Python 爬虫二
Posted Dandy Zhang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 爬虫二相关的知识,希望对你有一定的参考价值。
requests模块
Requests模块
get方法请求
整体演示一下:
import requests
response = requests.get("https://www.baidu.com")
print(type(response))
print(response.status_code)
print(type(response.text))
print(response.text)
print(response.cookies)
print(response.content) # 二进制
print(response.content.decode("utf-8"))
我们可以看出response使用起来确实非常方便,这里有个问题需要注意一下:
很多情况下的网站如果直接response.text会出现乱码的问题,所以这个使用response.content
这样返回的数据格式其实是二进制格式,然后通过decode()转换为utf-8,这样就解决了通过response.text直接返回显示乱码的问题.
请求发出后,Requests 会基于 HTTP 头部对响应的编码作出有根据的推测。当你访问 response.text 之时,Requests 会使用其推测的文本编码。你可以找出 Requests 使用了什么编码,并且能够使用 response.encoding 属性来改变它.如:
import requests response = requests.get( url=\'https://www.autohome.com.cn/news/\' ) response.encoding = response.apparent_encoding # 使用默认的编码原则 print(response.text)
一个简单的get请求的爬虫结果:

如果我们想要在URL查询字符串传递数据,通常我们会通过httpbin.org/get?key=val方式传递。Requests模块允许使用params关键字传递参数,以一个字典来传递这些参数,格式如下:
# 实例方法一 import requests response = requests.get("url?name=dandy&age=18") print(response.text) # 实例方法二 import requests url = \'\' data = { "name":"dandy", "age":18 } response = requests.get(url,params=data) print(response.url) print(response.text)
上述两种的结果是相同的,通过params参数传递一个字典内容,从而直接构造url
注意:第二种方式通过字典的方式的时候,如果字典中的参数为None则不会添加到url上
获取二进制数据
在上面提到了response.content,这样获取的数据是二进制数据,同样的这个方法也可以用于下载图片以及
视频资源
添加headers
和前面我们将urllib模块的时候一样,我们同样可以定制headers的信息,如当我们直接通过requests请求知乎网站的时候,默认是无法访问的。谷歌浏览器里输入chrome://version,就可以看到用户代理,将用户代理添加到头部信息:
也可以随便输入一个网址:
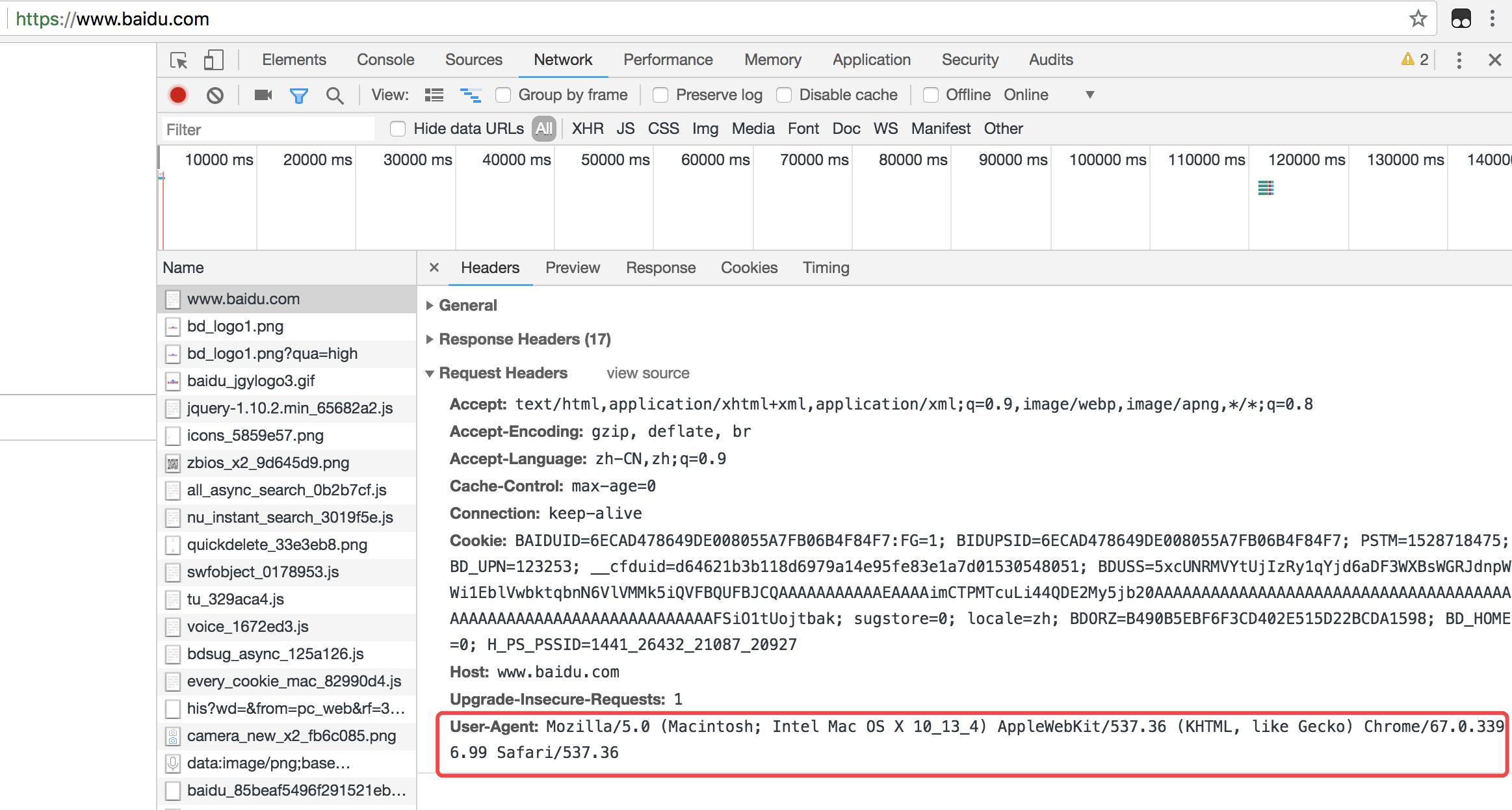
都可以获取到。
copy出来仿造的请求头信息
import requests url = \'\' headers = { "User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36" } response =requests.get(url,headers=headers) print(response.text)
post请求
通过在发送post请求时添加一个data参数,这个data参数可以通过字典构造成,这样
对于发送post请求就非常方便
import requests url = \'\' data = { "name":"dandy", "age":18 } response = requests.post(url,data=data) print(response.text)
同样的在发送post请求的时候也可以和发送get请求一样通过headers参数传递一个字典类型的数据
模拟登陆&自动点赞
首先打开抽屉,点击登陆,打开开发者模式,随意的输入账号密码,然后点击登陆,可以的到如下的图:

备注:之前抽屉是不会去抓去请求头的终端设备信息的,现在有验证了,0.0
首先需要大佬们去注册一下账号密码,然后我们来模拟浏览器登陆,这里需要注意的一点是,登陆的时候可以注意一下,如果浏览器刷新了,那肯定是form验证,如果没有那就一定是ajax验证。所以这里不用说,测试一下就发现是ajax验证:
import requests headers = { "User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36" } # header里伪造终端信息 post_dict = { \'phone\': \'8615988888888\', \'password\': \'*******\', \'oneMonth\': 1 } response = requests.post( url=\'https://dig.chouti.com/login\', data=post_dict, headers=headers ) print(response.content) cookie_dict = response.cookies.get_dict() print(cookie_dict)
这里,既然是ajax登陆,返回的可以猜到一定是json数据:
b\'{"result":{"code":"9999", "message":"", "data":{"complateReg":"0","destJid":"cdu_51970753537"}}}\' {\'gpsd\': \'4fa04e9978e550f8d6ea1fb5418184ee\', \'puid\': \'c3c133fab0b2ba4bcb5e0f9b494501cd\', \'JSESSIONID\': \'aaahPA3kgUc2yhWM_9xsw\'}
到现在为止,已经顺利的实现了登陆功能,然后实现了,大家应该都知道为什么要抓取一下cookies打印出来吧?
cookies的真正的意义就是在于当第一次登陆完,之后就可以直接带着服务器返回的cookies去向服务器发送请求。之后就可以肆意妄为了!!!
