java和python对比
Posted 浅忆尘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java和python对比相关的知识,希望对你有一定的参考价值。
一:解释性和编译型
梳理
编译型:源代码经过编译直接变为二进制的机器语言,每次都可以直接重新运行不需要翻译。典型的就是c语言。
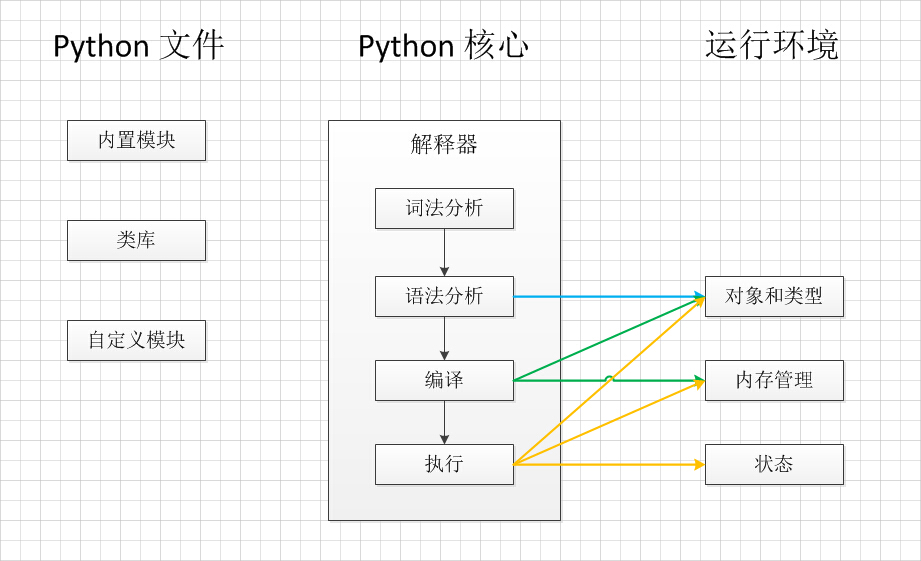
解释性:java和python都是解释型,源代码经过编译变为中间代码(字节码文件),非二进制代码,然后将字节码放在VM上运行,达到跨平台的目的。
解释器将中间代码转为二进制代码。
java和python都是边解释边执行,但是解释之前都先进行了编译工作,编译为vm能看懂的字节码,vm解释的是字节码,非源码和机器语言。
但是为什么python比java慢了一个级别?
主要原因是python是动态语言,java是静态语言。
静态语言:变量声明的时候要声明变量类型,这样编译器在程序运行时知道变量的类型,提前按数据类型规划好了内存区域,找起来范围小十分的快捷。
动态语言:在程序运行时解释器只知道变量是一个对象,至于具体是什么类型解释器并不知道,所以每次程序运行的时候都要判断变量的类型,然后再去找此变量。
java对于相同类型,编译像预演一样,在现场直播时安排连续的一块小内存存放,寻址速度快,还有JIT的编译优化等。
python则是程序分配的全内存寻址,比java肯定慢了。
还有像容器类型,java中的数组变量类型必须一致;但是python中list用的多,变量类型任意。
java中对变量类型还进行了细分,java中分直接传递和引用传递,python全部都是引用传递。(直接传递,拷贝数据;引用传递,传内存地址。)
因为动态语言多了一个类型判断的过程,因此python比java慢了一个级别。
动态语言是简单,但是解释器在背后做的事情比静态语言的解释器在背后做了更多的事情。
python两个概念,PyCodeObject和pyc文件
在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。
当python程序运行时,编译的结果保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将内存中的PyCodeObject写回到pyc文件中,前提有写权限。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到对比修改时间,改动了就重新编译,没改动则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
test.py如下
def test():
print("Hello World")
if __name=="__main__":
test()
此时python test.py发现硬盘中根本没有pyc文件
但是如果把函数定义放到另一个a.py文件中,在test.py中from a import test
此时再python test.py就会发现有了pyc文件。这说明了什么?
