VGGNet随笔
Posted ZmQmZa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了VGGNet随笔相关的知识,希望对你有一定的参考价值。
论文:Very deep convolutional networks for large-scale image recognition
一、前言
VGGNet与GoogLeNet分别获得了那一年ImageNet图像分类大赛的第二和第一,如果说GoogleNet是通过改变网络的宽度来提高神经网络的性能(很多的并行计算),证明了适度增加网络的宽度可以提高网络的性能,那么VGGNet就是通过增加网络的深度来提高网络的性能,本文探究了网络深度与其性能之间的关系,成功的构筑了16~19层深的卷积神经网络,证明了增加网络的深度能在一定程度上影响网络的最终性能,VGGNet可以看成是AlexNet的加强版,有更深的网络层,包括卷积层和池化层下采样以及全连接层。
二、VGGNet网络模型

1、结构简单
VGGNet的网络结构就像AlexNet一样简单,甚至于比AlexNet还要更简单,因为在特征提取层里VGGNet的所有卷积核的kernel_size,stride,padding都一样,没有选择不同尺寸的卷积核做特征的提取,层与层之间使用最大池化分开,然后再加上3个全连接层,最后再接上softmax输出层,这样就构成了整个网络结构,即使整个网络结构简洁明了但是却性能十足,在特征提取上依然有很好的性能,这也是为什么直到今天VGG也依然被很多工作用于图像的特征提取器的原因。
2、小卷积核
小卷积核是VGG的一个重要特点,我们知道ZFNet的论文里提到过较大的卷积核更有可能造成特征值溢出导致梯度爆炸的问题,因此需要使用小卷积核防止梯度爆炸,而本文却是从另一个角度来解释为什么小卷积核要比大的卷积核更加有效,以下图为例:
假设feature mao的尺寸是28x28,卷积步长stride=1,padding=0,那么使用一个5x5的卷积核进行卷积得到的输出feature map的尺寸为26x26,卷积核的参数是25个。
而本文就采用多个小卷积核的方法来代替大卷积核,先使用一个3x3的卷积核进行卷积,得到feature map的尺寸为26x26,这时候在使用一个3x3的卷积核得到的feature map的尺寸为24x24,与使用一个5x5的卷积核的效果一样,但是参数却只有18个,说明多个小卷积核确实可得到与大卷积核一样的效果。我们可以从感知野的角度来解释这一现象,我们可以认为大卷积核的感知野较大,所以一次5x5就可以得到24x24的feature map,小卷积核的感知野较小,需要2个3x3的卷积核的感知野叠加才能得到一样的效果,也就是说2个3x3的卷积核的感知野相当于1个5x5的卷积核的感知野,那么也就很容易可以知道3个3x3的卷积核的感知野相当于1个7x7的卷积核的感知野,参数量更少。因此我们可以使用小卷积核来代替大卷积核,既能增加非线性的映射,也能很好的减少参数量。
3、小池化核
与AlexNet的3x3的卷积核相比,VGG全部采用2x2的卷积核进行下采样。
4、通道数多
VGG的第一层通道数为64,后面每一层就翻倍一次,最多到512个通道数,也就是将空间维度的特征转移到了通道维度上。
5、层数更深,特征图更多
与第四点一样,都是卷积层注重扩大feature map的通道数,池化层专注于缩小feature map的空间尺寸,使模型架构更深更宽的同时控制了计算量的增加规模。
总结
VGG证明了较深的网络可以帮助模型更好的进行特征提取,其实也就是能够更好的提取更高级别的语义信息,能够从低级的空间信息逐渐进行特征融合,扩大其感知野,总结出更高级的语义信息,而这种高级别的语义信息才是对后边的分类有所帮助,因此VGG这种更深的特征提取层才会对后来深度学习的发展产生这么大的影响。
手撕 CNN 经典网络之 VGGNet(PyTorch实战篇)
大家好,我是红色石头!
在上一篇文章:
详细介绍了 VGGNet 的网络结构,今天我们将使用 PyTorch 来复现VGGNet网络,并用VGGNet模型来解决一个经典的Kaggle图像识别比赛问题。
正文开始!
