相应的程序以响应命令。有时,称之为命令解释器。
~
init进程 /sbin/init
系统引导时,内核会创建一个名为init的特殊进程,即“所有进程之父”,该进程的相应程序文件为/sbin/init。系统的所有进程不是由 init(使用fork())“亲自”创建,就是由其后代进程创建。mi进程的进程号总为1,且总是以超级用户权限运行。谁(哪怕是超级用户)都不能“杀死”init 进程,只有关闭系统才能终止该进程。init的主要任务是创建并监控系统运行所需的一系列进程。(手册页 init(8)中包含了init进程的详细信息。)
~
守护进程
守护进程指的是具有特殊用途的进程,系统创建和处理此类进程的方式与其他进程相同,
但以下特征是其所独有的:
“长生不老”。守护进程通常在系统引导时启动,直至系统关闭前,会一直“健在”。
,守护进程在后台运行,且无控制终端供其读取或写入数据。
守护进程中的例子有syslogd(在系统日志中记录消息)和httpd(利用HTTP分发Web页面)。
~
Linux 也提供了丰富的进程间通信(IPC)机制,如下所示。
信号(signal),用来表示事件的发生。
管道(亦即shell 用户所熟悉的“|”操作符)和FIFO,用于在进程间传递数据。
套接字,供同一台主机或是联网的不同主机上所运行的进程之间传递数据。
文件锁定,为防止其他进程读取或更新文件内容,允许某进程对文件的部分区域加以锁定。
消息队列,用于在进程间交换消息(数据包)。
信号量(semaphore),用来同步进程动作。
共享内存,允许两个及两个以上进程共享一块内存。当某进程改变了共享内存的内容时,其他所有进程会立即了解到这一变化。
~
时间
~
/proc文件系统
类似于其他的儿种UNIX实现,Linux 也提供了/proc文件系统,由一组目录和文件组成,
装配(mount)于/proc目录下。
proc 文件系统是一种虚拟文件系统,以文件系统目录和文件形式,提供一个指向内核数据结构的接口。这为查看和改变各种系统属性开启了方便之门。此外,还能通过一组以/proc/PID形式命名的目录(PID即进程ID)查看系统中运行各进程的相关信息。
通常,/proc 目录下的文件内容都采取人类可读的文本形式,shell 脚本也能对其进行解析。程序可以打开、读取和写入proc 目录下的既定文件。大多数情况下,只有特权级进程才能修改/proc目录下的文件内容。
~
P37
标准C语言函数库:GNU C语言函数库(glibc)
http://www.gnu.org/software/libc
确定版本方法:
1. $/lib/libc.so.6
2. $ldd myprog | grep libc
_GLIBC_ _GLIBC_MINOR_
gnu_get_libc_version()-->"2.12"
confstr()--> _CS_GNU_LIBC_VERSION-->"glibc 2.12"
~
文件空洞
~
ioctl()
~/etc/passwd
~
/proc
uname()
~~~~~~~~~~~~~~~~
20章 信号:基本概念
信号是发生某种事件的通知机制,可以由内核、另一进程或进程自身发送给进程。存在一系列的标准信号类型,每种都有唯一的编号和目的。
信号传递通常是异步行为,这意味着信号中断进程执行的位置是不可预测的。有时(比如,硬件产生的信号),信号也可同步传递,这意味着在程序执行的某一点可以预期并重现信号的传递。
默认情况下,要么忽略信号,要么终止进程(生成或者不生成核心转储文件),要么停止一个正在运行的进程,要么重启一个已停止的进程。特定的默认行为取决于信号类型。此外,程序可以使用signal()或者sigaction()来显式忽略一个信号,或者建立一个由程序员自定义的信号处理器程序,以供信号到达时调用。出于可移植性考虑,最好使用sigaction()来建立信号处理器函数。
一个(具有适当权限的)进程可以使用kill()向另一进程发送信号。发送空信号(0)是判定特定进程ID是否在用的方式之一。
每个进程都具有一个信号掩码,代表当前传递遭到阻塞的一组信号。使用sigprocmask()可从信号掩码中添加或者移除信号。
如果接收的信号当前遭到阻塞,那么该信号将保持等待状态,直至解除对其阻塞。系统不会对标准信号进行排队处理,也就是说,将信号标记为等待状态(以及后续的传递)只会发生一次。进程能够使用sigpending()系统调用来获取等待信号集(用以描述多个不同信号的数据结构)。
与signal()相比,sigaction()系统调用在设置信号处置方面提供了更多控制,且更具灵活性。首先,可以指定一组调用处理器函数时将阻塞的额外信号。此外,可以使用各种标志来控制调用信号处理器时所发生的行为。例如,启用某些标志即可选择旧有的不可靠信号语义(不阻塞引发处理器调用的信号,在调用信号处理器之前就将信号处置重置为默认值)。
借助于pause(),进程可暂停执行,直至信号到达为止。
~
可重入 reentrant
SUSv3对可重入函数的定义是:函数由两条或多条线程调用时,即便是交叉执行,其效果也与各线程以未定义顺序依次调用时一致。
更新全局变量或静态数据结构的函数可能是不可重入的。(只用到本地变量的函数肯定是可重入的。)
~
异步信号安全 async-signal-safe
异步信号安全的函数是指当从信号处理器函数调用时,可以保证其实现是安全的。如果某一函数是可重入的,又或者信号处理器函数无法将其中断时,就称该函数是异步信号安全的。
~
sig_atomic_t
