最近看到一个 UP 主做的视频,使用可视化动态图,把目前播放量最多的 UP 主一一列出来,结果第一名是哔哩哔哩番剧,第一名的播放量是第二名近 10 倍。

B站的番剧数量,也是相对其他平台比较多的,而且质量都还不错。说实话,刚开始用哔哩哔哩的时候,就是为了看番剧。作为一个喜欢看番剧的 pk 哥,我决定用爬虫爬取一下日本动漫电影 TOP100 都有哪些?网上看了一下,时光网正好有这个排行榜,而且信息相对来说比较全。

所以我决定用爬虫把这个榜单上 Top100 的所有电影信息全部保存为 csv 文件放在本地,看有没有之前我遗漏的经典动漫电影。
以下是保存的效果。保存的列包括电影名称、导演编剧、发行公司、更多片名、评分、首日票房、总票房。有些电影没有评分和票房信息的就直接显示为空。

获取电影ID信息
本次爬虫项目主要分为三个部分。第一部分我们要获取电影的 Id信息,因为我们需要保存的所有信息,都和这个有关。Id从哪里获取呢?我们打开这个榜单页面的源代码。源代码中我们可以看到,id都在链接后面。

为了缩小范围,我们发现这些链接都在 class=top_nlist 里面,我们用 beautifulsoup 库提取属性 class= top_nlist 所有的元素。然后用正则表达式,提取出每页的 id信息。

这里第 1 个页面需要特殊处理一下,因为第 2 个页面到第 10 个页面后面都是直接带的数字,第 1 个页面直接我在后面加 -1 的话会报 404,所以这个页面单独拿出来提取页面信息。然后再把 ID 信息全部加到空列表里面。
提取评分和票房信息
ID 信息获取了,接下来我们通过 ID 信息来获取电影的评分和票房信息。通过 F12 调试我们可以看到。评分和票房信息在 js 里面。

请求链接里变化的就是电影的 ID ,其他的保持不变就好。
我们对返回信息通过简单的处理转换为 Json 格式。之后我们就可以直接通过 key 值提取 value 值了。这里主要提取的信息有:评分、首日票房和总票房。

