详细的BoltDB学习记录文档
Posted huageyiyangdewo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详细的BoltDB学习记录文档相关的知识,希望对你有一定的参考价值。
最近项目中用到了boltdb这个go开发的key/value 数据库,但是之前并有接触过,所以特意去看了官方,也找了些资料,网上找的资料要不就是官方文档的翻译,要不就是简单的介绍一点,都不是很全,所以这里记录下。话不多说,冲!
本篇文章是参考了官方的文档,内容和官方的基本一致,只是加了些自己的理解在里面而已,大家也可以去直接去看github上的介绍。地址:bolt。
说个实话,去看官方文档的时候,其实还是有好多没有看懂,还是需要自己去看看源码,才能明白其中官方文档说的意思。
1、BoltDB简介
本文介绍的是bolt这个数据库,并不是etcd用到的bbolt。这个一定要注意,别搞混了。
说到这个,随便提一嘴,etcd中的 bbolt 是基于bolt开发而来的,因为 bolt 2019年3月19日就封版了,不再进行维护,所以 etcd 团队就fork了一份,再此基础上进行开发维护。
1.1 BoltDB 基础介绍
BoltDB是一个纯Go语言编写的键值存储数据库,它的设计目标是提供一个简单的纯 Go key/value 存储,并且不会使代码具有多余的特性。BoltDB采用了B+树的数据结构,支持ACID事务,具有快速的读写速度和低延迟的响应时间。BoltDB的特点包括:
1、简单易用:BoltDB的API非常简单易用,只需要几行代码就可以完成数据库的创建、打开、读写等操作。
2、高性能:BoltDB采用了B+树的数据结构,支持快速的读写操作,同时还具有较低的内存占用和CPU负载。
3、可嵌入:BoltDB可以嵌入到应用程序中,不需要单独的数据库服务器,可以方便地进行部署和管理。
4、ACID事务:BoltDB支持ACID事务,可以保证数据的一致性和可靠性。
5、支持并发:BoltDB支持并发读写操作,可以满足高并发的应用场景。
1.2 BoltDB使用场景
从上面的基础介绍我们知道,BoltDB 可以用于下面的场景中,不过具体场景具体分析,BoltDB也有很多局限性。
1、Web 应用程序的持久化存储:BoltDB 可以用于存储 Web 应用程序的配置信息、用户会话信息等。
2、分布式系统的数据存储:BoltDB 可以用于存储分布式系统的元数据、状态信息等。
3、数据分析和机器学习:BoltDB 可以用于存储数据集、模型参数等。
4、消息队列:BoltDB 可以用于存储消息队列的消息、消费者状态等。
我们现在的项目,需要开发一个客户端程序,部署到硬件设备上,部署是由项目的实施人员跟进的。考虑到客户端存储的数据类型有限,并且查询都是基于 key 进行查询,所以 BoltDB 是适合现有的场景的。
说了这么多介绍,接下来就一起学习如何使用 BoltDB 吧。
2、BoltDB 入门
2.1 BoltDB的安装
安装命令如下:
go get github.com/boltdb/bolt/...
执行该命令后,会将 Blot 可执行文件安装到 $GOBIN 路径中。
2.2 打开BlotDB
bolt.Open()打开的数据库路径不存在时,会自动创建。注意:如果路径包含目录,目录必须存在,否则报错。
Bolt 中的顶级对象是一个 DB。它被表示为磁盘上的单个文件,表示数据的一致快照。
要打开数据库,只需使用 bolt.Open() 函数:
package main
import (
"log"
"github.com/boltdb/bolt"
)
func main()
// Open the my.db data file in your current directory.
// It will be created if it doesn\'t exist.
db, err := bolt.Open("my.db", 0600, nil)
if err != nil
log.Fatal(err)
defer db.Close()
...
请注意:Bolt 会在数据文件上获得一个文件锁,所以多个进程不能同时打开同一个数据库。 打开一个已经打开的 Bolt 数据库将导致它挂起,直到另一个进程关闭它。为防止无限期等待,您可以将超时选项传递给Open()函数:
db, err := bolt.Open("my.db", 0600, &bolt.OptionsTimeout: 1 * time.Second)
3、事务
Bolt 一次只允许一个读写事务,但是一次允许多个只读事务。 每个事务处理都有一个始终如一的数据视图()。
单个事务以及从它们创建的所有对象(例如 bucket,key)不是线程安全的。 要处理多个 goroutine 中的数据,则必须为每个 goroutine 启动一个事务,或使用锁来确保一次只有一个 goroutine 访问事务。 从 DB 创建事务是线程安全的。
只读事务和读写事务不应该相互依赖,一般不应该在同一个例程中同时打开。 这可能会导致死锁,因为读写事务需要定期重新映射数据文件,但只有在只读事务处于打开状态时才能这样做。
3.1 读写事务 - db.Update
为了启动一个读写事物,你可以使用DB.Update()函数:
err := db.Update(func(tx *bolt.Tx) error
...
return nil
)
在闭包内部,有一个一致的数据库视图。 那什么时候提交事务,什么时候回滚事务呢?
- 如果返回错误,那么整个事务将回滚。
- 如果函数没有返回任何错误,则提交事务。
注意: 我们使用时,一定要检查db.Update函数返回的错误,因为它会报告任何可能导致事务无法完成的磁盘故障。如果在闭包中返回一个错误,它将被传递。
例子:
package main
import (
"fmt"
"github.com/boltdb/bolt"
)
func main()
db, err := bolt.Open("test/my.db", 0600, nil)
if err != nil
fmt.Printf("open db error, err: %v\\n", err)
return
err = db.Update(func(tx *bolt.Tx) error
b := tx.Bucket([]byte("test"))
if b == nil
b, err = tx.CreateBucket([]byte("test"))
if err != nil
fmt.Printf("tx.CreateBucket failed, err: %v\\n", err)
return err
_ = b.Put([]byte("name"), []byte("xiaoling"))
v := b.Get([]byte("name"))
fmt.Println("name: ", string(v))
return nil
)
if err != nil
fmt.Println("db.Update failed, err:", err)
3.2 只读事务 - db.View
启动一个只读事务,你可以使用DB.View()函数:
err := db.View(func(tx *bolt.Tx) error
...
return nil
)
可以在此闭包中获得数据库的一致视图,但是,在只读事务中不允许进行更新、修改、删除操作。只能检索存储区,检索值,或者在只读事务中复制数据库。
例子:
package main
import (
"errors"
"fmt"
"github.com/boltdb/bolt"
)
func main()
db, err := bolt.Open("test/my.db", 0600, nil)
if err != nil
fmt.Printf("open db error, err: %v\\n", err)
return
err = db.View(func(tx *bolt.Tx) error
b := tx.Bucket([]byte("test"))
if b == nil
return errors.New("not found Bucket: test")
v := b.Get([]byte("name"))
fmt.Println("name: ", string(v))
return nil
)
if err != nil
fmt.Println("db.View failed, err:", err)
3.3 批量读写事务 - db.Batch
每个 DB.Update() 等待磁盘提交写入。我们知道,一条一条数据的插入是比较耗时的,性能肯定不会太高,那有没有像Mysql那样批量插入的方式呢?
DB.Batch()可以实现上面的需求,最小化这种开销,下面一起来看看如何使用。
err := db.Batch(func(tx *bolt.Tx) error
...
return nil
)
并发批量调用可以组合成更大的交易。 批处理仅在有多个 goroutine 调用时才有用。
如果部分事务失败,batch 可以多次调用给定的函数。 该函数必须是幂等的,只有在成功从 DB.Batch() 返回后才能生效。
注意:
看官方文档到这里时,一脸懵逼,说了个啥啊(原谅自己太菜)。
接下来说说自己的理解。如果有错误的地方,恳请指出,轻喷!
官方的意思是DB.Update() 要等到把数据提交到磁盘后才会返回,那如果程序中有大量的DB.Update() 等待执行,每个DB.Update() 都要等待把数据提交到磁盘后才执行,效率不高。哪有什么方式可以优化呢,答案就是: DB.Batch() 。
DB.Batch() 有机会把多个 fn 函数提交到一组,然后一起执行,这个机会是什么意思呢?
