AI芯片与SystemVerilog参数化
Posted 吴建明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI芯片与SystemVerilog参数化相关的知识,希望对你有一定的参考价值。
AI芯片与SystemVerilog参数化
大模型引发技术变革, AI芯片公司面临新挑战

ChatGPT 在全球范围内掀起了一场技术革命与商业浪潮,AI 市场也迎来了前所未有的机遇与增量。
当前,AI 基础设施的算力、算法呈现新 “摩尔定律”:相同算力下能训练生产更优质的模型,同时最先进的 AI 模型约每几个月算力需求就会扩大一倍。
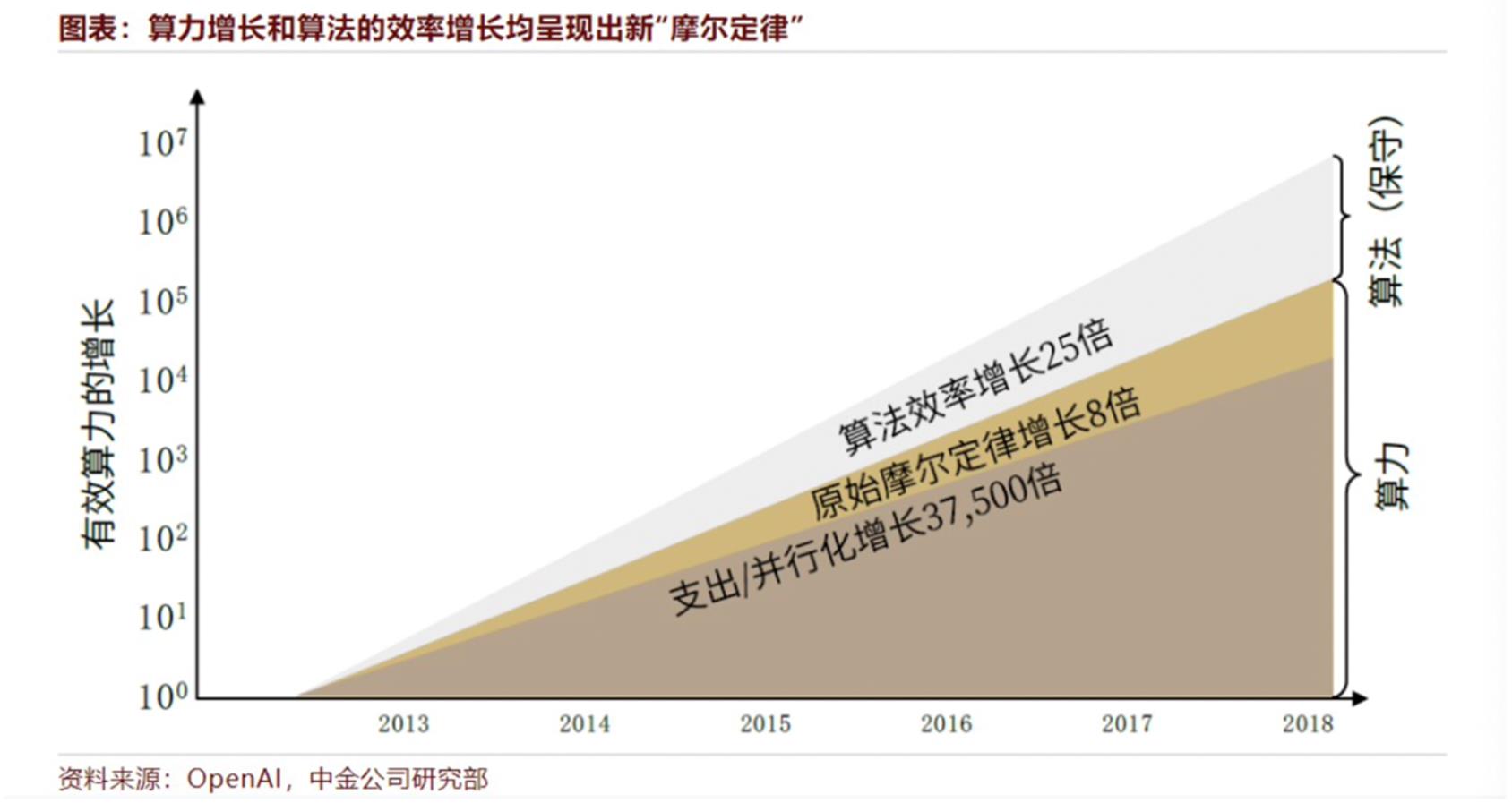
根据斯坦福大学和麦肯锡联合发布的《2019 人工智能指数报告》,2012 年之前最先进 AI 模型计算量每两年翻一倍;2012 年之后计算量每 3.4 个月翻一番,从 2012 年到 2020 年 3 月已增长 30 万倍。
伴随着大模型的快速迭代,其对算力的要求也不断提高,而算力的核心就是人工智能芯片。因此,如何在新趋势、新挑战下快速响应客户需求,推出切实可用的软硬件解决方案,成为了摆在国内 AI 芯片企业面前的首要课题。
拥抱变化,聚焦提升产品力
ChatGPT 及大模型技术大会上,昆仑芯科技研发总监王志鹏表示:“作为一家芯片公司,需要对市场的需求和变化非常敏感,才能使硬件产品始终精准匹配主流需求。”
大模型对计算的要求主要体现在三个方面,一是算力,二是互联,三是成本。就大模型而言,昆仑芯科技在产品定义上已经做出布局 —— 相较第一代产品,昆仑芯 2 代
AI 芯片可大幅优化算力、互联和高性能,而在研的下一代产品则将提供更佳的性能体验。
昆仑芯科技成立于 2021 年,前身为百度智能芯片及架构部。在实际业务场景中深耕 AI 加速领域已逾 10 年,专注打造拥有强大通用性、易用性和高性能的通用人工智能芯片。
在持续推进核心技术攻关的同时,昆仑芯科技紧密关注科技前沿,精准匹配市场需求。目前,公司已实现两代通用 AI 芯片的量产及落地应用,在互联网、智慧金融、智慧交通等领域已规模部署数万片。

昆仑芯在大模型场景的规模落地实践
“来自真实场景” 一直是昆仑芯科技最独特的身份标签,也是其规模部署数万片、在行业内 “领跑落地” 的核心优势所在。
王志鹏认为,只有基于真实业务场景中的数据进行端到端优化,才能顺利推进大模型落地。
目前市场上主流的大模型以 Transformer 架构为主,包含 Encoder 和 Decoder。Encoder
主要被应用于各类 NLP 的判别类任务;而 Decoder 更多被应用于翻译、图文生成等场景,最近出圈的 ChatGPT 就是典型代表。
针对大模型,昆仑芯持续打磨部署优化方案,领跑产业落地。昆仑芯已将大模型的 Transformer 相关优化技术沉淀为重要基建,优化后的性能比原有方案提升 5 倍以上,压缩显存 30% 以上。
以文生图大模型为例,昆仑芯已跑通一条端到端优化、规模落地之路。
AI 绘画模型的推理算力及显存需求随图像分辨率增大而指数级增加,同时,图像生成需要循环采样数十次,产业落地动辄需要高昂成本的部署集群,严重阻碍了 AIGC 模型大规模商业化落地。
2022 年第四季度,昆仑芯联合客户,基于飞桨 PaddlePaddle 发起了端到端联合优化项目。在 2-3 周内,项目组快速完成端到端优化,最终实现输入文本后 2 秒出图的优化效果,性能提升近 8 倍。
目前,昆仑芯 AI 加速卡 R200 已在该客户的大模型场景完成规模部署,性能数据全面超越同系列主流推理卡:
- 基于昆仑芯 AI 加速卡 R200 高效运算与推理能力,综合优化方案,在 dpm-25steps 算法下,利用昆仑芯 AI 加速卡 R200,生成 1024*1024 图像时的推理速度为 10.89 iters/s,相比同能力的主流推理卡快 20%。
- 昆仑芯 AI 加速卡 R200 拥有 32G GDDR6 显存,为大规模参数提供更大的存储容量、更高带宽的内存访问、更稳定的性能,生成更高分辨率的图片,为用户提供高性价比服务。
与此同时,面向当前市场需求迫切的大模型场景,据悉昆仑芯科技即将推出一款加速器组解决方案。
该加速器组搭载第二代昆仑芯 AI 芯片,是 AI 基础设施的重要组成部分,为 AI IAAS 平台、 AI PAAS 平台提供坚实算力支撑。该产品可提供更为集约的 AI 算力,具备分布式集群部署能力,支持弹性 RDMA 网络,对比传统网络通信时延降低 2~3 倍。该产品可明显提高并行加速比,训推一体化助力提高资源利用率,极大提升模型开发迭代效率。
携手上层伙伴共拓 AI 芯生态
ChatGPT 及大模型技术大会上,与会者提问:在生态建设方面,国内 AI 芯片产业面临的客观情况是什么?
这也是昆仑芯科技经常被客户提及的现实问题。
昆仑芯科技在努力进一步扩大生态影响力:首先要深刻理解客户的使用习惯,满足客户需求,踏踏实实把软硬件从产品和技术上做到位。随着产品的规模部署,客户越来越多,生态也就自然而然建立起来了。与此同时,产品也会因此得到更好的打磨,进入良性循环。
在昆仑芯科技看来,AI 芯片看似是一个硬件,但其本质则是一款软件产品。这也证明了软件栈、生态对于 AI 芯片发展的关键作用。
目前,昆仑芯已实现对飞桨的原生适配,并完成了 III 级兼容性测试,训练与推理性能可以满足用户的应用需求。从底层 AI 算力组件、AI 服务器,到操作系统,再到昆仑芯 SDK,昆仑芯和飞桨携手完成了一套端到端的 AI 计算系统解决方案,并致力于打造一个全栈式软硬一体的 AI 生态。
为进一步完善软件生态,昆仑芯已与多款通用处理器、操作系统、主流框架完成端到端适配,实现了软硬件解决方案的技术栈,为客户提供开箱即用的 AI 芯片产品。

