双目立体匹配GANet阅读笔记
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了双目立体匹配GANet阅读笔记相关的知识,希望对你有一定的参考价值。
参考技术A 双目立体匹配解决问题为在极线上查找同一物理点在左右相机图像的对应投影位置,从而得到视差图,用于双目系统的物体深度估计。其核心思想是计算两个像素的相似度度量,选择最佳匹配点。基本步骤为预处理,代价计算,代价聚合,视差计算,视差优化,后处理6个步骤。随着大量合成数据集出现,基于深度学习的算法性能已经显著超过非深度学习算法。GANet将人工设计的算法转换为,基于数据的函数逼近学习过程,性能在KITTI 立体匹配竞赛中名列前茅。本文主要介绍GANet涉及算法,包含经典非深度学习算法(代价滤波、SGBM),首个端到端网络GCNet 和GANet原理;最后对比室外场景下性能效果。基于单像素相似度度量的方式,视差结果存在较大噪声。基于滤波的代价聚合方法,能有效降噪;使用原图的引导滤波器[1]方式或者十字交叉臂[2]的自适应形状的代价聚合方式,可实现快速降噪同时保持边缘特性。
SGBM是opencv实现经典立体匹配算法之一,代价聚合融合局部均值滤波和SGM聚合两种方式,整体流程图见图1。
1)代价计算
分别计算水平梯度方向图像和原始图像的BT代价(考虑采样影响的亮度差值),两者简单相加求和得到初始代价值。
2)代价聚合
代价聚合包含局部均值滤波和SGM聚合。局部均值滤波使用固定窗口大小的均值滤波聚合代价。SGM聚合[4]是经典算法,核心思想是多路径代价聚合,每条路径上计算本身代价项和惩罚项。
SGM全局能量函数定义为:
为视差图,大小为HxW, 每个像素取值最大为 .给定视差 , 为像素p处本身代价值,第二项为邻域像素视差差值为1的惩罚项,控制平滑性,第三项为邻域像素视差差值较大的惩罚项,控制图像边缘位置不连续性。 共有 可能性,直接优化困难。
SGM将其转换为16个方向1D路径代价求和方式来近似加速计算,时间复杂度
单个路径方向r上代价计算为,其中第一项为本身代价值,第二项为惩罚项,第三项为防止累积造成数值过大。
多条路径代价求和得到最终聚合代价值
对于每个方向的每个像素计算Dmax次,中间项 可以预先计算,时间复杂度为O(Dmax)。
3)视差计算
每个像素位置采用WTA(赢家通吃)的策略,选择代价最小的视差值
4)后处理
使用显著性一致校验检测异常点,亚像素级增强使得离散视差值连续化,获取更高精度的视差,最后使用左右一致性检测异常点。
基于深度学习强大的特征提取能力,深度卷积网络特征逐渐被用于匹配代价计算。随着大量合成视差估计数据集的出现,DispNet[5]成为首个实现端到端可学习的视差估计网络。该网络借鉴了光流估计FlowNet思想,本质上两者处理问题一致,均解决输入同一场景两幅图像,输出每个像素偏移量的问题。GC-Net[6]提出4D代价空间和3D卷积做代价聚合,真正实现视差估计全流程参数化学习过程。
整体计算过程为:
(1)左右相机图像使用深度卷积网络提取特征图 ;
(2)拼接每个像素位置对应视差水平的特征,得到4D代价空间,维度为 ;
(3)在高度、宽度和视差3个维度做3D卷积,代价聚合;
(4)使用soft argmin回归视差,训练损失函数为smooth L1。
相对直接度量特征距离的方式,GCNet巧妙使用组合4D代价空间和3D卷积代价聚合,通过可学习权重得到更多代价聚合方式。如果直接计算c维特征的距离度量,得到 维的代价空间,这种方式只能衡量特征的相对大小,限制代价计算方式多种可能性。GCNet中每组3D滤波器,计算每一个特征线性加权代价,并融合空间域和视差域的代价,最后所有特征对应代价求和得到聚合代价值。公式如下:
传统立体匹配算法通常选择代价最小的视差,即argmin操作。这种操作得到离散精度视差,视差精度低,同时操作不可微,不能使用BP算法训练。GCNet提出soft argmin方式回归视差,即计算代价归一化概率加权的视差值,因为视差和代价成反比,所以有负号。
视差回归属于稠密像素级预测任务,而高分辨率特征图对稠密任务性能起到至关重要的作用。GCNet采用encoder-decoder方式做代价聚合;PSMNet[7]使用stacked hourglass 提取特征,进一步使用类似stacked hourglass方式堆叠更多3D滤波器做代价聚合,提升匹配效果。GANet[8]提出guided SGA和LGA层进行代价聚合操作,提升立体匹配的性能同时也降低计算量。
整体结构见图2:左右图像首先经过特征提取器提取特征,组合4D代价空间,然后使用3D卷积和guided sga做代价聚合,最后回归像素点的视差值。