在 10 毫秒(默认值)内通过 Batch() 提交的函数,就有可能组成一组,一起执行。
DB.Batch()源码:
func (db *DB) Batch(fn func(*Tx) error) error
errCh := make(chan error, 1)
db.batchMu.Lock()
if (db.batch == nil) || (db.batch != nil && len(db.batch.calls) >= db.MaxBatchSize)
// There is no existing batch, or the existing batch is full; start a new one.
db.batch = &batch
db: db,
// 最多等待 MaxBatchDelay ,默认值为 10 * time.Millisecond
db.batch.timer = time.AfterFunc(db.MaxBatchDelay, db.batch.trigger)
// 重点看这里,这就是把 传进来的 fn 函数追加到 db.batch.calls
// 当 calls 中的数量 大于 MaxBatchSize 时就提交事务,写入磁盘
// 注意,那如果数量不大于怎么办呢,不要慌,db.batch.timer 后会自动执行 fn 函数
db.batch.calls = append(db.batch.calls, callfn: fn, err: errCh)
// MaxBatchSize 默认值为 1000
if len(db.batch.calls) >= db.MaxBatchSize
// wake up batch, it\'s ready to run
go db.batch.trigger()
db.batchMu.Unlock()
err := <-errCh
if err == trySolo
err = db.Update(fn)
return err
看了上面源码过后,对DB.Batch()有了一定的了解,接下来,再通过例子进行验证,就知道官方的意思了。
package main
import (
"errors"
"fmt"
"github.com/boltdb/bolt"
"time"
)
func main()
db, err := bolt.Open("test/my.db", 0600, nil)
if err != nil
fmt.Printf("open db error, err: %v\\n", err)
return
loopCount := 1
db.MaxBatchSize = 2
db.MaxBatchDelay = time.Second * 3
for i := 0; i < loopCount; i++
i := i
go func()
err = db.Batch(func(tx *bolt.Tx) error
b := tx.Bucket([]byte("test"))
if b == nil
return errors.New("not found Bucket: test")
b.Put([]byte("name-1"), []byte("xiaolin-1"))
fmt.Println(string(b.Get([]byte("name-1"))))
return nil
)
if err != nil
fmt.Println(i, "---> db.Batch failed, err:", err)
()
if err != nil
fmt.Println("db.Update failed, err:", err)
time.Sleep(time.Second*2)
这里,我们通过loopCount、MaxBatchSize、MaxBatchDelay、time.Sleep(time.Second*2)不同的值来说明:
1、第一种情况
loopCount := 1
db.MaxBatchSize = 2
db.MaxBatchDelay = time.Second * 3
time.Sleep(time.Second*2)
运行结果为空。为什么呢,因为 我们只往 db.batch.calls中添加了一个Call,所以会等待3秒钟后才会提交数据到磁盘,但是程序2秒钟之后就结果了。所以什么都没有。
2、第二种情况
loopCount := 2
db.MaxBatchSize = 2
db.MaxBatchDelay = time.Second * 3
time.Sleep(time.Second*2)
运行结果打印了两次 xiaolin-1。为什么呢,因为 我们往 db.batch.calls中添加了2个Call,大于等于MaxBatchSize,会立即把数据提交到磁盘。
3、第三种情况
loopCount := 1
db.MaxBatchSize = 2
db.MaxBatchDelay = time.Second * 3
time.Sleep(time.Second*4)
运行结果是 等待了3秒钟后,打印了xiaolin-1,然后 等待了1秒,程序结果。为什么呢,因为 我们往 db.batch.calls中添加了1个Call,小于MaxBatchSize,这个时候就会等待MaxBatchDelay才会执行 db.batch.trigger。
通过上面三种情况,大致清楚了 DB.Batch()的作用。到这里也终于明白Batch函数注释,Batch is only useful when there are multiple goroutines calling it.这句话的含义了。
3.4 手动管理交易
DB.View()和 DB.Update()函数是DB.Begin()函数的包装器。 这些帮助函数将启动事务,执行一个函数,然后在返回错误时安全地关闭事务。 这是使用 Bolt 事务的推荐方式。
但是,有时可能需要手动开始和结束事务。 可以直接使用DB.Begin()函数,一定记得关闭事务。
// Start a writable transaction.
tx, err := db.Begin(true)
if err != nil
return err
defer tx.Rollback()
// Use the transaction...
_, err := tx.CreateBucket([]byte("MyBucket"))
if err != nil
return err
// Commit the transaction and check for error.
if err := tx.Commit(); err != nil
return err
DB.Begin()的第一个参数是一个布尔值,说明事务是否可写,这也是DB.View()和 DB.Update()的区别之一。
4、bolt的使用
4.1 Bucket的管理
在上面的使用案例中,我们都会先通过tx.CreateBucket或者tx.Bucket来获取一个Bucket对象,为什么呢?
因为Bucket是数据库中 key/value 对的集合。 bucket 中的所有 key 必须是唯一的。 可以使用 DB.CreateBucket() 函数创建一个存储 bucket:
db.Update(func(tx *bolt.Tx) error
b, err := tx.CreateBucket([]byte("MyBucket"))
if err != nil
return fmt.Errorf("create bucket: %s", err)
return nil
)
也可以使用 Tx.CreateBucketIfNotExists() 函数创建一个 bucket ,当然,如果存在就不会创建。 在实际编程中,我们通常使用此函数来获取或者创建Bucket,其实我们通过看源码,会发现Tx.CreateBucketIfNotExists也是对tx.CreateBucket和tx.Bucket做了一层封装而已。
要删除一个 bucket,只需调用 Tx.DeleteBucket() 函数即可。
4.2 如何往Bucket中读写数据
如何将 key/value 对保存到 bucket呢,需要 Bucket.Put() 函数:
db.Update(func(tx *bolt.Tx) error
b := tx.Bucket([]byte("MyBucket"))
err := b.Put([]byte("answer"), []byte("42"))
return err
)
这将在 MyBucket 中存储一个key为 “answer” ,value为“42”的key/value对。
要检索这个value,我们可以使用 Bucket.Get() 函数:
db.View(func(tx *bolt.Tx) error
b := tx.Bucket([]byte("MyBucket"))
v := b.Get([]byte("answer"))
fmt.Printf("The answer is: %s\\n", v)
return nil
)
Get() 函数不会返回错误,因为它的操作保证可以正常工作(除非有某种系统失败)。 如果 key 存在,则它将返回其字节片段值。 如果不存在,则返回零。 请注意,可以将零长度值设置为与不存在的键不同的键。
使用 Bucket.Delete() 函数从 bucket 中删除一个 key。
请注意,从 Get() 返回的值仅在事务处于打开状态时有效。 如果需要在事务外使用到它,则必须使用 copy() 将其复制到另一个字节片段。
上面这句话咋个理解呢,我是没看到什么意思!!!!我说说我的理解,如果错误了,请不吝赐教,谢谢。我感觉这里的意思:如果