现在我们来实现一下自动点赞的功能,首先找一篇文章,点个赞:
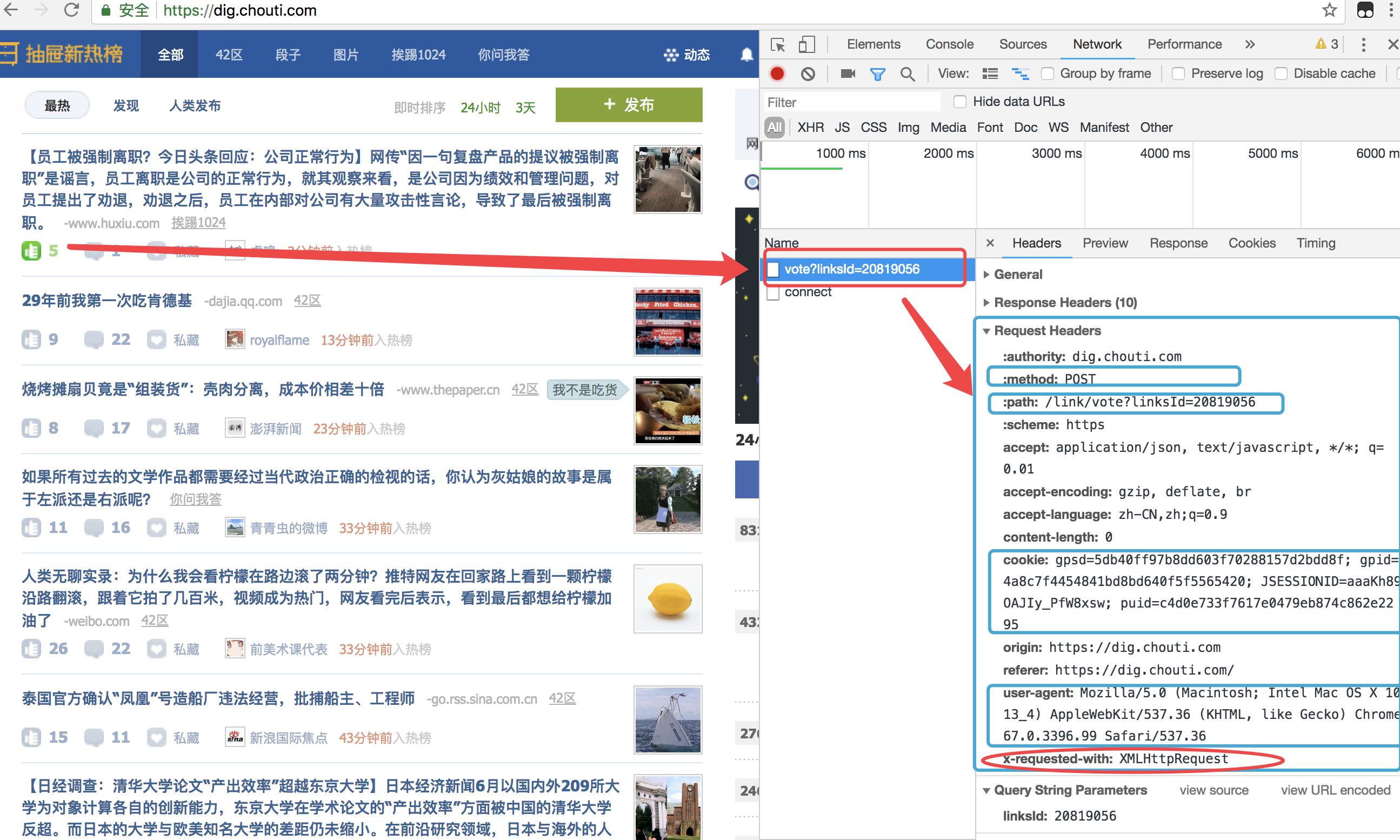
由上,可以发现点赞的网址,post的数据等,此时取消点赞,写代码:
import requests headers = { "User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36" } post_dict = { \'phone\': \'8615962180289\', \'password\': \'zhangy321281\', \'oneMonth\': 1 } response = requests.post( url=\'https://dig.chouti.com/login\', data=post_dict, headers=headers ) print(response.content) cookie_dict = response.cookies.get_dict() print(cookie_dict) response_vote = requests.post( url=\'https://dig.chouti.com/link/vote?linksId=20819056\', cookies=cookie_dict ) print(response_vote)
信心满满写好了:
b\'{"result":{"code":"9999", "message":"", "data":{"complateReg":"0","destJid":"cdu_51970753537"}}}\' {\'gpsd\': \'74338b2cda9e9a355a52854b95474e3a\', \'puid\': \'07fd1754895aefa93b4b46fb52990f7f\', \'JSESSIONID\': \'aaavRXk12M4Kidy5_9xsw\'} <Response [403]>
什么??怎么会这样??拿着浏览器返回的cookie怎么不可以呢?那该怎么办?
