Python入门 - 2(真0基础)
Posted nick-j-li
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python入门 - 2(真0基础)相关的知识,希望对你有一定的参考价值。
一 前言
上一章说了那么多,不知道大家是否有跃跃欲试的冲动。说实话,编程就像英语一样,只是一门语言,如果不用出来,能力会衰退。就像荒岛没人对话,时间长了很可能就不会说话了。如果不能自己写出来,永远就是别人的东西。这就是为什么很多人看了网络上那么多视频都学不会的原因。是的,可能你也正在看,甚至跟着视频将代码敲了下来,但是这些都是别人的。试着问自己一下,关了视频再写一遍,能做到吗?大概率是做不到的。。。怎么办?多写?写到吐?NO!!! base on project的学习计划才是有意义的。盲目多写,或者盲目写重复的内容只能让你记住了一部分的写法,思路不是你的。找一个目标,你喜欢的方向,往那个方向去研究,找那个方向的project去做。举个例子,我喜欢炒股炒外汇,那就去看一些关于量化交易系统的书或者文章,试着写一个自动买卖的小系统。为什么要这样做?因为持久的学习需要满足感,需要自信心。当自己写的程序能跑起来时,那种快感是难以言喻的。当然,无论选择哪个方向,基础还是必须打好的,没有这些基础,根本无法支撑你走得更远,更无法达到你的目标,所以,加油!坚持!
二 三元运算(装13用!!!~~~)
上一章的流程控制,是不是一个if...else...就得分好几行来写,难道就不能有一行写完的表达方式?必须有啊,写出来还特别有逼格。别人几百行实现的功能,几十行就实现了,是不是短小精悍?
# 正常写法 if 1 < 2: val = 1 else: val = 2 # 三元运算 val = 1 if 1 < 2 else 2
三 字符编码
大家在使用电脑的过程肯定都见过一个现象,就是“乱码”。好好地解压一个文件,名字变成了乱码。或者打开一个word文档,里面是各种不知名的字符。这些问题大概率都是和字符编码相关的。最形象的说法就是,你有一把锁配套一把钥匙,锁只能用你的钥匙来开。要是别人用其他钥匙硬塞进去,只会弄坏锁本身。所以,什么锁配什么钥匙,“上锁”“解锁”都用同一把钥匙就不会出问题了。
1、为什么需要有字符编码?
无论你是否科班出身,是否有过编程的经验,只要你懂点电脑的基本常识,你大概率都会知道计算机只认识二进制,也就是一堆“010101010101”。那西方的英语、西班牙语,东方的国语、韩语、日语等语言,计算机又是怎么明白的呢?就拿Python作为例子,为什么我们写英语,电脑能够执行?如果说计算机只懂得0和1,是不是会像摩斯密码一样,存在一个对照表将我们输入的内容转换成0和1?从而破译出答案来?是的,这就是字符编码存在的价值。下面是各种字符编码的简介,是按照【时间顺序】逐一介绍。
2、ASCII码(American Standard Code for Information Interchange)
最初的版本大概长这个样子↓↓↓
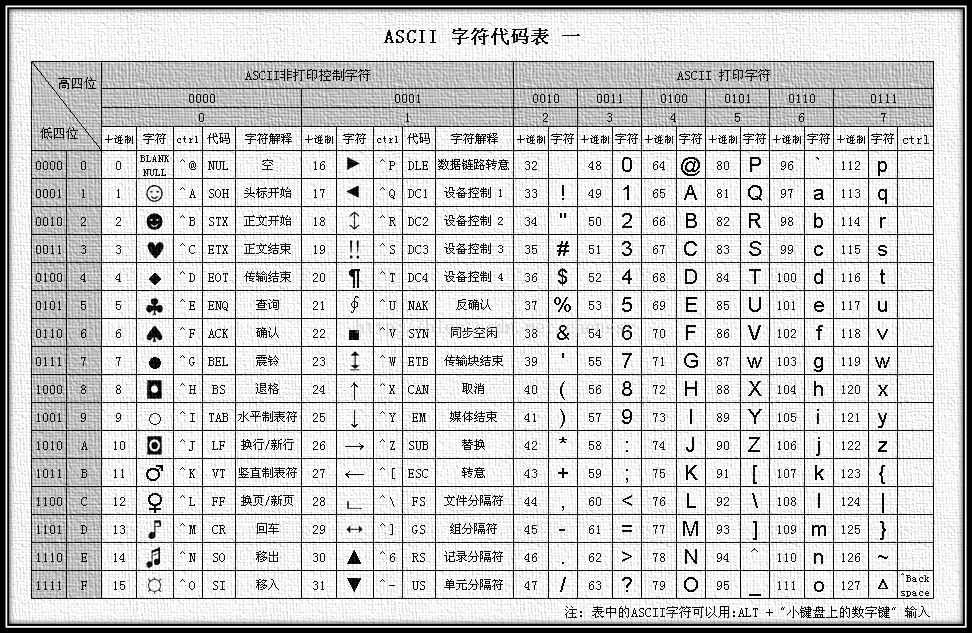
ASCII码最早在美国被提出,当时发明者根本就没想过以后中国人也能用上电脑,所以除了英文字母和一些特殊字符能够对应上,中文和其他语言均没有对应。后来又拓展了一些,但依然没有支持其他语言的对应↓↓↓
