如何使用API 网关做服务编排?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用API 网关做服务编排?相关的知识,希望对你有一定的参考价值。
参考技术A服务编排/数据聚合 指的是可以通过一个请求来依次调用多个微服务,并对每个服务的返回结果做数据处理,最终整合成一个大的结果返回给前端。
例如一个服务是“查询用户预定的酒店”,前端仅需要传一个订单ID,后端会返回整个订单的信息,包括用户信息、酒店信息和房间信息等。
这个服务背后可能对应着以下几个操作:
微服务架构上对功能做了解耦,使用服务编排可以快速从各类服务上获取需要的数据,对业务实现快速响应。总的来说,编排有以下几点优势:
Goku API Gateway (中文名:悟空 API 网关)是一个基于 Golang 开发的微服务网关,能够实现高性能 HTTP API 转发、服务编排、多租户管理、API 访问权限控制等目的,拥有强大的自定义插件系统可以自行扩展,并且提供友好的图形化配置界面,能够快速帮助企业进行 API 服务治理、提高 API 服务的稳定性和安全性。
Goku API Gateway支持一个编排API对应多个后端服务,每个后端服务的请求参数可以使用前端传入的参数,也可以在编排里自定义(写静态参数或从返回数据里获得)。每个后端服务的返回数据支持过滤、删除、移动、重命名、拆包和封包等操作;编排API能够设定编排失败时的异常返回。
Goku API Gateway 的社区版本(CE)同时拥有完善的使用指南和二次开发指南,内置的插件系统也能够让企业针对自身业务进行定制开发。
项目地址: https://github.com/eolinker/goku-api-gateway
官网地址: https://www.eolinker.com
我们将编排的整个操作放到网关进行,由网关对数据做处理与转换,这样无需对后端服务做改动。一个请求到达网关,网关调用多个后端服务,并且在网关上对各个服务的返回数据做处理(操作有过滤、移动、重命名、封包、拆包,后面会对各操作做详细解释),最后由网关将数据整合好返回给前端。
网关将编排过程中对 API的转发处理过程 (转发->获取返回数据->数据处理)称为一个 Step 。
添加一个转发服务,该服务为 查询订单详情API,配置相应的转发地址、传入的参数、对返回数据做何种处理等。
由于篇幅原因,后续的Step(查询用户详情、查询酒店详情、查询房间详情)就不一一展示了。
网关将编排过程中对 API的转发处理过程 (转发->获取返回数据->数据处理)称为一个 Step。
我们将处理查询订单详情API称为 Step1 ,其中Step1的返回数据有:用户ID、酒店ID、房间ID。同理,将查询用户信息这步称为 Step2 ,将查询酒店信息称为 Step3 ,将查询房间信息称为 Step4 。
传参规则:
以下为转发路径的传参写法:
Step2中需要接收Step1里返回的userID作为参数,同时需要接收前端传入的Authorization参数
在网关里Step2的请求参数配置如下所示,请求参数存在多个的话用换行表示:
1.查询订单详情的API,返回数据称为json1,内容如下:
2.查询用户详情的API,返回数据称为json2,内容如下:
3.查询酒店详情的返回数据,称为json3,内容如下:
4.查询房间详情的返回数据,称为json4,内容如下:
5.可以在每一个Step里对返回Json做处理,网关会将处理过的数据最后整合起来,再返回前端,例如这是通过网关返回的最终数据:
这里以查询酒店详情API的返回数据json3为例,讲解网关如何在编排过程中对返回数据做处理。
查询酒店详情API返回的原始数据如下:
从网关返回给前端的数据中截取酒店信息的数据如下:
从原始数据到处理后的数据需要经过以下操作:
字段黑名单的作用是排除某些字段,支持数组形式。
在网关的Step3里配置如下:
经过网关处理后,实际的返回数据如下,可以看到data对象里的id字段已经被过滤掉:
拆包是指将指定对象的内容提取出来作为该步骤(step)的返回结果。其中匹配目标只能为object,匹配目标为空时,结果为 ,可用于清除数据。
在网关的Step里配置如下:
经过网关处理后,实际的返回数据如下,可以看到data对象被拆开,最终数据仅保留了data对象里面的字段:
字段封包会将当前的数据整体打包为最终返回数据中的一个对象,不支持*,不支持数组。
在网关的Step里配置如下:
经过网关处理后,实际的返回数据如下,数据被整体打包为hotelinfo对象:
经过三个步骤,就可以将原始数据变成最终的数据。
本文仅列举了编排过程中部分数据处理的操作,如需了解更多编排细则,可通过文末给出的教程链接。
相关链接
如何设计一个亿级API网关?