管不了那么多,先用笨方法来测试cookies里面哪一个控制这登陆状态认证:
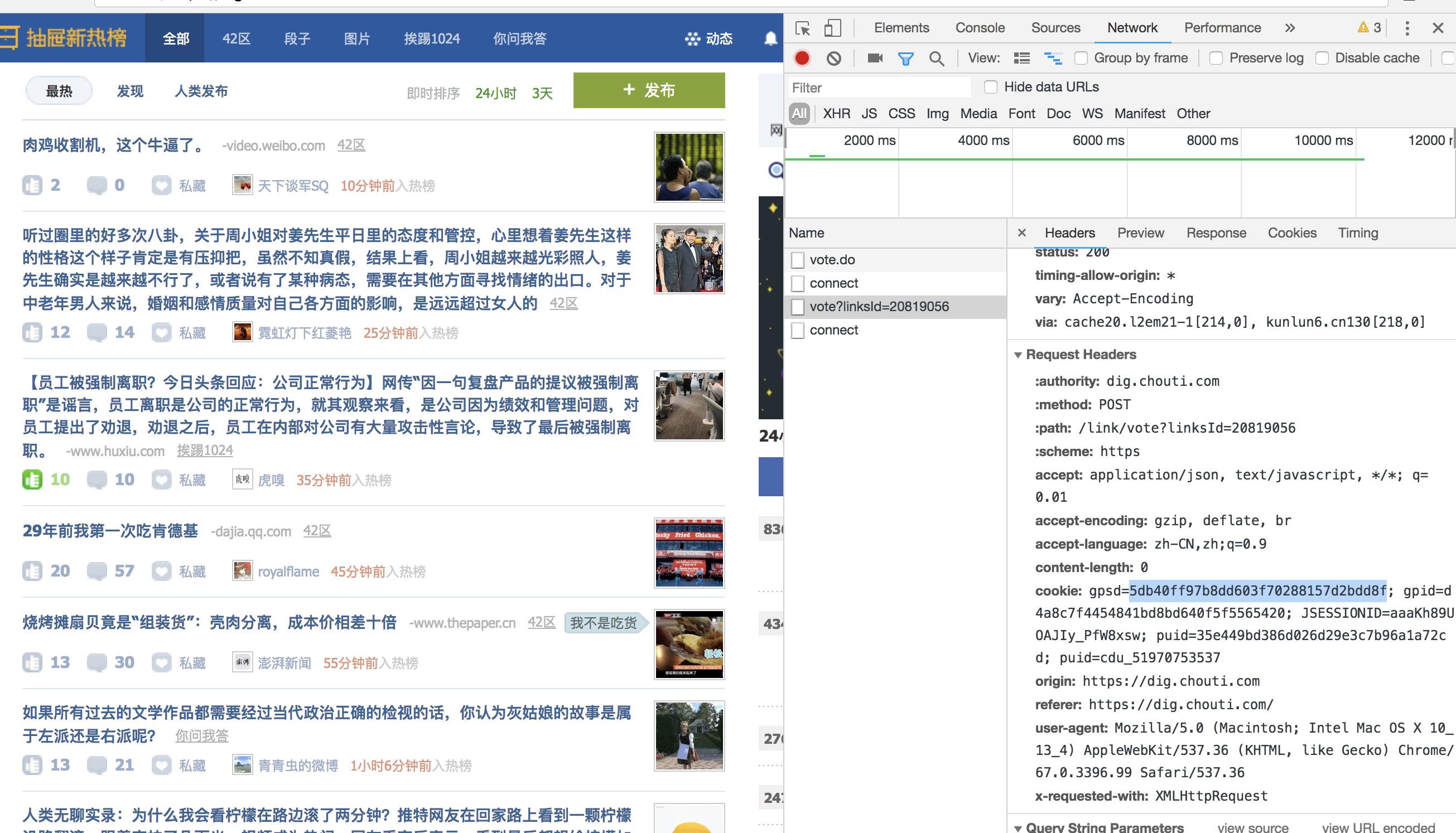
取消点赞,重新测试代码点赞:
import requests headers = { "User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36" } response = requests.post( url=\'https://dig.chouti.com/link/vote?linksId=20819056\', cookies={ \'gpsd\': \'5db40ff97b8dd603f70288157d2bdd8f\' # 因为没办法,所以只能用浏览器的cookies做验证,一次次取一个值 }, headers=headers ) print(response.text)
测试结果:
{"result":{"code":"9999", "message":"推荐成功", "data":{"jid":"cdu_51970753537","likedTime":"1531564084343000","lvCount":"10","nick":"衰Zzz","uvCount":"1","voteTime":"小于1分钟前"}}}
天呐!!!成功了!!!
