Python:编码与解码和转义字符
Posted 落日峡谷
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python:编码与解码和转义字符相关的知识,希望对你有一定的参考价值。
Python里面的字符一般默认为Unicode字符,属于str类型;而编码则是将字符转换成字节流的过程,反之解码是将字节流解析为字符的过程。
所谓的字节流,在pyhton里面,属于bytes类型。
1. python有两种方式实现编码和解码:
- encode 和 decode 方法:encode()函数根据括号内的编码方式,把str类型的字符串转换为bytes字符串,decode反之。
b = \'龙\'.encode(\'utf-8\') # \'龙\':unicode字符,encode进行 utf-8 编码 print(\'b:\',b) # 开头的 b 字符表示bytes类型 print(type(b)) #类型是\'bytes\' d = b.decode(\'utf-8\') #解码 print(\'d:\',d) print(type(d))

- str 和 bytes 方法
ss = bytes(\'龙\', encoding=\'utf-8\') # 编码 print(\'ss:\',ss) print(type(ss)) cc = str(ss, encoding=\'utf-8\') # 解码 print(\'cc:\',cc) print(type(cc))

求编码的字节长度,可以通过 len() 函数 对bytes类型的编码求长度得到:
print(len(b)) #编码的字节数,3个字节编码,因为b就是字节类型 bytes,此时为b:b\'\\xe9\\xbe\\x99\'
2. bytes函数:class bytes([source[, encoding[, errors]]]) —— 返回一个新的 bytes 对象,该对象是一个 0 <= x < 256 区间内的整数不可变序列。
参数
- 如果 source 为整数,则返回一个长度为 source 的初始化数组;
- 如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
- 如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
- 如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。
- 如果没有输入任何参数,默认就是初始化数组为0个元素。
ss = bytes(\'龙\', encoding=\'utf-8\') # 字符串 print(\'ss:\',ss) print(type(ss)) s2 = bytes(12) # 整数 print(\'ss:\',s2) s3 = bytes([12,3]) # 可迭代类型,元素必须为[0 ,255] 中的整数; print(\'s3:\',s3)
s4 = bytes(\'what?\', encoding=\'utf-8\') # 字符串,英文
print(\'s4:\',s4)
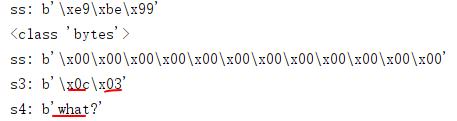
3. 乱码:因为字符串等都是经过某一编码方式编码的,所以如果解码的时候并不是对应的编码方式,则很容易出现乱码;此时就需要使用对应的编码方式解码。
(1)如果结果是一堆bytes类型的:\'\\x..\\x..\\x..\',则可以直接decode,通过相应的编码方式,例如decode(\'utf-8\')
(2)如果是由于解码和编码的方法不一致,则反向先编码再解码即可,例如:
nn = \'龙在天下\'.encode(\'gbk\') mm = nn.decode(\'ISO-8859-1\') print(\'mm:\',mm) #乱码 kk = mm.encode(\'ISO-8859-1\').decode(\'gbk\') # 对乱码反向解码 print(\'kk:\',kk)
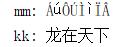
不过一般情况下,会直接报错,例如gbk和utf-8混用时会出现:UnicodeDecodeError: \'utf-8\' codec can\'t decode byte 0xc1 in position 0: invalid start byte。
最重要的是:编码和解码的方法最好一致。
4. 转义字符:遇到特殊字符的时候需要用到转义字符,就像不能直接用class来做变量一样,python中的转义字符主要如下:
| 转义字符 | 描述 |
|---|---|
| \\(在行尾时) | 续行符 |
| \\\\ | 反斜杠符号 |
| \\\' | 单引号 |
| \\" | 双引号 |
| \\a | 响铃 |
| \\b | 退格(Backspace) |
| \\e | 转义 |
| \\000 | 空 |
| \\n | 换行 |
| \\v | 纵向制表符 |
| \\t | 横向制表符 |
| \\r | 回车 |
| \\f | 换页 |
| \\oyy | 八进制数,yy代表的字符,例如:\\o12代表换行 |
| \\xyy | 十六进制数,yy代表的字符,例如:\\x0a代表换行 |
| \\other | 其它的字符以普通格式输出 |
所以上面经常遇到类似:b\'\\xe9\\xbe\\x99\',其中 b 表示bytes类型,\\x 其实表示十六进制值。
参考:
https://www.cnblogs.com/bruce-gou/p/10256151.html
https://www.runoob.com/python/python-strings.html
https://www.runoob.com/python3/python3-func-bytes.html
https://www.jianshu.com/p/220ee0f219c6
以上是关于Python:编码与解码和转义字符的主要内容,如果未能解决你的问题,请参考以下文章