MySQL Myisam和Innodb的区别
MySQL 区别于其他数据库的很重要的一个特点就是插件式的表存储引擎,其基于表,而不是数据库。由于每个存储引擎都有其特点,最常见的是 Innodb 引擎和 Myisam 引擎,因此我们可以针对每一张表来挑选最合适的存储引擎。
两者区别对照表:
| Myisam | Innodb | |
|---|---|---|
| 5.5版本前默认引擎 | 5.5后默认引擎 | |
| 索引数据结构 | B+树 | B+树 |
| 索引类型 | 非聚集索引 | 聚集索引 |
| 事务 | 不支持 | 支持(提交、回滚) |
| 外键 | 不支持 | 支持 |
| 锁的级别 | 表级锁,不会出现死锁,但并发性能差 | 行级锁,能抗更高并发。同时还通过MVVC多版本控制来提高并发读写性能。可能发生死锁,消耗资源多。如果一条语句无法确定要扫描的范围,也会锁定整张表 |
| CRUD | 查询速度快,在索引树找到物理地址取出数据 | 查询比Myisam慢,可能需要二次查询。行级锁,大量写操作速度快。 |
| 表行数 | 单独记录,如果有where也会全表扫描 | 需全表扫描,select count(*) from table |
| 数据恢复能力 | 数据恢复慢 | 有完善的数据快速恢复能力 |
| delete from table时 | 会直接重建表 | 会一行一行的删除,但是可以用truncate table代替 |
| 适用场景 | 1.查询频繁 2.大量查总count 3.没有事务操作 |
1.并发量大,需要高可用 2.表更新频繁(更改、插入、删除) 3.需要事务 |
聚集索引、非聚集索引查询过程的比较
非聚集索引查询过程
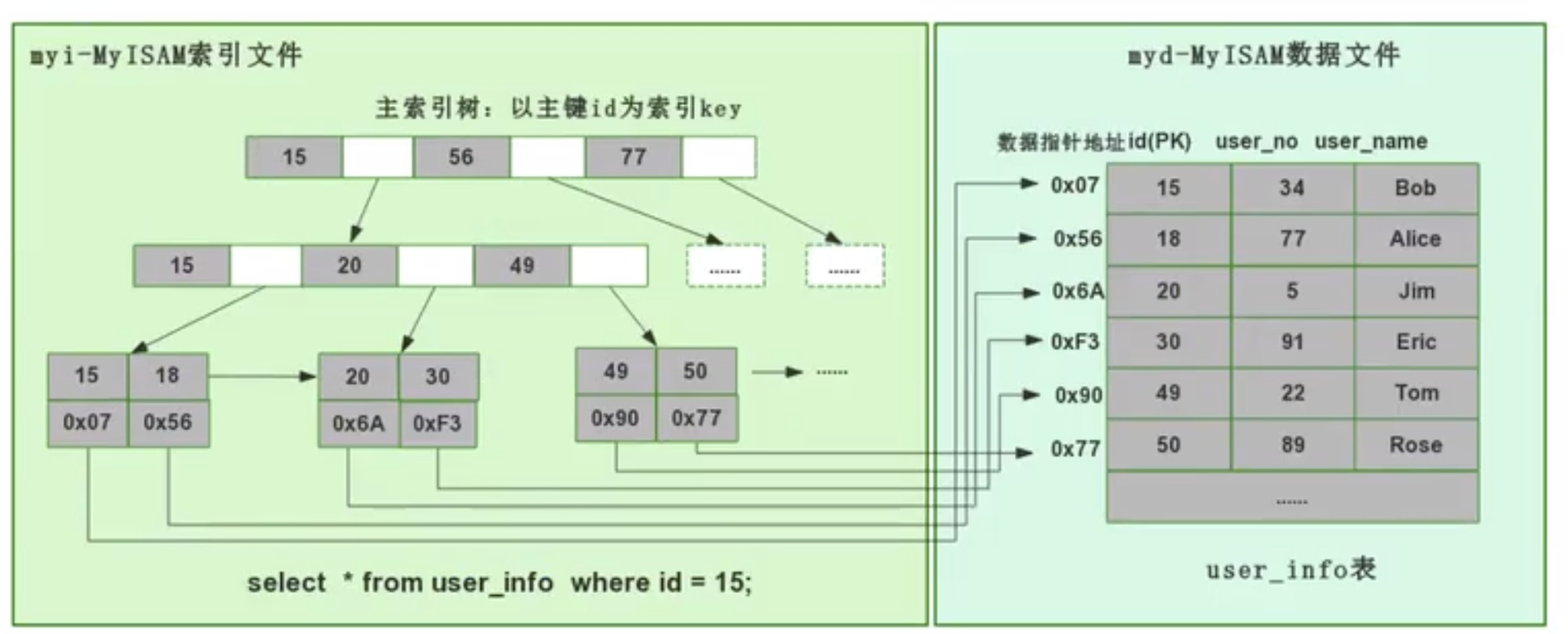
索引和数据是分开的
1,先沿着索引树找到数据的物理位置
2,到物理位置取出数据【又叫数据回行、回表】
