Python- discover()方法与执行顺序补充
Posted konglingbin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python- discover()方法与执行顺序补充相关的知识,希望对你有一定的参考价值。
可以根据不同的功能创建不同的测试文件,甚至是不同的测试目录,测试文件中还可以将不同的小功能划分为不同的测试类,在类下编写测试用例,让整体结构更加清晰
但通过addTest()添加、删除测试用例就变得非常麻烦
TestLoader 类中提供的discover()方法可以自动识别测试用例
discover(start_dir,pattern=\'test*.py\',top_level_dir= None)
找到指定目录下所有测试模块,并可递归查到子目录下的测试模块,只有匹配到文件名时才加载
start_dir:要测试的模块名或测试用例目录
pattern=\'test*.py\':表示用例文件名的匹配原则。此处匹配以“test”开头的.py 类型的文件,* 表示任意多个字符
top_level_dir= None 测试模块的顶层目录,如果没有顶层目录,默认为None
实例1:
import unittest
test_dir = \'./\'
#定义测试目录为当前目录
discover = unittest.defaultTestLoader.discover(test_dir,pattern=\'test*.py\')
if __name__ == \'__main__\':
runner = unittest.TextTestRunner()
runner.run(discover)
discover()方法会自动根据测试目录test_dir 匹配查找测试用例文件,并将查找到的测试用例组装到测试套件中,因此,可以直接通过
run()方法执行discover,大大简化了测试用例的查找与执行
实例2:
suite = unittest.TestSuite()
all_cases = unittest.defaultTestLoader.discover(PY_PATH,\'Test*.py\')
#discover()方法会自动根据测试目录匹配查找测试用例文件(Test*.py),并将查找到的测试用例组装到测试套件中
[suite.addTests(case) for case in all_cases]
report_html = BeautifulReport.BeautifulReport(suite)
二、用例执行的顺序
unittest 框架默认根据ASCII码的顺序加载测试用例,数字与字母的顺序为:0~9,A~Z,a~z
如果要让某个测试用例先执行,不能使用默认的main()方法,需要通过TestSuite类的addTest()方法按照一定的顺序来加载
discover(start_dir,pattern=\'test*.py\',top_level_dir=None)
找到指定目录下所有测试模块,并可递归查到子目录下的测试木块,只有匹配到的文件名才会被加载。如果启动的不是顶层目录,那么顶层目录必然单独指定。
- start_dir:要测试的模块名或测试用例的目录。
- pattent=‘test*.py’:表示用例文件名的匹配原则。此处匹配文件名一test开头的所有.py类型文件,*表示任意多个字符。
- top_level_dir=None :测试模块的顶层目录,如果没有顶层目录,默认为None。

import unittest
import json
import requests
from HTMLTestRunner import HTMLTestRunner
import time
#定义测试用例的目录为当前目录
test_dir = \'./\'
discover = unittest.defaultTestLoader.discover(test_dir,pattern = \'test*.py\')
if __name__=="__main__":
#按照一定的格式获取当前的时间
now = time.strftime("%Y-%m-%d %H-%M-%S")
#定义报告存放路径
filename = \'./\' + now + \'test_result.html\'
fp = open(filename,"wb")
#定义测试报告
runner = HTMLTestRunner(stream = fp,
title = "xxx接口测试报告",
description = "测试用例执行情况:")
#运行测试
runner.run(discover)
fp.close() #关闭报告文件
下面直接举例说明discover用法:
一、 准备工作
目录结构:
DiscoverCase.py 文件代码:
import unittest
import os
def discover_case(case_dir):
# 待执行用例的目录
testcase = unittest.TestSuite()
discover = unittest.defaultTestLoader.discover(case_dir,pattern="*.py",top_level_dir=None)
# discover方法筛选出来的用例,循环添加到测试套件中
print(discover)
for test_suite in discover:
for test_case in test_suite:
print(test_case)
# 添加用例到testcase
#testcase.addTests(test_case)
testcase.addTests(test_case)
return(testcase)
path = os.path.join(os.getcwd(), "测试用例")
case = discover_case(case_dir=path)
print(case)
Test1代码(test2~4代码基本相同):
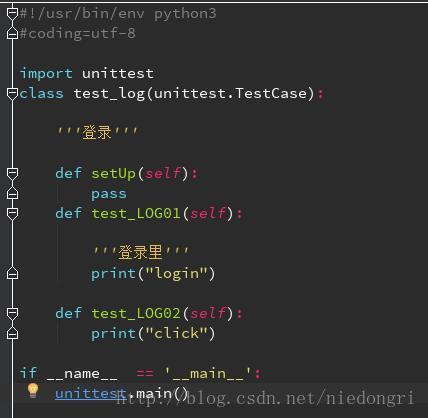
注意:每个testcase里面的执行用例(即以test开头的函数)必现大于或等于两个,不然会报错。
二、写好这些后我们就直接跑程序看结果
运行后用例的文件名、类名、函数名都会遍历出来

注意:如果用例名称全为中文是不可以加载的到的,必须以字母开始,比如“i登录.py”
以上是关于Python- discover()方法与执行顺序补充的主要内容,如果未能解决你的问题,请参考以下文章
利用Python的unittest单元测试框架的discover方法批量执行脚本用例
摆脱京城贵妇unittest的骚套路discover,自定义用例执行顺序。
python接口自动化(二十六)--批量执行用例 discover(详解)