所以我们可以先跟踪确定了,肯定是gpsd有问题。
这时候退出登陆重新刷新网页:
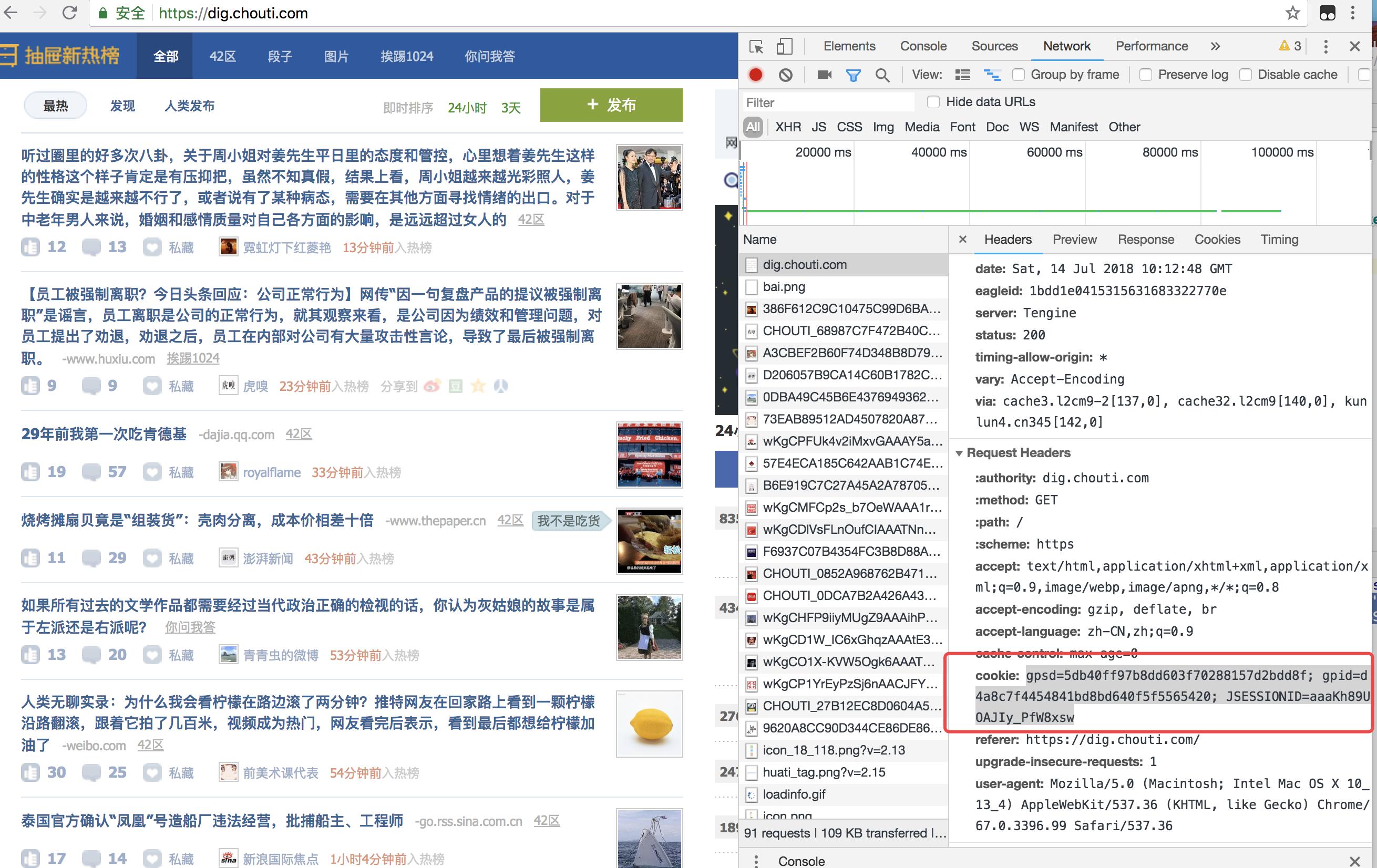
记录一下cookies:
cookie: gpsd=5db40ff97b8dd603f70288157d2bdd8f; gpid=d4a8c7f4454841bd8bd640f5f5565420; JSESSIONID=aaaKh89UOAJIy_PfW8xsw
不免有些疑问,为什么第一次get就有cookies,
此时我们再用代码测试一下gpsd的值:
import requests headers = { "User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36" } response_get = requests.get( url=\'https://dig.chouti.com/\', headers=headers ) print(response_get.cookies.get_dict()) post_dict = { \'phone\': \'8615988888888\', \'password\': \'********\', \'oneMonth\': 1 } response_post = requests.post( url=\'https://dig.chouti.com/login\', data=post_dict, headers=headers ) print(response_post.content) cookie_dict = response_post.cookies.get_dict() print(cookie_dict)
查看cookies对比:
{\'gpsd\': \'38644be424cebb27e1cc631dd84ae9d2\', \'JSESSIONID\': \'aaaKwMAE52emjedIW-xsw\'}
b\'{"result":{"code":"9999", "message":"", "data":{"complateReg":"0","destJid":"cdu_51970753537"}}}\'
{\'gpsd\': \'7b32421f6a73365b2dbb6b9739afaaff\', \'puid\': \'497b5a7249b8538e70ac87ead562c91f\', \'JSESSIONID\': \'aaa5sbGP7XecWf15W8xsw\'}
发现两次的gpsd不一致,从web开发者角度登陆之后的cookies一定是不会再去进行改变,所以前后一共就有这么两种可能性的cookies,上面的点赞失败了,那就代表返回的cookies一定是没有用的:
那是不是可以猜想认证的gpsd会不会是第一次的gpsd值,但是一想又不太可能,因为第一次的还没有认证,怎么能保证呢?那会不会是第一次的gpsd再登陆的时候传过去做了认证,然后浏览器记录了它,但是为了防止爬虫做了一份假的gpsd给你 ,想到这里不免想测试一下:
import requests headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36" } response_get = requests.get( url=\'https://dig.chouti.com/\', headers=headers ) r1 = response_get.cookies.get_dict() # 第一次get请求获取服务器给的cookies post_dict = { \'phone\': \'8615988888888\', \'password\': \'********\', \'oneMonth\': 1, } response_post = requests.post( url=\'https://dig.chouti.com/login\', data=post_dict, headers=headers, cookies=r1 # 第二次再把第一次得到的cookies传回去进行认证授权 ) print(response_post.content) r2 = response_post.cookies.get_dict() # 这个是个骗子!!! response_vote = requests.post( url=\'https://dig.chouti.com/link/vote?linksId=20819056\', cookies={ \'gpsd\': r1[\'gpsd\'] }, headers=headers ) print(response_vote.text)
测试结果:
b\'{"result":{"code":"9999", "message":"", "data":{"complateReg":"0","destJid":"cdu_51970753537"}}}\' {"result":{"code":"9999", "message":"推荐成功", "data":{"jid":"cdu_51970753537","likedTime":"1531565602774000","lvCount":"16","nick":"衰Zzz","uvCount":"1","voteTime":"小于1分钟前"}}}
完成!!