当我们为某个字段添加索引时,我们同样会生成对应字段的索引树,该字段的索引树的叶子节点同样是记录了对应数据的物理地址,然后也是拿着这个物理地址去数据文件里定位到具体的数据记录。
注:Myisam支持没有主键的表存在。
聚集索引查询过程
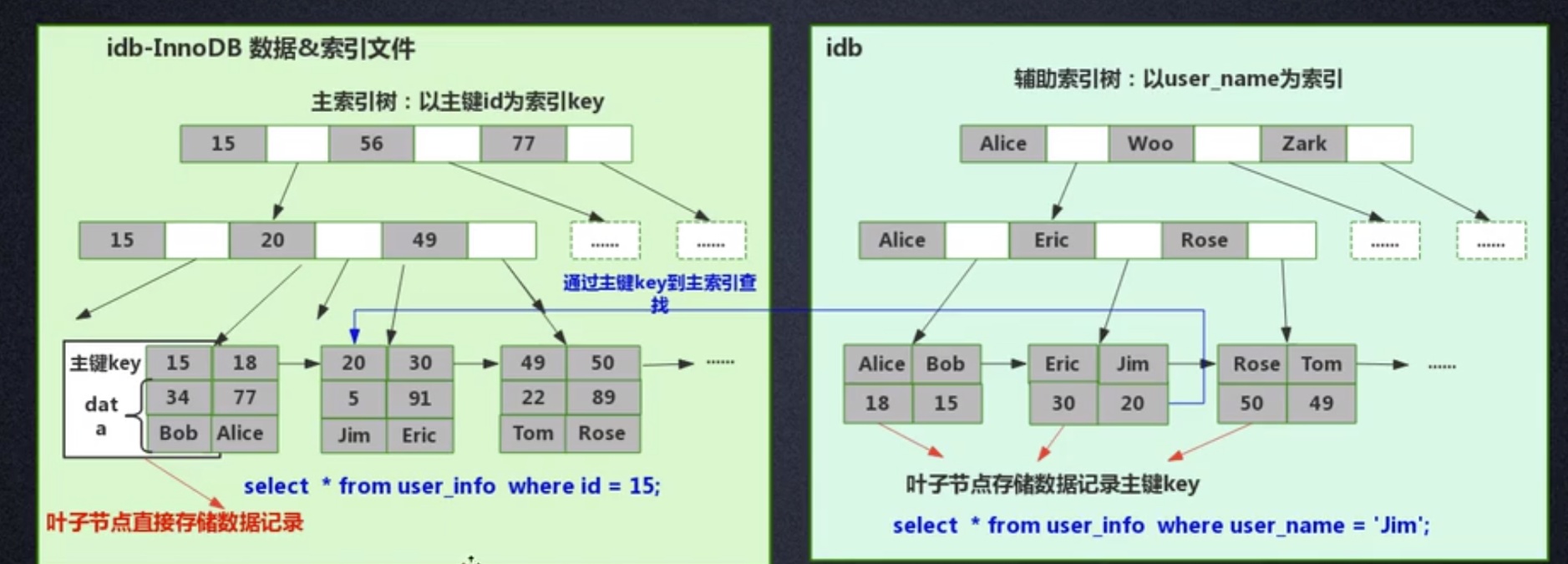
索引和数据是在一起的,在同一个文件中
聚集索引中,数据存储在主键Key索引树的叶子节点上。如果创建了其他列的索引,例如username,也会生成一颗username索引树,但是username索引树的叶子节点只存username和主键Key,不存其他字段,如果就只需要username和Key属性,则取走就可以了【索引覆盖】;如果需要除username和Key之外的属性,需要拿着这个Key沿着主键Key索引树查叶子节点,再取走数据,也就是需要两次查询。
1,用主键Key查询时,找到Key的叶子节点取出数据即可。
2,用其他索引列(username)查询时,在username索引树中找到主键Key,拿着Key再走主键索引树,取走数据。如果只需要username和Key两个属性,那么在username索引树上取走就可以了【索引覆盖】。
注:如果没有指定主键,Innodb会为每行自动生成一个6字节的ROWID作为主键建立主键索引树。
可以做索引的数据结构有:
1,hash表
查询速度非常快,时间复杂度O(1)。hash冲突一般用链地址法解决。
最终被Pass了,原因是对范围查询效率很差,范围查询时要挨个比较。
2,二叉搜索树—>红黑树—>AVL树—>B树—>B+树
二叉排序树平均复杂度log(n),但极端情况会退化为线性表O(n)的复杂度,导致检索性能降低。能范围查询。
红黑树和AVL树通过自旋维持平衡,红黑树有右倾问题,AVL树不存在极端情况,AVL有不错的检索性能又能范围查询,但是为什么Mysql没选AVL?因为AVL每个节点都只存一个数据,而一次磁盘IO读一个数据和读100个数据消耗的时间基本一致,那么应该尽可能在一次磁盘IO中多读一点数据到内存,尽量减少磁盘IO的次数。