说明了pyc文件的目的是为了重用。
python解释器认为只有import的模块,才是要被重用的模块。对于test.py文件来讲,解释器不认为他是需要被重用的模块,因为他会被经常的改动,把它持久化是画蛇添足的,因为每次都要持久化为pyc文件,因此python只会把可重用的模块持久化为pyc文件。
速度
字节码并不能加快程序的运行速度,只是加快了代码的加载速度。
源代码都会被编译为字节码,java和Python都有这一步,当python运行主文件的时候,会将用到的其他模块全部编译为二进制的pyc文件来加快第二次运行程序时加载模块的速度,省去了源代码转为字节码的过程,解释器直接在pvm中拿到pyc文件直接执行。
当创建pyc文件的时候会和模块文件的最后一次修改时间进行映射,一旦第二次运行时会比较修改时间,如果修改时间没变就直接拿pyc文件执行,如果改变了就重新编译。
如果没有创建文件的权限,那么pyc文件是在内存存在的,每次运行pyc文件都是在内存重新编译生成,无法加快程序加载速度。
编译
java的编译就像预演一样,会把你所有的错误找出来,例如结果是none,然后你调用了一个方法,编译绝对无法通过,更加无法执行。
python是没有预演,只有现场直播,代码只有执行到错误位置才会报错,如果没有执行到是不会报错的,根据表演者(程序员)的水平高低,经验少的就会在直播时出很多错误,经验丰富就会犯的错误少,同java一样对none对象调用方法,只有运行起来才会发现错误。
设计初衷
python将开发者视为合格的开发人员,会自觉的遵守规范,当然你可以不遵守,那只能说明你“不合群”,并不是语言本身有问题,例如mixin机制,常量等都没有硬语法约束,而是规范。
java就像一个严格的监督者,你必须按照它要求的来,不按要求来就是错误,会在语法层面上约束的死死的。
java的设计严谨,总感觉有些过度设计,就像2020疫情中诞生的一个概念“去过度化”。
java没有多继承,用了接口的概念。实现逻辑上is...a与has...a的逻辑区分。
python虽然支持多继承,但是不推崇多继承,而是推崇鸭子类型,设计者把类设计的相似,长的像鸭子那么就是鸭子。
这样逻辑上虽然是同一类鸭子,但是代码层面上类之间是毫无关系的,完全解耦。
python崇尚鸭子类型和魔法方法(还有namespace),让python天生就是多态,
java的多态要建立继承关系,子类重写父类;定义时放父类/接口类型,调用时传入子类/实现类对象,刻意去多态,
python内置的协议就是魔法方法,不同的魔法方法分别属于不同的大类
python没有接口的概念,尽管python用abc模块模仿了抽象类,但我几乎没怎么用过。
魔法方法就像是彩蛋一样,有各种被动的触发方式,任何一个类都可以将魔法方法放到里面来增强类的表达。
python一切皆对象:元类type继承object类,元类type实例化了object类对象,听上去和现实是矛盾的,好像是一个闭环,但是在代码中并不矛盾,也是可以实现的。
矛盾是因为和现实世界映射对比起来矛盾:type继承了父类object,然后type又自己实例化了自己,然后又实例化了老爹,这什么玩意?
继承爹,又实例化爹在启动阶段并不矛盾,继承了静态的代码又没有调用爹的方法,开个后门让他过去
type类没用爹的方法,但是其他object类可能会使用object的方法,那没问题,只要其他对象在obejct实例化之后创建就可以了。
type继承object,object是对象,type也是对象;而type创建了所有的对象,那么一切都是对象。
type对象都是type自己创建的,用了一个指针而已。
python一切皆对象,1在java是基本数据类型,存放栈中,而pyhton一切皆对象,a=1背后是a=int(1),int是内置类,用的小写,1也是一个对象,在堆里面分配内存
堆空间比栈空间大的多,二者都去找1,当然java找的快。
总结
java和python程序速度差一个量级是因为语言本身的特性,静态和动态,与pyc文件毫无关系。
虽然速度差了一个量级,但是大多应用是无感知,0.1秒和0.01秒感觉都是过了1秒,又不是作购物网站,促销时遇到大规模并发,每一门语言有他擅长的领域,如果一门语言擅长所有的领域,那么早天下统一了。
python是顺序执行代码的和if __name__=="__main__"无关。
一份程序为了区分主动执行还是被调用,Python引入了变量__name__,当文件是被调用时,__name__的值为模块名,当文件被执行时,__name__为\'__main__\'
主动执行的叫脚本,被引入使用的叫模块。
1 #/usr/bin/env/ python #(1) 起始行 2 #"this is a test module" #(2) 模块文档(文档字符串) 3 import sys 4 import os #(3) 模块导入 5 6 debug = True #(4) (全局)变量定义 7 class FooClass (object): 8 \'foo class\' 9 pass #(5) 类定义(若有) 10 def main(): 11 \'test function\' 12 foo = FooClass() 13 if debug: 14 print \'ran test()\' #(6) 函数定义(若有) 15 if __name__ == \'__main__\': 16 main()
若是文件主动执行了,则最好写成跟上面的例子一样,main之前不要有可执行代码,这样做到程序从main()开始,流程逻辑性强
若是文件作为模块被调用,则可以不用写main(),从上而下顺序执行。
其实Python是否保存成pyc文件和我们在设计缓存系统时是一样的,我们可以仔细想想,到底什么是值得扔在缓存里的,什么是不值得扔在缓存里的。
在跑一个耗时的Python脚本时,我们如何能够稍微压榨一些程序的运行时间,就是将模块从主模块分开。(虽然往往这都不是瓶颈)
在设计一个软件系统时,重用和非重用的东西是不是也应该分开来对待,这是软件设计原则的重要部分。
在设计缓存系统(或者其他系统)时,我们如何来避免程序的过期,这也是Python的解释器也为我们提供了一个特别常见而且有效的解决方案。
以上是关于java和python对比的主要内容,如果未能解决你的问题,请参考以下文章