昆仑芯软件栈
结语
谈及大模型趋势下 AI 芯片公司面对的变化,王志鹏说道: “必须快速调整心态,并拥抱大模型带来的变化。”
而这也刚好印证了昆仑芯科技 “突破创新” 的公司文化:面对瞬息万变的外部环境,突破创新是适应行业的唯一方式。
面对复杂多变的市场环境以及新场景新应用对研发和落地的重重挑战,国内 AI 芯片公司如何出圈?
集十余年 AI 加速领域的技术积淀,曾任百度智能芯片及架构部首席架构师、现任昆仑芯科技 CEO 欧阳剑认为,“AI 芯片公司应抓住场景和技术创新‘双驱动’模式,驱动架构优化升级与软硬件产品迭代,这是持续保持竞争力的关键。”
SystemVerilog中的类的参数化能干啥
Verilog中,大家已经知道可以使用各种编译命令和parameter等实现参数化的设计,具体使用时只需要通过修改对应的参数,就可以实现在不修改原代码的情况下,使对应的模块适用于不同的应用场合,从而可以提高代码的重用性和对应模块的通用性。在SystemVerilog中除了继续向下通吃Verilog的各种参数化设计方法外,还可以实现类的参数化设计,可以基于相同的模板类通过传递不同的参数实现不同的类,提高了代码的重用性。SystemVerilog中,类的参数化主要是用过两种方式实现的,一种是数值参数化,一种是类型参数化,其通用格式如下:

下面将通过示例说明类参数化的应用。
1.数值参数化
【示例】
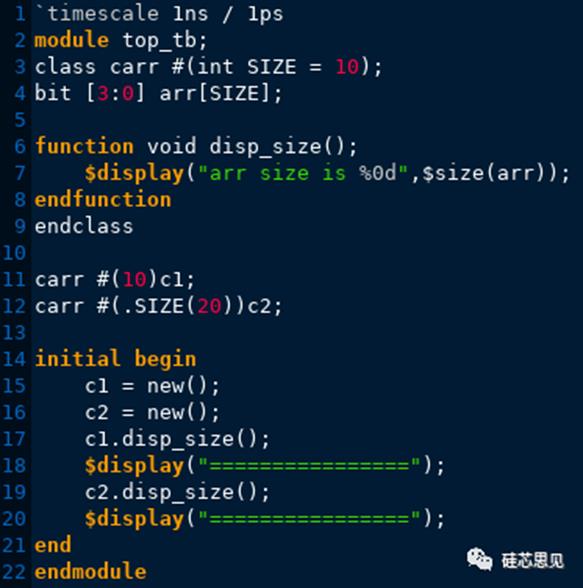
【仿真结果】

示例中,参数化类carr定义时,指定了参数SIZE,该参数SIZE将用于限定类中属性arr数组的大小,当传入不同的参数时,参数化类carr将形成特定的一个类,其中arr数组的大小也由传递的具体参数决定。示例中分别声明了两个句柄c1和c2,并且在声明时指定了参数类的参数SIZE的值,然后通过这两个句柄分别调用参数类中的方法disp_size,通过仿真结果,此时这两个句柄指向对象中的数组的大小是不一样,分别是句柄声明时传入的参数10和20。那么句柄c1和c2可以互相传递吗?
【示例】

【仿真结果】
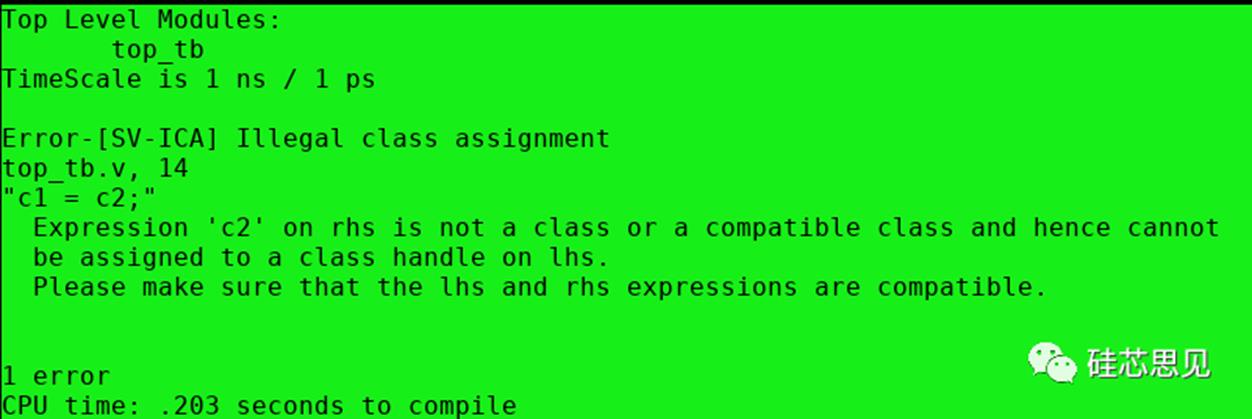
通过仿真结果可以看到,c1和c2是不能相互传递的,这主要是因为c1和c2在声明时传递给类carr的参数不同所以c1和c2句柄类型是不同的,即相互之间不能直接进行句柄的传递。由此可以知道,参数化类如果在声明句柄时指定不同的参数值,那么声明的句柄将不属于同一类型。实际使用时,参数化类不止可以将数值进行参数化,还可以将数据类型作为参数进行传递,下面示例说明。
2.类型参数化
【示例】
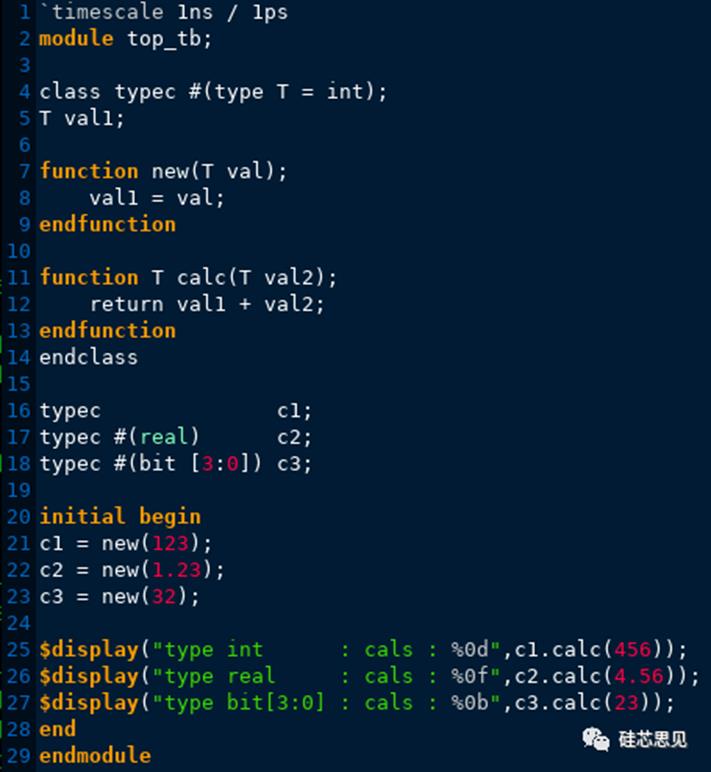
【仿真结果】
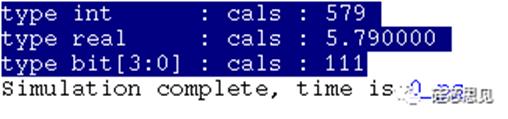
示例中,类typec在定义时,也使用了参数,但是此时使用的参数是“type”,即类型作为参数,并且该类型参数将决定整个参数类typec中使用该类型参数的所有类型。示例中声明句柄c1时,没有指定参数,因为typec定义时其中的参数指定了默认类型为int,所以此时c1中的类型T采用了默认类型int。c2声明时指定了typec的参数类型为real,则声明c2时,typec类中的T为real,同理c3中的T为bit[3:0]。然后通过句柄调用了方法calc返回不同类型的计算结果。这里需要注意的是,c3中T的类型为bit[3:0],所以调用方法calc返回的结果高位将被截掉,所以仿真最后的结果为“111”,即7(32+23=55,转换成二进制最低3位为“111”)。
3.参数默认值
上例中,c1声明时没有指定参数类型,就可以声明句柄,那么是不是所有的参数类都可以在声明句柄时不指定参数值或者参数类型呢?大家请看下例。
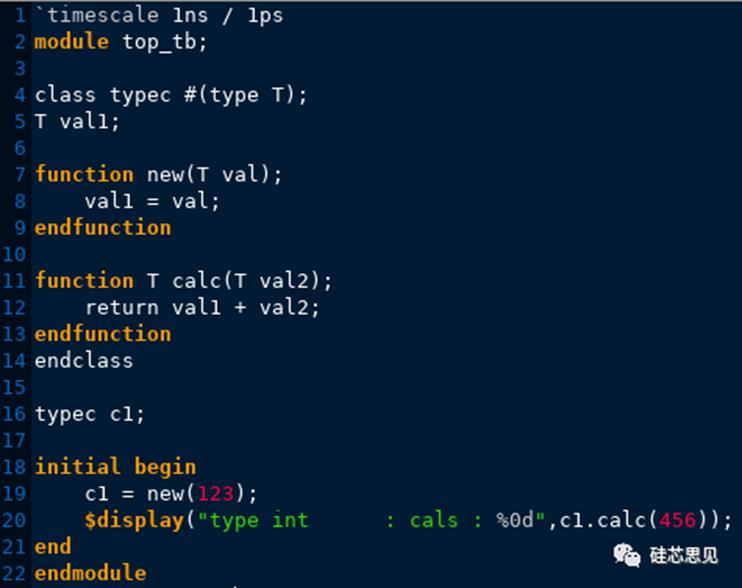
【示例】
【仿真结果】