C语言标准以及SUSv3定义了一种整型数据类型sig_atomic _t,意在保证读写操作的原子性。所有在主程序与信号处理器函数之间共享的全局变量都应声明如下:
volatile sig atomic t flag;
注意,C语言的递增(++)和递减(-)操作符并不在sig_atomic_t所提供的保障范围之内。这些操作在某些硬件架构上可能不是原子操作(更多细节请参考30.1节)。在使用sig_atomic_t变量时唯一所能做的就是在信号处理器中进行设置,在主程序中进行检查(反之亦可)。
C99和 SUSv3规定,实现应当(在<stdint.h>中)定义两个常量SIG_ATOMIC_MIN和SIGATOMICMAX,用于规定可赋给 sig atomic_t类型的值范围。标准要求,如果将sigatomic_t表示为有符号值,其范围至少应该在-127~127之间,如果作为无符号值,则应该在0~255之间。在Linux中,这两个常量分别等于有符号32位整型数的负、正极限值。
~
终止信号处理器函数的其他方法
目前为止所看到的信号处理器函数都是以返回主程序而终结。
以下是从信号处理器函数中终止的其他一些方法。
* 使用_exit()终止进程。处理器函数事先可以做一些清理工作。注意,不要使用exit()来终止信号处理器函数,因为它不在表21-1所列的安全函数中。之所以不安全,是因为如25.1节所述,该函数会在调用_exit()之前刷新stdio的缓冲区。
* 使用kill()发送信号来杀掉进程(即,信号的默认动作是终止进程)。
* 从信号处理器函数中执行非本地跳转。
* 使用abort()函数终止进程,并产生核心转储。
~
核心转储文件
特定信号会引发进程创建一个核心转储文件并终止运行(参考表20-1)。所谓核心转储是内含进程终止时内存映像的一个文件。(术语core源于一种老迈的内存技术。)将该内存映像加载到调试器中,即可查明信号到达时程序代码和数据的状态。
引发程序生成核心转储文件的方式之一是键入退出字符(通常为Control-\\),从而生成SIGQUIT信号。
$ ulimit -c unlimited
$ sleep 30 Explained in main text
Type Control-\\
Quit (core dumped)
$ ls -1 core Shows core dump file for sleep(1)
-rw------- 1 mtk users 57344 Nov 30 13:39 core
核心转储文件创建于进程的工作目录中,名为core。这是核心转储文件的默认位置和名称。稍后,将解释如何改变这些默认值。
借助于许多实现所提供的工具(例如FreeBSD 和Solaris中的gcore),可获取某一正在运行进程的核心转储文件。Linux 系统也有类似功能,使用gdb去连接(attach)运行的进程,然后运行 gcorc 命令。
不产生核心转储文件的情况
以下情况不会产生核心转储文件。
* 进程对于核心转储文件没有写权限。造成这种情况的原因有进程对将要创建核心转储文件的所在目录可能没有写权限,或者是因为存在同名(且不可写,亦或非常规类型,例如,目录或符号链接)的文件。
* 存在一个同名、可写的普通文件,但指向该文件的(硬)链接数超过一个。
* 将要创建核心转储文件的所在目录并不存在。
* 把进程“核心转储文件大小”这一资源限制置为0。36.3节将就这一限制(RLIMIT_CORE)进行详细讨论。上例就使用了ulimit命令(C shell中为limit命令)来取消对核心转储文件大小的任何限制。
* 将进程“可创建文件的大小”这一资源限制设置为0。36.3节将描述这一限(RLIMIT_FSIZE)。
* 对进程正在执行的二进制可执行文件没有读权限。这样‘就防止了用户借助于核心转储文件来获取本无法读取的程序代码。
* 以只读方式挂载当前工作目录所在的文件系统,或者文件系统空间已满,又或者i-node资源耗尽。还有一种情况,即用户已经达到其在该文件系统上的配额限制。
* Set-user-ID(set-group-ID)程序在由非文件属主(或属组)执行时,不会产生核心转储文件。这可以防止恶意用户将一个安全程序的内存转储出来,再针对诸如密码之类的敏感信息进行刺探。
借助于Linux 专有系统调用 prctl()的PR_SET_DUMPABLE 操作,可以为进程设置dumpable 标志。当非文件属主(或属组)运行set-user-ID(set-group-ID)程序时,如设置该标志即可生成核心转储文件。PR_SET_DUMPABLE 操作始见于Linux 2.4,更多详细信息参见prctl(2)手册页。另外,始于内核版本2.6.13,针对set-user-ID和set-group-ID进程是否产生核心转储文件,/proc/sys/fs/suid_dumpable 文件开始提供系统级控制。详情参见proc(5)手册页。
始于内核版本2.6.23,利用Linux特有的/proc/PID/coredump_filter,可以对写入核心转储文件的内存映射类型(第49章将解释内存映射)施以进程级控制。该文件中的值是一个4位掩码,分别对应于4种类型的内存映射:私有匿名映射、私有文件映射、共享匿名映射以及共享文件映射。文件默认值提供了传统的Linux行为:仅对私有匿名映射和共享匿名映射进行转储。详情参见core(5)手册页。
为核心转储文件命名:/proc/sys/kernel/core_pattern
~
实时信号
sigqueue()
SA_SIGINFO
~