1)SGA
相比传统SGM算法,SGA层使用归一化权重加权和计算单一路径代价,权重由图像几何纹理特征控制。公式如下:
最后在4个方向上取最大的代价输出
相对于SGM中使用固定惩罚项的方式,SGA层学习可变权重,而且权重由图像空间纹理和上下文信息引导学习,使得不同区域(平坦、边缘)具有不同的权重值。
3D卷积代价聚合方式,可以被堆叠多次,扩大聚合像素范围,每个像素位置计算复杂度为 ;SGA层每次计算均聚合整行或者整列像素的代价,计算复杂度为 。所以说SGA层代价聚合效果优于3D卷积,同时计算复杂度低;代价是需要更多的参数量,每个像素位置均需要存储一组加权参数。
2)LGA层
LGA层使用归一化权重加权代价和,聚合代价。公式如下
乍看很像归一化权重的3D卷积操作,不同点是3D卷积在空间和视差水平上权重共享,而lga层权重不共享,每个像素位置,视差水平都有一组权重。这种操作更类似快速边缘保持滤波器guided filter, 文章后续试验表明添加lga层在物体边缘位置效果更好。
测试对比sgbm和ganet在室外场景图像效果。sgbm算法在不同场景下有一定的偏差,但效果整体比较稳定;GANet在大部分区域匹配非常精确, 在无纹理区域(地面、天空)更加平滑,物体边缘效果精确,但是在近距离的重复区域仍存在较大偏差。这主要是GANet特征提取器采用多次下采样,再上采样恢复高分辨率特征导致。HRNet[9]使用多分辨率子网并行计算,多尺度融合的方式获取高分率特征。在人体姿态估计、像素级分类等任务中,都被证明有效。试验HRNet做特征提取器,近距离的重复区域的立体匹配效果会更加精确。
随着大量标注数据集出现,基于深度学习的立体匹配算法在特定场景下的效果显著优于非深度学习算法。GANet将经典SGM算法参数化表示,基于数据学习参数;同时摒弃深度卷积网络权值共享的机制,添加基于图像纹理控制的权重操作层,在立体匹配数据集取得优异性能。这种结合领域知识设计的网络架构是无法通过最近盛行的网络架构搜索得到的。
1. C. Rhemann, A. Hosni, M. Bleyer,等. Fast cost-volume filtering for visual correspondence and beyond[J].
2. Xing Mei, Xun Sun, Mingcai Zhou,等. On Building an Accurate Stereo Matching System on Graphics Hardware[C]// IEEE International Conference on Computer Vision Workshops, ICCV 2011 Workshops, Barcelona, Spain, November 6-13, 2011. IEEE, 2011.
3. https://www.jianshu.com/p/07b499ae5c7d
4. Heiko Hirschmüller. Stereo Processing by Semi-Global Matching and Mutual Information[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2007, 30(2):328-341.
5. Mayer N , Ilg E , Husser P , et al. A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation[J]. 2015.
6.Kendall A , Martirosyan H , Dasgupta S , et al. End-to-End Learning of Geometry and Context for Deep Stereo Regression[J]. 2017.
7.Chang J R , Chen Y S . Pyramid Stereo Matching Network[J]. 2018.
8.Zhang F , Prisacariu V , Yang R , et al. GA-Net: Guided Aggregation Net for End-to-end Stereo Matching[J]. 2019.
9.Sun K , Xiao B , Liu D , et al. Deep High-Resolution Representation Learning for Human Pose Estimation[J]. 2019.
