21 同步与互斥互斥量
Posted 人民广场的二道贩子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了21 同步与互斥互斥量相关的知识,希望对你有一定的参考价值。
1 简介
mutex相对于semaphore更加高效。
mutex在面对SMP时,如果mutex在别的CPU上运行,而“我”是唯一在等待这个mutex的进程。此时“我”是不会去休眠的,而是原地spin
2 mutex的结构和API
2.1 mutex结构
struct mutex my_mutex;
struct mutex
/* 1: unlocked, 0: locked, negative: locked, possible waiters */
/* 1: unlock
* 0: lock
* -1:lock,有人wait
*/
atomic_t count; /* 1: unlocked, 0: locked, negative: locked, possible waiters,这里描述的是possible */
spinlock_t wait_lock; /* 借助spinlock */
struct list_head wait_list; /* 与spinlock一致,等待线程放于此 */
#if defined(CONFIG_DEBUG_MUTEXES) || defined(CONFIG_MUTEX_SPIN_ON_OWNER)
struct task_struct *owner; /* 调试和性能优化 */
#endif
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
struct optimistic_spin_queue osq; /* Spinner MCS lock */
#endif
#ifdef CONFIG_DEBUG_MUTEXES
void *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
;
2.2 mutex的API
-
mutex_init(mutex)
初始化mutex
-
DEFINE_MUTEX(mutexname)
定义并初始化一个mutexname
-
void mutex_lock(struct mutex *lock)
获得mutex,如果无法获得会休眠
-
int mutex_lock_interruptible(struct mutex *lock)
获得mutex,如果无法获得会休眠。此外还能被信号唤醒
return
- 0:成功获得mutex
- -EINTR:被信号唤醒
-
int mutex_lock_killable(struct mutex *lock)
获得mutex,如果无法获得会休眠。此外还能被
fatal signal信号唤醒return
- 0:成功获得mutex
- -EINTR:被信号唤醒
-
int mutex_trylock(struct mutex *lock)
尝试获取mutex,如果无法获得立即返回
return
- 1:获得了mutex
- 0:没有获得mutex
-
void mutex_unlock(struct mutex *lock)
释放mutex,唤醒其他等待同一个mutex的线程
3 mutex实现机制
mutex中存在两条路径,一条fastpath,一条slowpath
3.1 mutex_lock
mutex_lock -> __mutex_fastpath_lock | | -> mutex_set_owner
| -> __mutex_lock_slowpath |
void __sched mutex_lock(struct mutex *lock)
might_sleep();
/*
* The locking fastpath is the 1->0 transition from
* \'unlocked\' into \'locked\' state.
*/
__mutex_fastpath_lock(&lock->count, __mutex_lock_slowpath);
mutex_set_owner(lock);
EXPORT_SYMBOL(mutex_lock);
static inline void
__mutex_fastpath_lock(atomic_t *count, void (*fail_fn)(atomic_t *))
/* 原子操作减
* 如果之前count为1,即mutex未被占用。直接返回。
*/
if (unlikely(atomic_dec_return_acquire(count) < 0))
fail_fn(count); // 如果count值为0,即mutex被占用。则调用__mutex_lock_slowpath。走slow路径
__visible void __sched
__mutex_lock_slowpath(atomic_t *lock_count)
/* container_of 从成员推出指针head */
struct mutex *lock = container_of(lock_count, struct mutex, count);
__mutex_lock_common(lock, TASK_UNINTERRUPTIBLE, 0,
NULL, _RET_IP_, NULL, 0);
/*
* Lock a mutex (possibly interruptible), slowpath:
*/
static __always_inline int __sched
__mutex_lock_common(struct mutex *lock, long state, unsigned int subclass,
struct lockdep_map *nest_lock, unsigned long ip,
struct ww_acquire_ctx *ww_ctx, const bool use_ww_ctx)
struct task_struct *task = current;
struct mutex_waiter waiter;
unsigned long flags;
int ret;
/* 传入值为0 */
if (use_ww_ctx)
struct ww_mutex *ww = container_of(lock, struct ww_mutex, base);
if (unlikely(ww_ctx == READ_ONCE(ww->ctx)))
return -EALREADY;
/* 禁止抢占 */
preempt_disable();
mutex_acquire_nest(&lock->dep_map, subclass, 0, nest_lock, ip);
/* 优化操作
* 如果是在另外一个CPU上的进程在使用,则不休眠,尝试等待一会
*/
if (mutex_optimistic_spin(lock, ww_ctx, use_ww_ctx))
/* got the lock, yay! */
preempt_enable();
return 0;
/* 上锁 */
spin_lock_mutex(&lock->wait_lock, flags);
/*
* Once more, try to acquire the lock. Only try-lock the mutex if
* it is unlocked to reduce unnecessary xchg() operations.