sigsuspend() 使用掩码来等待信号
sigwaitinfo() 同步接收信号
sigtimedwait() 允许指定等待时限
signalfd()创建一个特殊文件描述符,发往调用者的信号都可以从该描述符中读取。 不需要时,应关闭释放资源。
~
Kill %1 Kill program running in background
~
利用信号进行进程间通信
从某种角度,可将信号视为进程间通信(IPC)的方式之一。然而,信号作为一种IPC机制却也饱受限制。首先,与后续各章描述的其他IPC方法相比,对信号编程既繁且难,具体原因如下。
* 信号的异步本质就意味着需要面对各种问题,包括可重入性需求、竞态条件及在信号处理器中正确处理全局变量。(如果用 sigwaitinfo()或者signalfd()来同步获取信号,这些问题中的大部分都不会遇到。)
* 没有对标准信号进行排队处理。即使是对于实时信号,也存在对信号排队数量的限制。这意味着,为了避免丢失信息,接收信号的进程必须想方设法通知发送者,自己为接受另一个信号做好了准备。要做到这一点,最显而易见的方法是由接收者向发送者发送信号。
还有一个更深层次的问题,信号所携带的信息量有限:信号编号以及实时信号情况下一字之长的附加数据(一个整数或者一枚指针值)。与诸如管道之类的其他IPC方法相比,过低的带宽使得信号传输极为缓慢。
由于上述种种限制,很少将信号用于IPC。
~~~
22.14 总结
某些信号会引发进程创建一个核心转储文件,并终止进程。核心转储所包含的信息可供调试器检查进程终止时的状态。默认情况下,对核心转储文件的命名为core,但Linux提供了proc/sys/kernel/core_pattern文件来控制对核心转储文件的命名。
信号的产生方式既可以是异步的,也可以是同步的。当由内核或者另一进程发送信号给进程时,信号可能是异步产生的。进程无法精确预测异步产生信号的传递时间。(文中曾指出,异步信号通常会在接收进程第二次从内核态切换到用户态时进行传递。)因进程自身执行代码而直接产生的信号则属于是同步产生的,例如,执行了一个引发硬件异常的指令,或者去调用raise()。同步生成的信号,其传递可以精确预测(立即传递)。
实时信号是POSIX对原始信号模型的扩展,不同之处包括对实时信号进行队列化管理,具有特定的传递顺序,并且还可以伴随少量数据一同发送。设计实时信号,意在供应用程序自定义使用。实时信号的发送使用sigqueue()系统调用,并且还向信号处理器函数提供了一个附加参数(siginfo_t结构),以便其获得信号的伴随数据,以及发送进程的进程ID和实际用户ID。
sigsuspend()系统调用在自动修改进程信号掩码的同时,还将挂起进程的执行直到信号到达,且二者属于同一原子操作。为了避免执行上述功能时出现竞态条件,确保sigsuspend()的原子性至关重要。
可以使用sigwaitinfo()和sigtimedwait()来同步等待一个信号。这省去了对信号处理器的设计和编码工作。对于以等待信号的传递为唯一目的的程序而言,使用信号处理器纯属多此一举。
像sigwaitinfo()和 sigtimedwait()一样,可以使用Linux特有的signalfd()系统调用来同步等待一个信号。这一接口的独特之处在于可以通过文件描述符来读取信号。还可以使用selet()、poll()和epoll来对其进行监控。
尽管可以将信号视为IPC的方式之一,但诸多制约因素令其常常无法胜任这一目的,其中包括信号的异步本质、不对信号进行排队处理的事实,以及较低的传递带宽。信号更为常见的应用场景是用于进程同步,或是各种其他目的(比如,事件通知、作业控制以及定时器到期)。
此外,还有各种信号相关的函数是针对线程的(比如,pthread kill()和pthreadsigmask()),将延后至33.2节进行讨论。
~~~~~
定时器,用途之一是为系统调用的阻塞设定时间上限。
~
POSIX时钟
POSIX间隔式定时器
~
pthread_mutex_lock()
pthread_cond_signal()
pthread_cond_wait()
~
ctrl+Z suspend program inbackground
fg 用于将后台运行的或挂起的任务切换到前台运行
~
fork() 创建新进程
理解fork()的诀窍是,要意识到,完成对其调用后将存在两个进程,且每个进程都会从fork()的返回处继续执行。
这两个进程将执行相同的程序文本段,但却各自拥有不同的栈段、数据段以及堆段拷贝。子进程的栈、数据以及栈段开始时是对父进程内存相应各部分的完全复制。执行fork()之后,每个进程均可修改各自的栈数据、以及堆段中的变量,而并不影响另一进程。
程序代码则可通过fork()的返回值来区分父、子进程。在父进程中,fork()将返回新创建子进程的进程ID。鉴于父进程可能需要创建,进而追踪多个子进程(通过wait()或类似方法),这种安排还是很实用的。而 fork()在子进程中则返回0。如有必要,子进程可调用getpid()以获取自身的进程ID,调用getppid()以获取父进程ID。
当无法创建子进程时,fork()将返回-1。失败的原因可能在于,进程数量要么超出了系统针对此真实用户(real user ID)在进程数量上所施加的限制(RLIMIT_NPROC,36.3节将对此加以描述),要么是触及允许该系统创建的最大进程数这一系统级上限。
调用fork()时,有时会采用如下习惯用语:
pid_t childpid; /* Used in parent after successful fork() to record PID of child */
switch (childpid = fork())
case -1: /* fork() failed */
/* Handle error */
case 0:
/* Child of successful fork() comes here */
/* Perform actions specific to child */
default:
/* Parent comes here after successful fork()*/
/* Perform actions specific to parent */
调用fork()之后,系统将率先“垂青”于哪个进程(即调度其使用CPU)是无法确定的。
~~~
控制进程的内存需求
通过将fork()与wait()组合使用,可以控制一个进程的内存需求。进程的内存需求量,亦即进程所使用的虚拟内存页范围,受到多种因素的影响,例如,调用函数,或从函数返回时栈的变化情况,对exec()的调用,以及因调用malloc()和 firee()而对堆所做的修改——这点对这里的讨论有着特殊意义。
假设以程序清单24-3所示方式调用fork()和 wait(),且将对某函数 fumc()的调用置于括号之中。由执行程序可知,由于所有可能的变化都发生于子进程,故而从对func()的调用之前开始,父进程的内存使用量将保持不变。这一用法的实用性则归于如下理由。
* 若已知func()导致内存泄露,或是引发堆内存的过度碎片化,该技术则可以避免这些问题。(要是无法访问func()的源码,想要处理这些问题也就无从谈起。)
* 假设某一算法在做树状分析(tree analysis)的同时需要进行内存分配(例如,游戏程序需要分析一系列可能的招法以及对方的应手)。本可以调用firee()来释放所有已分配的内存,不过在某些情况下,使用此处所描述的技术会更为简单,返回(父进程),且调用者(父进程)的内存需求并无改变。
如程序清单24-3的实现所示,必须将func()的返回结果置于exit()的8位传出值中,父进程调用wait()可获得该值。不过,也可以利用文件、管道或其他一些进程间通信技术,使func()返回更大的结果集。
程序清单24-3:调用函数而不改变进程的内存需求量
pid t childpid;
int status;
childpid = fork();
if (childPid ==-1)
errExit("fork");
if (childPid == 0) /* Child calls func() and */
exit(func(arg)); /* uses return value as exit status */
/* Parent waits for child to terminate. It can determine the result of func() by inspecting \'status\'.*/
if (wait(&status)==-1)
errExit("wait");
~~~~~~~~~~~~~~~~~~~~~
退出处理程序 exit handler
注册退出处理程序 atexit() on_exit()
~
stdio缓冲区
可以采用以下任一方法来避免重复的输出结果。
* 作为针对 stdio 缓冲区问题的特定解决方案,可以在调用fork()之前使用函数 fflush()来刷新stdio缓冲区。作为另一种选择,也可以使用setvbuf()和setbuf()来关闭stdio流
* 子进程可以调用_exit()而非exit(),以便不再刷新 stdio缓冲区。这一技术例证了一个更为通用的原则:在创建子进程的应用中,典型情况下仅有一个进程(一般为父进程)应通过调用_exit()终止,而其他进程应调用exit()终止,从而确保只有一个进程调用退出处理程序并刷新stdio缓冲区,这也算是众望所归吧。
还存在其他方法,可以(有时很有必要)允许父子进程都调用exit()。例如,可以设计这样的退出处理程序,即使是从多个进程中调用,它们也能够正确地处理,或者令应用程序仅在调用fork()之后才去安装退出处理程序。此外,有时可能确实希望所有的应用程序都在fork()之后刷新 stdio 缓冲区。这时,可以见机行事,要么选择使用exit()来终止进程,要么在每个进程中均显式调用flfush()。
~
25.5总结
进程的终止分为正常和异常两种。异常终止可能是由于某些信号引起,其中的一些信号还可能导致进程产生一个核心转储文件。
正常的终止可以通过调用_exit()完成,更多的情况下,则是使用_exit()的上层函数exit()完成。_exit()和 exit()都需要一个整型参数,其低8位定义了进程的终止状态。依照惯例,状态0用来表示进程成功完成,非0则表示异常退出。
不管进程正常终止与否,内核都会执行多个清理步骤。调用exit()正常终止一个进程,将会引发执行经由atexit()和on_exit()注册的退出处理程序(执行顺序与注册顺序相反),同时刷新stdio缓冲区。
~
在shell中,可通过读取$?变量来获取上次执行命令的终止状态。
~
孤儿进程与僵尸进程
进程ID为1的众进程之祖-init会接管孤儿进程。
换言之,某一子进程的父进程终止后,对getppid()的调用将返回1,这是判定某一子进程之“生父”是否“在世”的方法之一(前提是假设该子进程由init之外的进程创建)。