示例中,参数类typec在定义时,虽然指定了类型参数,但是此时该类型参数并没有指定默认值,所以此时如果声明c1句柄时没有指定参数类型,那么typec中的类型T将会成为“游魂野鬼”,所以此时仿真器在编译析构时就会善意输出上述报错信息。所以,如果使用了参数类,并且参数有默认值,那么在声明句柄时不指定参数时,那么该参数将会使用默认值,如果在声明句柄时指定了参数,那么该参数类将会使用声明句柄时指定的参数。
4.父类子类都参数化
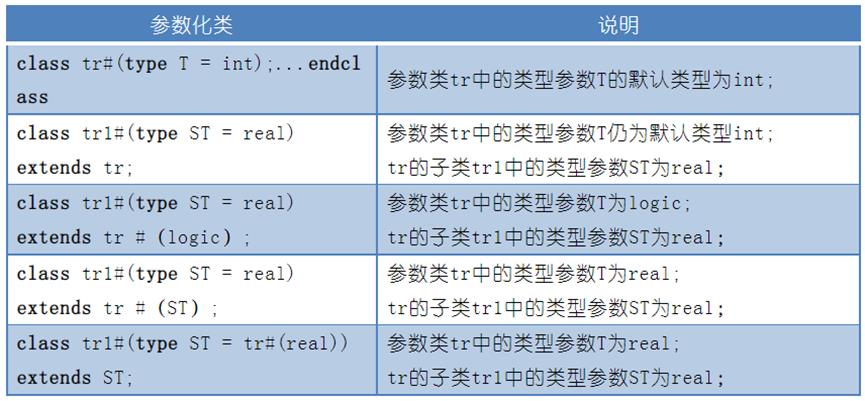
除了上述一些相对比较简单的类参数化模型之外,在实际使用时,经常会遇到父类子类都参数化的情况,汇总如下表所示。
【示例】
【仿真结果】

