写了那么久的Python,你应该学会使用yield关键字了
Posted 青南的小世界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了写了那么久的Python,你应该学会使用yield关键字了相关的知识,希望对你有一定的参考价值。
写过一段时间代码的同学,应该对这一句话深有体会:程序的时间利用率和空间利用率往往是矛盾的,可以用时间换空间,可以用空间换时间,但很难同时提高一个程序的时间利用率和空间利用率。
但如果你尝试使用生成器来重构你的代码,也许你会发现,在一定程度上,你可以既提高时间利用率,又提高空间利用率。
我们以一个数据清洗的简单项目为例,来说明生成器如何让你的代码运行起来更加高效。
在 Redis 中,有一个列表
datalist,里面有很多的数据,这些数据可能是纯阿拉伯数字,中文数字,字符串"敏感信息"。现在我们需要实现:从 Redis 中读取所有的数据,把所有的字符串敏感信息全部丢掉,把所有中文数字全部转换为阿拉伯数字,以{‘num‘: 12345, ‘date‘: ‘2019-10-30 18:12:14‘}这样的格式插入到 MongoDB 中。
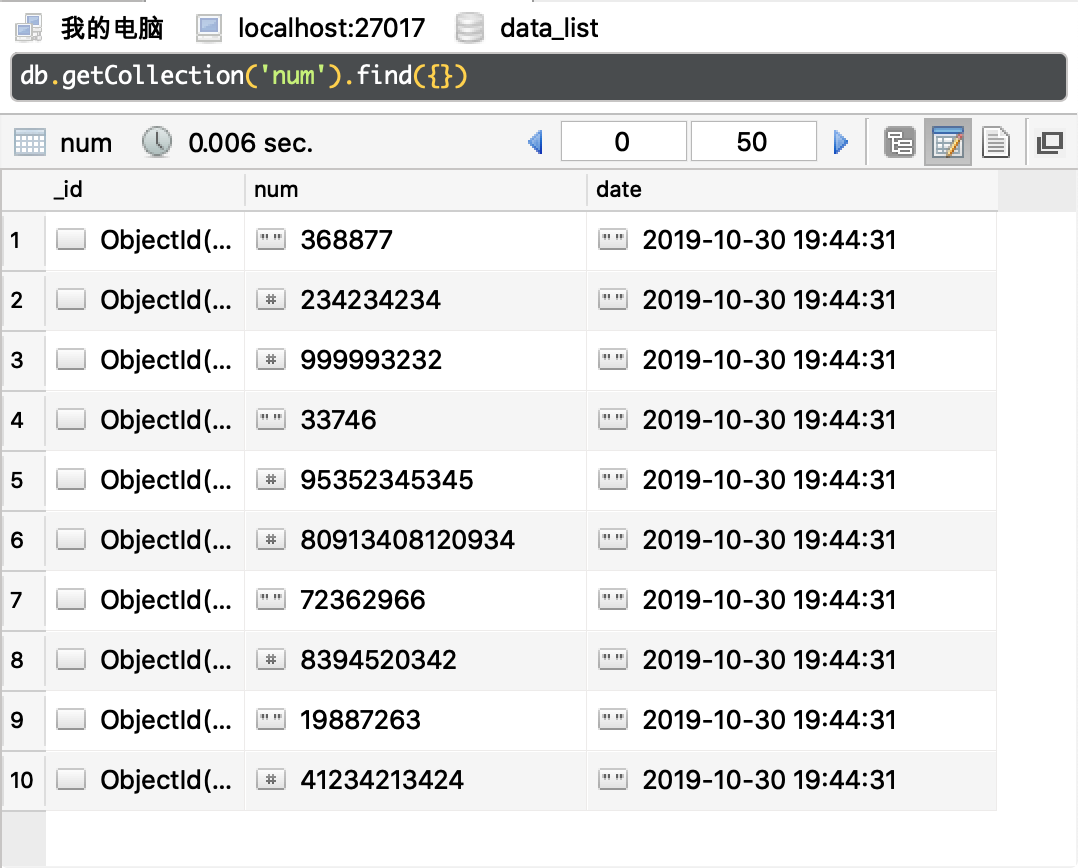
示例数据如下:
41234213424
一九八八七二六三
8394520342
七二三六二九六六
敏感信息
80913408120934
敏感信息
敏感信息
95352345345
三三七四六
999993232
234234234
三六八八七七
敏感信息如下图所示:

如果让你来写这个转换程序,你可能会这样写:
import redis
import datetime
import pymongo
client = redis.Redis()
handler = pymongo.MongoClient().data_list.num
CHINESE_NUM_DICT = {
'一': '1',
'二': '2',
'三': '3',
'四': '4',
'五': '5',
'六': '6',
'七': '7',
'八': '8',
'九': '9'
}
def get_data():
datas = []
while True:
data = client.lpop('datalist')
if not data:
break
datas.append(data.decode())
return datas
def remove_sensitive_data(datas):
clear_data = []
for data in datas:
if data == '敏感信息':
continue
clear_data.append(data)
return clear_data
def tranfer_chinese_num(datas):
number_list = []
for data in datas:
try:
num = int(data)
except ValueError:
num = ''.join(CHINESE_NUM_DICT[x] for x in data)
number_list.append(num)
return number_list