使用参数 PR_SET_PDEATHSIG 调用Linux特有的系统调用prctl(),将有可能导致某一进程在成为孤儿时收到特定信号。
在父进程执行 wait()之前,其子进程就已经终止,这将会发生什么?此处的要点在于,即使子进程已经结束,系统仍然允许其父进程在之后的某一时刻去执行wait(),以确定该子进程是如何终止的。内核通过将子进程转为僵尸进程(zombie)来处理这种情况。这也意味着将释放子进程所把持的大部分资源,以便供其他进程重新使用。该进程所唯一保留的是内核进程表中的一条记录,其中包含了子进程ID、终止状态、资源使用数据(36.1节)等信息。
至于僵尸进程名称的由来,则源于UNIX系统对电影情节的效仿-无法通过信号来杀死僵尸进程,即便是(银弹)SIGKILL。这就确保了父进程总是可以执行wait()方法。
当父进程执行wait()后,由于不再需要子进程所剩余的最后信息,故而内核将删除僵尸进程。另一方面,如果父进程未执行wait()随即退出,那么init 进程将接管子进程并自动调用wait(),从而从系统中移除僵尸进程。
如果父进程创建了某一子进程,但并未执行wait(),那么在内核的进程表中将为该子进程永久保留一条记录。如果存在大量此类僵尸进程,它们势必将填满内核进程表,从而阻碍新进程的创建。既然无法用信号杀死僵尸进程,那么从系统中将其移除的唯一方法就是杀掉它们的父进程(或等待其父进程终止),此时init 进程将接管和等待这些僵尸进程,从而从系统中将它们清理掉。
在设计长生命周期的父进程(例如:会创建众多子进程的网络服务器和Shell)时,这些语义具有重要意义。换句话说,在此类应用中,父进程应执行wait()方法,以确保系统总是能够清理那些死去的子进程,避免使其成为长寿僵尸。如26.3.1节所述,父进程在处理SIGCHLD信号时,对wait()的调用既可同步,也可异步。
~
ps | grep %s basename(argv[0])
ps(1)所输出的字符串<defunct>表示进程处于僵尸状态。
~
26.4总结
使用wait()和waitpid()(以及其他相关函数),父进程可以得到其终止或停止子进程的状态。该状态表明子进程是正常终止(带有表示成功或失败的退出状态),还是异常中止,因收到某个信号而停止,还是因收到SIGCONT信号而恢复执行。
如果子进程的父进程终止,那么子进程将变为孤儿进程,并为进程ID为1的init进程接管。子进程终止后会变为僵尸进程,仅当其父进程调用wait()(或类似函数)获取子进程退出状态时,才能将其从系统中删除。在设计长时间运行的程序,诸如 shell程序以及守护进程(daemon)时,应总是捕获其所创建子进程的状态,因为系统无法杀死僵尸进程,而未处理的僵尸进程最终将塞满内核进程表。
捕获终止子进程的一般方法是为信号SIGCHLD设置信号处理程序。当子进程终止时(也可选择子进程因信号而停止时),其父进程会收到SIGCHLD信号。还有另一种移植性稍差的处理方法,进程可选择将对SIGCHLD信号的处置置为忽略(SIG_IGN),这时将立即丢弃终止子进程的状态(因此其父进程从此也无法获取到这些信息),子进程也不会成为僵尸进程。
~~
27.3 解释器脚本
所谓解释器(interpreter),就是能够读取并执行文本格式命令的程序。(相形之下,编译器则是将输入源代码译为可在真实或虚拟机器上执行的机器语言。)各种UNIX shell,以及诸如awk、sed、perl、python和ruby之类的程序都属于解释器。除了能够交互式地读取和执行命令之外,解释器通常还具备这样一种能力:从被称为脚本(script)的文本文件中读取和执行命令。
UNIX内核运行解释器脚本的方式与二进制(binary)程序无异,前提是脚本必须满足下面两点要求:首先,必须赋予脚本文件可执行权限;其次,文件的起始行(initial line)必须指定运行脚本解释器的路径名。格式如下:
#! interpreter-path [ optional-arg ]
字符#!必须置于该行起始处,这两个字符串与解释器路径名之间可以以空格分隔。在解释该路径名时不会使用环境变量PATH,因而一般应采用绝对路径。使用相对路径固然可行,但很少见。对其解释则相对于启动解释器进程的当前工作自录。解释器路径名后还可跟随可选参数(稍后将解释其目的),二者之间以空格分隔。可选参数中不应包含空格。
作为例子,UNIX shell 脚本通常以下面这行开始,指定运行该脚本的 shell:
#!/bin/sh
解释器脚本文件首行中的可选参数不应包含空格,因为空格此处所起的作用完全取决于实现。Linux 系统不会对可选参数(optional-arg)中的空格做特殊解释,将从参数起始直至行尾的所有文本视为一个单词(正如后面所述,再将其作为一整个参数传递给解释器)。注意,对空格的这种处理方式与shell的做法形成鲜明对比,后者总是将其视为命令行中各单词的界定符。
Linux 内核要求脚本的起始行不得超过127个字节,其中不包括行尾的换行符(newline)。超出部分会被悄无声息地略去。
~
执行时关闭(close-on-exec)标志 (FD_CLOEXEC)
fcntl() F_GETFD F_SETFD
~
system()
~
进程记账 process accounting
acct()
~
clone() 系统调用
在进程创建期间对步骤的控制更为精准。
主要用于线程库的实现。
有损于程序的可移植性,故而应避免在应用程序中直接使用。
~
29.9 线程VS进程
将应用程序实现为一组线程还是进程?