1. 数据集制作
在论文中AlexNet作者使用的是ILSVRC 2012比赛数据集,该数据集非常大(有138G),下载、训练都很消耗时间,我们在复现的时候就不用这个数据集了。由于MNIST、CIFAR10、CIFAR100这些数据集图片尺寸都较小,不符合AlexNet网络输入尺寸227x227的要求,因此我们改用kaggle比赛经典的“猫狗大战”数据集了。
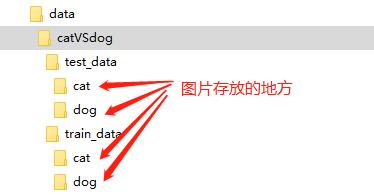
该数据集包含的训练集总共25000张图片,猫狗各12500张,带标签;测试集总共12500张,不带标签。我们仅使用带标签的25000张图片,分别拿出2500张猫和狗的图片作为模型的验证集。我们按照以下目录层级结构,将数据集图片放好。
为了方便大家训练,我们将该数据集放在百度云盘,下载链接:
链接:https://pan.baidu.com/s/1UEOzxWWMLCUoLTxdWUkB4A
提取码:cdue
1.1 制作图片数据的索引
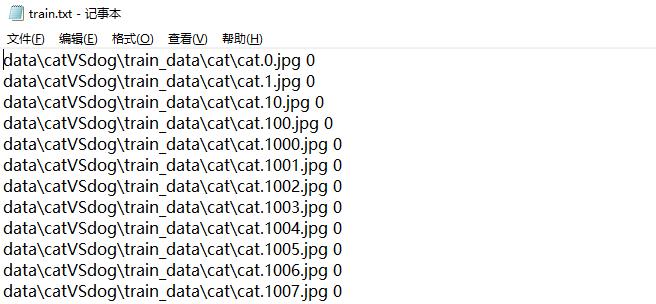
准备好数据集之后,我们需要用PyTorch来读取并制作可以用来训练和测试的数据集。对于训练集和测试集,首先要分别制作对应的图片数据索引,即train.txt和test.txt两个文件,每个txt中包含每个图片的目录和对应类别class(cat对应的label=0,dog对应的label=1)。示意图如下:
制作图片数据索引train.txt和test.txt两个文件的python脚本程序如下:
import os
train_txt_path = os.path.join("data", "catVSdog", "train.txt")
train_dir = os.path.join("data", "catVSdog", "train_data")
valid_txt_path = os.path.join("data", "catVSdog", "test.txt")
valid_dir = os.path.join("data", "catVSdog", "test_data")
def gen_txt(txt_path, img_dir):
f = open(txt_path, 'w')
for root, s_dirs, _ in os.walk(img_dir, topdown=True): # 获取 train文件下各文件夹名称
for sub_dir in s_dirs:
i_dir = os.path.join(root, sub_dir) # 获取各类的文件夹 绝对路径
img_list = os.listdir(i_dir) # 获取类别文件夹下所有png图片的路径
for i in range(len(img_list)):
if not img_list[i].endswith('jpg'): # 若不是png文件,跳过
continue
#label = (img_list[i].split('.')[0] == 'cat')? 0 : 1
label = img_list[i].split('.')[0]
# 将字符类别转为整型类型表示
if label == 'cat':
label = '0'
else:
label = '1'
img_path = os.path.join(i_dir, img_list[i])
line = img_path + ' ' + label + '\\n'
f.write(line)
f.close()
if __name__ == '__main__':
gen_txt(train_txt_path, train_dir)
gen_txt(valid_txt_path, valid_dir)运行脚本之后就在./data/catVSdog/目录下生成train.txt和test.txt两个索引文件。
1.2 构建Dataset子类
PyTorch 加载自己的数据集,需要写一个继承自torch.utils.data中Dataset类,并修改其中的__init__方法、__getitem__方法、__len__方法。默认加载的都是图片,__init__的目的是得到一个包含数据和标签的list,每个元素能找到图片位置和其对应标签。然后用__getitem__方法得到每个元素的图像像素矩阵和标签,返回img和label。
from PIL import Image
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, txt_path, transform = None, target_transform = None):
fh = open(txt_path, 'r')
imgs = []
for line in fh:
line = line.rstrip()
words = line.split()
imgs.append((words[0], int(words[1]))) # 类别转为整型int
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
fn, label = self.imgs[index]
img = Image.open(fn).convert('RGB')
#img = Image.open(fn)
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)getitem是核心函数。self.imgs是一个list,self.imgs[index]是一个str,包含图片路径,图片标签,这些信息是从上面生成的txt文件中读取;利用Image.open对图片进行读取,注意这里的img是单通道还是三通道的;self.transform(img)对图片进行处理,这个transform里边可以实现减均值、除标准差、随机裁剪、旋转、翻转、放射变换等操作。