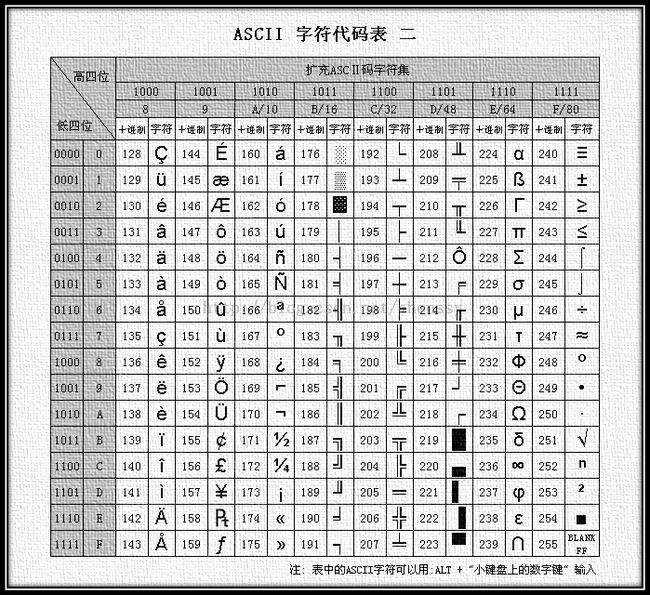
3、GBK(Guo Biao Kuozhan国标扩展的首字母,不要Z可能是因为不好读吧~~~>.<)
从0开始到255,一共256位就是ASCII码的极限了,但就连一个边旁部首都没有,中国人不乐意啊,中国人也会强大啊,凭什么我们不能有自己的一席之地?一怒之下,自己搞了个GBK,把中文收编进去,而且不能和ASCII码有冲突。紧接着其他国家的各种码也出来了。韩国的EUC-KR,日本的Shift_JIS等等。
4、Unicode
码是越来越多了,难道以后每个电脑都要预装这么多不同的码么?更重要的是,预装一个别的国家的东西,那种不安全感,就像要强迫出厂的苹果手机预装小米软件一样。所以,针对这种需求,万国码出现了。终于有一个看上去啥都有的百科全书了。但是有一部分人开始不高兴了。你可能不知道,ASCII码对于英语字符是非常节省的,一个字符只需要1个Bytes,也就是1个B。而在Unicode里,为了配合其他语言,一个英语字符变成了2个B。无端端多了一倍。。。一两个字符不是问题,但问题是,多起来怎么办?!在那个年代,内存是极其珍贵的,网络是很慢的,内容多了,肯定慢。我本来可以存的内容,因为Unicode这么一搞,能存的东西就减半了。有解决方案吗?继续看下去。。。
Bit,计算机中最小的表示单位 8Bit = 1Bytes 字节,最小的存储单位,1Bytes缩写为1B 1KB = 1024B 1MB = 1024KB 1GB = 1024MB 1TB = 1024GB 1PB = 1024TB 1EB = 1024PB 1ZB = 1024EB 1YB = 1024ZB 1BB = 1024YB
5、UTF-8(Unicode Transformation Format)
为了节约内存,UTF-8诞生了,对Unicode进行了一些加工,将英文字母编写成1个字节,将汉字编写成3个字节,对非常生僻的字符才用4-6个字节。这样解决了英文字母占用内存倍增的问题,也让各国的编码整合了。算是现时最完善的编码了。但是这一切都是按时间顺序发生进而完善的,那原本那些已经用GBK、ASCII编码存好的程序怎么办?如果硬生生换编码,从硬盘读取到内存时程序肯定会出现各种异常,可能冒这个险吗?根本不可能!!!几百万行代码重新写吗?想太多!!!那怎么办?(咋问题这么多(-_ -!!!))其实上面的内容已经有答案了。Unicode就是答案。反正Unicode整合了这么多个国家的编码,只要用Unicode这把万能钥匙去解锁,就一定能不损坏锁又能开锁。现在的计算机基本上是这么干的,在内存中用的是Unicode,在硬盘中和传输中用的是UTF-8。举个例子,我们打开一个文件,文件会进入内存,这个时候会转换为Unicode。然后在保存时,文件会进入硬盘,这个时候就会转换成UTF-8。
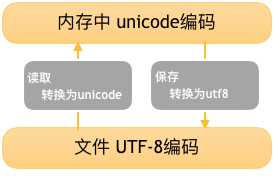
6、字符编码的转换
总结:什么钥匙开什么锁。用什么编码存到硬盘的,就得用什么编码取出来。
最后抛出一个问题。假设现在有两台电脑,一台是日本产的,预装有Unicode和Shift-JIS日本编码,一台是中国产的,预装有Unicode和GBK中文编码。如果在中国产的电脑上编写好文件,在日本产的电脑上打开,能显示中文吗?