*/
/* 再次判定如果mutex没有被锁,并且count为1,则跳过等待
*/
if (!mutex_is_locked(lock) &&
(atomic_xchg_acquire(&lock->count, 0) == 1))
goto skip_wait;
debug_mutex_lock_common(lock, &waiter);
debug_mutex_add_waiter(lock, &waiter, task);
/* add waiting tasks to the end of the waitqueue (FIFO): */
/* 将当前进程放入wait_list
* 这里是FIFO,即先等待的先获得mutex
*/
list_add_tail(&waiter.list, &lock->wait_list);
waiter.task = task;
lock_contended(&lock->dep_map, ip);
for (;;)
/*
* Lets try to take the lock again - this is needed even if
* we get here for the first time (shortly after failing to
* acquire the lock), to make sure that we get a wakeup once
* it\'s unlocked. Later on, if we sleep, this is the
* operation that gives us the lock. We xchg it to -1, so
* that when we release the lock, we properly wake up the
* other waiters. We only attempt the xchg if the count is
* non-negative in order to avoid unnecessary xchg operations:
*/
/* 如果count为1,则意为着mutex可用,break */
if (atomic_read(&lock->count) >= 0 &&
(atomic_xchg_acquire(&lock->count, -1) == 1))
break;
/*
* got a signal? (This code gets eliminated in the
* TASK_UNINTERRUPTIBLE case.)
*/
/* 获得到信号,就退出 */
if (unlikely(signal_pending_state(state, task)))
ret = -EINTR;
goto err;
if (use_ww_ctx && ww_ctx->acquired > 0)
ret = __ww_mutex_lock_check_stamp(lock, ww_ctx);
if (ret)
goto err;
/* 把当前进程设为非RUNNING */
__set_task_state(task, state);
/* didn\'t get the lock, go to sleep: */
spin_unlock_mutex(&lock->wait_lock, flags); // 解锁
schedule_preempt_disabled(); // 开始调度
spin_lock_mutex(&lock->wait_lock, flags); // 被信号或者mutex_unlock唤醒,上锁
/* 设置当前进程为RUNNING */
__set_task_state(task, TASK_RUNNING);
/* 删除mutex中wait_list中的进程 */
mutex_remove_waiter(lock, &waiter, task);
/* set it to 0 if there are no waiters left: */
/* 如果wait_list为空,表示已经没人等待这个mutex了。将count设为0 */
if (likely(list_empty(&lock->wait_list)))
atomic_set(&lock->count, 0);
debug_mutex_free_waiter(&waiter);
skip_wait:
/* got the lock - cleanup and rejoice! */
lock_acquired(&lock->dep_map, ip);
mutex_set_owner(lock);
/* use_ww_ctx为0 */
if (use_ww_ctx)
struct ww_mutex *ww = container_of(lock, struct ww_mutex, base);
ww_mutex_set_context_slowpath(ww, ww_ctx);
spin_unlock_mutex(&lock->wait_lock, flags);
preempt_enable();
return 0;
err:
mutex_remove_waiter(lock, &waiter, task);
spin_unlock_mutex(&lock->wait_lock, flags);
debug_mutex_free_waiter(&waiter);
mutex_release(&lock->dep_map, 1, ip);
preempt_enable();
return ret;
3.2 mutex_unlock
mutex_unlock -> __mutex_fastpath_unlock
void __sched mutex_unlock(struct mutex *lock)
/*
* The unlocking fastpath is the 0->1 transition from \'locked\'
* into \'unlocked\' state:
*/
#ifndef CONFIG_DEBUG_MUTEXES
/*
* When debugging is enabled we must not clear the owner before time,
* the slow path will always be taken, and that clears the owner field
* after verifying that it was indeed current.