db.Update函数外部需要使用到Get()查询得到的值,需要先使用 copy 函数将值复制给外部的变量。因为slice是引用类型,这样当我们在db.Update函数内容修改了返回的值时,不会影响到最开查询的结果。
4.3 自动递增函数-NextSequence()
我们知道Mysql可以将主键设置为自动递增的,那bolt有没有也是的功能呢,是有的,Bucket.NextSequence()将返回一个自动递增的数字。
package main
import (
"fmt"
"github.com/boltdb/bolt"
"sync"
)
func main()
db, err := bolt.Open("test/my.db", 0600, nil)
if err != nil
fmt.Printf("open db error, err: %v\\n", err)
return
wg := sync.WaitGroup
testMap := make(map[uint64]struct)
for i := 0; i < 100; i++
wg.Add(1)
go func()
defer func()
wg.Done()
()
db.Update(func(tx *bolt.Tx) error
b := tx.Bucket([]byte("test"))
id, _ := b.NextSequence()
v, ok := testMap[id]
if ok
fmt.Printf("%v in testMap \\n", v)
testMap[id] = struct
return nil
)
()
if err != nil
fmt.Println("db.Update failed, err:", err)
wg.Wait()
if len(testMap) != 100
var note interface = "testMap exist duplicate key"
panic(note)
5、 如何迭代查询 keys
5.1 基础介绍
Bolt 将 keys 以字节排序的顺序存储在一个 bucket 中。这使得对这些 keys 的顺序迭代非常快。要遍历 key,我们将使用一个 Cursor:
package main
import (
"bytes"
"fmt"
"github.com/boltdb/bolt"
)
func main()
db, err := bolt.Open("test/my.db", 0600, nil)
if err != nil
fmt.Printf("open db error, err: %v\\n", err)
return
err = db.View(func(tx *bolt.Tx) error
// Assume bucket exists and has keys
c := tx.Bucket([]byte("test")).Cursor()
prefix := []byte("name")
for k, v := c.Seek(prefix); k != nil && bytes.HasPrefix(k, prefix); k, v = c.Next()
fmt.Printf("key=%s, value=%s\\n", k, v)
return nil
)
if err != nil
fmt.Println("db.Update failed, err:", err)
结果:
key=name, value=xiaoling
key=name-0, value=0
key=name-1, value=xiaolin-1
key=name-10, value=10
key=name-2, value=xiaolin-2
key=name-3, value=xiaolin-3
key=name-4, value=4
key=name-5, value=5
key=name-6, value=6
key=name-7, value=7
key=name-8, value=8
key=name-9, value=9
Cursor 允许您移动到键列表中的特定点,并一次向前或向后移动一个键。
Cursor 上有以下功能:
First() Move to the first key.
Last() Move to the last key.
Seek() Move to a specific key.
Next() Move to the next key.
Prev() Move to the previous key.复制代码
每个函数都有(key [] byte,value [] byte)的返回签名。 当你迭代到游标的末尾时,Next() 将返回一个零键。 在调用 Next() 或 Prev() 之前,您必须使用 First(), Last() 或 Seek() 来寻找位置。 如果你不寻找位置,那么这些函数将返回一个零键。
在迭代期间,如果 key 非零,但是 value 为零,则意味着 key 指的是一个 bucket 而不是一个 value。 使用 Bucket.Bucket() 访问子 bucket。通过下面这个例子来进行理解:
package main
import (
"fmt"
"github.com/boltdb/bolt"
)
func main()
db, err := bolt.Open("test/my.db", 0600, nil)
if err != nil
fmt.Printf("open db error, err: %v\\n", err)
return
err = db.Update(func(tx *bolt.Tx) error
// Assume bucket exists and has keys
b := tx.Bucket([]byte("test"))
b2, _ := b.CreateBucketIfNotExists([]byte("test2"))
b2.Put([]byte("name"), []byte("nihao"))
c := b.Cursor()
prefix := []byte("name")
for k, v := c.Seek(prefix); k != nil ; k, v = c.Next()
if k != nil && v == nil // 重点就是这句话,这种情况下说明key 指的是一个 bucket 而不是一个 value
b2 = b.Bucket(k)
fmt.Println(string(b2.Get([]byte("name"))))
return nil
)
if err != nil
fmt.Println("db.Update failed, err:", err)
// 执行结果
nihao
5.2 前缀扫描
迭代关键字前缀,可以将 Seek() 和 bytes.HasPrefix() 组合起来:
db.View(func(tx *bolt.Tx) error
// Assume bucket exists and has keys
c := tx.Bucket([]byte("MyBucket")).Cursor()
prefix := []byte("1234")
for k, v := c.Seek(prefix); k != nil && bytes.HasPrefix(k, prefix); k, v = c.Next()
fmt.Printf("key=%s, value=%s\\n", k, v)
return nil
)
5.3 范围扫描
另一个常见的用例是扫描一个范围,如时间范围。我们可以使用可排序的时间编码(如 RFC3339 ),那么可以查询特定的日期范围,如下所示:
db.View(func(tx *bolt.Tx) error
// Assume our events bucket exists and has RFC3339 encoded time keys.
c := tx.Bucket([]byte("Events")).Cursor()
// Our time range spans the 90\'s decade.
min := []byte("1990-01-01T00:00:00Z")
max := []byte("2000-01-01T00:00:00Z")
// Iterate over the 90\'s.
for k, v := c.Seek(min); k != nil && bytes.Compare(k, max) <= 0; k, v = c.Next()
fmt.Printf("%s: %s\\n", k, v)
return nil
)
请注意,尽管 RFC3339 是可排序的,但 RFC3339Nano 的 Golang 实现不会在小数点后使用固定数量的数字,因此无法排序。
5.4 ForEach()
那怎么迭代查询 bucket 中的所有key呢,方法是使用ForEach()函数。
db.View(func(tx *bolt.Tx) error
// Assume bucket exists and has keys
b := tx.Bucket([]byte("MyBucket"))
b.ForEach(func(k, v []byte) error
fmt.Printf("key=%s, value=%s\\n", k, v)
return nil
)
return nil
)
请注意,ForEach()中的键和值仅在事务处于打开状态时有效。如果您需要使用事务外的键或值,则必须使用 copy()将其复制到另一个字节片。
6、嵌套的 bucket
我们可以在一个 key 中存储一个 bucket 来创建嵌套的 bucket 。 创建方式和以前创建 bucket 一样:
func (*Bucket) CreateBucket(key []byte) (*Bucket, error)
func (*Bucket) CreateBucketIfNotExists(key []byte) (*Bucket, error)
func (*Bucket) DeleteBucket(key []byte) error
这里讲一个嵌套使用的bucket的场景,假设有一个多租户应用程序,其中根级 bucketRoot 是帐户 bucket。 这个 bucketRoot 里面是一系列的帐户,这些账户本身就是一个 bucket。 而在序列的 bucket 中,存储各个账户的信息。
// createUser creates a new user in the given account.
func createUser(accountID int, u *User) error
// Start the transaction.
tx, err := db.Begin(true)
if err != nil
return err
defer tx.Rollback()
// Retrieve the root bucket for the account.
// Assume this has already been created when the account was set up.
root := tx.Bucket([]byte(strconv.FormatUint(accountID, 10)))
// Setup the users bucket.
bkt, err := root.CreateBucketIfNotExists([]byte("USERS"))
if err != nil
return err
// Generate an ID for the new user.
userID, err := bkt.NextSequence()
if err != nil
return err
u.ID = userID
// Marshal and save the encoded user.
if buf, err := json.Marshal(u); err != nil
return err
else if err := bkt.Put([]byte(strconv.FormatUint(u.ID, 10)), buf); err != nil
return err
// Commit the transaction.
if err := tx.Commit(); err != nil
return err
return nil
7、数据库备份
Blot 是一个单一的文件,所以很容易备份。 您可以使用Tx.WriteTo()函数将数据库的一致视图写入目的地。 如果从只读事务中调用它,它将执行热备份而不会阻止其他数据库的读写操作。
默认情况下,它将使用一个常规的文件句柄来利用操作系统的页面缓存。 如何针对大于RAM的数据集进行优化,请参阅Tx文档。
如果需要处理大型数据集,需要采取特殊的优化措施,这些措施可以在Tx文档中找到。
一个常见的用例是通过 HTTP 进行备份,因此可以使用像 curl 这样的工具来进行数据库备份:
func BackupHandleFunc(w http.ResponseWriter, req *http.Request)
err := db.View(func(tx *bolt.Tx) error
w.Header().Set("Content-Type", "application/octet-stream")
w.Header().Set("Content-Disposition", `attachment; filename="my.db"`)
w.Header().Set("Content-Length", strconv.Itoa(int(tx.Size())))
_, err := tx.WriteTo(w)
return err
)
if err != nil
http.Error(w, err.Error(), http.StatusInternalServerError)
复制代码
那么你可以用这个命令备份:
$ curl http://localhost/backup > my.db
或者你可以打开你的浏览器到http://localhost/backup,它会自动下载。如果你想备份到另一个文件,你可以使用 Tx.CopyFile()辅助函数。
8、官方文档其他的介绍
上面的内容基本上是关于如何使用 bolt 数据库的,下面的内容则是讲一讲 bolt 与其他数据的区别,以及什么时候选择使用 bolt 有优势。下面的内容就是复制的参考链接的内容了,嘿嘿。
8.1 与其他数据库比较
8.1.1 Postgres, MySQL, & other relational databases
关系数据库将数据结构化为行,并且只能通过使用SQL来访问。 这种方法提供了如何存储和查询数据的灵活性,但也会导致解析和规划SQL语句的开销。 Bolt通过字节切片键访问所有数据。 这使得 Bolt 可以快速读写数据,但不提供内置的连接值的支持。
大多数关系数据库(SQLite除外)都是独立于服务器的独立服务器。 这使您的系统可以灵活地将多个应用程序服务器连接到单个数据库服务器,但是也增加了通过网络序列化和传输数据的开销。 Bolt 作为应用程序中包含的库运行,因此所有数据访问都必须通过应用程序的进程。 这使数据更接近您的应用程序,但限制了多进程访问数据。
8.1.2 LevelDB, RocksDB
LevelDB 及其衍生产品(RocksDB,HyperLevelDB)与 Bolt 类似,它们被绑定到应用程序中,但是它们的底层结构是日志结构合并树(LSM树)。 LSM 树通过使用提前写入日志和称为 SSTables 的多层排序文件来优化随机写入。 Bolt 在内部使用 B+ 树,只有一个文件。 两种方法都有折衷。
如果您需要高随机写入吞吐量(> 10,000 w / sec)或者您需要使用旋转磁盘,则 LevelDB可能是一个不错的选择。 如果你的应用程序是重读的,或者做了很多范围扫描,Bolt 可能是一个不错的选择。
另一个重要的考虑是 LevelDB 没有交易。 它支持批量写入键/值对,它支持读取快照,但不会使您能够安全地进行比较和交换操作。 Bolt 支持完全可序列化的 ACID 事务。
8.1.3 LMDB
Bolt 最初是 LMDB 的一个类似实现,所以在结构上是相似的。 两者都使用 B+ 树,具有完全可序列化事务的 ACID 语义,并且使用单个writer 和多个 reader 来支持无锁 MVCC。
这两个项目有些分歧。 LMDB 主要关注原始性能,而 Bolt 专注于简单性和易用性。 例如,LMDB 允许执行一些不安全的操作,如直接写操作。 Bolt 选择禁止可能使数据库处于损坏状态的操作。 这个在 Bolt 中唯一的例外是 DB.NoSync。
API 也有一些差异。 打开 mdb_env 时 LMDB 需要最大的 mmap 大小,而Bolt将自动处理增量式 mmap 大小调整。 LMDB 用多个标志重载 getter 和 setter 函数,而 Bolt 则将这些特殊的情况分解成它们自己的函数。
8.2 注意事项和限制
选择正确的工具是非常重要的,Bolt 也不例外。在评估和使用 Bolt 时,需要注意以下几点:
- Bolt 适合读取密集型工作负载。顺序写入性能也很快,但随机写入可能会很慢。您可以使用
DB.Batch()或添加预写日志来帮助缓解此问题。 - Bolt在内部使用B +树,所以可以有很多随机页面访问。与旋转磁盘相比,SSD可显着提高性能。
- 尽量避免长时间运行读取事务。 Bolt使用
copy-on-write技术,旧的事务正在使用,旧的页面不能被回收。 - 从 Bolt 返回的字节切片只在交易期间有效。 一旦事务被提交或回滚,那么它们指向的内存可以被新页面重用,或者可以从虚拟内存中取消映射,并且在访问时会看到一个意外的故障地址恐慌。
- Bolt在数据库文件上使用独占写入锁,因此不能被多个进程共享
- 使用
Bucket.FillPercent时要小心。设置具有随机插入的 bucket 的高填充百分比会导致数据库的页面利用率很差。 - 一般使用较大的 bucket。较小的 bucket 会导致较差的页面利用率,一旦它们大于页面大小(通常为4KB)。
- 将大量批量随机写入加载到新存储区可能会很慢,因为页面在事务提交之前不会分裂。不建议在单个事务中将超过 100,000 个键/值对随机插入单个新 bucket中。
- Bolt使用内存映射文件,以便底层操作系统处理数据的缓存。 通常情况下,操作系统将缓存尽可能多的文件,并在需要时释放内存到其他进程。 这意味着Bolt在处理大型数据库时可以显示非常高的内存使用率。 但是,这是预期的,操作系统将根据需要释放内存。 Bolt可以处理比可用物理RAM大得多的数据库,只要它的内存映射适合进程虚拟地址空间。 这在32位系统上可能会有问题。
- Bolt数据库中的数据结构是存储器映射的,所以数据文件将是endian特定的。 这意味着你不能将Bolt文件从一个小端机器复制到一个大端机器并使其工作。 对于大多数用户来说,这不是一个问题,因为大多数现代的CPU都是小端的。
- 由于页面在磁盘上的布局方式,Bolt无法截断数据文件并将空闲页面返回到磁盘。 相反,Bolt 在其数据文件中保留一个未使用页面的空闲列表。 这些免费页面可以被以后的交易重复使用。 由于数据库通常会增长,所以对于许多用例来说,这是很好的方法 但是,需要注意的是,删除大块数据不会让您回收磁盘上的空间。
参考链接:
存储引擎 boltdb 的设计奥秘?