本节将简单考虑一下可能影响这一决定的部分因素。先从多线程方法的优点开始。
* 线程间的数据共享很简单。相形之下,进程间的数据共享需要更多的投入。(例如,创建共享内存段或者使用管道pipe)。
* 创建线程要快于创建进程。线程间的上下文切换(context-switch),其消耗时间一般也比进程要短。
线程相对于进程的一些缺点如下所示。
* 多线程编程时,需要确保调用线程安全(thread-safe)的函数,或者以线程安全的方式来调用函数。(31.1节将讨论线程安全的概念。)多进程应用则无需关注这些。
* 某个线程中的bug(例如,通过一个错误的指针来修改内存)可能会危及该进程的所有线程,因为它们共享着相同的地址空间和其他属性。相比之下,进程间的隔离更彻底。
* 每个线程都在争用宿主进程(host process)中有限的虚拟地址空间。特别是,一旦每个线程栈以及线程特有数据(或线程本地存储)消耗掉进程虚拟地址空间的一部分,则后续线程将无缘使用这些区域。虽然有效地址空间很大(例如,在x86-32平台上通常有 3GB),但当进程分配大量线程,亦或线程使用大量内存时,这一因素的限制作用也就突显出来。与之相反,每个进程都可以使用全部的有效虚拟内存,仅受制于实际内存和交换(swap)空间。
影响选择的还有如下几点。
* 在多线程应用中处理信号,需要小心设计。(作为通则,一般建议在多线程程序中避免使用信号。)关于线程与信号,33.2节会做深入讨论。
* 在多线程应用中,所有线程必须运行同一个程序(尽管可能是位于不同函数中)。对于多进程应用,不同的进程可以运行不同的程序。
* 除了数据,线程还可以共享某些其他信息(例如,文件描述符、信号处置、当前工作目录,以及用户I和组ID)。优劣之判,视应用而定。
~
29.10 总结
在多线程程序中,多个线程并发执行同一程序。所有线程共享相同的全局和堆变量,但每个线程都配有用来存放局部变量的私有栈。同一进程中的线程还共享一干其他属性,包括进程ID、打开的文件描述符、信号处置、当前工作目录以及资源限制。
线程与进程间的关键区别在于,线程比进程更易于共享信息,这也是许多应用程序舍进程而取线程的主要原因。对于某些操作来说(例如,创建线程比创建进程快),线程还可以提供更好的性能。但是,在程序设计的进程/线程之争中,这往往不会是决定性因素。
可使用pthread_create()来创建线程。每个线程随后可调用pthreadexit()独立退出。(如有任一线程调用了exit(),那么所有线程将立即终止。)除非将线程标记为分离状态(例如通过调用pthread detached()),其他线程要连接该线程,则必须使用pthread_join(),由其返回遭连接线程的退出状态。
~~~
线程:线程同步
两个工具:互斥量(mutexe)和条件变量(condition variable)。
互斥量可以帮助线程同步对共享资源的使用,以防如下情况发生:线程某甲试图访问一共享变量时,线程某乙正在对其进行修改。
条件变量则是在此之外的拾遗补缺,允许线程相互通知共享变量(或其他共享资源)的状态发生了变化。
~
术语临界区(critical section)是指访问某一共享资源的代码片段,并且这段代码的执行应为原子(atomic)操作,亦即同时访问同一共享资源的其他线程不应中断该片段的执行。
~
为避免线程更新共享变量时所出现问题,必须使用互斥量(mutex是mutual exclusion的缩写)来确保同时仅有一个线程可以访问某项共享资源。更为全面的说法是,可以使用互斥量来保证对任意共享资源的原子访问,而保护共享变量是其最常见的用法。
互斥量有两种状态;已锁定(locked)和未锁定,(unlocked)。任何时候,至多只有一个线程可以锁定该互斥量。试图对已经锁定的某一互斥量再次加锁,将可能阻塞线程或者报错失败,具体取决于加锁时使用的方法。
一旦线程锁定互斥量,随即成为该互斥量的所有者。只有所有者才能给互斥量解锁。这一属性改善了使用互斥量的代码结构,也顾及到对互斥量实现的优化。因为所有权的关系,有时会使用术语获取(acquire)和释放(release)来替代加锁和解锁。
一般情况下,对每一共享资源(可能由多个相关变量组成)会使用不同的互斥量,每一线程在访问同一资源时将采用如下协议。
* 针对共享资源锁定互斥量。
* 访问共享资源。
* 对互斥量解锁。
如果多个线程试图执行这一代码块(一个临界区),事实上只有一个线程能够持有该互斥量(其他线程将遭到阻塞),即同时只有一个线程能够进入这段代码区域。
注意:使用互斥锁仅是一种建议,并非强制。
~~