*/
mutex_clear_owner(lock);
#endif
__mutex_fastpath_unlock(&lock->count, __mutex_unlock_slowpath);
EXPORT_SYMBOL(mutex_unlock);
static inline void
__mutex_fastpath_unlock(atomic_t *count, void (*fail_fn)(atomic_t *))
/* count加1后如果count还是小于等于1,则表示设备当前有人等待。不能直接放回
* 需要调用slowpath
*/
if (unlikely(atomic_inc_return_release(count) <= 0))
fail_fn(count);
__visible void
__mutex_unlock_slowpath(atomic_t *lock_count)
struct mutex *lock = container_of(lock_count, struct mutex, count);
__mutex_unlock_common_slowpath(lock, 1);
static inline void
__mutex_unlock_common_slowpath(struct mutex *lock, int nested)
unsigned long flags;
WAKE_Q(wake_q);
/*
* As a performance measurement, release the lock before doing other
* wakeup related duties to follow. This allows other tasks to acquire
* the lock sooner, while still handling cleanups in past unlock calls.
* This can be done as we do not enforce strict equivalence between the
* mutex counter and wait_list.
*
*
* Some architectures leave the lock unlocked in the fastpath failure
* case, others need to leave it locked. In the later case we have to
* unlock it here - as the lock counter is currently 0 or negative.
*/
if (__mutex_slowpath_needs_to_unlock())