答案是可以的。文件会先从GBK转换成Unicode存到内存里,可以读取到中文,自然可以显示中文。
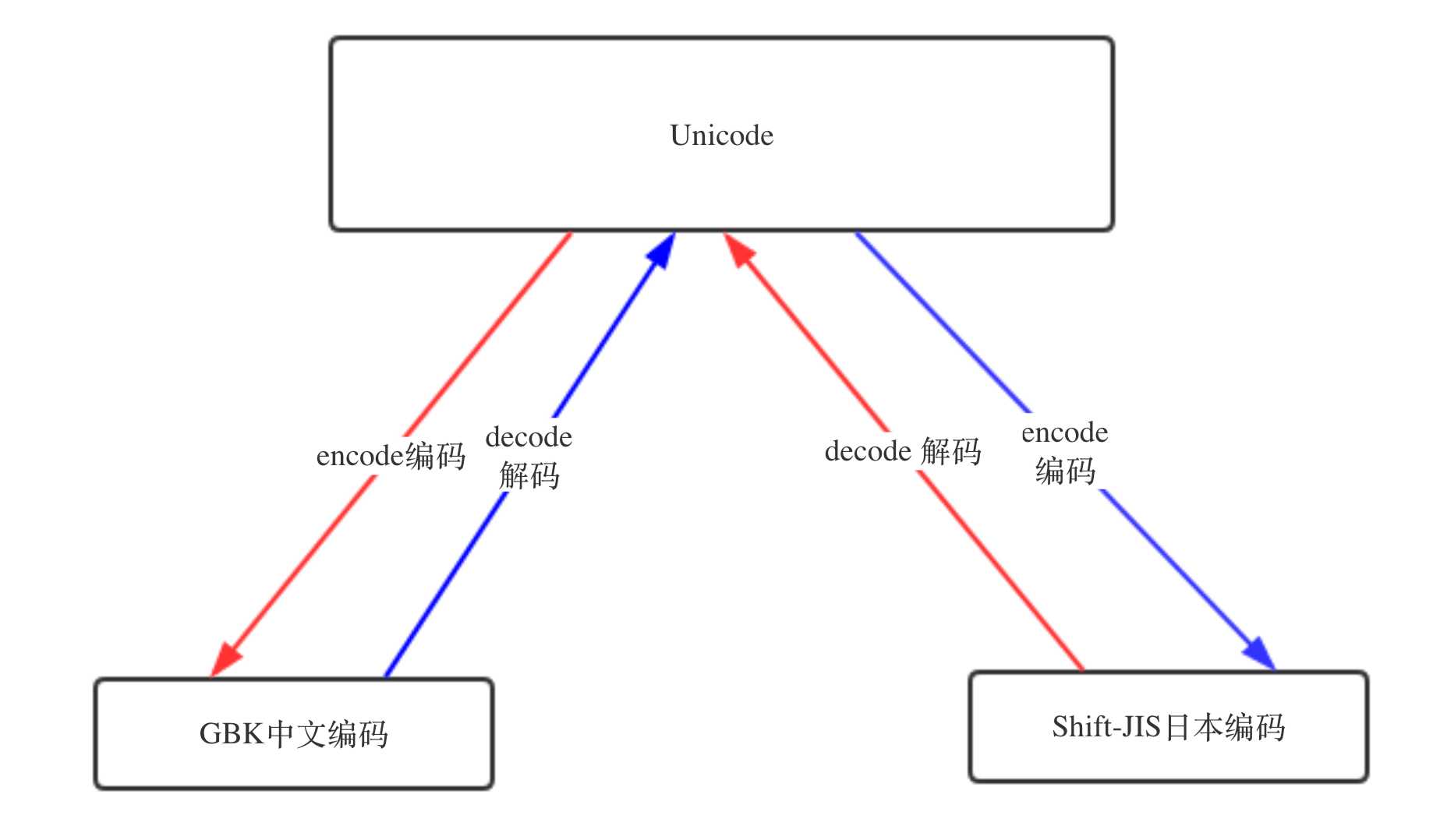
四 文件处理
读写文件在Python中是常见的事情。因为暂时不知道数据库如何使用,所以很多临时的数据只能够格式化存到文档中(也就是存到硬盘里,不用怕存到内存一断电就没了)。以下是一般的文件操作思路:
#1 打开文件,得到文件内容并赋值给一个变量 #2 修改文件内容,增删改查等方式 #3 将修改的文件内容存回文件 #4 关闭文件
1、读文件,“r”模式
#1 打开文件nick.txt,并赋值给变量f,方便后续操作用 f = open(‘nick.txt‘, ‘r‘, encoding=‘utf-8‘) # 默认打开模式就为r #2 通过read命令获得变量f的内容,并赋值给变量data,方便对内容进行增删改查 data = f.read() # 读取所有内容 data = f.readline() # 读取一行内容 data = f.readlines() # 读取每一行内容,并存放在列表 #3 关闭文件 f.close()
2、写文件,“w”模式
#1 以“w”模式打开文件nick.txt,并赋值给变量f,方便后续操作用 f = open(‘nick.txt‘, ‘w‘, encoding=‘utf-8‘) #2 通过write命令覆盖变量f的内容 f.write("01010101") # 注意!原内容会被覆盖! f.writelines("0101010101") # 当需要将多行内容写入txt文件时用这个 #3 关闭文件 f.close()
3、加内容,“a”模式
#1 以“a”模式打开文件nick.txt,并赋值给变量f,方便后续操作用 f = open(‘nick.txt‘, ‘a‘, encoding=‘utf-8‘) #2 通过write命令覆盖变量f的内容 f.write(" 01010101") # 注意!新内容会追加在原内容的后面! #3 关闭文件 f.close()
五 函数(终于要迈入一个稍微有点难度的部分喇~~~散花~~~)
能学到这里,证明你对最最最基础的语法已经有了一定的了解。现在写几十行甚至上百行代码实现一些基本功能已经不是问题了。或许你已经感受到,写代码时经常会重复用到一些语句,而且频次还较高,这样看起来很low,如果能有办法将这些常用的语句整合到一个地方,然后每次调用这个地方的内容,就不用重复写同一些代码了,对不?所以函数就出现了!!!这里的函数不是数学中常说的函数,而是这类重复功能归集到一起的统称。
这部分之所以说是上升了一个难度,并不是说内容难,而是因为你如果不用函数,依然可以实现功能。而用函数能让代码优雅,更容易被维护。这是一种思维层次的改变,并不是你学懂了就能用出来的。换句话说,如果你没有编程经验,你怎么知道某些方法会重复?你怎么知道某些代码会被经常使用?所以没有经验的时候,是无法顺利用出函数的。对于入门者,这是一道坎!只有告诉自己,即使代码low,先写,重复就重复,通过第二版去将重复的内容写成函数,不断修改和优化代码。切忌一步登天。也不要因为写不出函数而气馁。说到底,就是积累得还不够而已。解释完函数存在意义,我们一起来看看函数的分类。
1、函数分类
# 使用函数前必须要先定义函数,再使用。就像先有了一只篮球,才能开始一场篮球比赛一样。定义函数,可以是内置的,也可以是自定义的: #1 内置函数 还记得之前我们在人与机器交互那小节中提及的input功能吗?其实这里的input就是一种函数,而且是被内置好的,也就是启动Python时就会附带定义好的。这是为了方便开发时,不用再针对一些简单的功能重复定义。对于内置函数,我们可以拿来就用而无需事先定义,见下表。 #2 自定义函数 由于内置函数的功能都相对简单,并无法应对复杂的需求。这就需要我们自己根据需求,事先定制好我们自己的函数来实现某种功能,在遇到应用场景时,调用自定义的函数即可。例如在一次计算中,我们可以定义一个函数来处理加法,只需要将内容传进去,就会返回加法的结果。
以下是常用的内置函数↓↓↓