提取其他电影详细信息
接下来我们需要通过 ID 信息获取对应电影的名称和导演编剧等详细信息。这些信息在源代码中,可以直接通过正则表达式来提取。

用正则表达式提取信息的前提是我们要找到信息的规律。这样通过正则表达式提取就又快又准。

提取了这些信息之后,我们把它保存在 list 列表中,这样做的目的是为了后面我们保存为 csv 文件做准备。
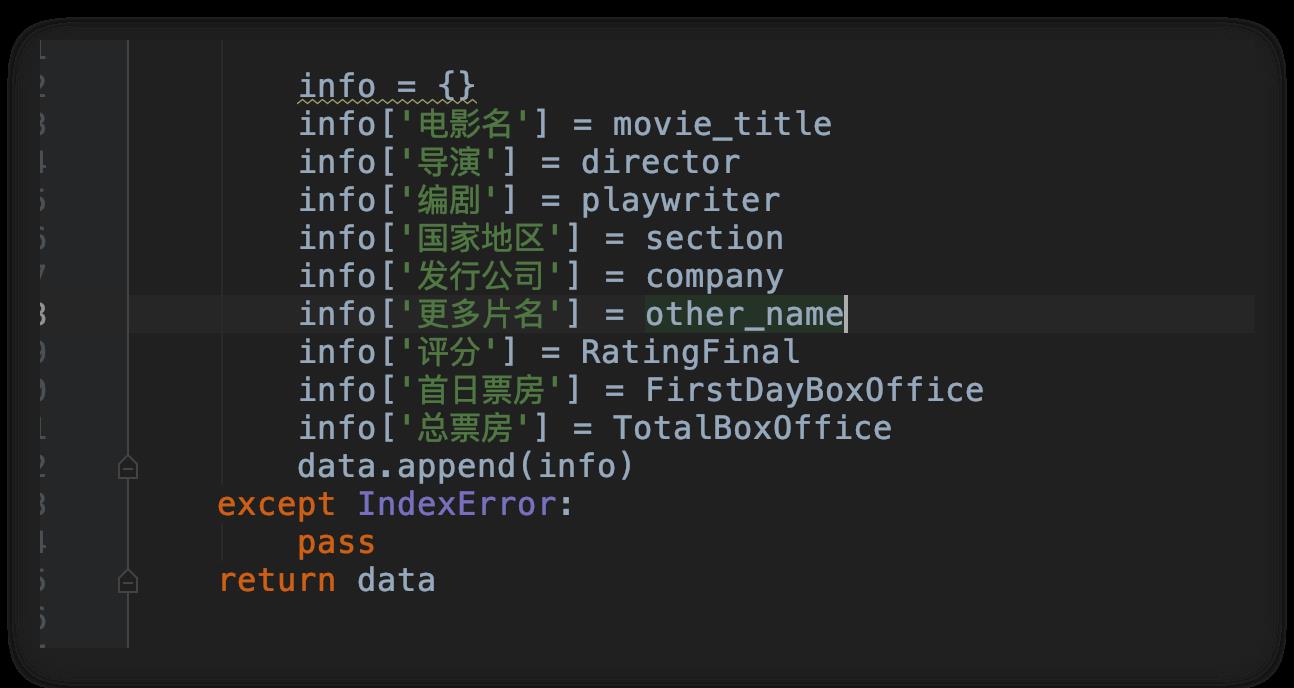
保存为csv文件
每页的信息获取了之后,我们就可以把这些信息追加保存到 csv 文件中。每保存一部电影信息,保存下一部电影信息就进行追加保存。为了避免保存后的 csv 文件打开出现乱码,我们需要将编码形式设置为 encoding=\'utf-8\' 格式。
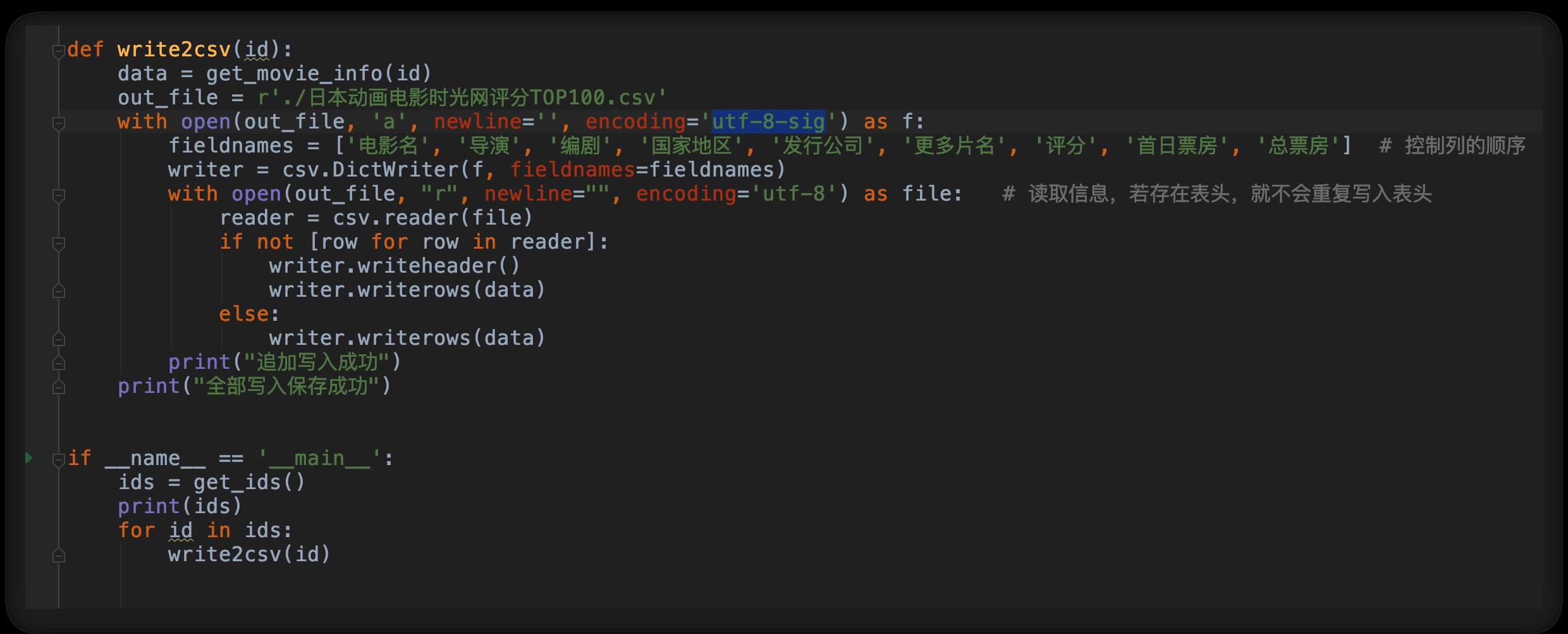
通过这三步,这个 Top100 排行榜中的所有动漫电影信息都全部保存在本地的 csv 文件中啊。那我们就可以更方便的浏览这些电影信息。这样我们就可以更好的追番了。本文所有的代码信息可在公众号「Python知识圈」后台回复「动漫电影」获取。