爬虫登陆GitHub实战:https://www.cnblogs.com/wuzdandz/p/9338543.html
请求
前面已经讲过基本的GET请求,下面稍微详谈一下带参数的请求:
import requests # 方法一 response = requests.get(\'http://****.com/?name=dandy&age=18\') print(response.text) # 方法二 import requests data = { "name":"dandy", "age":18 } response = requests.get("http://*****.com",params=data) print(response.url) # 提交url print(response.text)
本质上方法二会被转换成方法一 请求头: content-type:application/url-form-encod...... 请求体: user=dandy&age=18 局限性在于传递的value只能是字符串,数字,列表,不能是字典,
上述两种的结果是相同的,通过params参数传递一个字典内容,从而直接构造url。
注意:第二种方式通过字典的方式的时候,如果字典中的参数为None则不会添加到url上
json
import requests import json url = \'\' response = requests.get(url) print(type(response.text)) print(response.json()) print(json.loads(response.text)) print(type(response.json()))
从结果可以看出requests里面集成的json其实就是执行了json.loads()方法,两者的结果是一样的
data = {\'user\': \'dandy\', \'age\': 18} ==> json数据 "{\'user\': \'dandy\', \'age\': 18}"
请求头:
content-type:application/json....
请求体:
user=dandy&age=18
可以传递字典嵌套的字典
获取二进制数据
在上面提到了response.content,这样获取的数据是二进制数据,同样的这个方法也可以用于下载图片以及
视频资源
添加headers
和前面我们将urllib模块的时候一样,我们同样可以定制headers的信息,如当我们直接通过requests请求知乎网站的时候,默认是无法访问的
之前的实例抽屉自动登陆,就定制了请求头headers
Referer: requests.request( method="POST", url = url1, params={\'k1\': v1, \'k2\': \'v2\'}, json = {\'user\': \'dandy\', \'age\': 18} headers={ "Referer": url/login, # 判断上一次请求的网站是不是也是本网站,不是的话默认为非正常访问 "User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36" } )
cookie
import requests response = requests.get("http://www.baidu.com") print(response.cookies) for k, v in response.cookies.items(): print(k + "=" + v)
Cookie放在请求头里面发送的
POST请求
通过在发送post请求时添加一个data参数,这个data参数可以通过字典构造成,这样
对于发送post请求就非常方便
import requests data = { "name":"dandy", "age":18 } response = requests.post("http://*****.com",data=data) print(response.text)
同样的在发送post请求的时候也可以和发送get请求一样通过headers参数传递一个字典类型的数据
*************************************************************************************
在Django内部,如果是以post传递过去数据data = {\'user\': \'dandy\', \'age\': 18};
请求头:
content-type:application/url-form-encod......
请求体:
user=dandy&age=18
根据请求头的不同决定是否请求体里面的data转换并放到request.POST里面
*************************************************************************************
响应
我们可以通过response获得很多属性,例子如下
import requests response = requests.get("http://www.baidu.com") print(type(response.status_code),response.status_code) print(type(response.headers),response.headers) print(type(response.cookies),response.cookies) print(type(response.url),response.url) print(type(response.history),response.history)
状态码判断
Requests还附带了一个内置的状态码查询对象
主要有如下内容:
100: (\'continue\',),
101: (\'switching_protocols\',),
102: (\'processing\',),
103: (\'checkpoint\',),
122: (\'uri_too_long\', \'request_uri_too_long\'),
200: (\'ok\', \'okay\', \'all_ok\', \'all_okay\', \'all_good\', \'\\o/\', \'✓\'),
201: (\'created\',),
202: (\'accepted\',),
203: (\'non_authoritative_info\', \'non_authoritative_information\'),
204: (\'no_content\',),
205: (\'reset_content\', \'reset\'),
206: (\'partial_content\', \'partial\'),
207: (\'multi_status\', \'multiple_status\', \'multi_stati\', \'multiple_stati\'),
208: (\'already_reported\',),
226: (\'im_used\',),
Redirection.