B树一个节点存储了多个数据,尽可能的减少了磁盘IO次数,有高效的检索速度,且支持范围查询。时间复杂度h·log(n),h表示树高,n表示一个节点存的数据量。
B树已经不错了,但为了更高的检索性能,推出了B+树。B+树的非叶子节点存的是索引,索引比原数据小,所以一个节点中能存更多的索引,真实数据都在叶子节点,叶子节点之间用链表横向连接,支持范围查询。和B树相比,B+索引树更矮,只需很少的磁盘IO次数,大大提高了检索效率。
为什么不给所有字段都加索引?
给字段加索引以后,查询性能有所提升,那干脆给所有字段都加上索引算了呗,全面提升查询性能!
大戳特戳辽!!原因有二:
1,太多的索引占用更多的磁盘空间和内存空间,索引在调用时被加载到内存,对于大型表可能影响读取性能
2,影响写入的速度(插入/删除/更新),每更新一条记录,也要更新它的索引树。因此,索引越多写的性能越慢。
什么时候需要给表的字段加索引:
1,较频繁的作为查询条件的字段应该创建索引。
2,经常排序、分组的字段应该创建索引。
3,更新非常频繁的字段不适合创建索引。(要更新索引树,影响写性能)
索引为什么能提高排序速度?
MySQL 中的Innodb、Myisam都是基于B+树建立的索引树,B+树的叶子节点用链表横向串联起来,叶子节点本身就是排好序的,从左往右一次递增,所以执行SQL语句排序时取出的数据就是排序好的。
补一个Memory存储引擎
Memory引擎是把数据放在内存中,一旦服务关闭,表中数据就会丢失。Memory默认使用hash索引,有非常快的查询速度[O(1)],但范围查询性能很差。
Memory支持的数据类型有限制,不支持TEXT/BLOB等,锁的级别是表级锁,扛不住很高的并发。它主要用于那些内容变化不频繁的数据,现在MongoDB、Redis等NOSQL数据库越来越流行,Memory存储引擎的使用场景变得越来越少。
其他存储引擎:
MERGE(分区表)
BLACKHOLE(黑洞引擎)
CSV
ARCHIVE