作者 | 奇伢
来源 | 奇伢云存储

etcd 的存储

etcd v3 是使用的持久化存储来存储它的 kv 数据,etcd 存储的是非常核心的元数据信息,所以最重要的是稳定。使用的是 boltdb 。下面说道说道这个 boltdb 。

boltdb 是什么?

boltdb 是一个非常出名的存储引擎,纯 Go 语言实现的 KV 存储引擎。
boltdb 项目非常值得学习,封装的 API 简单,内部实现很精巧。整个项目去掉注释,测试代码啥的,就几千行代码。Github 地址为 https://github.com/boltdb/bolt 。但 boltdb 项目已经由原作者封版了,不再迭代更新。
etcd 自己 fork 了一个 boltdb 分支出来,上面做了一些自己的小优化。
boltdb 启发于 Howard Chu's LMDB[1] 项目,感兴趣的也可以去看下。
特点:
整个数据库就一个 db 文件,贼简单;
基于 B+ 树的索引,读效率高效且稳定;
读事务可多个并发,写事务只能串行;
缺点:
事务的实现贼简单,但是写的开销太大;
boltdb 写事务不能并发,只能靠批量操作来缓解性能问题;
下面我们从外到内一步步探索下 boltdb 的实现。

boltdb 看起来是什么样子?

整个 db 就一个单文件,只不过这个文件内容是有格式的。先用 hexdump 看一眼:

仔细的童鞋会发现,这个数据间隔有点意思?
0000 // 0 偏移
1000 // 4k 偏移
2000 // 8k 偏移
3000 // 12k 偏移
4000 // 16k 偏移
5000 // 16k 偏移每个偏移都是 4k 的间隔,里面还有一些看不懂的二进制数据。以前奇伢说过,越往底层都会有一个存储单元的概念,因为要合并一些边际开销,比如,文件系统大多以 4k 为单位进行管理,page cache 也以 4k 为单位管理。再看硬件,也是如此,磁盘的最小处理单位是扇区( 512字节 ),ssd 的读写是以 4k 为单位管理的。
boltdb 作为一个存储引擎,自然要统筹管理空间的使用,自然也有这么一个概念。boltdb 以 4k 定长为存储单元划分空间,这一个个 4k 叫做 page,boltdb 在上面建立更抽象的概念。
来看看 boltdb 怎么管理空间的吧。

怎么管理空间?