API 网关可以看做系统与外界联通的入口,我们可以在网关处理一些非业务逻辑的逻辑,比如权限验证,监控,缓存,请求路由等等。
为什么需要 API 网关
为什么需要 API 网关?有如下几点原因:
RPC 协议转成 HTTP。由于在内部开发中我们都是以 RPC 协议(thrift or dubbo)去做开发,暴露给内部服务,当外部服务需要使用这个接口的时候往往需要将 RPC 协议转换成 HTTP 协议。
请求路由。在我们的系统中由于同一个接口新老两套系统都在使用,我们需要根据请求上下文将请求路由到对应的接口。
统一鉴权。因为鉴权操作不涉及到业务逻辑,那么可以在网关层进行处理,不用下层到业务逻辑。
统一监控。由于网关是外部服务的入口,所以我们可以在这里监控我们想要的数据,比如入参出参,链路时间。
流量控制,熔断降级。对于流量控制,熔断降级非业务逻辑可以统一放到网关层。
有很多业务都会自己去实现一层网关层,用来接入自己的服务,但是对于整个公司来说这还不够。
统一 API 网关
统一的 API 网关不仅有 API 网关的所有的特点,还有下面几个好处:
统一技术组件升级。在公司中如果有某个技术组件需要升级,那么是需要和每个业务线沟通,通常几个月都搞不定。
举个例子如果对于入口的安全鉴权有重大安全隐患需要升级,如果速度还是这么慢肯定是不行,那么有了统一的网关升级是很快的。
统一服务接入。对于某个服务的接入也比较困难,比如公司已经研发出了比较稳定的服务组件,正在公司大力推广,这个周期肯定也特别漫长,由于有了统一网关,那么只需要统一网关统一接入。
节约资源。不同业务不同部门如果按照我们上面的做法应该会都自己搞一个网关层,用来做这个事,可以想象如果一个公司有 100 个这种业务,每个业务配备 4 台机器,那么就需要 400 台机器。
并且每个业务的开发 RD 都需要去开发这个网关层,随时去维护,增加人力。如果有了统一网关层,那么也许只需要 50 台机器就可以做这 100 个业务的网关层的事,并且业务 RD 不需要随时关注开发,上线的步骤。
统一网关的设计