有时,一个线程需要同时访问两个或更多不同的共享资源,而每个资源又都由不同的互斥量管理。当超过一个线程加锁同一组互斥量时,就有可能发生死锁。
要避免此类死锁问题,最简单的方法是定义互斥量的层级关系。当多个线程对一组互斥量操作时,总是应该以相同顺序对该组互斥量进行锁定。
另一种方案的使用频率较低,就是“尝试一下,然后恢复”。在这种方案中,线程先使用函数pthread mutex_lock()锁定第1个互斥量,然后使用函数pthread mutex_ trylock()来锁定其余互斥量。如果任一pthread mutex_trylock()调用失败(返回EBUSY),那么该线程将释放所有互斥量,也许经过一段时间间隔,从头再试。较之于按锁的层级关系来规避死锁,这种方法效率要低一些,因为可能需要历经多次循环。另一方面,由于无需受制于严格的互斥量层级关系,该方法也更为灵活。[Butenhof,1996]中载有这一方案的范例。
~~~
pthread_mutex_lock()
pthread_mutex_unlock()
pthread_mutex_trylock()
pthread_mutex_timedlock()
PTHREAD_MUTEX_INITIALIZER
pthread_mutex_init()
pthread_mutex_destroy()
~
通知状态的改变:条件变量 (Condition Variable)
互斥量防止多个线程同时访问同一共享变量。条件变量允许一个线程就某个共享变量(或其他共享资源)的状态变化通知其他线程,并让其他线程等待(堵塞于)这一通知。
~
pthread_cond_signal()
pthread_cond_broadcast()
pthread_cond_wait()
PTHREAD_COND_INITIALIZER
pthread_cond_init()
pthread_cond_destroy()
~
通用设计原则:必须由一个while循环,而不是if语句,来判断对pthread_cond_wait()的调用。
这是因为,当代码从pthread_cond wait()返回时,并不能确定判断条件的状态,所以应该立即重新检查判断条件,在条件不满足的情况下继续休眠等待。
从pthread cond_wait()返回时,之所以不能对判断条件的状态做任何假设,其理由如下。
* 其他线程可能会率先醒来。也许有多个线程在等待获取与条件变量相关的互斥量。即使就互斥量发出通知的线程将判断条件置为预期状态,其他线程依然有可能率先获取互斥量并改变相关共享变量的状态,进而改变判断条件的状态。
* 设计时设置“宽松的”判断条件或许更为简单。有时,用条件变量来表征可能性而非确定性,在设计应用程序时会更为简单。换言之,就条件变量发送信号意味着“可能有些事情”需要接收信号的线程去响应,而不是“一定有一些事情”要做。使用这种方法,可以基于判断条件的近似情况来发送条件变量通知,接收信号的线程可以通过再次检查判断条件来确定是否真的需要做些什么。
* 可能会发生虚假唤醒的情况。在一些实现中,即使没有任何其他线程真地就条件变量发出信号,等待此条件变量的线程仍有可能醒来。在一些多处理器系统上,为确保高效实现而采用的技术会导致此类(不常见的)虚假唤醒。SUSv3对此予以明确认可。
~
30.3 总结
线程提供的强大共享是有代价的。多线程应用程序必须使用互斥量和条件变量等同步原语来协调对共享变量的访问。互斥量提供了对共享变量的独占式访问。条件变量允许一个或多个线程等候通知:其他线程改变了共享变量的状态。
~
31.5总结
若一函数可由多个线程同时安全调用,则称之为线程安全的函数。使用全局或静态变量是导致函数非线程安全的通常原因。在多线程应用中,保障非线程安全函数安全的手段之一是运用互斥锁来防护对该函数的所有调用。这种方法带来了并发性能的下降,因为同一时点只能有一个线程运行该函数。提升并发性能的另一方法是:仅在函数中操作共享变量(临界区)的代码前后加入互斥锁。
使用互斥量可以实现大部分函数的线程安全,不过由于互斥量的加、解锁开销,故而也带来了性能的下降。如能避免使用全局或静态变量,可重入函数则无需使用互斥量即可实现线程安全。
SUSv3所规范的大部分函数都需实现线程安全。SUSv3同时也列出了小部分无需实现线程安全的函数。一般情况下,这些函数将静态存储返回给调用者,或者在对函数的连续调用间进行信息维护。根据定义,这些函数是不可重入的,也不能使用互斥量来确保其线程安全。本章讨论了两种大致相当的编程技术——线程特有数据和线程局部存储——可在无需改变函数接口定义的情况下保障不安全函数的线程安全。这两种技术均允许函数分配持久的、基于线程的存储。
~