1.3 加载数据集和数据预处理
当Mydataset构建好,剩下的操作就交给DataLoder来加载数据集。在DataLoder中,会触发Mydataset中的getiterm函数读取一张图片的数据和标签,并拼接成一个batch返回,作为模型真正的输入。
pipline_train = transforms.Compose([
#transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(), #随机旋转图片
#将图片尺寸resize到224x224
transforms.Resize((224,224)),
#将图片转化为Tensor格式
transforms.ToTensor(),
#正则化(当模型出现过拟合的情况时,用来降低模型的复杂度)
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
#transforms.Normalize(mean = [0.485, 0.456, 0.406],std = [0.229, 0.224, 0.225])
])
pipline_test = transforms.Compose([
#将图片尺寸resize到224x224
transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
#transforms.Normalize(mean = [0.485, 0.456, 0.406],std = [0.229, 0.224, 0.225])
])
train_data = MyDataset('./data/catVSdog/train.txt', transform=pipline_train)
test_data = MyDataset('./data/catVSdog/test.txt', transform=pipline_test)
#train_data 和test_data包含多有的训练与测试数据,调用DataLoader批量加载
trainloader = torch.utils.data.DataLoader(dataset=train_data, batch_size=64, shuffle=True)
testloader = torch.utils.data.DataLoader(dataset=test_data, batch_size=32, shuffle=False)
# 类别信息也是需要我们给定的
classes = ('cat', 'dog') # 对应label=0,label=1在数据预处理中,我们将图片尺寸调整到224x224,符合VGGNet网络的输入要求。均值mean = [0.5, 0.5, 0.5],方差std = [0.5, 0.5, 0.5],然后使用transforms.Normalize进行归一化操作。
我们来看一下最终制作的数据集图片和它们对应的标签:
examples = enumerate(trainloader)
batch_idx, (example_data, example_label) = next(examples)
# 批量展示图片
for i in range(4):
plt.subplot(1, 4, i + 1)
plt.tight_layout() #自动调整子图参数,使之填充整个图像区域
img = example_data[i]
img = img.numpy() # FloatTensor转为ndarray
img = np.transpose(img, (1,2,0)) # 把channel那一维放到最后
img = img * [0.5, 0.5, 0.5] + [0.5, 0.5, 0.5]
#img = img * [0.229, 0.224, 0.225] + [0.485, 0.456, 0.406]
plt.imshow(img)
plt.title("label:".format(example_label[i]))
plt.xticks([])
plt.yticks([])
plt.show()
2. 搭建VGGNet神经网络结构
class VGG(nn.Module):
def __init__(self, features, num_classes=2, init_weights=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 500),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(500, 20),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(20, num_classes)
)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_features(cfg: list):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
cfgs =
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: model number not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_features(cfg), **kwargs)
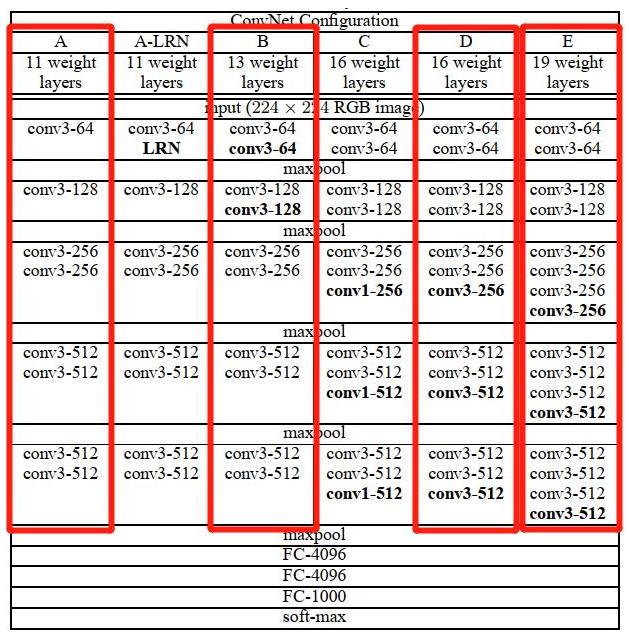