异步化请求
对于我们自己实现的网关层,由于只有我们自己使用,对于吞吐量的要求并不高,所以我们一般同步请求调用即可。
对于我们统一的网关层,如何用少量的机器接入更多的服务,这就需要我们的异步,用来提高更多的吞吐量。
对于异步化一般有下面两种策略:
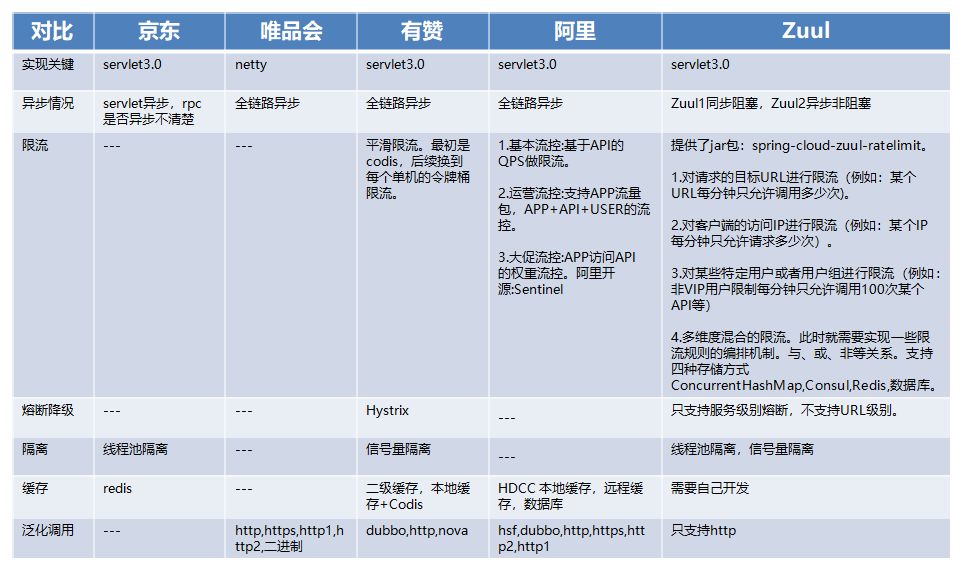
Tomcat/Jetty+NIO+servlet3。这种策略使用的比较普遍,京东,有赞,Zuul,都选取的是这个策略,这种策略比较适合 HTTP。在 Servlet3 中可以开启异步。
Netty+NIO。Netty 为高并发而生,目前唯品会的网关使用这个策略,在唯品会的技术文章中在相同的情况下 Netty 是每秒 30w+ 的吞吐量,Tomcat 是 13w+。
可以看出它们是有一定的差距的,但是 Netty 需要自己处理 HTTP 协议,这一块比较麻烦。
对于网关是 HTTP 请求场景比较多的情况可以采用 Servlet,毕竟可以更加成熟的处理 HTTP 协议。如果更加重视吞吐量那么可以采用 Netty。
全链路异步
对于来的请求我们已经使用异步了,为了达到全链路异步我们需要对去的请求也进行异步处理。对于去的请求我们可以利用 RPC 的异步支持进行异步请求。
所以基本可以达到下图:
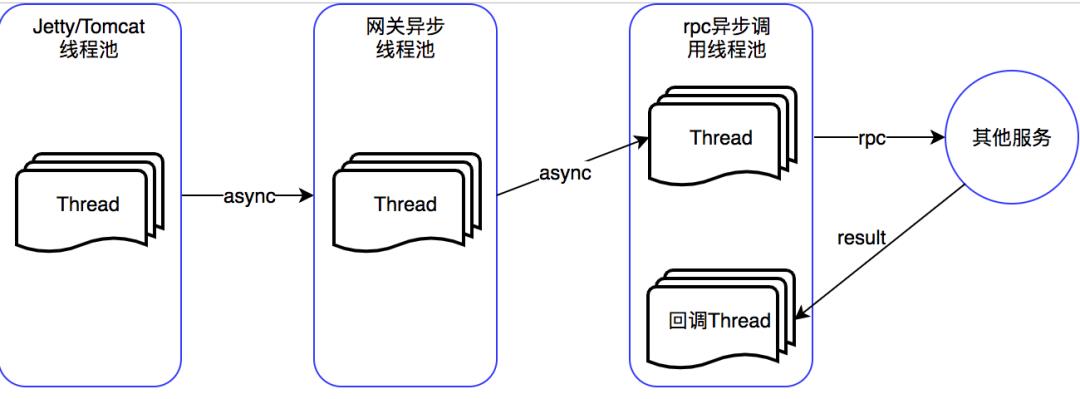
先在 Web 容器中开启 Servlet 异步,然后进入到网关的业务线程池中进行业务处理,然后进行 RPC 的异步调用并注册需要回调的业务,最后在回调线程池中进行回调处理。
链式处理
在设计模式中有一个模式叫责任链模式,它的作用是避免请求发送者与接收者耦合在一起,让多个对象都有可能接收请求,将这些对象连接成一条链,并且沿着这条链传递请求,直到有对象处理它为止。
通过这种模式将请求的发送者和请求的处理者解耦了。在我们的各个框架中对此模式都有实现,比如 Servlet 里面的 Filter,SpringMVC 里面的 Interceptor。