上面提到是以 4k 为粒度来管理空间的,每个 4k 叫做 page 。
1 page 页
为了方便管理,page 自然也是会有格式的,每个 page 都会有 header ,header 后面是 data 数据。
// header 结构体
type page struct
id pgid // page 编号
flags uint16 // 标明 page 的属性
count uint16 // 标明 page 上有多少个元素
overflow uint32 // 标明后面是不是还有连续的页跟着
ptr uintptr // 这就是个用来定界的
示意图:

从物理层面来说
boltdb 的 db 文件来说就是由这样一个个 page 组成的。举个例子,如果是一个 32K 的文件,那么就由 8 个 page 组成,每个 page 都有自己的唯一编号( pgid ),从 0 到 7 。
从逻辑层面来说
boltdb 把这一个个 page 组成了一个树形结构,它们之间通过 page id 关联起来。我们再往下思考:
第一个点:树自然会有个源头,比如从那个 page 开始索引,还有一些最关键的元数据( meta 数据 );
第二个点:既然是一颗树,那么自然有中间节点、叶子节点;
第三个点:既然是空间管理,那么自然要知道哪些是存储了用户数据 page ,哪些是空闲的 page ;
上面提到的三个点都指向一个结论:page 的用途是不一样的。也就是说,虽然大家都是 page,但是身份不一样。有的是叶子节点,有的是中间节点,有的是 meta 节点,有的是 free 节点。这个由 page.flag 来标识。
const (
branchPageFlag = 0x01
leafPageFlag = 0x02
metaPageFlag = 0x04
freelistPageFlag = 0x10
)下面分开聊聊这几种 page 页。
2 meta page
元数据的 page ,这可太重要了。对于 boltdb 来说,meta 的 page 位置是固定的,就在 page 0,page 1 这两个位置( 也就是前两个 4k 页 )的位置。一切索引从此开始,简单看下里面的数据含义:

Root :指明树根的位置;
Freelist :指明空闲列表的位置;
Txn :事务编号(写事务的时候,事务号会递增);
有童鞋可能会疑惑了,为什么会有两个 meta 页?
这是一个非常重要的设计,在 boltdb 里有一个非常重要的设计:没有覆盖写,也就是不会原地更新数据。这个是 boltdb 实现 ACID 事务的秘密。
以前也提过,覆盖写是数据损坏的根源之一。因为写数据的时候可能会出现任何异常,比如写部分成功,部分失败 这种就不符合事务的 ACID 原则。
但由于 meta 是 boltdb 一切的源头,所以它必须是固定位置( 不然就找不到它 )。但为什么会有 paid 0,1 两个位置呢?
诀窍就在于:通过轮转写来解决覆盖写的问题。 每次 meta 的更新都不会直接更新最新的位置,而是写上上次的位置。

// 计算 page id 的位置
p.id = pgid(m.txid % 2)举个例子:
事务 0 写 page 0 ;
事务 1 写 page 1 ;
事务 2 写 page 0 ;
事务 3 写 page 1 ;
3 branch page
branch 的 page 就是做了树的叶子节点,这个没啥讲的,里面就是存储的 branch 的节点。本质也是 key/value,key 是用户的 key,只不过 value 是 page 的索引而已。看一下结构体:
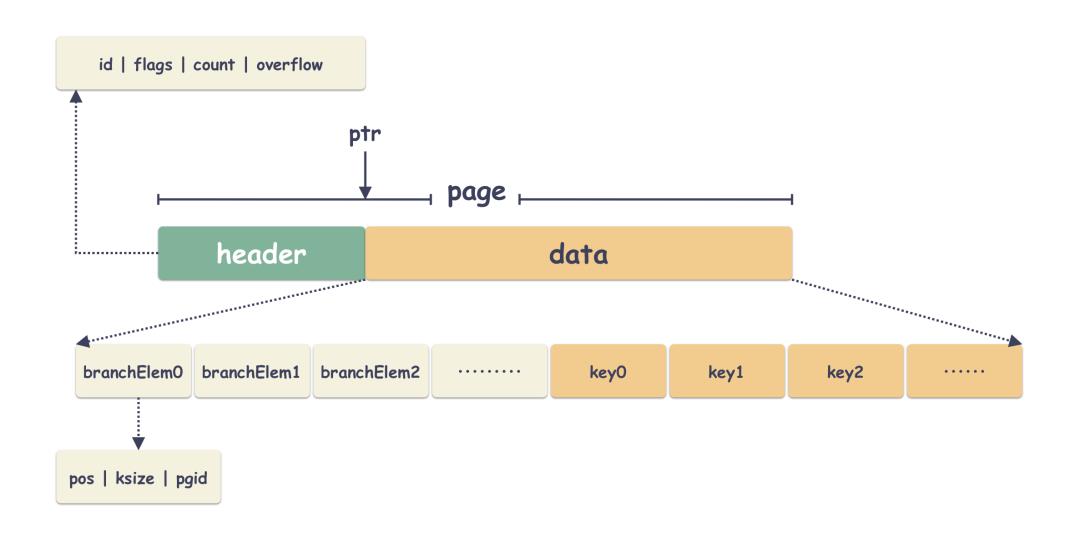
4 leaf page
叶子节点里面主要存储的是用户的数据,这个没啥讲的,一堆 key/value ,key 是用户的 key,value 是用户的数据。
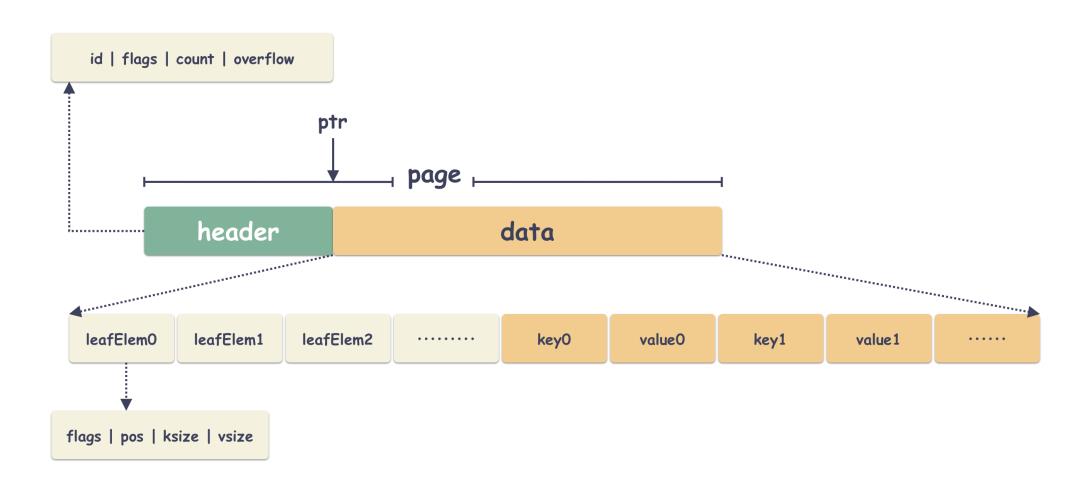
5 freelist page
所谓 freelist page 也就是说 page 里面存储的是一个个 pgid ,这些个 pgid 都是空闲可用的 page 的 id 。当写事务需要空闲的 page 存储数据的时候,就可以从这个里面捞一个来用。


怎么索引数据的?