return model首先,我们从VGG 6个结构中选择了A、B、D、E这四个来搭建模型,建立的cfg字典包含了这4个结构。例如对于vgg16,[64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']表示了卷积层的结构。64表示conv3-64,'M'表示maxpool,128表示conv3-128,256表示conv3-256,512表示conv3-512。
选定好哪个VGG结构之后,将该列表传入到函数make_features()中,构建VGG的卷积层,函数返回实例化模型。例如我们来构建vgg16的卷积层结构并打印看看:
cfg = cfgs['vgg16']
make_features(cfg)
定义VGG类的时候,参数num_classes指的是类别的数量,由于我们这里的数据集只有猫和狗两个类别,因此这里的全连接层的神经元个数做了微调。num_classes=2,输出层也是两个神经元,不是原来的1000个神经元。FC4096由原来的4096个神经元分别改为500、20个神经元。这里的改动大家注意一下,根据实际数据集的类别数量进行调整。整个网络的其它结构跟论文中的完全一样。
函数initialize_weights()是对网络参数进行初始化操作,这里我们默认选择关闭初始化操作。
函数forward()定义了VGG网络的完整结构,这里注意最后的卷积层输出的featureMap是N x 512 x 7 x 7,N表示batchsize,需要将其展开为一维向量,方便与全连接层连接。
3. 将定义好的网络结构搭载到GPU/CPU,并定义优化器
#创建模型,部署gpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_name = "vgg16"
model = vgg(model_name=model_name, num_classes=2, init_weights=True)
model.to(device)
#定义优化器
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.0001)4. 定义训练过程
def train_runner(model, device, trainloader, loss_function, optimizer, epoch):
#训练模型, 启用 BatchNormalization 和 Dropout, 将BatchNormalization和Dropout置为True
model.train()
total = 0
correct =0.0
#enumerate迭代已加载的数据集,同时获取数据和数据下标
for i, data in enumerate(trainloader, 0):
inputs, labels = data
#把模型部署到device上
inputs, labels = inputs.to(device), labels.to(device)
#初始化梯度
optimizer.zero_grad()
#保存训练结果
outputs = model(inputs)
#计算损失和
#loss = F.cross_entropy(outputs, labels)
loss = loss_function(outputs, labels)
#获取最大概率的预测结果
#dim=1表示返回每一行的最大值对应的列下标
predict = outputs.argmax(dim=1)
total += labels.size(0)
correct += (predict == labels).sum().item()
#反向传播
loss.backward()
#更新参数
optimizer.step()
if i % 100 == 0:
#loss.item()表示当前loss的数值
print("Train Epoch \\t Loss: :.6f, accuracy: :.6f%".format(epoch, loss.item(), 100*(correct/total)))
Loss.append(loss.item())
Accuracy.append(correct/total)
return loss.item(), correct/total5. 定义测试过程
def test_runner(model, device, testloader):
#模型验证, 必须要写, 否则只要有输入数据, 即使不训练, 它也会改变权值
#因为调用eval()将不启用 BatchNormalization 和 Dropout, BatchNormalization和Dropout置为False
model.eval()
#统计模型正确率, 设置初始值
correct = 0.0
test_loss = 0.0
total = 0
#torch.no_grad将不会计算梯度, 也不会进行反向传播
with torch.no_grad():
for data, label in testloader:
data, label = data.to(device), label.to(device)
output = model(data)
test_loss += F.cross_entropy(output, label).item()
predict = output.argmax(dim=1)
#计算正确数量
total += label.size(0)
correct += (predict == label).sum().item()
#计算损失值
print("test_avarage_loss: :.6f, accuracy: :.6f%".format(test_loss/total, 100*(correct/total)))6. 运行