def save_data(number_list):
for number in number_list:
data = {'num': number, 'date': datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
handler.insert_one(data)
raw_data = get_data()
safe_data = remove_sensitive_data(raw_data)
number_list = tranfer_chinese_num(safe_data)
save_data(number_list)运行效果如下图所示:
这段代码,看起来很 Pythonic,一个函数只做一件事,看起来也满足编码规范。最后运行结果也正确。能有什么问题?
问题在于,这段代码,每个函数都会创建一个列表存放处理以后的数据。如果 Redis 中的数据多到超过了你当前电脑的内存怎么办?对同一批数据多次使用 for 循环,浪费了大量的时间,能不能只循环一次?
也许你会说,你可以把移除敏感信息,中文数字转阿拉伯数字的逻辑全部写在get_data函数的 while循环中,这样不就只循环一次了吗?
可以是可以,但是这样一来,get_data就做了不止一件事情,代码也显得非常混乱。如果以后要增加一个新的数据处理逻辑:
转换为数字以后,检查所有奇数位的数字相加之和与偶数位数字相加之和是否相等,丢弃所有相等的数字。
那么你就要修改get_data的代码。
在开发软件的时候,我们应该面向扩展开放,面向修改封闭,所以不同的逻辑,确实应该分开,所以上面把每个处理逻辑分别写成函数的写法,在软件工程上没有问题。但是如何做到处理逻辑分开,又不需要对同一批数据进行多次 for 循环呢?
这个时候,就要依赖于我们的生成器了。
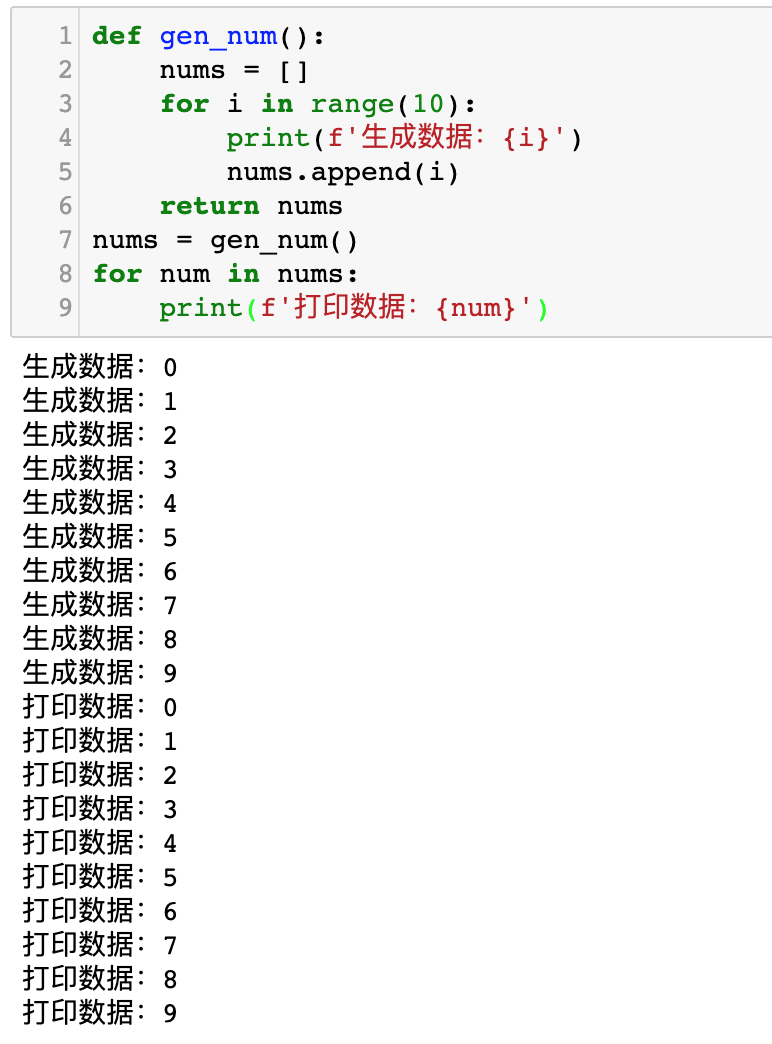
我们先来看看下面这一段代码的运行效果:
def gen_num():
nums = []
for i in range(10):
print(f'生成数据:{i}')
nums.append(i)
return nums
nums = gen_num()
for num in nums:
print(f'打印数据:{num}')运行效果如下图所示:
现在,我们对代码做一下修改:
def gen_num():
for i in range(10):
print(f'生成数据:{i}')
yield i
nums = gen_num()
for num in nums:
print(f'打印数据:{num}')其运行效果如下图所示:

大家对比上面两张插图。前一张插图,先生成10个数据,然后再打印10个数据。后一张图,生成一个数据,打印一个数据,再生成一个数据,再打印一个数据……
如果以代码的行号来表示运行运行逻辑,那么代码是按照这个流程运行的:
1->5->6->2->3->4->6->7->6->2->3->4->6->7->6->2->3->4->6->7....大家可以把这段代码写在 PyCharm 中,然后使用单步调试来查看它每一步运行的是哪一行代码。