atomic_set(&lock->count, 1); // count被置为1
spin_lock_mutex(&lock->wait_lock, flags);
mutex_release(&lock->dep_map, nested, _RET_IP_);
debug_mutex_unlock(lock);
/* 从wait_list中取出第一个进程 */
if (!list_empty(&lock->wait_list))
/* get the first entry from the wait-list: */
struct mutex_waiter *waiter =
list_entry(lock->wait_list.next,
struct mutex_waiter, list);
debug_mutex_wake_waiter(lock, waiter);
wake_q_add(&wake_q, waiter->task);
spin_unlock_mutex(&lock->wait_lock, flags);
wake_up_q(&wake_q); // 唤醒wait进程
Linux___线程互斥与同步
文章目录
1. 线程互斥
- 互斥:任何时刻,互斥保证有且只有一个执行流进入临界区,访问临界资源,通常对临界资源起保护作用。
1.1 临界资源、临界区、原子性
- 临界资源:被多个执行流同时访问的共享资源就叫做临界资源。
- 临界区:每个线程内部,访问临界资源的代码,就叫做临界区。
- 原子性:不会被任何调度机制打断的操作,该操作只有两态,要么别做,要么做完。
1.2互斥量mutex
- 大部分情况,线程使用的数据都是局部变量,变量的地址空间在线程栈空间内,这种情况,变量归属单个线程,其他线程无法获得这种变量。
- 但有时候,很多变量都需要在线程间共享,这样的变量称为共享变量,可以通过数据的共享,完成线程之间的交互。
- 多个线程并发的操作共享变量,会带来一些问题。
下面写个多个线程操作共享变量来抢票的售票系统代码:
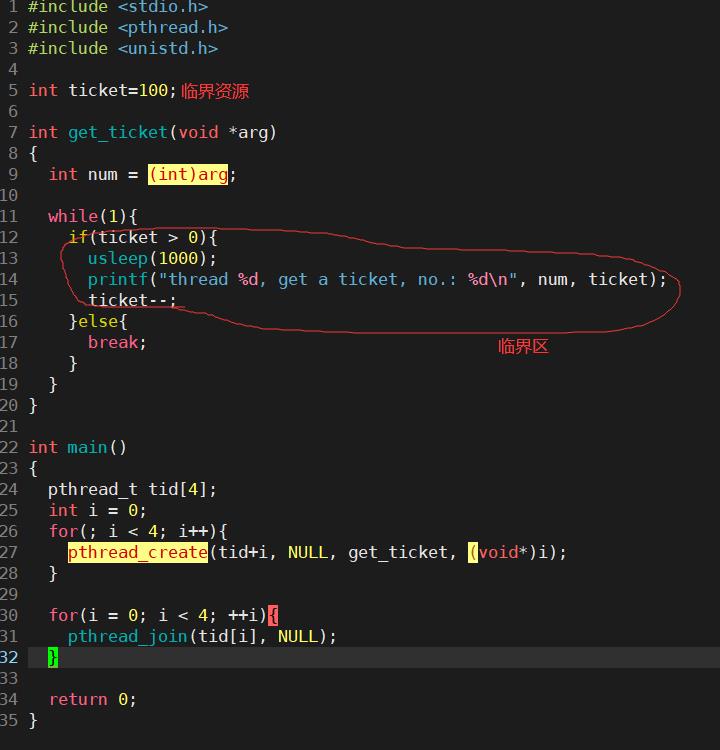
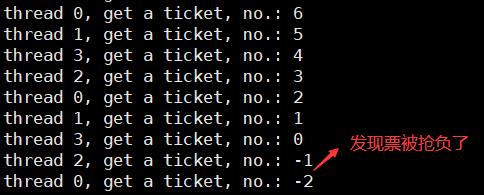
1.为什么可能无法获得争取结果?
if 语句判断条件为真以后,代码可以并发的切换到其他线程。usleep这个模拟漫长业务的过程中,可能有很多个线程会进入该代码段。ticket--操作本身就不是一个原子操作。

要解决以上问题,需要做到三点:
- 代码必须要有互斥行为:当代码进入临界区执行时,不允许其他线程进入该临界区。
- 如果多个线程同时要求执行临界区的代码,并且临界区没有线程在执行,那么只能允许一个线程进入该临界区。
- 如果线程不在临界区中执行,那么该线程不能阻止其他线程进入临界区。