2、如何自定义函数
# 逻辑大概是这样的: def 函数名(参数1,参数2,参数3,...): # 定义了函数,函数名最好能够精炼概括要做的事情 ‘‘‘注释‘‘‘ 函数体 # 具体函数要做的事情,函数的主体内容 return 返回的值 # 让函数结束时返回一个东西,可以返回值,甚至函数,遇到return语句,函数就会停止执行并返回结果
# 举个栗子 def id_verification(account, password): ””” 定义了一个id验证函数用于验证输入账号是否正确。 :param account: 账号 :param password: 密码 :return: 认证结果 ””” if account == ‘nick‘ and password == ‘1234‘: return ‘Welcome back!‘ else: return ‘invalid account or password‘
3、调用函数
# 定义了函数就是为了用,不然定义来干嘛对不对?那如何调用呢?就像上面的栗子,如果要调用id_verification函数,可以这样写 account = input(‘account:‘).strip() password = input(‘password:‘).strip() id_verification(account, password) # 调用函数,并传入account和password两个参数,如果仅仅只有id_verification,没有括号,函数是不会被调用的 # 调用函数后,参数会被送进函数进行运算。最终得出结果取决于自定义函数的返回值。有时候定义函数不一定要传入参数。像下面的例子,括号里是空的。
4、函数参数
# 谈到函数的参数,就要知道什么叫实参和形参,简单理解即可 def calc(x, y): # 这里的x和y就是形参,等着别人赋值给自己 res = x ** y return res c = calc(1, 2) # 这里的1和2就是实参,等着传值给别人 print(c)
# 了解完什么是形参和实参后,我们来看看一些更实用的例子。 def register(name, age, country): # 定义一个函数,让用户传入基础资料并打印 print("name:", name) print("age:", age) print("country:", country) register("nick", 18, "China") ... # 关键参数 # 如果100个用户都是来自于中国,那其实可以设置一个默认值,这个时候就出现了关键参数 def register(name, age, country="China"): print("name:", name) print("age:", age) print("country:", country) register("nick", 18) # 这样就不用输入了~100个用户都省了事 register("alex", 18, country="USA") # 当出现一个特殊的,这样写就好了 ... # 非固定参数 # 对于在定义函数时不知道将来会传什么进来的,可以这样写 def register(name, age, *args, **kwargs): print(name, age, args, kwargs) # 调用函数 register("nick", 18, "China", "Guangdong", course="Python", gender="male") # 输出 # nick 18 (China, Guangdong) {‘course‘= ‘Python‘, ‘gender‘= ‘male‘} ... # *args会生成一个元组 # **kwargs会生成一个字典
5、嵌套函数