在 Netflix Zuul 中也应用了这种模式,如下图所示:
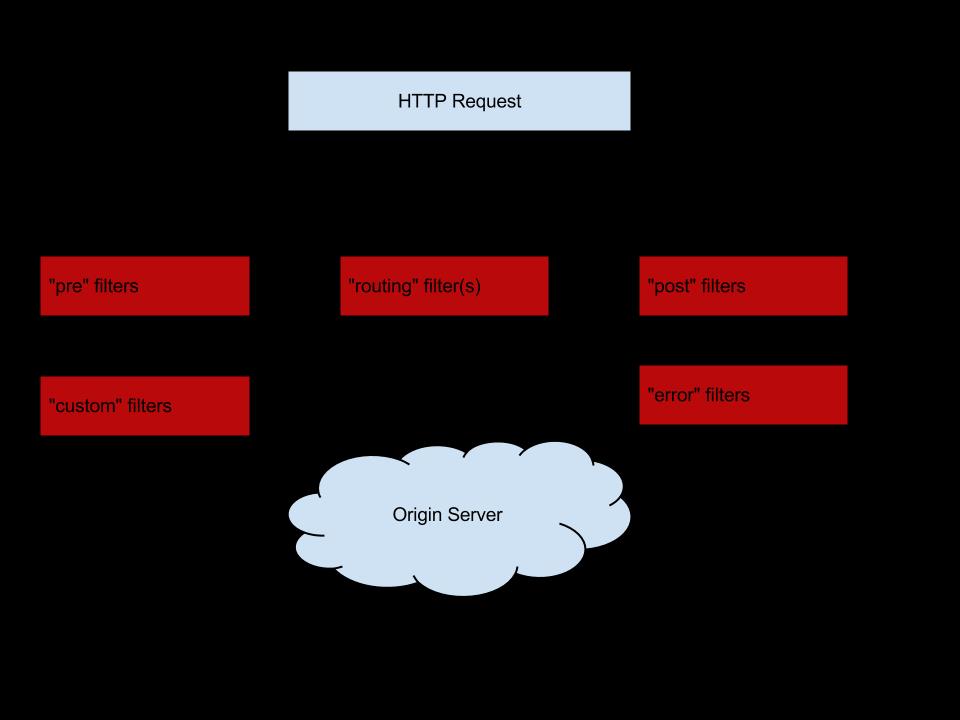
这种模式在网关的设计中我们可以借鉴到自己的网关设计:
preFilters:前置过滤器,用来处理一些公共的业务,比如统一鉴权,统一限流,熔断降级,缓存处理等,并且提供业务方扩展。
routingFilters:用来处理一些泛化调用,主要是做协议的转换,请求的路由工作。
postFilters:后置过滤器,主要用来做结果的处理,日志打点,记录时间等等。
errorFilters:错误过滤器,用来处理调用异常的情况。
这种设计在有赞的网关也有应用。
业务隔离
上面在全链路异步的情况下不同业务之间的影响很小,但是如果在提供的自定义 Filter 中进行了某些同步调用,一旦超时频繁那么就会对其他业务产生影响。所以我们需要采用隔离之术,降低业务之间的互相影响。
信号量隔离
信号量隔离只是限制了总的并发数,服务还是主线程进行同步调用。这个隔离如果远程调用超时依然会影响主线程,从而会影响其他业务。
因此,如果只是想限制某个服务的总并发调用量或者调用的服务不涉及远程调用的话,可以使用轻量级的信号量来实现。有赞的网关由于没有自定义 Filter,所以选取的是信号量隔离。
线程池隔离
最简单的就是不同业务之间通过不同的线程池进行隔离,就算业务接口出现了问题由于线程池已经进行了隔离,那么也不会影响其他业务。
在京东的网关实现之中就是采用的线程池隔离,比较重要的业务比如商品或者订单,都是单独的通过线程池去处理。
但是由于是统一网关平台,如果业务线众多,大家都觉得自己的业务比较重要,则需要单独的线程池隔离。
如果使用的是 Java 语言开发的话,那么在 Java 中线程是比较重的资源,比较受限,如果需要隔离的线程池过多不是很适用。
如果使用一些其他语言比如 Golang 进行开发网关的话,线程是比较轻的资源,所以比较适合使用线程池隔离。
集群隔离
如果有某些业务就需要使用隔离但是统一网关又没有线程池隔离,那么应该怎么办呢?
