通过抓包,实现Python模拟登陆各网站,原理分析!
Posted q1613161916
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通过抓包,实现Python模拟登陆各网站,原理分析!相关的知识,希望对你有一定的参考价值。

一、教程简介
1.1 基本介绍
通过分析登陆流程并使用 Python 实现模拟登陆到一个实验提供的网站,在实验过程中将学习并实践 Python 的网络编程,Python 实现模拟登陆的方法,使用 Firefox 抓包分析插件分析网络数据包等知识。
模拟登录可以帮助用户自动化完成很多操作,在不同场合下有不同的用处,无论是自动化一些日常的繁琐操作还是用于爬虫都是一项很实用的技能。本课程通过 Firefox 和 Python 来实现,环境要求如下:
- Python 库:urllib, http.cookiejar, Django
- Firefox 要求:装有 live http header插件 (已提供)

1.3 材料
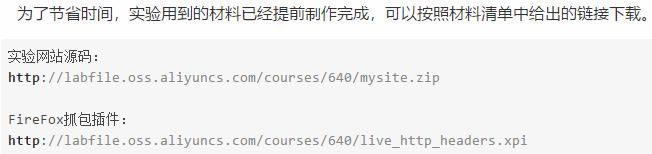
1.4 准备
1) 安装抓包插件Live Http Headers

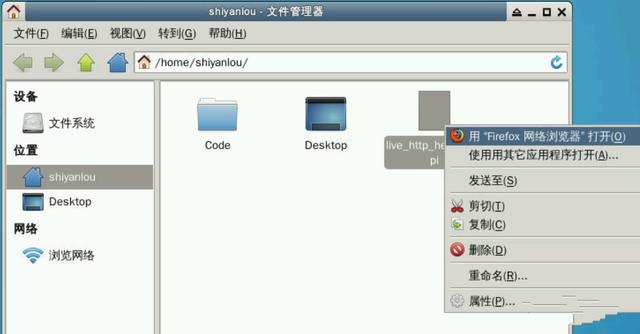
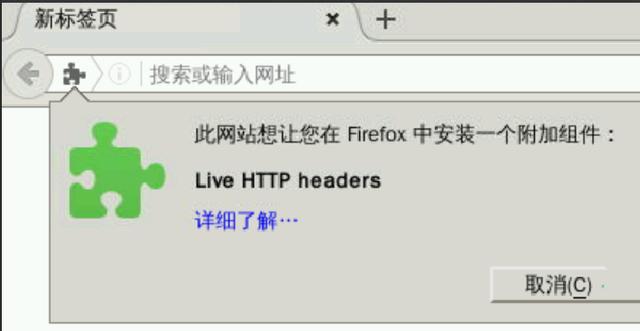

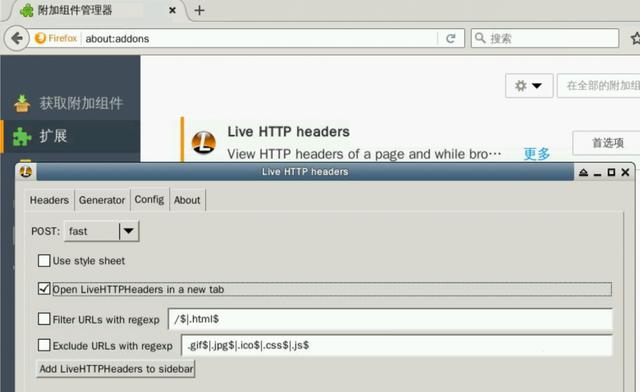
2)启动web应用
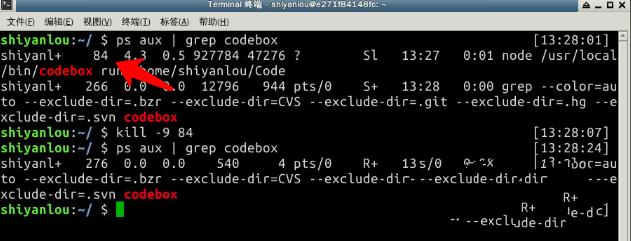
使用 ps -aux | grep codebox 查询获得 codebox 的进程号,然后使用 kill -9 进程号 停止 codebox 进程。执行过程见下图:
首先安装demo依赖的web框架django,并测试是否安装成功:
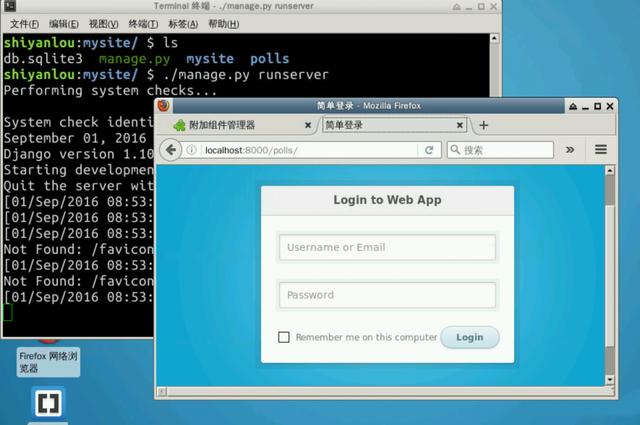
启动成功后在浏览器中输入 http://localhost:8000/polls 看到登录页面表示启动成功
二、分析登录过程
要通过编程实现登录,首先需要理解一般Web应用的登陆过程。