ORB SLAM2 双目稀疏立体匹配学习
本节学习自6哥的ORBSLAM2解读
这部分主要在frame.cc文件中
对应函数为:
Frame::Frame(const cv::Mat &imLeft, const cv::Mat &imRight, const double &timeStamp, ORBextractor* extractorLeft, ORBextractor* extractorRight, ORBVocabulary* voc, cv::Mat &K, cv::Mat &distCoef, const float &bf, const float &thDepth) :mpORBvocabulary(voc),mpORBextractorLeft(extractorLeft),mpORBextractorRight(extractorRight), mTimeStamp(timeStamp), mK(K.clone()),mDistCoef(distCoef.clone()), mbf(bf), mThDepth(thDepth), mpReferenceKF(static_cast<KeyFrame*>(NULL))
ORBSLAM2对双目帧处理的主要步骤:
- ID自增
- 计算图像金字塔的参数
- 对左右图像提取ORB特征点, 使用双线程进行提取
- 用opencv的矫正函数,内参对提取到的特征点进行矫正
- 计算双目见特征点的匹配,只有匹配成功的特征点才会计算深度,深度存放在mvDepth中;
- 计算去畸变后边界
具体步骤
- ID自增
mnId=nNextId++;
- 计算图像金字塔的参数
mnScaleLevels = mpORBextractorLeft->GetLevels();
mfScaleFactor = mpORBextractorLeft->GetScaleFactor();
mfLogScaleFactor = log(mfScaleFactor);
mvScaleFactors = mpORBextractorLeft->GetScaleFactors();
mvInvScaleFactors = mpORBextractorLeft->GetInverseScaleFactors();
mvLevelSigma2 = mpORBextractorLeft->GetScaleSigmaSquares();
mvInvLevelSigma2 = mpORBextractorLeft->GetInverseScaleSigmaSquares();
- 对左右图像提取ORB特征点, 使用双线程进行提取
thread threadLeft(&Frame::ExtractORB,this,0,imLeft);
thread threadRight(&Frame::ExtractORB,this,1,imRight);
threadLeft.join();
threadRight.join();
- 用opencv的矫正函数,内参对提取到的特征点进行矫正
UndisortKeyPoints();
- 计算双目见特征点的匹配,只有匹配成功的特征点才会计算深度,深度存放在mvDepth中;
ComPuteStereoMatches();
- 计算去畸变后边界
双目特征点匹配
本部分介绍上部分中的第5不
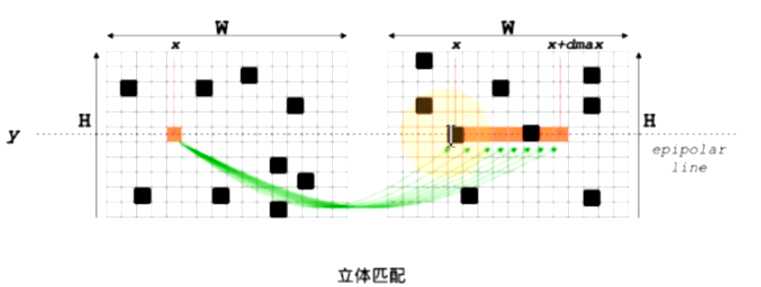
主要对应函数Frame::ComputeStereoMatches()。
输入:两帧立体矫正后的图像对应的ob特征点集
过程
- 行特征点统计
- 粗匹配
- 精确匹配SAD.
- 亚像素精度优化
- 最有视差值/深度选择
- 删除离群点( outliers)
输出:稀疏特征点视差图/深度图和匹配结果
视差公式
z:深度 d:视差(disparity)f:焦距 b:(baseline) 基线
(z=frac{fb}{d},d=u_L-u_R)
亚像素插值
// Sub-pixel match (Parabola fitting)
const float dist1 = vDists[L+bestincR-1];
const float dist2 = vDists[L+bestincR];
const float dist3 = vDists[L+bestincR+1];
const float deltaR = (dist1-dist3)/(2.0f*(dist1+dist3-2.0f*dist2));
if(deltaR<-1 || deltaR>1)
continue;
亚像素插值方法:

亚像素的误差在一个像素以内,所以修正量大一1时鉴定为误匹配。
- 最优视差值。深度选择
- 删除离群点(Outliers)
// 快匹配相似度阈值判断,快意话sad最小,不代表就是匹配的,比如光照变化,若纹理,无纹理都会造成误匹配
//误匹配判断条件 norm_sad > 1.5*1.4*median
sort(vDistIdx.begin(),vDistIdx.end()); //对dist进行排序
const float median = vDistIdx[vDistIdx.size()/2].first; //根据中值计算阈值
const float thDist = 1.5f*1.4f*median;
for(int i=vDistIdx.size()-1;i>=0;i--)
{
if(vDistIdx[i].first<thDist)
break;
else
{
mvuRight[vDistIdx[i].second]=-1;
mvDepth[vDistIdx[i].second]=-1;
}
}
以上是关于双目立体匹配GANet阅读笔记的主要内容,如果未能解决你的问题,请参考以下文章