#调用
epoch = 20
Loss = []
Accuracy = []
for epoch in range(1, epoch+1):
print("start_time",time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
loss, acc = train_runner(model, device, trainloader, loss_function, optimizer, epoch)
Loss.append(loss)
Accuracy.append(acc)
test_runner(model, device, testloader)
print("end_time: ",time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())),'\\n')
print('Finished Training')
plt.subplot(2,1,1)
plt.plot(Loss)
plt.title('Loss')
plt.show()
plt.subplot(2,1,2)
plt.plot(Accuracy)
plt.title('Accuracy')
plt.show()经历 20 次 epoch 的 loss 和 accuracy 曲线如下:
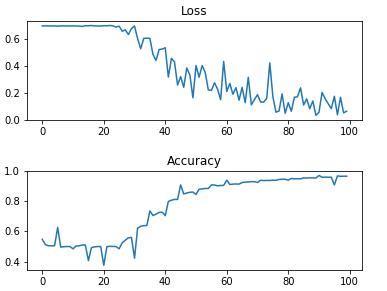
经过20个epoch的训练之后,accuracy达到了94.68%。
注意,由于 VGGNet网络比较大,用CPU会跑得很慢甚至直接卡顿,建议使用GPU训练。
7. 保存模型
print(model)
torch.save(model, './models/vgg-catvsdog.pth') #保存模型VGGNet 的模型会打印出来,并将模型模型命令为 vgg-catvsdog.pth 保存在固定目录下。

8. 模型测试
下面使用一张猫狗大战测试集的图片进行模型的测试。
from PIL import Image
import numpy as np
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = torch.load('./models/vgg-catvsdog.pth') #加载模型
model = model.to(device)
model.eval() #把模型转为test模式
#读取要预测的图片
# 读取要预测的图片
img = Image.open("./images/test_dog.jpg") # 读取图像
#img.show()
plt.imshow(img) # 显示图片
plt.axis('off') # 不显示坐标轴
plt.show()
# 导入图片,图片扩展后为[1,1,32,32]
trans = transforms.Compose(
[
transforms.Resize((227,227)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
#transforms.Normalize(mean = [0.485, 0.456, 0.406],std = [0.229, 0.224, 0.225])
])
img = trans(img)
img = img.to(device)
img = img.unsqueeze(0) #图片扩展多一维,因为输入到保存的模型中是4维的[batch_size,通道,长,宽],而普通图片只有三维,[通道,长,宽]
# 预测
# 预测
classes = ('cat', 'dog')
output = model(img)
prob = F.softmax(output,dim=1) #prob是2个分类的概率
print("概率:",prob)
value, predicted = torch.max(output.data, 1)
predict = output.argmax(dim=1)
pred_class = classes[predicted.item()]
print("预测类别:",pred_class)
输出:
概率: tensor([[7.6922e-08, 1.0000e+00]], device='cuda:0', grad_fn=<SoftmaxBackward>)
预测类别: dog
模型预测结果正确!
好了,以上就是使用 PyTorch 复现 VGGNet 网络的核心代码。建议大家根据文章内容完整码一下代码,可以根据实际情况使用自己的数据集,并对网络结构进行微调。
完整代码我已经放在了 GitHub 上,地址:
https://github.com/RedstoneWill/CNN_PyTorch_Beginner/blob/main/VGGNet/VGGNet.ipynb
手撕 CNN 系列:
手撕 CNN 经典网络之 LeNet-5(MNIST 实战篇)
手撕 CNN 经典网络之 LeNet-5(CIFAR10 实战篇)
手撕 CNN 经典网络之 AlexNet(PyTorch 实战篇)
如果觉得这篇文章有用的话,麻烦点个在看或转发朋友圈!
推荐阅读
(点击标题可跳转阅读)
重磅!
AI有道年度技术文章电子版PDF来啦!

扫描下方二维码,添加 AI有道小助手微信,可申请入群,并获得2020完整技术文章合集PDF(一定要备注:入群 + 地点 + 学校/公司。例如:入群+上海+复旦。

长按扫码,申请入群
(添加人数较多,请耐心等待)
感谢你的分享,点赞,在看三连 
以上是关于VGGNet随笔的主要内容,如果未能解决你的问题,请参考以下文章
手撕 CNN 经典网络之 VGGNet(PyTorch实战篇)