hibernate中 session.save(实体类)方法的原理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hibernate中 session.save(实体类)方法的原理相关的知识,希望对你有一定的参考价值。
我们知道hibernate中的session类中的save()方法可以将某一个实体类的对象存入数据库中,那么我想知道,session是如何判断传入的对象的真实的类型,并将其插入数据库中的?
例如:我有一个user对象,现在我想通过session中的save方法存储这个user对象,那么我需要这样写session.save(user);那么,我想问一下,session接收user对象后,它是如何知道user所属的类型,并解析user中的属性,然后将其插入到数据库中的?请注意,重点是session是如何判断user的本来类型的,解决这个问题就可以了,谢谢!

请您详细的说明一下,它是如何根据传入的对象来找到user对象的试题bean?
追答(1)把user对象加入到缓存中,使它变为持久化对象。
(2)选用映射文件指定的标识符生成器为持久化对象分配惟一的OID。比如user.hbm.xml文件中元素的子元素指定标识符生成器:
(3)计划执行一个insert语句,把user对象当前的属性值组装到insert语句中:
insert into CUSTOMERS(ID, NAME, ......) values(1, 'Tom', ......);
值得注意的是,save()方法并不立即执行SQL insert语句。只有当Session清理缓存时,才会执行SQL insert语句。如果在save()方法之后,又修改了持久化对象的属性,这会使得Session在清理缓存时,额外执行SQL update语句。以下两段代码尽管都能完成相同的功能,但是左边代码仅执行一条SQL insert语句,而右边代码执行一条SQL insert和一条SQL update语句。第一种代码减少了操作数据库的次数,具有更好的运行性能。
UserBean user = new UserBean();
// 先设置Customer对象的属性,再保存它
user .setName("Tom");
user .save(user );
transaction.commit();
UserBean user= new UserBean();
session.save(user );
// 先保存Customer对象,再修改它的属性
user .setName("Tom");
transaction.commit();
你的这个我已经看过了,但是你想实现上面的setName()方法就必须知道它所属的类型啊,这个问题并没有解决。
追答setName() 所属类型?方法不都是 public void setName(String name),String 属性啊,有点不明白你的意思了。
如果是数据库对应,那在生成的时候就和数据库的varchar2对应了啊。。。。
首先,你看看session类中的save方法,它是用object对象来接收传进来的值,并不知道传进来的是user对象,你怎么能直接调用setName()方法,你只有将它转换为User类型的对象才能使用user对象中的setName()方法,我问的就是这个传进来的user对象是怎么转换为其真正的对象的?
追答save方法里面的object可以是任意对象,比如什么User,你在实例化的时候(User user = new User();)的时候就已经指明了user是User对象啊。。你是不是纠结错东西了。
PS:有些东西想想挺好,纠结多了就不好了。有时候用着用着就知道是怎么回事了。
这里说不清,咱们去QQ上探讨,我的QQ:825338623
参考技术A 你要有类才能去存类User user,这个User类创建的时候,就需要注入hibernate的注解了
先是通过User这个类和数据库那张user表相连
所以你save一个user的时候,他是先找User这个类,然后通过这个类,通过这个类找到那张表,然后才存过数据库追问
问题太多,我给您以图片的形式发出来:

http://blog.csdn.net/liushuijinger/article/details/19439373

所以你save一个user的时候,他是先找User这个类
请您详细解释一下它是如何找到它原本所属的类的
源码已看,由于session就是一个接口,其中的save方法就是一个接口的方法,并没有实际的业务逻辑,我现在要找的是它实际的业务逻辑,如何判断user所属的类型,您说反射,我了解了一些,请您根据我的问题详细说说它的存储的过程,谢谢!
追答根据序列号和实体名称加上实体上的注解去找到传入 的本来类型
追问大神,来个例子???
hibernate一级缓存
对象分为三种状态:瞬时状态、持久化状态、游离状态.其实我们调用session.save或者session.update或者session.saveOrUpdate只是为了将对象的状态改变为持久态(将对象存入session一级缓存)。一级缓存
中的对象就是和session关联,session中有一级缓存区和快照区,执行事务提交的时候会判断快照中对象和缓存中对应的对象是否一致,如果一致不会执行修改SQL、不一致会执行修改SQL。
1.Hibernate一级缓存介绍:

2.一级缓存也是为了提高操作数据库的效率.
1.测试一级缓存的存在
@Test //证明一级缓存存在 public void fun1(){ //1 获得session Session session = HibernateUtil.openSession(); //2 控制事务 Transaction tx = session.beginTransaction(); //3执行操作 Customer c1 = session.get(Customer.class, 1l); Customer c2 = session.get(Customer.class, 1l); Customer c3 = session.get(Customer.class, 1l); Customer c4 = session.get(Customer.class, 1l); Customer c5 = session.get(Customer.class, 1l); System.out.println(c3==c5);//true //4提交事务.关闭资源 tx.commit(); session.close();// 游离|托管 状态, 有id , 没有关联 }
结果:只发出一次SQL请求,而且五个对象的内存地址一样,证明查询了一次SQL,然后后四个对象直接取的session缓存的对象。
由于第一次查询的时候先从session缓存中取,没有取到对应的数据,所以发出SQL从数据库中取出来并且会存到session缓存中; 第二次查询的时候从session缓存中取数据取到所以不发出SQL。
Hibernate: select customer0_.cust_id as cust_id1_0_0_, customer0_.cust_name as cust_nam2_0_0_, customer0_.cust_source as cust_sou3_0_0_, customer0_.cust_industry as cust_ind4_0_0_, customer0_.cust_level as cust_lev5_0_0_, customer0_.cust_linkman as cust_lin6_0_0_, customer0_.cust_phone as cust_pho7_0_0_, customer0_.cust_mobile as cust_mob8_0_0_ from cst_customer customer0_ where customer0_.cust_id=? true
2.一级缓存提高效率的手段:
(1)查询的时候提高查询手段:提高查询效率,原理如下:

(2)减少不必要的修改语句发送
hibernate在查询到的数据的时候会将一份存入缓存,一份存入快照,缓存会和内存中的对象保持一致,最后执行事务提交的时候会对比快照中的对象和session中的对象有没有修改,有修改的话没执行修改SQL,否则不会发出修改SQL。
@Test // public void fun2(){ //1 获得session Session session = HibernateUtil.openSession(); //2 控制事务 Transaction tx = session.beginTransaction(); //3执行操作 Customer c1 = session.get(Customer.class, 1l); c1.setCust_name("哈哈"); c1.setCust_name("测试"); //4提交事务.关闭资源 tx.commit(); session.close();// 游离|托管 状态, 有id , 没有关联 }
结果:
Hibernate: select customer0_.cust_id as cust_id1_0_0_, customer0_.cust_name as cust_nam2_0_0_, customer0_.cust_source as cust_sou3_0_0_, customer0_.cust_industry as cust_ind4_0_0_, customer0_.cust_level as cust_lev5_0_0_, customer0_.cust_linkman as cust_lin6_0_0_, customer0_.cust_phone as cust_pho7_0_0_, customer0_.cust_mobile as cust_mob8_0_0_ from cst_customer customer0_ where customer0_.cust_id=?
解释:原来数据库的Cust_name的值就是测试,所以在两次修改完成之后还是测试,所以只发出查询SQL而未发出修改SQL。Hibernate快照的作用就是确保一级缓存中的数据和数据库中的数据一致。
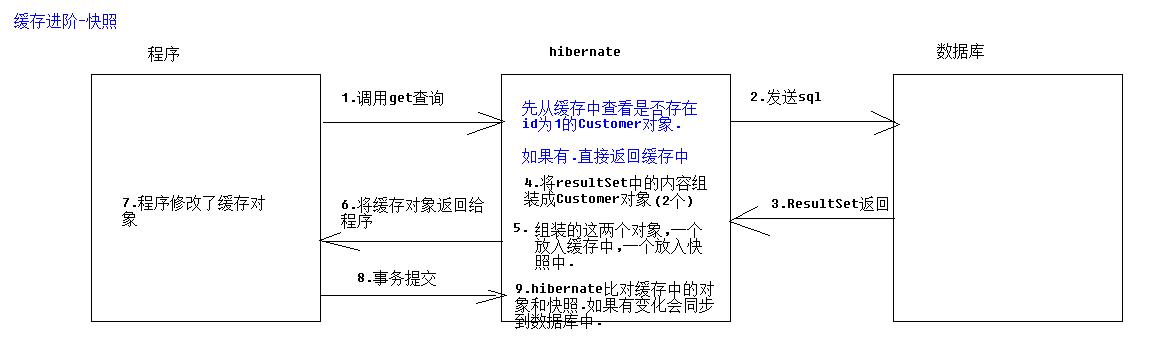
总结:
缓存: 为了提高效率.
一级缓存:为了提高效率.session对象中有一个可以存放对象的集合.
查询时: 第一次查询时.会将对象放入缓存.再次查询时,会返回缓存中的.不再查询数据库.
修改时: 会使用快照对比修改前和后对象的属性区别.只执行一次修改.
以上是关于hibernate中 session.save(实体类)方法的原理的主要内容,如果未能解决你的问题,请参考以下文章