# 其实在函数里面,也是可以调用已定义好的函数,也可以定义函数。 def f1(): # 定义函数f1 print(‘f1‘) def f2(): # 定义函数f2 def f3(): # 在函数f2内定义函数f3 print(‘f3‘) f3() # 执行函数f3,如果没有这一行,则不会执行函数f3 print(‘f2‘) def f4(): f1() f2() # 调用已定义好的函数f2 # 这种函数套函数,就是嵌套函数,在以后的编程会较为常用,很锻炼逻辑的哦~
6、高阶函数
# 函数里面的参数不仅可以接收变量,也可以接收其他函数,一起看这个高阶函数例子 def add(x, y, func): print(func(x) + func(y)) # 两数绝对值相加 add(1, 2, abs) # abs是内置函数,代表绝对值
7、递归
# 如果一个函数在内部调取自己,就叫递归 def calc(n) print(n) if int(n / 2) == 0: return n return calc(int(n / 2)) calc(10) #输出 10 5 2 1
8、名称空间
# 上面的例子里存在一个问题,我们可以直接输入f1(), f2()或f4()来调用函数,但我们无法直接输入f3()调用函数f3,这样会报错,那是为什么呢? # 简单来说,就是因为函数f3在函数f2内,函数f3在局部,并不是全局。在全局的位置查看不了局部,但是在局部可以查看全局。就像上面的函数f4里,可以在局部调用全局的函数f1和f2。 # 复杂来说,就需要引入名称空间这个新名词。名称空间储存的是变量名和变量值的关系。例如n = 1,名称空间就储存着n和1的关系。 # 计算机在查找名称空间的过程是有顺序的,先查看局部的名称空间,然后才是全局的名称空间,这就是为什么当计算机在找到局部名称空间时,可以找到全局名称空间。反之则不可以。属于先后顺序问题! # 完整来说,整个名称空间查找顺序可以简写为4个字母:LEGB 也称为作用域。 Locals 是函数内的名称空间 Enclosing 上一级嵌套函数的名称空间(闭包中常见,后面会讲闭包) Globals 全局变量,函数定义所在模块的名称空间 Builtins 内置模块的名称空间
9、匿名函数
# 记住一个词,叫lambda;lambda函数常与其他函数搭配使用,从而节省代码量,看一下下面的例子。 # 一般来说,如果要计算一堆数各自的平方,我们需要先定义一个计算平方的函数,然后再通过map内置函数,将数导进去进行平方,看代码↓↓↓ def square(x): return x ** 2 list(map(square, [1, 2, 3, 4, 5])) # 由于是内置函数,不用定义直接使用,得到一个列表 # 如果用lambda,就可以节省一些代码,不用定义square函数,直接套进map函数使用 list(map(lambda x: x ** 2, [1, 2, 3, 4, 5])) # 对于那种不常用的功能,可以通过lambda来节省代码,用完即弃。
10、闭包(开始有点深度了哦~)
# 函数里套了函数,外层函数被调用时,返回了内层函数的内存地址,执行内层函数时,内层函数调用外层函数局部变量的值,这种关系就是闭包。一起看下面这个例子 def outer(x): def inner(y): return x + y return inner # 只返回了inner的内存地址,没有括号,没有执行inner函数 a = outer(2) # 执行了外层outer函数 print(a) 返回了inner的内存地址 print(a(3)) # 执行inner函数,inner函数调用了外层函数的局部变量x = 2 返回了5
11、装饰器(又叫做语法糖,是函数章节较难的部分,很难啃~~做好心理准备,啃下去你就赢了~~>3<)
很多程序已经写完,且经过大量用户使用后,已无其他bug反馈,就可以认为该程序已经能稳定运行了。如果要增加新功能,有一个约定俗成的原则就是不能修改已经稳定运行的程序,只能加,不能改,毕竟谁都不是神,谁都无法保证改了之后是否会产生新的bug,特别是上百万行代码的程序,一旦发现新的bug,debug起来不是开玩笑的。因此,必须要用特定的方法去加入新功能,这个时候就有了装饰器存在的价值。一起看下面这个例子。