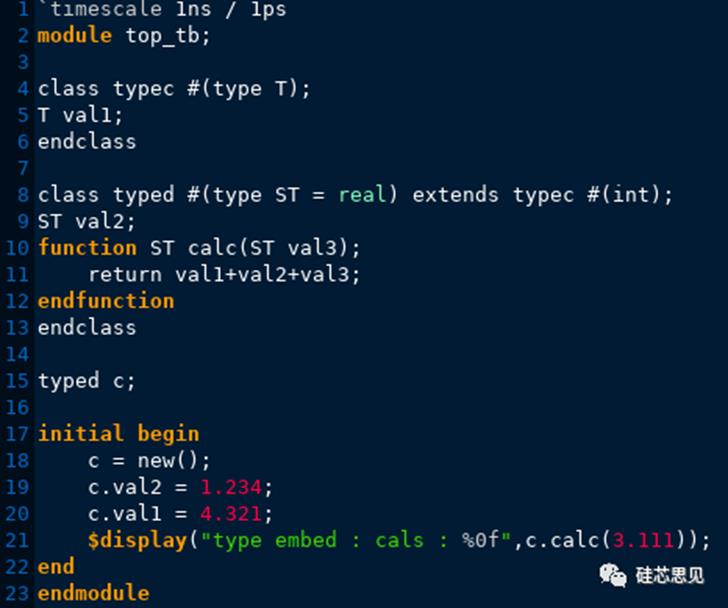
示例中,类typed拓展自typec,并且在typed定义时指定了该来的类型参数为real,同时指定了typed父类typec的类型参数为int。示例中第15行声明了句柄c,在第18行创建对象,并且句柄c指向该对象。第19行给子类中的属性val2赋值为1.234,因为val2类型为real,所以此时赋给val2中的值仍为1.234.第20行通过句柄c访问typec中属性val1,并且给val1赋值为4.321,但是因为typed在定义时给父类typec的类型参数指定的类型为int,所以此时val1的类型为int,所以val1中的值是4而不是赋给其的4.321。第21行调用typed中方法calc同时传递给val3的值为3.111,因为val3的类型为real(由ST决定),所以赋给val3的值仍为3.111。最终val1中的值为4,val2中的值为1.234,val3中的值为3.111,三者之和为仿真结果中显示的8.345。
通过上述示例,可以看到在使用参数化类时,用户可以定义一个模板类,通过传递不同的参数使模板类定制化,从而可以有效提高代码的复用性,同时在使用时大家也需要注意以下几点:
l给模板类传递不同的参数,那么形成的类虽然使用的模板相同,但是属于不同的类,是不能直接进行句柄传递;
l模板类的参数如果指定了默认值,那么在声明句柄时如果不指定参数,那么模板类的中的参数将使用默认值;
l模板类的参数如果没有指定默认值,那么在声明句柄时必须给参数指定默认值;
l用户在使用参数类时,建议先从非参数化类的定义开始,之后再经过调试抽象将非参数化类“提纯”到参数化类;
参考文献链接
https://mp.weixin.qq.com/s/WcmjosE-_YOz5J2nHa8sYQ
https://mp.weixin.qq.com/s/9R7bhuSTmHLdtq4Nj72G8w
AI推理与Compiler
AI推理与Compiler
AI芯片编译器能加深对AI的理解, AI芯片编译器不光涉及编译器知识,还涉及AI芯片架构和并行计算如OpenCL/Cuda等。如果从深度学习平台获得IR输入,还需要了解深度学习平台如Tensorflow、TVM等。
编译器领域的知识本身就非常艰深,和AI模型本身的关系也不是特别紧密,很难将AI建模作为发展方向,可以多关注GPGPU Architecture。即使AI芯片过气了,GPGPU还是会长盛不衰。
OneFlow是有其独特的设计理念和技术路线的。目前市面上已有的众多开源框架,用户最多的是PyTorch和TensorFlow,除此之外还有各大公司的自研框架:PaddlePaddle、MXNet、MindSpore、MegEngine等等。其中TensorFlow突出的特点是最完备,推理、serving、XLA、tensorboard等一应俱全,工业部署的主流还是TensorFlow;PyTorch的特点是易用性最好,eager执行、动态图、跟python的交互方式等等。
本文以 Batch Norm 为例介绍了推理计算图的具体实现,以及 MatMul 在 CPU 上的优化细节。作为 CPU 推理优化的基石,最优的推理计算图是实现高性能 CPU 推理的前提条件,极致性能的 MatMul 计算基础算子将为实现卷积计算中的 Im2col 和 Winograd 提供性能保障。
概述
天元(MegEngine)深度学习框架凭借「训练与推理一体化」的独特范式,能够极大程度上(90%)节省模型从研发到部署的整体成本,降低转换难度,真正实现小时级转化;同时,天元(MegEngine)在 CPU 推理方面所做的大量优化工作,也使得开发者在推理时能够发挥出处理器的最佳性能。
CPU 推理
CPU 推理的性能优化至关重要,经过优化的推理性能可以较未经优化的原始性能提升数十倍。
在进行模型推理阶段的优化时,首先需要对模型的计算图进行优化,以避免冗余的计算与访存,确保计算图在推理时是最优的;其次,在大多 CV 相关模型中,卷积的计算比重最高,达到模型总计算量 90% 以上,因此对模型推理的优化主要聚焦在对卷积计算的优化上。
卷积计算的实现方式有 3 种:direct 卷积,Im2col 卷积以及 Winograd 卷积。
Ÿ direct 卷积:根据卷积的计算公式直接对 FeatureMap 上进行滑窗计算;
Ÿ Im2col 卷积:根据卷积计算需要在输入通道上进行 reduce sum 的特点,将卷积运行转化为 MatMul 计算;
Ÿ winograd:在保证计算无误的前提下,使用加法替代乘法,达到优化卷积乘法计算量的目的,在中间过程需要使用 MatMul 进行计算。
以 Im2col 或 Winograd 方法进行的卷积计算,频繁使用到 MatMul,对 MatMul基础算子的优化尤为重要。
本文将首先介绍模型优化中的图优化,然后介绍基础算子 MatMul 在 CPU 上的优化方法。
推理计算图优化
在训练阶段定义模型的计算图,主要是为了满足模型参数的训练需求。当训练结束,模型参数固定后,对计算图的进一步优化能够帮助模型推理更加高效。
推理和训练的计算图是一张有向无环图(DAG),在天元中,开发者能够以类似 LLVM 的方式对 DAG 计算图定义许多优化方法,这里简称 OptPass。OptPass 可以根据用户的配置有选择性的加入到图优化的 OptPass 列表中,从而帮助用户灵活地为图优化定义 OptPass。
计算图优化
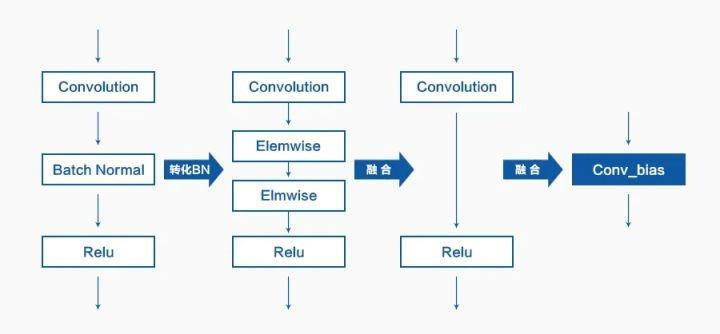
天元定义了多个为推理进行计算图优化的 OptPass,开发者使用这些 OptPass 之后,将得到一张用于推理的最优计算图。下面以 MobileNetV1 中, Convolution+Batch Norm+Relu 这样的典型结构经过计算图优化之后 Fuse 为 ConvBias 的过程为例,介绍天元的计算图优化过程。
由于 Batch Norm 在推理阶段除了输入 Tensor 外都是常数,可以简化为多个 elemwise 的组合,天元实现了一个 ConvertBatchNormToElemwisePass 的 Optpass,这个 OptPass 将模型中的所有 Batch Norm 转化为 Elemwise,具体转化原理如下:
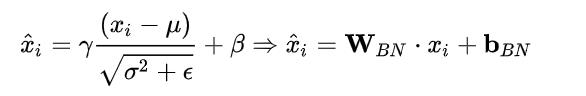
紧接这一过程,天元将运行 OptPass ParamRedistributePass,该 OptPass 会将上述 Batch Norm 转化而来的 Elemwise 中的 scale 融合到 convolution 的权重中,具体实现原理如下:

天元将运行 OptPass FuseConvBiasNonlinPass,该 OptPass 会将计算图中的 Convolution+Elemwise 转化为天元内部实现的 ConvBias Op 中,还会设置 ConvBias Op 中 NonelineaMode 参数。
如此便完成了从 Convolution+Batch Norm+Relu 到 ConvBias 的转换,整体转换过程如下图:

实验验证图优化之后的性能
在推理之前,如果要对完成训练的模型进行图优化,则需要在模型 dump 的期间进行,当然,也可以在 SDK 运行模型之前进行。下面是在模型 dump 时进行图优化的代码:
frommegengine.jitimporttrace@trace(symbolic=True)def pred_fun(data, *, net):net.eval() pred = net(data) pred_normalized = F.softmax(pred)returnpred_normalized# 使用 trace 类的 trace 接口无需运行直接编译pred_fun.trace(data, net=xor_net)# 使用 trace 类的 dump 接口进行部署pred_fun.dump("xornet_deploy.mge", arg_names=["data"], optimize_for_inference=True, enable_fuse_conv_bias_nonlinearity=True)
复制代码
上面的 optimize_for_inference=True 将在 dump 模型时候针对 inference 进行优化, enable_fuse_conv_bias_nonlinearity=True 将在模型中进行 Op Fuse 的优化,此外天元还支持其优化参数,具体可见天元的文档。
下表展示的,是在实验过程中对模型进行图优化前、后,模型运行性能的测试对比。
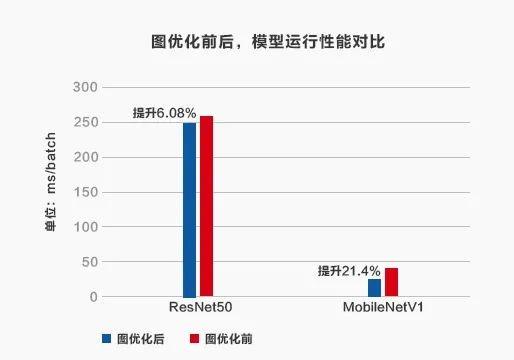
图优化对模型性能的提升效果显著,具体提升比例由模型自身决定。
MatMul 优化
MatMul 作为卷积运算的基础算子,会频繁地被 Im2col、Winograd 以及 FullyConnect 使用。在天元中,MatMul 既被封装为单独的 Op,也可以作为单独的 algo 供卷积的实现使用。
MatMul 也是计算最为密集的算子,因此天元进行了极致的优化。
优化
MatMul 是线性代数中的矩阵乘,假设矩阵 A 大小为 MK,矩阵 B 大小为 KN,则得到矩阵 C 大小为 M*N,其中 C 的每个元素的计算公式如下:
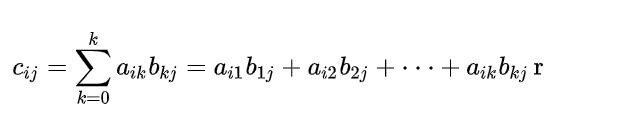
在 MatMul 的计算中乘法和加法的计算量为 2MNK (计算 C 中每个元素时,加法和乘法计算量分别为 K,C 的总元素个数为 MN),访存量为 2MNK (计算每个 C 中元素需要 2K 访存)+ 2MN(整个 C 矩阵读一次和写一次)。由于计算量固定(排除 Strassen),所以只能优化访存,使得乘法和加法运算达到处理器的极限性能,从而实现 MatMul 的最佳性能。
MatMul 分块
关于减少 MatMul 计算时的访存量,最有效的方法是对 MatMul 的计算进行分块,并将分块之后的数据保存在 CPU 的 Cache 中。
如下图所示,将 A 按照 mr 进行行分块,将 B 按照 nr 进行列分块,计算时将需要用到的分块保存在 CPU 的各级 Cache 中,从而极大的减少了内存的读写。
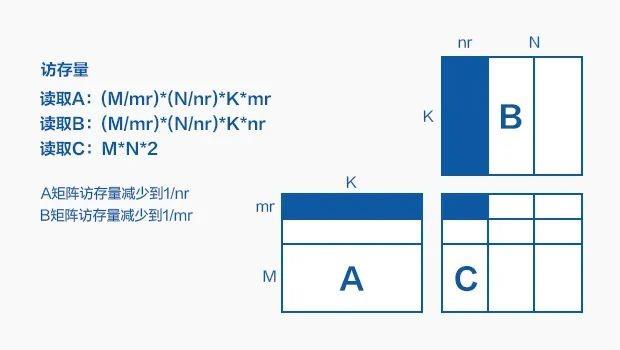
进一步细化上面的分块计算过程如下图所示,A 中的一个行块都要重复地和 B 中的每一个列块进行小分块的 MatMul,写入到 C 的小块中,为了使得分块尽量的大 (如上所述,能够减少内存访存量),Cache miss 率尽量低,因此需要根据 CPU 的 Cache 结构特点(速度:L1D>L2>L3,容量 L1D<L2<L3) 来分配 Cache 和数据块之间的存放关系,天元中进行的分配如下:
· 将下图中红色 (访问重复次数最多的 A 的行块,计算时需要的 B 的一个列块以及计算结果的 C 的小块) 部分都保存在 L1 中。
· 由于计算完每一个 C 的行块,都需要重复遍历一次整个 B 矩阵,因此将 B 存放在 L2 中使得每次读取 B 的一个列块都是从 L2 中读取,代价最小。
· 将重复访问率最高的 C 的累加中间结果保存在速度最快的 CPU 处理器的寄存器中。
通过上面的分配策略,并结合 CPU 中资源(寄存器数量,L1D 和 L2 的大小),便可以确定最佳的 MatMul 计算中的 Nr,Kr:
· 可以根据 CPU 处理器的寄存器数量得到 mr 和 nr 的具体大小,寄存器容量 > mr*nr
· 根据 L1D Cache 的大小结合 mr 和 nr 计算出 Kr,Kr=L1D/(mr+nr)
· 再根据 L2 的大小计算出 B 矩阵中的 Nr,Nr=(L2-L1D)/Kr
在上面计算 N 时,用 L2-L1D 的原因是,由于当前 CPU 使用的 Cache 是 Inclusive 的,且 L2 是指令缓存和数据缓存合并的,另外上面 M 没有明确限制。
在得到上面最佳 Nr、Kr、mr 和 nr 之后,进一步便可以首先对 MatMul 计算中的 N、K 进行 Nr 和 Kr 分块,然后在 Nr、Kr 的基础上再进行 mr 和 nr 分块。如此,MatMul 计算中的计算访存比达到最高,且 CPU 处理器的资源也得到充分利用。
经过分块之后,由于在最内层的计算 Kernel 为 A(mrKr)B(Krnr)=C(mrnr)的分块矩阵乘,决定了整个 MatMul 的计算性能,因此需要极致地优化。
Kernel 计算
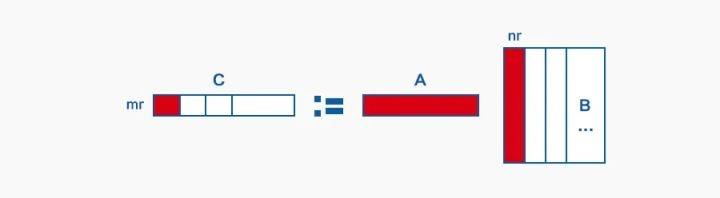
最核心的计算 Kernel 进行的是尺寸为 (mrKr)x(Krnr)–>(mr*nr) 的小尺寸 MatMul,其计算示意图如下:

如上图所示,Kernel 在计算时会读取 A 中一列, B 中一行,进行矩阵乘,得到 大小为 mr*nr 的 C,然后和原来 C 中的值相加,如此循环 Kr 次,完成该 Kernel 的计算。
在该 Kernel 的计算过程中乘法和加法的计算量为 2mrnrKr,访存量为 (mr+nr)Kr+2mrnr,可以根据处理器来判断该计算能否隐藏数据的访存。下面以 ARM cortex A76 为例进行分析,根据 A76 的数据手册得到:
· FP32 SIMD Load throughput=2,即单周期可以 load 8 个 float 数据
· FP32 SIMD FMLA throughput=2,即单周期可以进行 16 个乘加运算
当 Kernel 的尺寸 mr=8、nr=12、Kr=256,计算量为 49152 次乘加运算,访存量为 5312 个 float 数据时,该计算访存量为 9.25,大于处理器的计算访存比 2。因此可以得出结论,如果 A 和 B 均在 L1 中,则该 Kernel 的计算不会因为数据的 Load 被阻塞,所以计算单元能够发挥出处理器的最佳性能。
虽然在对 MatMul 进行分块时,已经计划将 A 和 B 这样的小矩阵置于 L1D Cache 中,但是数据在真正运行时却不一定都在 L1D 中,原因在于,B 矩阵的列块在原来的大矩阵中内存并不连续,其次 A 中的一列由于内存不连续,也不能使用 SIMD 进行 load,为此需要对 A 和 B 进行数据 PACK。
MatMul 数据 PACK
上文 kernel 在计算过程中,需要同时读取 A 矩阵 mr 行数据,而每行数据之间内存不连续,因此这种访问对 Cache 不友好,同样,在读取矩阵 B 中 nr 列的时候也存在数据读取不连续的问题,加之 A 的所有行块和 B 中的所有列块将被读取多次,因此可以通过对 A 和 B 提前进行数据 PACK, 实现在后续计算中频繁多次访问数据时是连续的(只在第一次 PACK 时对 Cache 不友好),进而获得巨大收益。