现在我们知道了存储的管理单元是 page,每个都由 header + data 组成,page 的类型则决定了 data 里面装什么数据。最主要是四种 page :
meta 的数据;
中间节点的数据(主要是索引数据);
叶子节点,存储的是 key/value 数据( 有意思的是这里的 key/value 也是有讲究的,既可能是用户的 key/value 数据,也可能是 bucket 的结构数据 );
freelist 的数据,里面存储的是一个个 pgid ;
那现在我们看 boltdb 是怎么来组织 page,索引这些数据。
1 B+ 树 ?
都说 boltdb 用的是 B+ 树的形式,说的也是对的,但是 boltdb 的 B+ 树有些变异,几点差异如下:
节点的分支个数不是固定值;
叶子节点不相互感知,它们之间不存在相互的指向引用;
并不保证所有的叶子节点在同一层;
划重点:boltdb 它用的是一个不一样的 B+ 树。 除了上面的,索引查找和数据组织形式都是 B+ 树的样子。
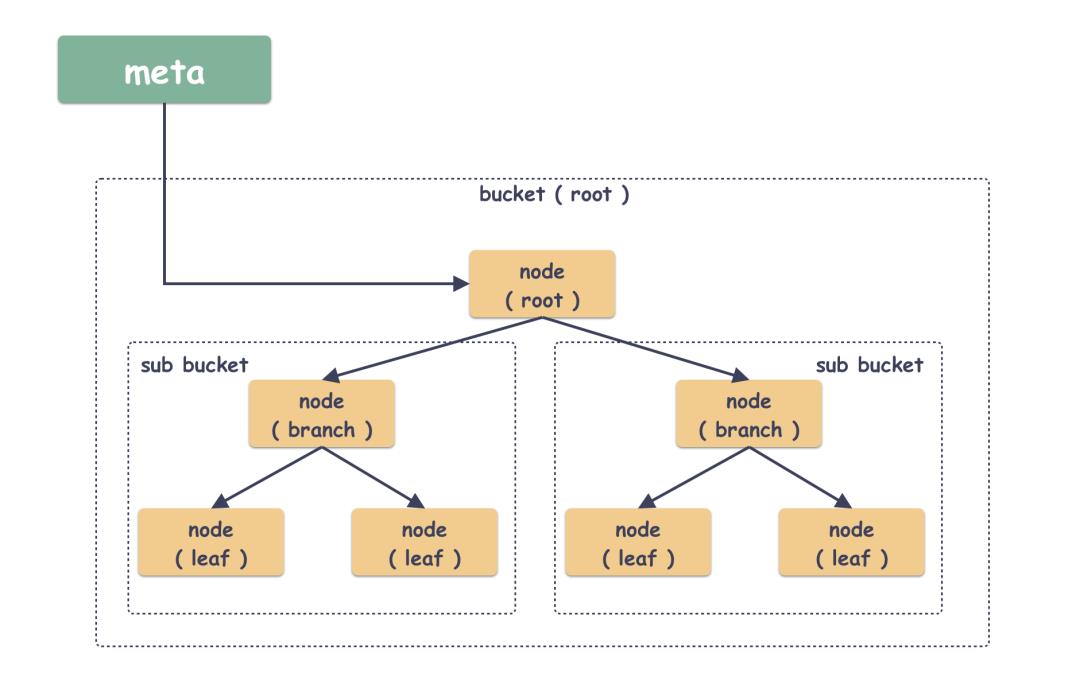
在 boltdb 里面有几个封装的概念:
Bucket :这是一个 boltdb 封装的一个抽象概念,但本质上呢它就是个命名空间,就是一些 key/value 的集合,不同的 Bucket 可以有同名的 key/value ;
node :B+ 树节点的抽象封装,可以说 page 是磁盘物理的概念,node 则是逻辑上的抽象了;
在 boltdb 中,Bucket 是可以嵌套的,这一点也带来了很大的灵活性,同样也是代码略微难懂的地方。其实 boltdb 天生就有一个 Bucket ,这个是自动生成的,由 meta 指向,不是用户创建的,后续创建的 Bucket 都是这个 Bucket 的 subbucket 。

怎么实现的事务?

划重点:boltdb 实现事务的方式非常简单,就是绝对不覆盖更新数据。 其中 meta 是通过两个互为备份的 page 页轮转写实现的,数据页又是怎么实现的呢?
秘密就是:每次都写新的地方,最后更改路径引用。我们来看一下它是怎么做的?看一下演绎的过程:
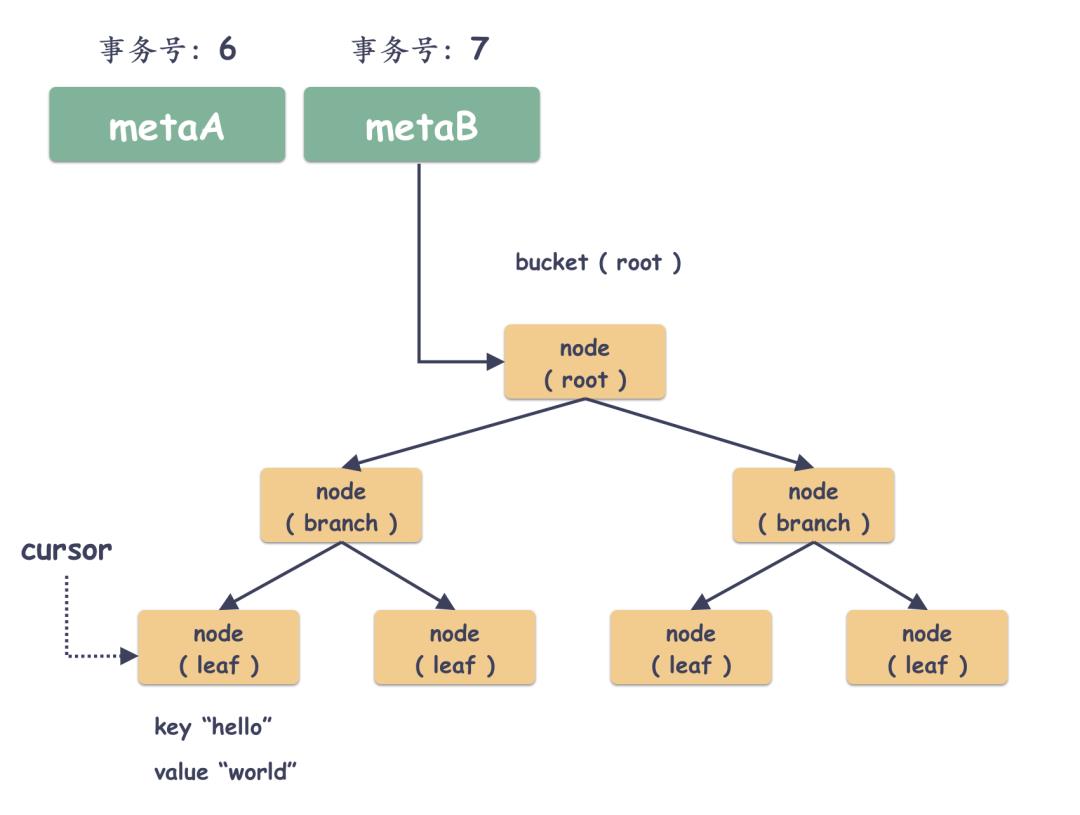
1 现状一棵树
假如当前如下,有个 key/value 键值对( "hello", "world" )存储在一个叶子 page 上。