# 假设我一开始写了这些代码(假设有几十万行),并且经过了长久验证,已稳定运行。 def bar(): # 定义了函数bar,用来打印某段话。 print("I am bar") # 假设这里是几十万行代码,有各种复杂的逻辑 ...
bar() # 执行该函数
# 如果我突然想加一个功能,希望用户输入自己的名字后,才执行这几十万行代码,我不能动这些稳定运行的代码。所以我只能用装饰器,加功能。我们先感性认识一下装饰器长什么样子。接下去会一步一步解释。 def login(func): # 在原本的几十万行代码上,加入了这么一个【装饰器】(函数) def collect_name(*args, **kwargs): # 函数里套了函数 input("name:") # 让用户输入名字 return func(*args, **kwargs) # 返回了外层函数参数名的函数(与闭包概念类似) return collect_name # 返回内层函数的内存地址,注意这里没有括号,所以是返回内存地址,而不是执行函数 @login # 语法糖,让下面的函数不止运行自己,还运行与语法糖同名的函数 def bar(): # 定义了函数bar,用来打印某段话。 print("I am bar") # 假设这里是几十万行代码,有各种复杂的逻辑 ... bar() # 执行该函数,调用bar函数的同时,调用login函数,这样就做到了没有动原本的代码,又增加了新功能的目的
# 下面我们来一步一步分析这个运行过程,请按照【数字顺序】阅读,建议多看几遍,一遍是看不懂的 def login(func): # 2、因为语法糖的原因,这里的函数绑定成login(bar) def collect_name(*args, **kwargs): # 5、执行了login函数内部的collect_name函数 input("name:") # 6、让用户输入名字 return func(*args, **kwargs) # 7、执行bar函数 return collect_name # 3、不执行内部函数,直接将collect_name内存地址(不带括号时)返回 @login # 1、程序经过了上面的函数login,再来到这个语法糖。这个语法糖的目的是绑定下面这个函数bar,当执行下面这个函数bar时,也同时调用与语法糖同名的函数login。 def bar(): print("I am bar") # 8、执行并打印 ... bar() # 4、执行该函数,实际上会执行了函数bar本身,也执行了函数login(bar)(),也就是collect_name函数
四 生成器和迭代器
# 生成器 g = (x * x for x in range(10)) >>>next(g) 1 >>>next(g) 4 >>>next(g) 9 >>>next(g) 16 >>>next(g) 25 # 如果所有值都需要next去调出,会疯掉的吧。不如用for,值用完了还不会报错 g = (x * x for x in range(10)) for n in g: print(n)
# 迭代器 # 判断一个对象是否为可迭代对象 from collections import Iterable a = isinstance([], Iterable) print(a) # 返回True # 判断一个对象是否为迭代器 from collections import Iterable b = isinstance([], Iterator) print(b) # 返回False # 将其转成迭代器,用itor函数 from collections import Iterable b = isinstance(iter([]), Iterator) print(b) # 返回True
五 模块
终于送走了函数,说明在中级的路上已越走越稳了。别忘记多做project,将上面的内容用在实战中。有一件事是可以肯定的,如果你曾经用过某个知识点,并且解决了问题,这个知识点会记得比其他都要牢固。不断用,不断试错。加油!!!