程序运行到yield就会把它后面的数字抛出到外面给 for 循环, 然后进入外面 for 循环的循环体,外面的 for 循环执行完成后,又会进入gen_num函数里面的 yield i后面的一行,开启下一次 for 循环,继续生成新的数字……
整个过程中,不需要额外创建一个列表来保存中间的数据,从而达到节约内存空间的目的。而整个过程中,虽然代码写了两个 for 循环,但是如果你使用单步调试,你就会发现实际上真正的循环只有for i in range(10)。而外面的for num in nums仅仅是实现了函数内外的切换,并没有新增循环。
回到最开始的问题,我们如何使用生成器来修改代码呢?实际上你几乎只需要把return 列表改成yield 每一个元素即可:
import redis
import datetime
import pymongo
client = redis.Redis()
handler = pymongo.MongoClient().data_list.num_yield
CHINESE_NUM_DICT = {
'一': '1',
'二': '2',
'三': '3',
'四': '4',
'五': '5',
'六': '6',
'七': '7',
'八': '8',
'九': '9'
}
def get_data():
while True:
data = client.lpop('datalist')
if not data:
break
yield data.decode()
def remove_sensitive_data(datas):
for data in datas:
if data == '敏感信息':
continue
yield data
def tranfer_chinese_num(datas):
for data in datas:
try:
num = int(data)
except ValueError:
num = ''.join(CHINESE_NUM_DICT[x] for x in data)
yield num
def save_data(number_list):
for number in number_list:
data = {'num': number, 'date': datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
handler.insert_one(data)
raw_data = get_data()
safe_data = remove_sensitive_data(raw_data)
number_list = tranfer_chinese_num(safe_data)
save_data(number_list)代码如下图所示:
如果你开启 PyCharm 调试模式,你会发现,数据的流向是这样的:
- 从 Redis 获取1条数据
- 这一条数据传给remove_sensitive_data
- 第2步处理以后的数据传给tranfer_chinese_num
- 第3步处理以后,传给 save_data
- 回到第1步
整个过程就像是一条流水线一样,数据一条一条地进行处理和存档。不需创建额外的列表,有多少条数据就循环多少次,不做多余的循环。
以上是关于写了那么久的Python,你应该学会使用yield关键字了的主要内容,如果未能解决你的问题,请参考以下文章