2 更新前先找位置
现在用户要更新这个 key="hello" 的值,更新 value 为 "qiya" ,那么很自然的,开启一个写事务,事务号递增+1,boltdb 需要通过 B+ 树的搜索算法定位到叶子节点。
3 定位到后,读改写
定位到 node 节点之后,怎么修改呢?这个节点里面可不止这一对 key/value,里面还有很多 key/value 。
做法很简单,读改写!也就是先把这个 node 对应的 page 读到内存,把所有的 key/value 加载出来,然后把 key="hello" 的值更新到 value="new_world" ,并且写到新的 page 里。
那问题来了,叶子节点更新了,那指向这个叶子节点的 branch 节点要不要更新呢 ?
自然是要的。那 branch 节点更新了,那 branch 的 branch 节点要不要更新呢?自然是要的。所以这一层层往上推,最终要更新到 meta page 的,也就是树根。
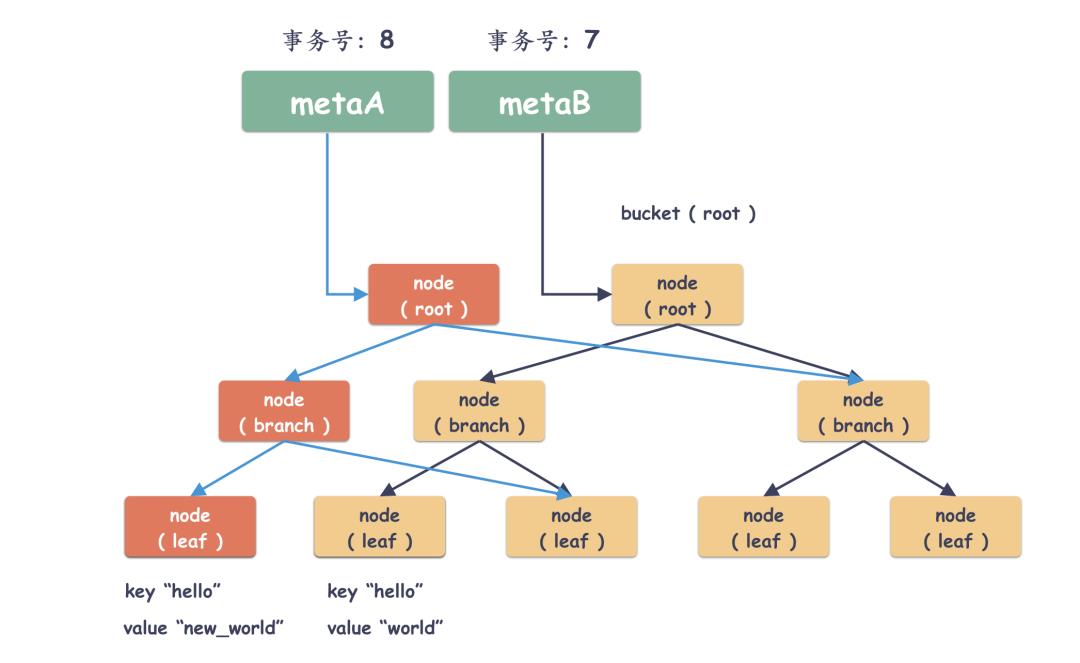
4 最后切换树根,被新 page 替换的最终会被释放
最终这些被替换的 page 就会被纳入到 freelist 里面,完全没有事务引用的话就会被释放。

5 小结一下
上面就是写事务的方式,总结一下:
通过 key 查询到位于 B+ 树的那个 page ;
把这个 page 读出来,构建 node 节点,更新 node 的内容;
把 node 的内容写到空闲的的 page ,并且一层层往上;
最终更新 meta 索引内容;
这里我先提一点个人的思考,很多人提到 boltdb 这是一种 cow ( copy-on-write )的方式,但其实我更偏向于把这个理解成 row 的方式。你觉得呢?

总结

etcd 使用 boltdb 来做存储引擎,读性能还行,写性能很一般,但是它稳;
boltdb 的物理存储单元是 page ,一般为 4k 一个;
page 有不同的类型,里面的内容根据类型不一样而不同;
boltdb 使用 row 的方式(个人理解),保证无覆盖写,等到 commit 的时候,最终修改引用,从而切换整个 db 的路径。这样的方式几乎是 0 成本实现的 ACID 事务;
meta 的 page 有两个,它们通过轮转写来实现的不覆盖写,从而保证了数据更新的安全;
B+ 树相比 LSM Tree 天然就有随机读的性能优势,它的树高度稳定,boltdb 通过 mmap 把文件映射到内存,这样简化了代码,读的缓存交给了操作系统的 page cache ;
boltdb 写性能可能很差,因为只要改了一点点东西,都会导致这个节点到 root 节点整条链路的更新,写放大挺严重的,所以它只能靠 batch 操作来安慰自己;
参考资料
[1]
LMDB Github 地址: https://github.com/LMDB


往期推荐

点分享

点收藏

点点赞

点在看
以上是关于详细的BoltDB学习记录文档的主要内容,如果未能解决你的问题,请参考以下文章