模块这一部分,简直就是Python的精华所在。为什么近年来Python越来越多人用?那是因为不同的功能模块越来越完善。(不禁感叹这个世界牛人真多啊~~~)大神们通过自己的努力,将写好的Python文件打包,放到网上,让大家随意下载使用。这些模块覆盖的细分领域越来越广,从金融、医疗、数学到高新科技,几乎一切你能想象的领域都有现成的模块可以下载。大家如果想多了解更多模块可以到这个网址https://pypi.python.org/pypi,根据自己喜欢的方向去寻找吧~~或许在不久的将来,你也能上传你的作品。
模块的存在大大节省了我们的开发时间,毕竟大神已经为我们准备好的工具,不用白不用,对吧?那我们先来看看模块分了几种:
1、模块分类
# 内置标准模块。有一些模块在安装Python时就会一并装入。可以理解为官方版本的模块。 # 第三方开源模块。由世界各地的大神撰写并上传,我们可以通过Pycharm等下载安装使用。 # 自定义模块。就是自己写出来的程序,自己打包,自己用。
2、模块调用
# 有不少表达式可以用来导入模块,根据不同情况而定,常用的有以下几种: import module from module import settings from . import module
# 是时候动起来了。快!动手打开Pycharm,建个文件夹printer,文件夹里新建两个py文件,分别写入以下内容。如下 # printer文件夹 # test.py文件 from hello import say_hi say_hi() # hello.py文件 def say_hi(): print("hello world") # 概括点来说,这两个文件其实可以看作是一个程序,目的是打印某句话。test文件作为程序入口,调用其他模块来辅助实现这个功能。
# 包(Package) # 上面的例子,我们用了一个文件夹,两个py文件,实现了打印某句话的功能程序。这类打印功能我们就统一放在printer这个文件夹里。像这样一个文件夹里存放多个模块文件,就称这个文件夹为【包】 # 上面的printer文件夹,为了能成为包,还需要在文件夹中加入__init__.py文件,从而告诉程序这是个包 # 像一些比较大型的项目,如微信等,也是将不同功能用不同包分开,例如朋友圈功能和聊天功能分开等。。然后包和包之间互相调用来实现功能。这是为了更加方便运维团队维护代码
# 为了调取不同包里的模块,有时候需要铺设好一条路。就像铁路一样,通了才有火车的身影 # 下面的例子,为了能够读取到另外一个文件夹account下的json文件,我们需要铺出一条路给程序,为此需要用到两个内置模块,os和sys,下面就导入一下 import sys import os # 当前文件路径向上返回两级,将路径赋值于DIR(大写表示常量,代表不变) DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # 将这条路加入到环境变量里面,这样Python才会去找这条路找文件 sys.path.append(DIR) # 往DIR路径后加入account和json.json,拼接出json文件的完整路径,可以直接用于open os.path.join(DIR, ‘account‘, ‘json.json‘)
3、time模块
# time模块是常常用来显示、计算各种格式的时间,下面是几个常用的,我们暂时不求多,只求用得着 time.time() # 返回当前时间的时间戳(就是一串数字) time.sleep() # 延迟执行,括号里写上时间即可,单位为秒。 time.strftime() # 举例:time.strftime("%Y-%m-%d %X", time.localtime()) # 输出‘2018-07-06 00:00:00‘
4、random模块
# 直接来看两个例子 # 生成随机6位数密码,是不是和一些网站登录时要你输入的验证码很像 import random import string numbers = " ".join(random.sample(string.ascii_lowercase + string.digits, 6)) print(numbers) # 这样每次打印都会是不同的6位数字或字母,而且没有空格 # 洗牌功能 import random a = [0, 1, 2, 3, 4, 5] random.shuffle(a) print(a) # 列表a的顺序会被打乱
5、json模块
# json模块可以存储字典,而之前我们常用的txt文件存不了字典 import json data = {"name": "nick", "age": 18} # 将data写入json文件 with open("nick.json", "w", encoding="utf-8") as db: json.dump(data, db) db.close() # 读取nick.json文件中的字典,并赋值给nick_data with open("nick.json", "r", encoding="utf-8") as db: nick_data = json.load() db.close()
6、logging模块