要做到这三点,本质上就是需要一把锁。Linux上提供的这把锁叫互斥量(mutex)。
1.3互斥量的接口
初始化互斥量:

销毁互斥量:

销毁互斥量需要注意:
- 不要销毁一个已经加锁的互斥量。
- 已经销毁的互斥量,要确保后面不会有线程再尝试加锁。
互斥量加锁和解锁:

注意:在特定线程/进程拥有锁的期间,有新的线程来申请锁,pthread_ mutex_lock调用会陷入阻塞(执行流被挂起),等待互斥量解锁。unlock之后对线程进程唤醒操作。此外,加锁的粒度越小越好。
- 锁的申请是将lock由1变为0;
- 锁的销毁时将lock由0变为1。
改进上面的抢票系统:
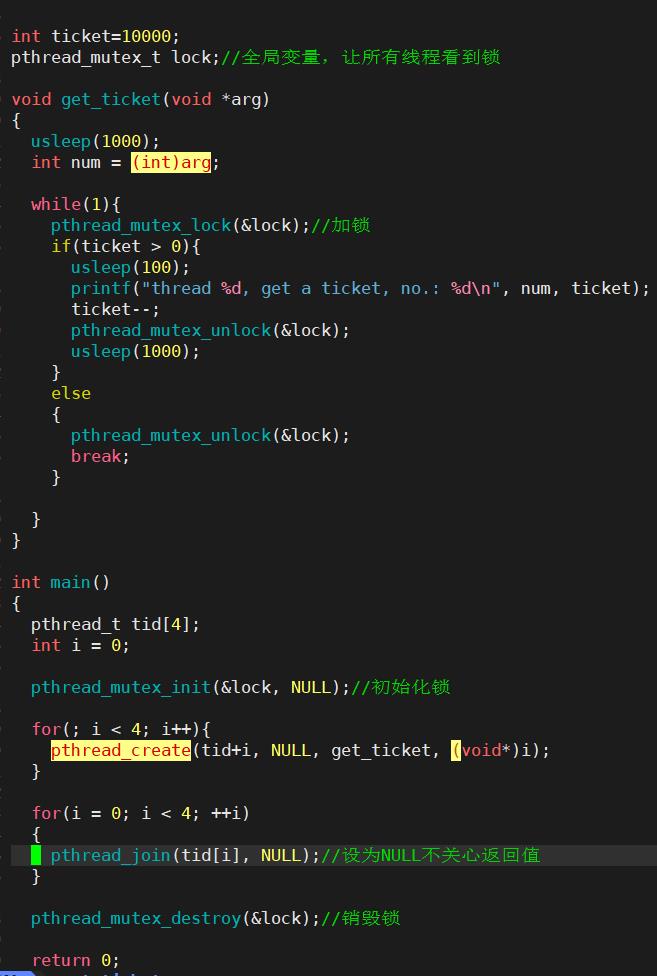
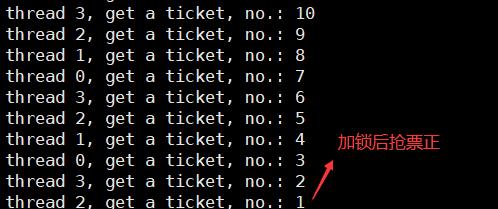
1.4互斥量(锁)实现原理
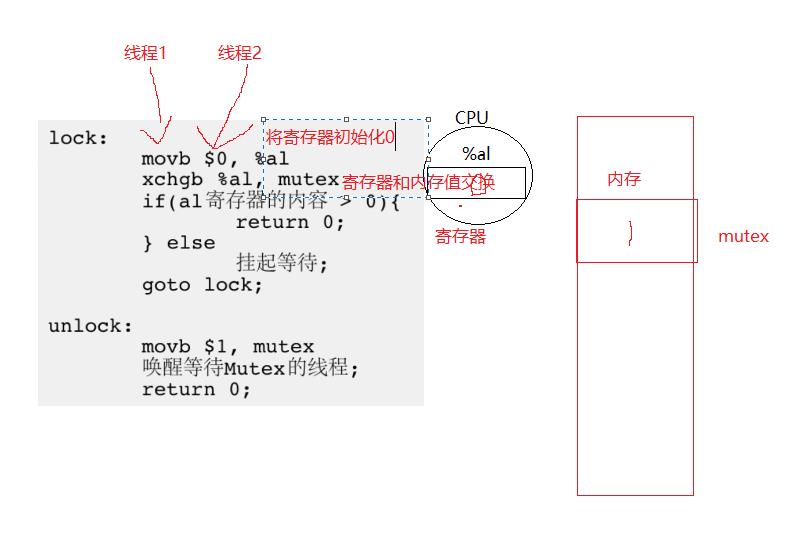
每个线程的寄存器是私有的,在修改数据的时候用的不是拷贝而是xchgb交换,将寄存器的值和内存的值互换。这保证了锁的原子性。因为其他线程申请的话,内存的值为0,申请不到锁。lock:0表示被占, 1表示可以被申请。
- 整个过程为1的mutex只有一份。
- exchange一条汇编完成了寄存器和内存数据的交换。
2. 可重入函数&&线程安全
- 线程安全:多个线程并发同一段代码时,不会出现不同的结果。常见对全局变量或者静态变量进行操作,并且没有锁保护的情况下,会出现该问题。
- 重入:同一个函数被不同的执行流调用,当前一个流程还没有执行完,就有其他的执行流再次进入,我们称之为重入。一个函数在重入的情况下,运行结果不会出现任何不同或者任何问题,则该函数被称为可重入函数,否则,是不可重入函数。
2.1 常见的线程不安全的情况
- 不保护共享变量的函数
- 函数状态随着被调用,状态发生变化的函数
- 返回指向静态变量指针的函数
- 调用线程不安全函数的函数
3. 死锁
死锁是指在一组进程中的各个进程均占有不会释放的资源,但因为互相申请被其他进程所占用而不会释放的资源,而处于的一种永久等待状态。
3.1 死锁四个必要条件
- 互斥条件:一个资源每次只能被一个执行流使用。
- 请求与保持条件:一个执行流因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:一个执行流已获得的资源,在末使用完之前,不能强行剥夺。
- 循环等待条件:若干执行流之间形成一种头尾相接的循环等待资源的关系。
3.2 避免死锁的方法
- 破坏死锁的四个必要条件
- 加锁顺序一致
- 避免锁未释放的
- 资源一次性分配
4.线程同步
同步概念:在保证数据安全(一般使用加锁方式)的情况下,让线程能够按照某种特定的顺序访问临界资源,就叫做同步。
- 为什么要存在同步?