那么可以使用集群隔离,如果你的某些业务真的很重要那么可以为这一系列业务单独申请一个集群或者多个集群,通过机器之间进行隔离。
请求限流
流量控制可以采用很多开源的实现,比如阿里最近开源的 Sentinel 和比较成熟的 Hystrix。
一般限流分为集群限流和单机限流:
集群限流:利用统一存储保存当前流量的情况,一般可以采用 Redis,这个一般会有一些性能损耗。
单机限流:限流每台机器我们可以直接利用 Guava 的令牌桶去做,由于没有远程调用性能消耗较小。
熔断降级
这一块也可以参照开源的实现 Sentinel 和 Hystrix,这里不是重点就不多提了。
泛化调用
泛化调用指的是一些通信协议的转换,比如将 HTTP 转换成 Thrift。在一些开源的网关中比如 Zuul 是没有实现的,因为各个公司的内部服务通信协议都不同。
比如在唯品会中支持 HTTP1、HTTP2、以及二进制的协议,然后转化成内部的协议。
淘宝的支持 HTTPS、HTTP1、HTTP2 这些协议都可以转换成 HTTP、HSF、Dubbo 等协议。
如何去实现泛化调用呢?由于协议很难自动转换,那么其实每个协议对应的接口需要提供一种映射。
简单来说就是把两个协议都能转换成共同语言,从而互相转换,如下图:
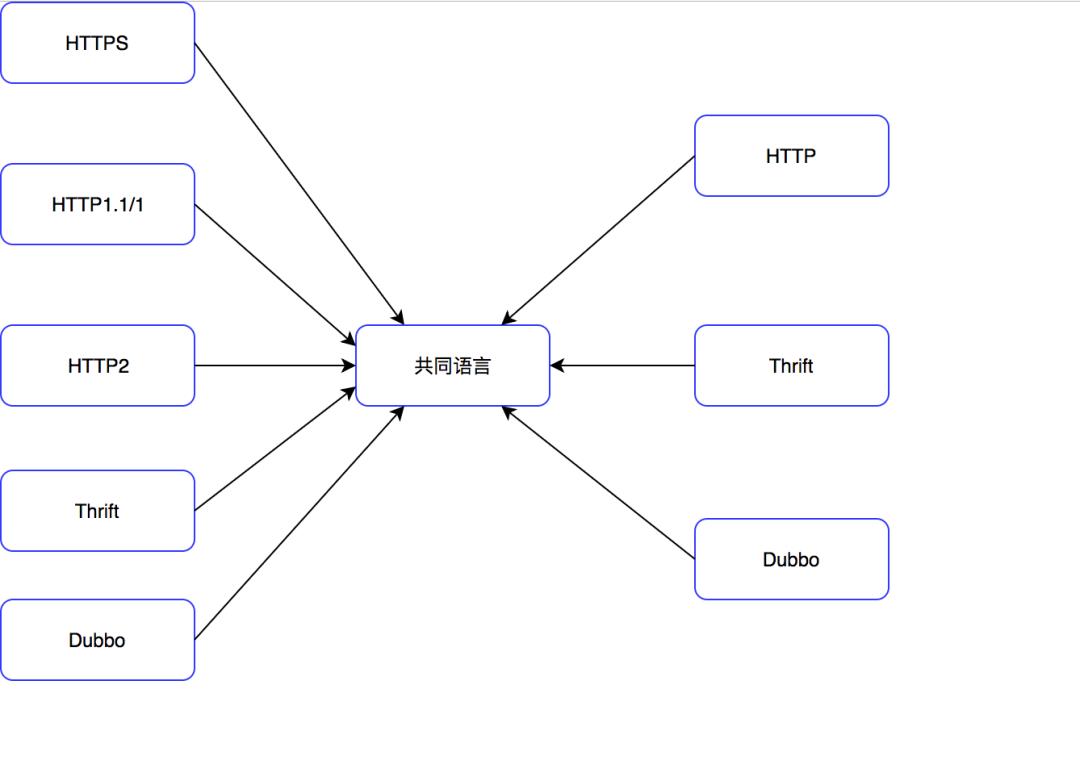
一般来说共同语言有三种方式指定:
json:json 数据格式比较简单,解析速度快,较轻量级。在 Dubbo 的生态中有一个 HTTP 转 Dubbo 的项目是用 JsonRpc 做的,将 HTTP 转化成 JsonRpc 再转化成 Dubbo。