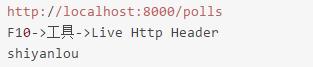
2.1 抓取请求
2.2原理分析

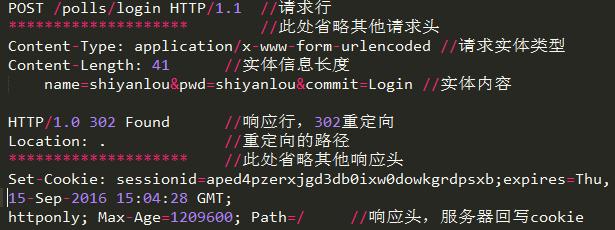
为什么是2个请求而不是1个呢?通过分析登录请求发现,登陆成功之后服务器发送了302重定向响应,服务器要求浏览器重新请求首页,这就产生了第二个请求。再来分析第二个请求,可以看到它相比登录请求多了一个请求头:

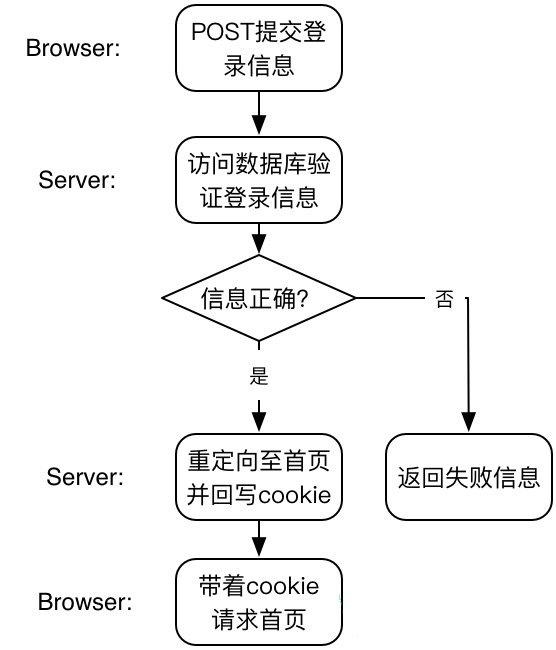
整个登录流程如下图所示:
服务器到底是如何区别不同用户的session的?为什么登陆成功会后要回写cookie呢?

2.3小结
对于服务器来说,登录=验证+写session。对于浏览器来说,登录=发送登录信息+获取带sessionid的cookie。可以说,只要获得了sessionid,就算实现了模拟登录。有了它我们便可以游离于系统之中。
三、使用Python实现登录(简单实例)
理解了登录过程的原理和细节之后,开始用Python来编写模拟登陆程序吧。

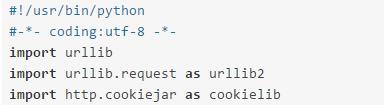
3.1导入模块
不要忘记编写文件头、导入必要的依赖模块
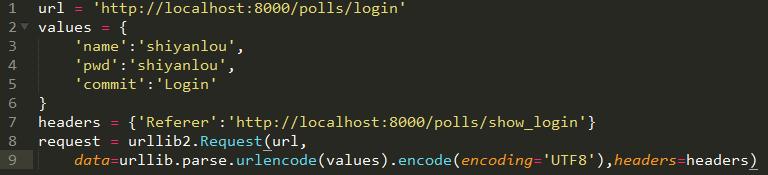
3.2构造登录请求

登录请求的实体部分如下:


全部Python代码:
附加参数

防盗链
Web 应用的资源都是有url的,只要获得了url就能够在任何地方引用。听起来很方便,但这可能会导致你的资源被别人盗用。

3.3发送请求并保存cookie

Python代码如下:
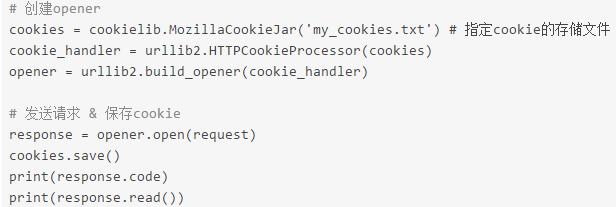
如果登陆成功

就可以在指定的文件my_cookies.txt中看到sessionid了。
3.4 使用cookie访问系统服务

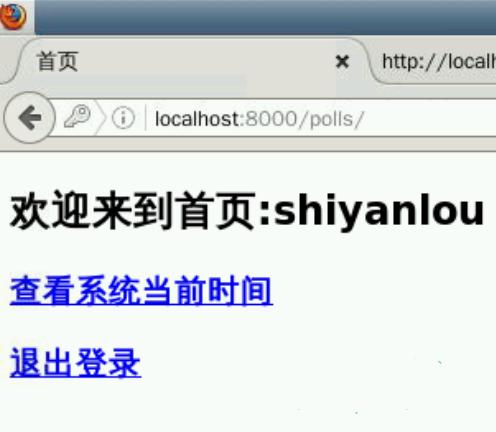
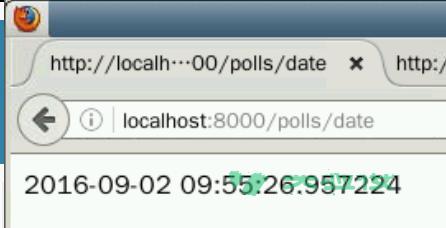
在我们模拟登录成功后,就可以直接通过opener打开这个url来使用这项系统服务。代码实现如下:
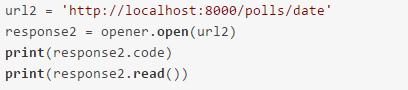
如果有是在另外一个python文件中使用这个cookie的话,再打开url之前需要先载入cookie:

教程取自实验楼。
以上是关于通过抓包,实现Python模拟登陆各网站,原理分析!的主要内容,如果未能解决你的问题,请参考以下文章