怎么在gridView控件中添加一列
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了怎么在gridView控件中添加一列相关的知识,希望对你有一定的参考价值。
数据库中的表:
代码如下:
public void bind()
SqlConnection con = new SqlConnection(constr);
string comstr = @"declare @sql1 varchar(max)
set @sql1 = 'select name as ' + '公司名'
select @sql1 = @sql1 + ' , max(case hsname when ''' + hsname + ''' then weight else 0 end) [' + hsname + ']'
from (select distinct hsname from Sum1) as a
set @sql1 = @sql1 + ' ,sum(weight) 总计 from Sum1 group by name'
exec(@sql1) ";
SqlCommand com = new SqlCommand(comstr,con);
DataTable table = new DataTable();
SqlDataAdapter adapter = new SqlDataAdapter(com);
adapter.Fill(table);
GridView1.DataSource = table;
GridView1.DataBind();
protected void Page_Load(object sender, EventArgs e)
if (!IsPostBack)
bind();
结果如图:
问题:怎么在公司名后添加一列“重量”
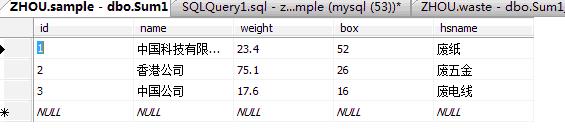
二种,查出数据以后,在datatable里面加一列追问
在datatable里怎么写啊
追答dt.Columns.Add("columName");
本回答被提问者和网友采纳在Spark Dataframe中的列列表中添加一列rowums
我有一个包含多个列的Spark数据帧。我想在数据帧上添加一列,它是一定数量的列的总和。
例如,我的数据如下所示:
ID var1 var2 var3 var4 var5
a 5 7 9 12 13
b 6 4 3 20 17
c 4 9 4 6 9
d 1 2 6 8 1
我想要添加一列来汇总特定列的行:
ID var1 var2 var3 var4 var5 sums
a 5 7 9 12 13 46
b 6 4 3 20 17 50
c 4 9 4 6 9 32
d 1 2 6 8 10 27
我知道如果您知道要添加的特定列,可以将列添加到一起:
val newdf = df.withColumn("sumofcolumns", df("var1") + df("var2"))
但是可以传递列名列表并将它们一起添加吗?基于这个答案基本上是我想要的,但它使用的是python API而不是scala(Add column sum as new column in PySpark dataframe)我觉得这样的东西会起作用:
//Select columns to sum
val columnstosum = ("var1", "var2","var3","var4","var5")
// Create new column called sumofcolumns which is sum of all columns listed in columnstosum
val newdf = df.withColumn("sumofcolumns", df.select(columstosum.head, columnstosum.tail: _*).sum)
这会抛出错误值sum并不是org.apache.spark.sql.DataFrame的成员。有没有办法对列进行求和?
在此先感谢您的帮助。
您应该尝试以下方法:
import org.apache.spark.sql.functions._
val sc: SparkContext = ...
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
val input = sc.parallelize(Seq(
("a", 5, 7, 9, 12, 13),
("b", 6, 4, 3, 20, 17),
("c", 4, 9, 4, 6 , 9),
("d", 1, 2, 6, 8 , 1)
)).toDF("ID", "var1", "var2", "var3", "var4", "var5")
val columnsToSum = List(col("var1"), col("var2"), col("var3"), col("var4"), col("var5"))
val output = input.withColumn("sums", columnsToSum.reduce(_ + _))
output.show()
然后结果是:
+---+----+----+----+----+----+----+
| ID|var1|var2|var3|var4|var5|sums|
+---+----+----+----+----+----+----+
| a| 5| 7| 9| 12| 13| 46|
| b| 6| 4| 3| 20| 17| 50|
| c| 4| 9| 4| 6| 9| 32|
| d| 1| 2| 6| 8| 1| 18|
+---+----+----+----+----+----+----+
干净利落:
import org.apache.spark.sql.Column
import org.apache.spark.sql.functions.{lit, col}
def sum_(cols: Column*) = cols.foldLeft(lit(0))(_ + _)
val columnstosum = Seq("var1", "var2", "var3", "var4", "var5").map(col _)
df.select(sum_(columnstosum: _*))
与Python等价:
from functools import reduce
from operator import add
from pyspark.sql.functions import lit, col
def sum_(*cols):
return reduce(add, cols, lit(0))
columnstosum = [col(x) for x in ["var1", "var2", "var3", "var4", "var5"]]
select("*", sum_(*columnstosum))
如果行中缺少值,则两者都将默认为NA。您可以使用DataFrameNaFunctions.fill或coalesce函数来避免这种情况。
我假设你有一个数据帧df。然后你可以总结除你的ID col之外的所有cols。当你有很多cols并且你不想手动提到像上面提到的所有列的所有列的名称时,这很有用。 This post有相同的答案。
val sumAll = df.columns.collect{ case x if x != "ID" => col(x) }.reduce(_ + _)
df.withColumn("sum", sumAll)
这是使用python的优雅解决方案:
NewDF = OldDF.withColumn('sums', sum(OldDF[col] for col in OldDF.columns[1:]))
希望这会影响Spark中类似的东西......任何人?
以上是关于怎么在gridView控件中添加一列的主要内容,如果未能解决你的问题,请参考以下文章