比如可以将一个 www.baidu.com/id = 1 GET 映射为 json:

xml:xml 数据比较重,解析比较困难,这里不过多讨论。
自定义描述语言:一般来说这个成本比较高,需要自己定义语言来进行描述并进行解析,但是其扩展性,自定义个性化性都是最高。例:Spring 自定义了一套自己的 SPEL 表达式语言。
对于泛化调用如果要自己设计的话 json 基本可以满足,如果对于个性化的需要特别多的话倒是可以自己定义一套语言。
管理平台
上面介绍的都是如何实现一个网关的技术关键。这里需要介绍网关的一个业务关键。
有了网关之后,需要一个管理平台去对我们上面所描述的技术关键进行配置,包括但不限于下面这些配置:
限流
熔断
缓存
日志
自定义 Filter
泛化调用
总结
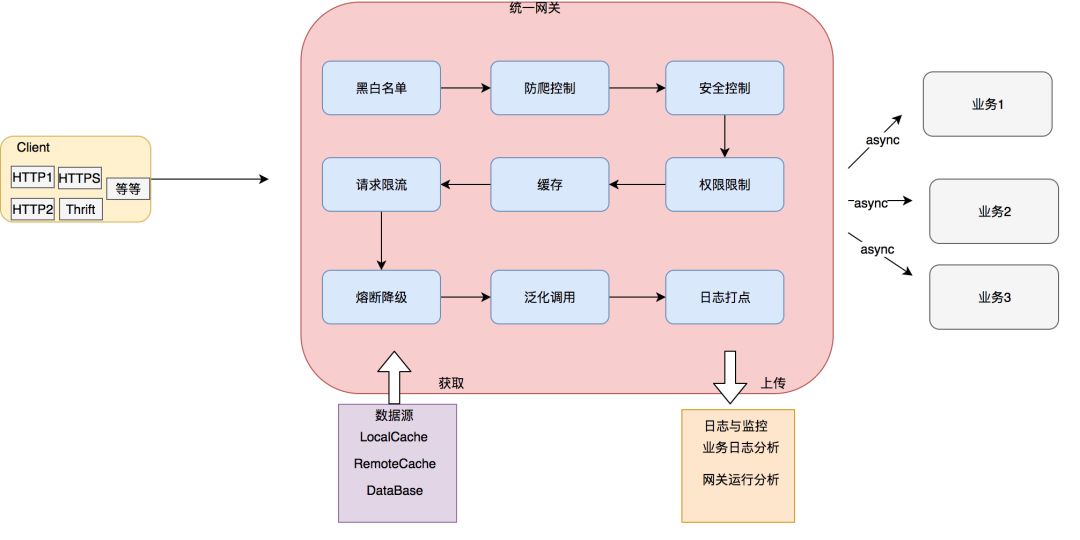
最后一个合理的标准网关应该按照如下去实现:
参考资料:
京东:http://www.yunweipai.com/archives/23653.html
有赞网关:https://tech.youzan.com/api-gateway-in-practice/
唯品会:https://mp.weixin.qq.com/s/gREMe-G7nqNJJLzbZ3ed3A
Zuul:http://www.scienjus.com/api-gateway-and-netflix-zuul/
编辑:陶家龙、孙淑娟

精彩文章推荐:
以上是关于如何使用API 网关做服务编排?的主要内容,如果未能解决你的问题,请参考以下文章
来自京东唯品会对微服务编排API网关持续集成的实践分享(下)
来自京东唯品会对微服务编排API网关持续集成的实践分享(上)