对矩阵 A 进行数据 PACK 是将 A 中 mr 行数据的相同列拷贝到一起,如上图中将 A PACK 到 A’ 的步骤。重复完所有 A 中的行块便完成了 A 矩阵的数据 PACK。B 矩阵的 PACK 操作是,将 nr 列数据拷贝到连续的内存地址中,对应上图 B PACK 到 B’ 的过程。
实 验
按照文介绍方式方式,天元在 X86 和 ARM 上分别对 MatMul 进行了优化。下表展示了 ARM64 上的性能测试结果,实验平台为 kirin 980。
首先,对该处理器进行分析可以看到,其主频为 2.6 GHz,每个周期能够进行 16 次乘加计算,因此其理论计算峰值为 16*2.6=41.6 Gflops。
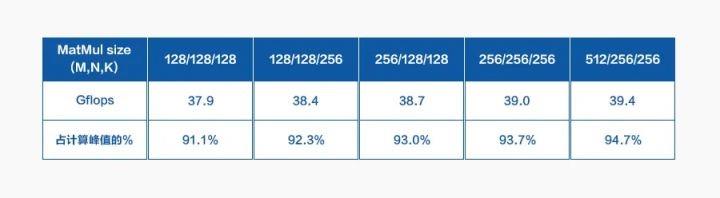
可以看到,经天元优化的 MatMul 计算,发挥出了该处理器 90% 以上的计算性能。
OneFlow
- OneFlow的设计思路,独特性
- OneFlow的特色一:Actor机制
- OneFlow的特色二:SBP机制
- 对人工智能/深度学习未来的看法
- 对开源的感想和总结
OneFlow是独特的
可以说完备性和易用性这两极分别被TF和PyTorch占据,OneFlow作为一个小团队打造的框架,如果单纯的模仿别的框架,跟TF比完备性,跟PyTorch比易用性,那是绝对没戏的。
但深度学习框架还有第三极:性能。OneFlow的特点就是追求极致的性能,而且是分布式多机多卡环境下的横向扩展性。OneFlow的核心设计理念就是从分布式的性能角度出发,打造一个多机多卡体验就像使用单卡一样容易,而且速度最快的深度学习框架。
深度学习是吞没算力的巨兽。多机多卡的理想很丰满,现实很骨感,用户会遇到多机多卡加速比不高,得不偿失,用户会遇到参数梁巨大时,现有框架不支持模型并行而无法训练。为解决此类问题,业界不仅仅改进深度学习框架自身,还研发了多种第三方插件,譬如NCCL, Horovod, BytePS,HugeCTR,Mesh-tensorflow, Gpipe等等。但是,仍只满足一小部分需求。
分别介绍两点OneFlow相较于其它框架的独特设计,来体现OneFlow是如何看待分布式场景下的深度学习训练的。
Actor——用一套简洁的机制解决所有令人头秃的技术难题
(关键特性:去中心化调度流水线数据搬运是一等公民传输被计算掩盖控制逻辑被执行逻辑掩盖)
在OneFlow的设计中,分为Compiler和Runtime两个时期,Compiler把用户定义的网络、分布式环境信息等编译成一个静态图的中间表示(称之为Plan);Runtime时期,各个机器根据Plan里的Actor描述信息真实地创建属于机器的众多Actor,整个深度学习训练期间,OneFlow的执行基本单元就是Actor,Actor之间通过消息机制通信,静态执行图上的节点就是Actor,节点之间的连边是Register,Register存储了Actor之间的生产者消费者信息,以及生产者Actor产生的数据。
1、Actor机制实现去中心化调度
OneFlow的运行时去中心化调度就是用Actor机制实现的。在整个由Actor构成的静态图中,没有一个中心的调度节点,每个Actor都只需要关心消费的那些Actor,和消费生产出的数据的那些Actor即可。这样在超大规模的分布式训练场景下,完全的去中心化调度可以避免中心调度的单点性能瓶颈问题。
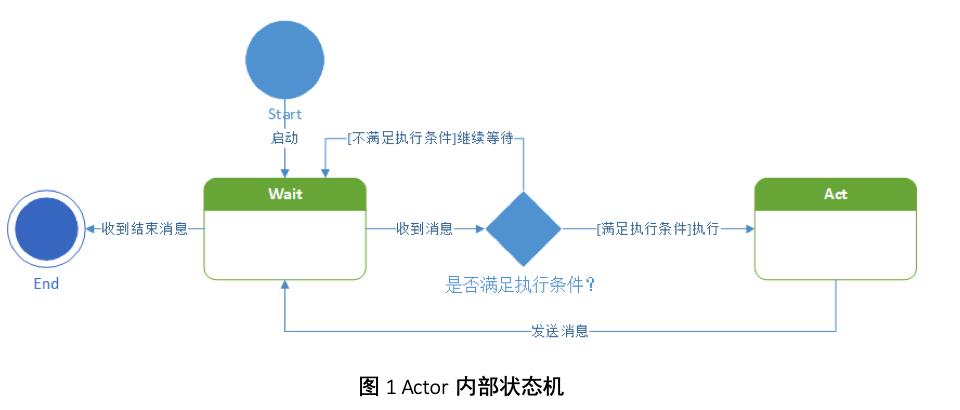
每个Actor内部都有一个状态机,Actor之间的收发消息和Actor内部执行都会改变状态。当Actor收到了执行所需要读取的Register,且当前有空闲的Register可以生产的时候,这个Actor就执行(Act)一次,生产出一个Register。生产完以后,该Actor就向需要消费这个Register的那些消费者Actor们发消息,表示可以来读取产生的数据了;同时该Actor还需要把消费完的那些Register还给这些Regsiter的生产者Actor们,表示用完了数据,可以回收了。Actor内部的状态机如图4所示。
2、Actor机制实现流水线
上面介绍了Actor的内部状态机,Actor之间的消息传递和数据传递是依赖Register实现的。一个Actor是否能执行,只跟两个条件相关:1)消费的那些Register是否可读;2)生产的那些Register是否有空闲块可写。对于一个Register,如果运行时分配多个空闲块,那么相邻的两个Actor就可以同时工作,重叠起来,这样就实现了各个Actor之间的流水线。理想状态下整个静态执行图的执行时间就是整个系统中是性能瓶颈的那个Actor运行的总时间,其余Actor的执行时间就被流水线掩盖起来了。
举一个例子来解释Actor机制下的流水线是如何运转起来的。图2是一个由3个Actor(a,b,c)组成的静态图的时序图。其中深绿色的Regst方块表示正在被使用的Register块,白色的Regst方块表示同一个Register的备用空闲块。
1)在Time0时刻,Actor a产出了一个Regst_a_0,Actor b 和 Actor c由于没有可读的Register,所以处在等待状态。假设每个Actor的执行时间都是单位时间。
2)到Time1时刻,Actor a给Actor b发消息说可以来读产出的Regst_a_0了,Actor b收到了消息,并检查生产的Register b是否有空闲Regst块可用,发现有可用的Regst_b_0,于是Time1时刻Actor b执行,读取Regst_a_0,写Regst_b_0;同时Actor a还会去看是否有空闲块可写,发现有,Time1时刻Actor a也在执行,写Regst_a_1。(这里需要说明的是,Regst_a_0和Regst_a_1逻辑上是属于同一个Register,只是空间上分成了不同的空闲块备份而已。在深度学习训练任务中,Regst_a_0和Regst_a_1里存放的是同一个operator产出的不同batch的数据。)于是Actor a和Actor b就并行工作起来了。Actor c由于没有数据可读,仍在等待。
3)到Time2时刻,Actor b 生产出了Regst_b_0,于是给下游的消费者Actor c发消息说可以来读生产的Regst_b_0,同时给上游的生产者Actor a发消息说用完了的Regst_a_0。此时Actor a 已经把刚刚生产的Regst_a_1又发给了Actor b,Actor b检查仍有Regst_b_1空闲,于是Actor b开始读Regst_a_1,写Regst_b_1;Actor c收到Regst_b_0,发现有Regst_c_0空闲,于是Actor c开始执行,读Regst_b_0, 写Regst_c_0;Actor a收到了Actor b用完还回来的Regst_a_0,检查Regst_a_0所有的消费者都用完了,于是将Regst_a_0回收,标记为空闲块,同时Actor a还可以继续执行,写Regst_a_2。
在上面的例子中,到了Time2时刻,其实Actor a、b、c都在工作,在深度学习训练任务中,Time2时刻Regst_b_0、Regst_c_0存放的是Batch 0的数据,Regst_a_1、Regst_b_1存放的是Batch 1的数据,Regst_a_2存放的是Batch 2的数据。通过一个Register有多个空闲块的设计,Actor机制就实现了流水并行。

3、数据搬运
在多机多卡的分布式环境中,各个机器和各个设备之间的数据传输往往是影响系统横向扩展性的最重要因素,如果传输开销可以被计算开销掩盖,那么分布式深度学习训练就可以达到理想的线性加速比。相较于其框架,OneFlow把数据搬运视为跟数据计算同等地位的操作,提出“数据搬运是一等公民”的思想。
已有框架在编译期的关注焦点是数据计算,数据搬运是背后隐式发生的,在静态分析计算图时略过计算和搬运的重叠编排,OneFlow在计算图中显式表达了数据搬运,而且在静态分析时同等对待数据搬运和数据计算,以最大化重叠搬运和计算。
在OneFlow最终的执行图中,数据搬运操作也是一个个Actor。除了在设备上做数据计算用的Actor以外,还有计算机内存到GPU显存之间的数据拷贝Actor,机器之间做网络通信的网络Actor,负责数据的切分、合并、复制的Actor,负责读取磁盘数据的Actor,负责加载保存模型的Actor等等。很多其框架都把数据加载、多卡模型梯度的同步、网络、模型加载更新等分别做成一个单独的模块,而OneFlow的设计是所有的功能都在一张由Actor组成的静态执行图里实现了。OneFlow这样的设计不仅简洁、优雅,还非常高效。