# logging模块是非常常用的生成日志的模块。程序执行时,如果没有日志记录,有很多信息会有缺失,甚至不清楚谁登陆过,谁做过什么,这样是非常不安全的。因此,这个模块十分十分重要。看下面的步骤,可以配置好不同的日志内容 # 下面这个例子,是配置日志内容的过程,目的是在文件和Pycharm消息框中同时输出内容,不妨复制到Pycharm试一试 import logging # 1. 生成logger对象 logger = logging.getLogger("web") # 相当于给日志起了个名字web logger.setLevel(logging.DEBUG) # 如果不设置默认级别是WARNING,此为全局 # 2. 生成handler对象 ch = logging.StreamHandler() # 输出到屏幕 ch.setLevel(logging.INFO) # 给不同输出途径设置不同的输出日志级别,设置级别不能比全局的低 fh = logging.FileHandler("web.log") # 输出到文件 fh.setLevel(logging.WARNING) # 给不同输出途径设置不同的输出日志级别,设置级别不能比全局的低 # 2.1 把handler对象绑定到logger logger.addHandler(ch) logger.addHandler(fh) # 3. 生成formatter对象,用于自定义格式化输出内容 # 3.1 把formatter对象绑定handler对象 file_formatter = logging.Formatter(‘%(asctime)s - %(name)s - %(levelname)s - %(message)s‘) console_formatter = logging.Formatter(‘%(asctime)s - %(name)s - %(levelname)s - %(lineno)d - %(message)s‘) ch.setFormatter(console_formatter) fh.setFormatter(file_formatter) logger.error(‘test log‘) logger.error(‘test log 2‘)
7、re模块
# 正则表达式也是一个常用的模块,甚至有的Python开发书一上来第一章第一节就讲正则表达式。爬虫等工序到最后需要用正则表达式格式化输出内容。不妨通过下面的例子看看,复制到Pycharm上玩一玩吧。不过,看完后尽量自己写一遍哦! import re # re.match 从头开始匹配 s = ‘abc1d3e‘ b = re.match(‘[0-9]‘, s) # 要求第一个值必须是数字,否则返回None print(‘b:‘, b) f = ‘12bdfd‘ c = re.match(‘[0-9]‘, f) # 默认只能匹配到一个值 print(‘c:‘, c) # re.search 匹配包含,全局匹配 e = re.search(‘[0-9]‘, s) print(‘e:‘, e) # re.findall 匹配上值,然后以列表形式保存 g = re.findall(‘[0-9]‘, s) print(‘g:‘, g) # re.split 以匹配到的字符当做列表分隔符 s = ‘alex22jack23rain31jinxin50|mack-Oldboy‘ print(re.split(‘d+|||W| ‘, s)) # ‘|‘本身作为或标识符,需要前面加‘‘才能用于分隔 s = ‘alex22jack23rainjinxin50|mack-Oldboy‘ print(re.split(‘d+|\\\\|||W| ‘, s)) # ‘‘本身作为标识符需要用4个才能表示一个 # re.sub 匹配字符并替换 s = ‘alex22jack23rain31jinxin50|mack-Oldboy‘ print(re.sub(‘d+|||W‘, ‘_‘, s)) # 替换掉数字 h = ‘9-2*5/3+7/3*99/4*2998+10*568/14‘ print(re.split(‘[-*/+]‘, h)) print(re.split(‘W‘, h)) i = "[email protected]" j = re.fullmatch("[email protected]w+.(com|cn|edu|org)", i) print(j)
以上是关于Python入门 - 2(真0基础)的主要内容,如果未能解决你的问题,请参考以下文章
8. 这篇博客,把python从数值到模块到字典到元组,真python入门复习教程通览