线程:线程取消
pthread_cancel()
pthread_setcancelstate()
pthread_setcanceltype()
线程一旦收到取消请求,且启用了取消性状态并将类型置为延迟,则其会在下次抵达取消点时终止。如果该线程尚未分离(not detached),那么为防止其变为僵尸线程,必须由其他线程对其进行连接(join)。连接之后,返回至函数pthread_join()中第二个参数的将是一个特殊值:PTHREAD_CANCELED。
~
线程可取消性的检测
pthread_testcancel() 产生一个取消点。线程如果已有处于挂起状态的取消请求,那么只要调用该函数,线程就会随之终止。
当线程执行的代码未包含取消点时,可以周期性地调用pthread_testcancel(),以确保对其他线程向其发送的取消请求做出及时响应。
~
清理函数(Cleanup handler)
每个线程都可以拥有一个清理函数栈。当线程遭取消时,会沿该栈自项向下依次执行清理函数,首先会执行最近设置的函数,接着是次新的函数,以此类推。当执行完所有清理函数后,线程终止。
函数 pthrcad_cleanup_push()和 pthread_cleanup_pop()分别负责向调用线程的清理函数栈添加和移除清理函数。
~
32.7 总结
函数pthread_cancel()允许某线程向另一个线程发送取消请求,要求目标线程终止。
目标线程如何响应,取决于其取消性状态和类型。如果禁用线程的取消性状态,那么请求会保持挂起(pending)状态,直至将线程的取消性状态置为启用。如果启用取消性状态,那么线程何时响应请求则依赖于取消性类型。若类型为延迟取消,则在线程下一次调用某个取消点(由SUSv3标准所规定的一系列函数之一)时,取消发生。如果为异步取消类型,取消动作随时可能发生(鲜有使用)。
线程可以设置一个清理函数栈,其中的清理函数属于由开发人员定义的函数,当线程遭到取消时,会自动调用这些函数以执行清理工作(例如,恢复共享变量状态,或解锁互斥量)。
~
NPTL (Native POSIX Threads Library)
~
高级线程同步原语:障碍(barrier)、读写锁(read-write lock)、自旋锁(spin lock)
~
本文来自博客园,作者:Theseus‘Ship,转载请注明原文链接:https://www.cnblogs.com/yongchao/p/17367304.html
PE知识复习之PE合并节
PE知识复习之PE合并节
一丶简介
根据上一讲.我们为PE新增了一个节. 并且属性了各个成员中的相互配合. 例如文件头记录节个数.我们新增节就要修改这个个数.
那么现在我们要合并一个节.以上一讲我们例子讲解.
以前我们讲过PE扩大一个节怎么做. 合并节跟扩大节类似. 只不过一个是扩大. 一个是合并了.
合并节的步骤.
1.修改文件头节表个数
2.修改节表中的属性
节.sIzeofRawData 节数据对齐后的大小.
3.修改扩展头中PE镜像大小 SizeofImage
4.被合并的节以0填充.
二丶实战合并一个节
1.修改文件头中节表个数
为什么修改应该不用多说了. 我们既然合并. 那么节就要少一个.那么自然就进行修改了.

原节表有8个.我们修改为7即可.
2.修改节.SizeofRawData 节数据对齐后的大小.

我们把最后的AAAA节.合并到上一个节.rsrc中.
.rsrc.SizeofRawData = .文件对齐(rsrc.SizeofRawData + AAA.节数据的大小)
修改这个属性就按照上面的公式修改就行.原来节数据大小.加上要被合并的节的数据大小.按照文件对齐存放即可.
例如下图:

原来节数据对齐后的大小是0x600. AAAA节数据对齐后的大小是0x1000.那么修改.rsrc.SizeofRawData 为 0x1600即可.

最后一个节表以0填充即可.
3.修改扩展头的PE镜像大小. SizeofImage
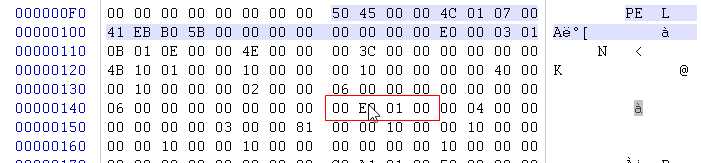
我们上一讲新增了一个节.所以映像大小为0x1E000. 所以现在要进行修改.合并了0x1000数据大小.那么改为0x1D000即可.
4.测试程序
程序可以直接运行.那么内存中看看节展开位置有没有我们的合并节的节数据.

内存中0x41c000位置.就是节展开位置.我们没有合并之前.并没有我们的FFFF填充的数据.合并之后.出现了数据.说明已经成功合并了这个节了.
也相当于对这个节进行扩大了.
以上是关于节)的主要内容,如果未能解决你的问题,请参考以下文章