300: (\'multiple_choices\',),
301: (\'moved_permanently\', \'moved\', \'\\o-\'),
302: (\'found\',),
303: (\'see_other\', \'other\'),
304: (\'not_modified\',),
305: (\'use_proxy\',),
306: (\'switch_proxy\',),
307: (\'temporary_redirect\', \'temporary_moved\', \'temporary\'),
308: (\'permanent_redirect\',
\'resume_incomplete\', \'resume\',), # These 2 to be removed in 3.0
Client Error.
400: (\'bad_request\', \'bad\'),
401: (\'unauthorized\',),
402: (\'payment_required\', \'payment\'),
403: (\'forbidden\',),
404: (\'not_found\', \'-o-\'),
405: (\'method_not_allowed\', \'not_allowed\'),
406: (\'not_acceptable\',),
407: (\'proxy_authentication_required\', \'proxy_auth\', \'proxy_authentication\'),
408: (\'request_timeout\', \'timeout\'),
409: (\'conflict\',),
410: (\'gone\',),
411: (\'length_required\',),
412: (\'precondition_failed\', \'precondition\'),
413: (\'request_entity_too_large\',),
414: (\'request_uri_too_large\',),
415: (\'unsupported_media_type\', \'unsupported_media\', \'media_type\'),
416: (\'requested_range_not_satisfiable\', \'requested_range\', \'range_not_satisfiable\'),
417: (\'expectation_failed\',),
418: (\'im_a_teapot\', \'teapot\', \'i_am_a_teapot\'),
421: (\'misdirected_request\',),
422: (\'unprocessable_entity\', \'unprocessable\'),
423: (\'locked\',),
424: (\'failed_dependency\', \'dependency\'),
425: (\'unordered_collection\', \'unordered\'),
426: (\'upgrade_required\', \'upgrade\'),
428: (\'precondition_required\', \'precondition\'),
429: (\'too_many_requests\', \'too_many\'),
431: (\'header_fields_too_large\', \'fields_too_large\'),
444: (\'no_response\', \'none\'),
449: (\'retry_with\', \'retry\'),
450: (\'blocked_by_windows_parental_controls\', \'parental_controls\'),
451: (\'unavailable_for_legal_reasons\', \'legal_reasons\'),
499: (\'client_closed_request\',),
Server Error.
500: (\'internal_server_error\', \'server_error\', \'/o\\\', \'✗\'),
501: (\'not_implemented\',),
502: (\'bad_gateway\',),
503: (\'service_unavailable\', \'unavailable\'),
504: (\'gateway_timeout\',),
505: (\'http_version_not_supported\', \'http_version\'),
506: (\'variant_also_negotiates\',),
507: (\'insufficient_storage\',),
509: (\'bandwidth_limit_exceeded\', \'bandwidth\'),
510: (\'not_extended\',),
511: (\'network_authentication_required\', \'network_auth\', \'network_authentication\'),
通过下面例子测试:(不过通常还是通过状态码判断更方便)
import requests response= requests.get("http://www.baidu.com") if response.status_code == requests.codes.ok: print("访问成功")
requests高级用法
文件上传
实现方法和其他参数类似,也是构造一个字典然后通过files参数传递