- 使多线程同步高效的完成某些事情。
同步实现的事情:当有资源的时候,可以直接获取资源,没有资源的时候,线程进行等待,等待另外的线程生产一个资源,当生产完成的时候,通知等待的线程。
4.1条件变量
- 当一个线程互斥地访问某个变量时,它可能发现在其它线程改变状态之前,它什么也做不了。
- 例如一个线程访问队列时,发现队列为空,它只能等待,只到其它线程将一个节点添加到队列中,这种情况就需要用到条件变量。
竞态条件:因为时序问题,而导致程序异常,我们称之为竞态条件。在线程场景下,这种问题也不难理解。
条件变量的本质:PCB等待队列+两个接口(等待接口+唤醒接口)
4.2条件变量函数
- 定义条件变量
pthread_cond_t 条件变量类型
- 初始化条件变量
int pthread_cond_init(pthread_cond_t *restrict cond,const pthread_condattr_t *restrict attr);
参数:
cond:传入条件变量的地址
attr:条件变量的属性,一般设置为NULL,采用默认属性
- 销毁(释放动态初始化的条件变量所占用的内存)
int pthread_cond_destroy(pthread_cond_t *cond)
- 等待条件满足(将调用该等待接口的执行流放入PCB等待队列当中)
int pthread_cond_wait(pthread_cond_t *restrict cond,pthread_mutex_t *restrict mutex);
参数:
cond:传入条件变量的地址
restrict mutex:传入互斥锁变量的地址
- 唤醒等待(通知PCB等待当中的执行流来访问临界资源)
int pthread_cond_signal(pthread_cond_t *cond);
参数:
cond:传入条件变量的地址
//唤醒至少一个PCB等待队列当中的线程
4.3 为什么会有互斥锁?
- 同步并没有保证互斥,意味着不同的执行流可以在同一时刻去访问临界资源,所以需要条件变量中的互斥锁来保证互斥,各执行流在访问临界资源的时候,只有一个执行流可以访问。

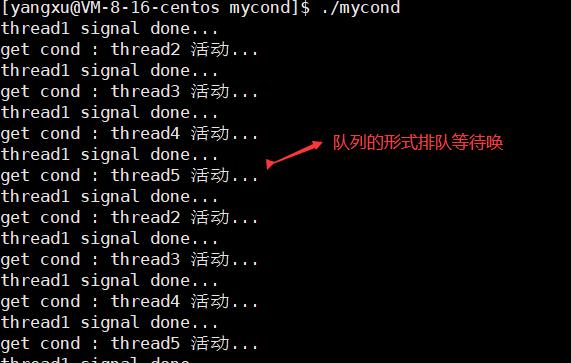
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
pthread_mutex_t lock;
pthread_cond_t cond;
void *task_t2(void *arg)
const char *name = (char*)arg;
while(1)
pthread_cond_wait(&cond, &lock);
printf("get cond : %s 活动...\\n", name);
void *task_t1(void *arg)
const char *name = (char*)arg;
while(1)
sleep(rand()%3+1);
pthread_cond_signal(&cond);
printf("%s signal done...\\n", name);
int main()
pthread_mutex_init(&lock, NULL);
pthread_cond_init(&cond, NULL);
pthread_t t1,t2,t3,t4,t5;
pthread_create(&t1, NULL, task_t1, "thread1");
pthread_create(&t2, NULL, task_t2, "thread2");
pthread_create(&t3, NULL, task_t2, "thread3");
pthread_create(&t4, NULL, task_t2, "thread4");
pthread_create(&t5, NULL, task_t2, "thread5");
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
pthread_join(t5, NULL);
pthread_mutex_destroy(&lock);
pthread_cond_destroy(&cond);
return 0;
以上是关于21 同步与互斥互斥量的主要内容,如果未能解决你的问题,请参考以下文章