Airflow使用技巧之-清理元数据库
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Airflow使用技巧之-清理元数据库相关的知识,希望对你有一定的参考价值。
参考技术A 在生产环境运行Airflow一段时间后,由于定时Job会在DagRun,TaskInstance等表插入大量的数据,会逐渐拖慢Airflow系统的内部SQL查询,进一步会影响前端管理页面的响应速度,所以需要定时清理不需要的 历史 数据,来保证前端管理页面的响应速度。根据Airflow版本的不同,分为1.10(V1)版本和2.0之后(V2)的版本两种,代码有细微差异。
V2
V1
使用方法:
1. 将上面的代码复制到一个新py文件airflow_db_cleanup_dag.py,保存在DAG目录下。
2. 可以通过在Airflow变量里增加一个变量max_metadb_storage_days来配置元数据保留天数,如果不配置这个变量,默认是90天。
3. 可以修改 schedule_interval变量来设置DAG执行时间,目前是每天执行一次,在UTC时间的8点半,北京时间下午4点半。
注意事项:
1. 请根据你Airflow实际上线时间来判断,将要被删除的数据量的大小,如果数据量很大,会导致Job卡住或者响应变慢,建议在调度的低峰时间或者分批删除数据。分批删除的方法是,通过调整变量max_metadb_storage_days来控制删除的数据的时间范围,比如先删除1年前的,再删除6个月-1年之间的,最后删除6个月到3个月的数据。
2. 如果有每季度执行一次的任务,需要将max_metadb_storage_days调大至120天,否则可能会导致最近一次执行的DagRun被清理后,Dag又重新被触发一次。原因是Scheduler会持续检查每个DAG是否满足执行条件,如果找不到DagRun记录,会认为该Dag还没有被执行过,从而又执行一次。
原创大数据基础之Airflow生产环境部署airflow研究
一 官方
airflow官方分布式部署结构图
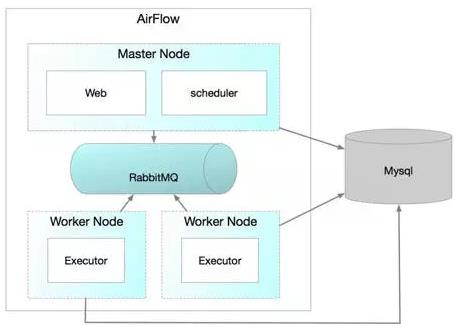
airflow进程
- webserver
- scheduler
- flower(非必须)
- worker
airflow缺点
- scheduler单点
- 通过在scheduler的dags目录变动dag文件来提交流程
官方分布式部署方案
- 多个webserver
- 多个worker
- CeleryExecutor(依赖redis或rabbitmq)
- MesosExecutor(依赖mesos)
第三方开源方案ASFC
针对scheduler单点问题,有第三方方案:https://github.com/teamclairvoyant/airflow-scheduler-failover-controller
The Airflow Scheduler Failover Controller (ASFC) is a mechanism that ensures that only one Scheduler instance is running in an Airflow Cluster at a time. This way you don\'t come across the issues we described in the "Motivation" section above.
You will first need to startup the ASFC on each of the instances you want the scheduler to be running on. When you start up multiple instances of the ASFC one of them takes on the Active state and the other takes on a Standby state. There is a heart beat mechanism setup to track if the Active ASFC is still active. If the Active ASFC misses multiple heart beats, the Standby ASFC becomes active.
The Active ASFC will poll every 10 seconds to see if the scheduler is running on the desired node. If it is not, the ASFC will try to restart the daemon. If the scheduler daemons still doesn\'t startup, the daemon is started on another node in the cluster.
Airflow Scheduler Failover Controller (ASFC),实现方式为:多个实例中只有一个处于active状态,处于active状态的实例会每10s检查一下scheduler进程是否存活并根据需要重启进程;
坏消息是该方案和airflow新版本1.10不兼容
二 基于mesos+hdfs的airflow生产环境部署方案研究
相同部分
和官方一致
- 使用mysql数据库作为元数据库
和官方不一致1
- 所有对dags目录的修改同步到hdfs上,保证dags目录的高可用
- 使用HDFS NFSGateway,将hdfs挂载到所有可能的scheduler节点上的,无论scheduler被部署在哪个节点上,都使用同一个dags目录
- 使用nginx+marathon-lb向外暴露airflow的webserver,可以操作流程或查看流程执行情况等
1 airflow单实例容器部署方案
和官方不一致2
- webserver、scheduler、worker作为docker容器运行,在多个节点上只部署一个实例,由marathon保证可用性,由marathon-lb做服务发现
- worker使用LocalExecutor,即所有的任务都使用子进程执行
- 为了使容器内的worker的LocalExecutor能够访问外部集群功能,一种可行的方式是将各种组件的父目录挂载到容器中(比如各个组件目录为/app/java、/app/hive、/app/spark、/app/hdfs,则挂载/app目录到容器内),然后所有的任务脚本一开始统一引入执行一个初始化环境变量的公共脚本,设置各种Home和Path,然后就可以在容器内使用各种组件的客户端,比如java、hive、spark、hdfs等
2 airflow分布式容器部署方案
和官方不一致2
- webserver和scheduler作为docker容器运行,在多个节点上只部署一个实例,由marathon保证可用性,由marathon-lb做服务发现
- worker使用MesosExecutor:
- 直接在mesos agent上执行airflow任务,好处是可以保证具体任务能够访问到集群的功能,比如impala/flink,缺点是需要在所有mesos agent节点的宿主机上部署airflow
- 在mesos agent上部署airflow worker的docker容器,然后在容器中执行airflow任务,好处是部署0成本,缺点是docker容器内只包含worker,不能使用外部集群的功能,不过这个缺点可以使用上一方案中LocalExecutor相同的方式解决
airflow docker image:https://github.com/puckel/docker-airflow
以上是关于Airflow使用技巧之-清理元数据库的主要内容,如果未能解决你的问题,请参考以下文章