requests.post( url=\'xxx\', files={ \'f1\': open(\'a.csv\', \'rb\'), # 上传文件对象,默认名称为文件名称 \'f2\': (filename, open(\'b.csv\', \'rb\')) # 自定义文件名 } )
证书认证
现在的很多网站都是https的方式访问,所以这个时候就涉及到证书的问题
import requests response = requests.get("https://www.12306.cn") print(response.status_code)
默认的12306网站的证书是不合法的,这样就会提示如下错误
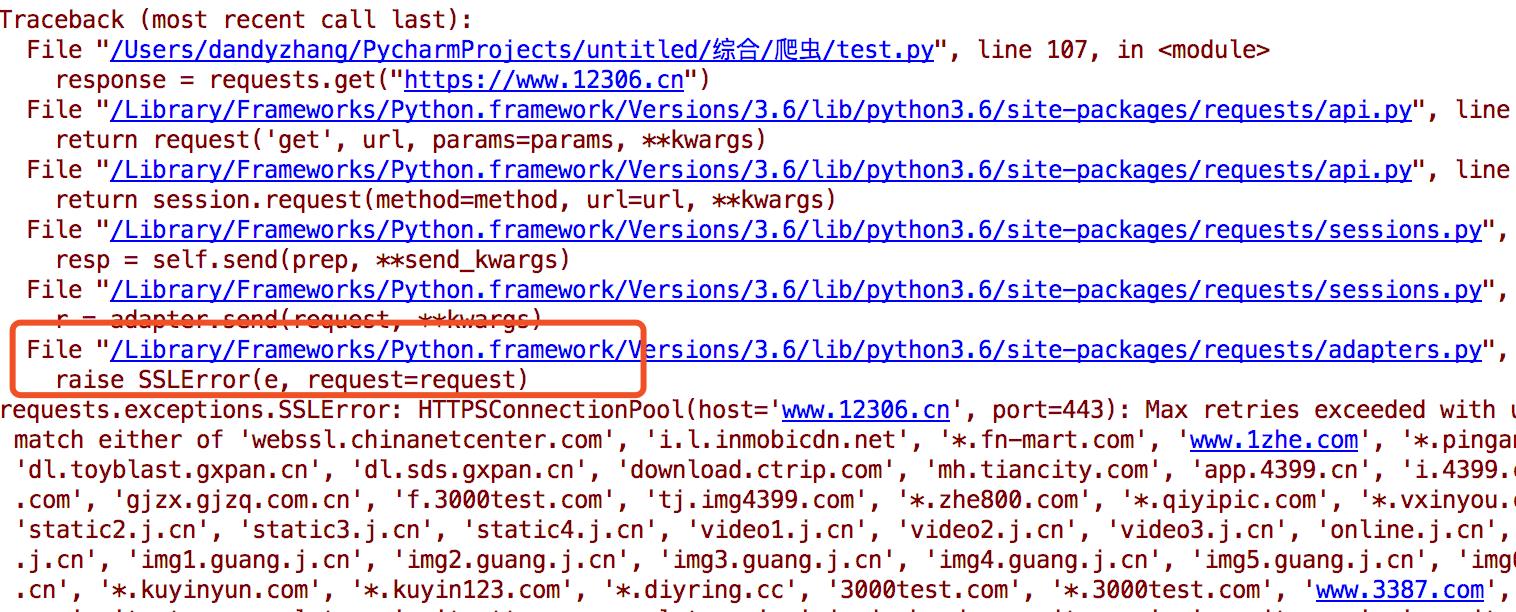
为了避免这种情况的发生可以通过verify=False,这样是可以访问到页面的:
import requests response = requests.get("https://www.12306.cn", verify=False) print(response.status_code)
结果如下:
certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning) 200
解决方法:
import requests import urllib3 urllib3.disable_warnings() response = requests.get("https://www.12306.cn", verify=False) print(response.status_code)
这样就不会提示警告信息,当然也可以通过cert参数放入证书路径
关于证书有两种:
verify:证书 https: ==> ssl加密 requests.get( url=\'https://...\', cert=\'abc.pem\', # 自己制作的证书 pem证书格式 ) requests.get( # 厂商制作好的,在系统创建时就已经植入,直接购买权限 url=\'https://...\', cert=(\'abc.crt\', \'xxx.key\'), ) verify:False 忽略证书,直接交互
代理设置
import requests proxies= { "http":"http://127.0.0.1:9999", "https":"http://127.0.0.1:8888" } response = requests.get("https://www.baidu.com",proxies=proxies) print(response.text)
如果代理需要设置账户名和密码,只需要将字典更改为如下:
proxies = {
"http":"http://user:password@127.0.0.1:9999"
}
如果你的代理是通过sokces这种方式则需要pip install "requests[socks]"
proxies= {
"http":"socks5://127.0.0.1:9999",
"https":"sockes5://127.0.0.1:8888"
}
请求不是发送到目的URL的,而是先发送给代理,代理再去发送请求
超时设置
通过timeout参数可以设置超时的时间,等服务器多长时间放弃
(a,b) ==> a 发送最长时间;b 等待最长时间
认证设置
如果碰到需要认证的网站可以通过requests.auth模块实现
import requests from requests.auth import HTTPBasicAuth response = requests.get("http://120.27.34.24:9001/",auth=HTTPBasicAuth("user","123")) print(response.status_code)
另一种方式:
import requests response = requests.get("http://120.27.34.24:9001/",auth=("user","123")) print(response.status_code)
基本登陆框 md5加密请求头发送过去, 用户名&密码
重定向设置
allow-redirects:是否允许重定向到新的地址拿数据
分流迭代设置
流,如果为false,会一次性下载,如果为true,会一点一点的下载,迭代拿
session设置(持久化)
还记得前面大费周章的去把cookies值装进headers,重新认证么?现在用session来改写一下!!!
import requests session = requests.Session() headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36" } # 1、首先登陆任何页面,获取cookie r1 = session.get( url=\'https://dig.chouti.com/\', headers=headers ) # 2、用户登陆,携带上一次的cookie,后台对cookie中的gpsd进行授权 post_dict = { \'phone\': \'8615988888888\', \'password\': \'zhang1111111\', \'oneMonth\': 1, } r2 = session.post( url=\'https://dig.chouti.com/login\', data=post_dict, headers=headers ) # 点赞 r3 = session.post( url=\'https://dig.chouti.com/link/vote?linksId=20819051\', headers=headers ) print(r3.text)
结果输出:
{"result":{"code":"9999", "message