图3表示了没有GPU-Direct的情况下,在OneFlow的Runtime阶段,一个设备上的计算节点如果消费了另一个设备的计算节点,数据是如何搬运过去的。
4、尽可能并行
在OneFlow的设计中,所有的出发点都是希望可以尽可能并行,从而达到最优的分布式性能。比如考虑到分布式训练模型梯度同步时,显存到内存的传输带宽高于机器之间的网络传输带宽,OneFlow会做两级的scatter和gather操作(本机的和各个机器之间的),用于增加locality,提高整体性能;又比如在异步启动深度学习训练时,python端用户的控制逻辑跟OneFlow运行时的执行图是并行执行的,同时OneFlow有一套互斥临界区的设计保证执行的高效性和正确性;数据加载部分无论是从磁盘读数据还是从python端喂数据,OneFlow都能保证尽可能并行,使得计算设备不会因为要等数据而导致性能下降。
已有框架要尽可能重叠数据搬运和计算,一般借助多层回调(callback)函数,当嵌套层次过多时,会遇到所谓的callback hell麻烦,正确性和可读性都可能下降。但在OneFlow中,以上的这些并行并发特性,都是在这一套简洁的Actor机制下实现的,解决了令人头秃的callback hell问题。
此外,在多机的网络通信部分,OneFlow底层的网络通信库原生支持RDMA的高性能通信,也有一套基于epoll的高效通信设计。而相比于最流行的Pytorch,多机还需要通过RPC来做数据同步。
Placement+SBP——OneFlow如何做到分布式最易用
OneFlow是目前分布式场景中支持数据并行、模型并行、流水并行等最易用的深度学习框架。用户只需要像单卡一样去搭建网络模型,并告诉OneFlow有哪些机器哪些卡,OneFlow就会用最高效的方式把这些机器和设备使用起来。
这源于OneFlow的一套独特的设计:ConsistentView(一致性视角)。对于多机多卡,OneFlow会抽象成一个超级大的设备,称之为逻辑上的设备,这个逻辑设备的显存是实际多个物理设备的显存之和,这个逻辑设备的算力也是实际多个物理设备的算力之和。用户只需要定义在这个逻辑上的超级设备里,深度学习模型是如何构建的,其余的便不需要用户来操作,由OneFlow来完成逻辑上的设备到物理上的设备的映射。
这里先明确两个概念:“逻辑上的”和“物理上的”。“逻辑上的”表示OneFlow把分布式集群抽象成一个超级计算机之后的计算和数据,“物理上的”表示那些真实的部署到各个机器和设备上的计算和数据。深度学习网络是由Op构成的计算图,Op之间生产消费Tensor数据。在多机多卡的环境下,一个逻辑上的Op会对应多个真实的物理上的Op,每个物理上的Op实际执行的计算都是这个逻辑Op计算的一部分,一个逻辑上的Tensor也会对应多个物理上的Tensor,每个物理上的Tensor都是逻辑Tensor的一部分。
对于其框架定义的分布式训练,每张卡是一个“world”,多卡之间根据暴露出来的接口来同步模型梯度;而对于OneFlow而言,多机多卡也都是一个“world”,使用一套Placement+SBP的方式做全局的统筹管理。
1、Placement
在OneFlow的计算图搭建过程中,每个计算Op都有一个属性叫做Placement,表示了该逻辑上的Op,是要部署到哪些机器哪些设备上的。对于常见的数据并行,就是所有的Op都部署到所有的设备上。但OneFlow也支持用户指定Op的Placement,比如当网络过大单卡根本放不下的时候,在OneFlow可以让网络的前一部分在一张卡上,后一部分在另一张卡上,用一种“接力”的方式工作,实现流水并行。
图4展示了一种可能的Placement例子:

2、SBP
SBP是OneFlow独有的概念,他是三个单词的首字母组合:Split、Broadcast、PartialSum(以PartialSum为例,实际上还可以是PartialMin, PartialMax等reduce操作),全称叫SbpParallel,表示一种逻辑上的Tensor跟物理上的多个Tensor的映射关系。
其中Split表示物理上的Tensor是逻辑Tensor按照某一维度切分后得到的, Split有个参数axis,表示切分的维度,如果把多个物理上的Tensor按照Split的维度进行拼接,就能还原出逻辑Tensor;Broadcast表示物理上的Tensor是跟逻辑上的Tensor完全相同的;PartialSum表示物理上的Tensor虽然跟逻辑上的Tensor形状一致,但是物理上的Tensor里的值是逻辑Tensor里对应位置的一部分,如果把物理上的多个Tensor按照对应位置相加,即可还原出逻辑上的Tensor。图5展示了SBP的简单示例。
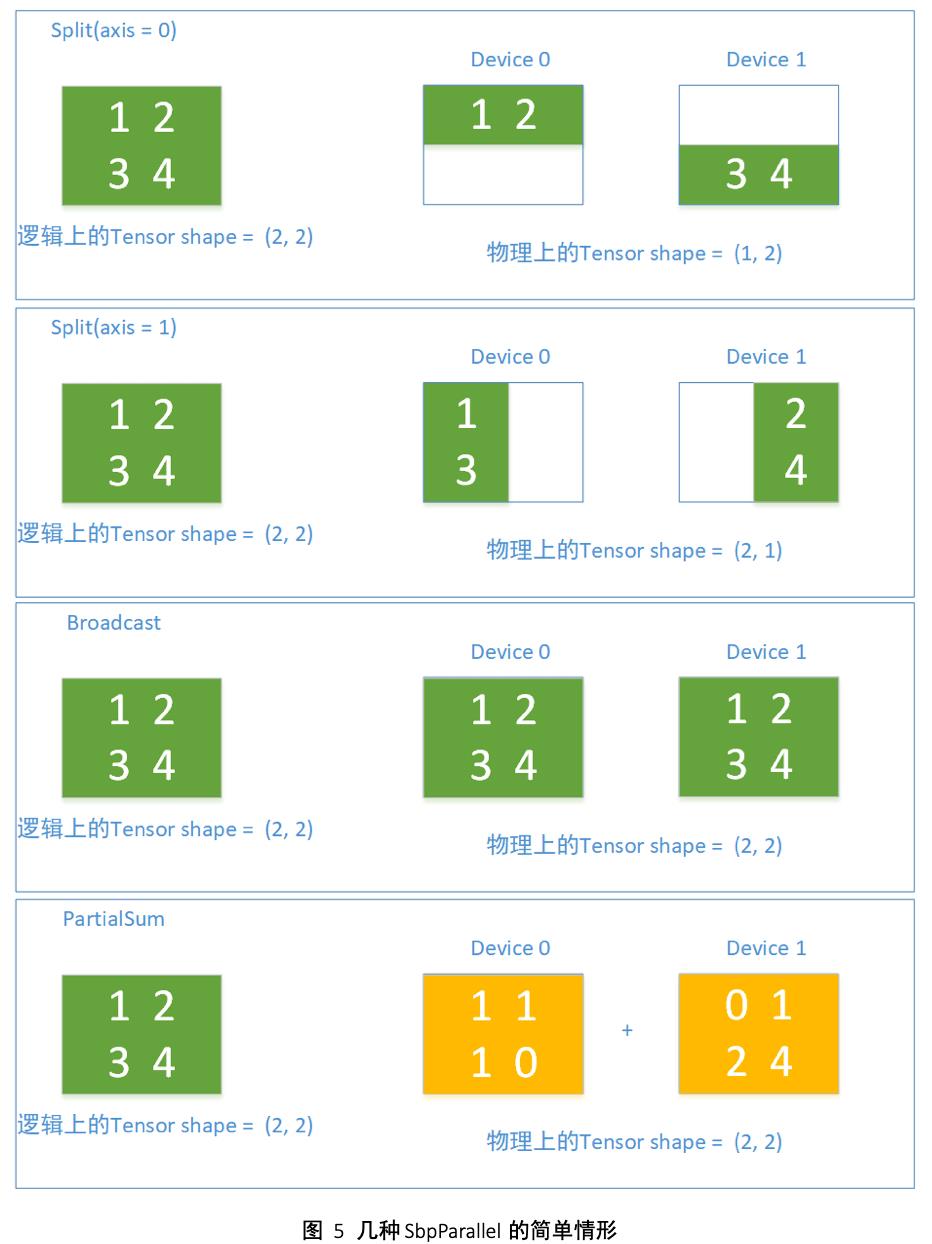
SbpSignature是一个SbpParallel的集合,在OneFlow的设计里是Op的属性,描绘了一个逻辑上的Op被映射成各个设备上的多个物理上的Op以后,这些物理上的Op是如何看待输入输出Tensor在逻辑上和物理上的映射关系的。一个Op会有多个合法的SbpSignature,一个最简单的合法signature就是输入输出都是Broadcast,这表示了这个Op需要整个逻辑上的Tensor数据。
当用户构建的逻辑上的计算图确定以后,OneFlow在Compiler生成分布式的物理上的执行图时,会考虑每个Op的Placement和该Op允许的合法SbpSignature列表,在其中选择一个传输开销最小的SbpSignature作为本次训练的SbpSignature,用于指导Compiler生成最高效的执行图。
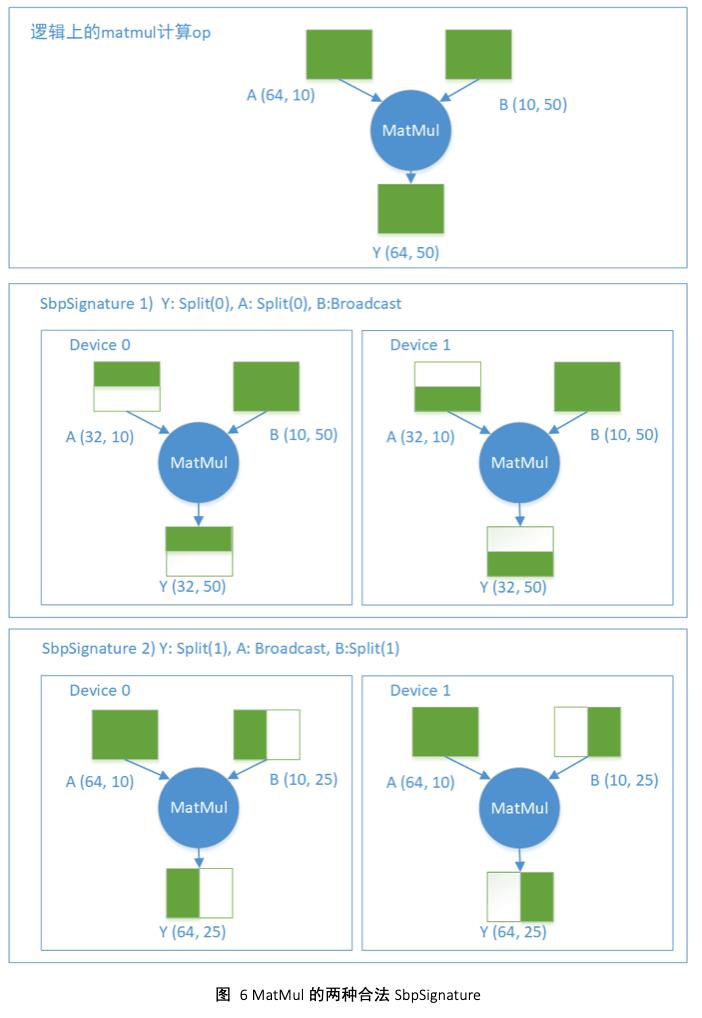
关于Op的合法SbpSignature的列表,举一个矩阵乘法(matmul)的Op的例子。定义: Y = matmul(A,B) , A, B, Y都是Tensor,表示Y = AB。那么至少存在两种合法的SbpSignature:
- Y: Split(0), A:Split(0), B:Broadcast
- Y: Split(1), A:Broadcast, B: Split(1)
两种合法的signature在两个设备上的示意图如图6所示。假设逻辑上的MatMul的输入输出Tensor的形状是:
A(64, 10) X B(10, 50) -> Y(64, 50)
且该Op分布在两个设备上。在第一种SbpSignature下,0号设备上的A是逻辑上A的前一半,1号设备上的A是逻辑A的后一半(按照第0维切分),而两个设备上的B跟逻辑上的B完全一致,两个设备输出的Y分别是逻辑上的Y的前一半和后一半。同样可以分析第二种SbpSignature。
值得一提的是,当A是数据,B是模型的时候,第一种SbpSignature就是数据并行,第二种SbpSignature就是模型并行。如果两个相邻的MatMul op,前一个使用第一种SbpSignature,后一个使用第二种SbpSignature,整个网络就实现了混合并行。图7是一个混合并行的示例,定义了Y0 = MatMul_0(A0, B0) , Y1 = MatMul_1(Y0, B1)这样一个由两个op组成的计算图,其中A0, Y0, Y1是数据Tensor,B0, B1是模型Tensor。
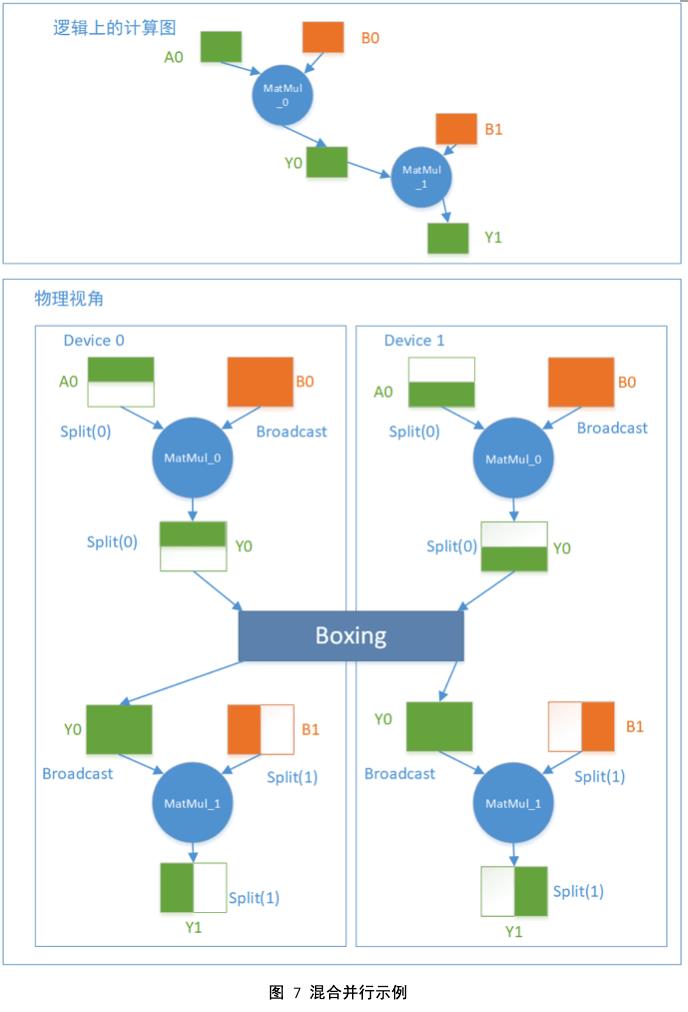
在图7中MatMul_0产出的Y0被MatMul_1消费,但是这两个op对同一个Tensor的SBP看待方式是不一样的,MatMul_0认为Y0是Split(axis=0)切分,但是MatMul_1需要一个Broadcast的Y0输入。这时候OneFlow会自动插入一个“万能”的Boxing Op做必要的数据裁剪、拼接、搬运和求和等等操作,使得所有的Op都可以在分布式环境下拿到想要的数据。
另外在数据并行的时候,训练的前向模型Tensor的是Broadcast,对应反向传播的梯度就是PartialSum,当Optimizer需要全部的梯度来更新模型时,就会触发OneFlow的Boxing机制进行高效的梯度同步工作。
3、最易用的分布式并行框架
OneFlow的这套Placement + SBP + Boxing的机制,可以使得用户定义的计算图中的Op、Tensor以任意的方式分布在各个机器和各个设备上,无论是数据并行、模型并行还是流水并行,对于OneFlow而言,都只是一个特定Placement下的特定SbpSignature的组合而已,用户可以方便的配置,也可以交给OneFlow来做自动的处理。
另外,早在微软推出ZeRO-2框架之前,OneFlow就已经支持了类似的功能,多机多卡情况下,每个模型Tensor都只保存在其中一个设备上,降低梯度计算中的内存占用。
综上,在编译期,OneFlow通过在一套数学上严谨的形式系统来表示所有合法的并行模式,并支持编译器较方便地自动搜索最优并行方案;在运行期,则通过Actor系统最优地、灵活地支持并行、并发执行。OneFlow的内核具有简洁、高效和高扩展性的优点。
浅谈人工智能和深度学习的未来
OneFlow区别于其它深度学习框架的核心就是对于分布式训练的思考和设计,OneFlow致力于分布式训练最快。
随着深度学习的发展,模型会越来越大,训练深度学习模型所需的算力会越来越高,同时模型增大的速度要大于GPU单卡显存扩容的速度;训练对算力的增长要求要大于GPU单卡算力增长的速度。所以分布式深度学习训练会越来越常见、越来越重要。BERT、GPT-3等模型的出现印证了判断。单个芯片的能力总是受到物理约束,相信算力增长的解决之道在于横向扩展,而这必须从系统软件的角度去求解,一旦解决,即使是把性能“一般”的芯片互联起来,只要系统软件可以让协同工作好,就可以满足任何算力需求。
在分布式深度学习训练中,性能至关重要。性能和横向扩展性是深度学习框架的核心竞争力。
如果深度学习的未来是单机单卡就能搞得定的规模的话,那么深度学习也就只能做做目前已知的一些简单任务,深度学习的浪潮也会褪去。
开源,OneFlow还有很长的路要走
OneFlow团队是一个小团队,OneFlow作为一个开源框架还有很多不足。框架的易用性和完善性不如Pytorch和Tensorflow。团队还在努力补上OneFlow的短板,同时也非常需要开源社区的支持。
以上是关于AI芯片与SystemVerilog参数化的主要内容,如果未能解决你的问题,请参考以下文章