记一次nginx配置不当引发的499与failover 机制失效
Posted To be a better programmer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次nginx配置不当引发的499与failover 机制失效相关的知识,希望对你有一定的参考价值。
背景
nginx 499在服务端推送流量高峰期长期以来都是存在的,间或还能达到告警阈值触发一小波告警,但主观上一直认为499是客户端主动断开,可能和推送高峰期的用户打开推送后很快杀死app有关,没有进一步探究问题根源。
然而近期在非高峰期也存在499超过告警阈值的偶发情况,多的时候一天几次,少的时候则几天一次,持续一般也就数分钟,并且该类告警一般集中于一台api机器,与推送高峰时多台机器同时499告警明显不同,不由得脑海中升起了问号,经过和小伙伴的共同探究,最后发现之前对于499是客户端主动断开因而和服务端关系不大的想当然认知是错误的,这里记录一下。
499的含义与可能原因
499其实并不是HTTP协议的标准状态码,而是nginx自定义的状态码,并没有在nginx官方文档中找到对该状态码的明确说明,这里引用一个感觉比较专业的博文上的解释:
HTTP error 499 simply means that the client shut off in the middle of processing the request through the server. The 499 error code puts better light that something happened with the client, that is why the request cannot be done. So don’t fret: HTTP response code 499 is not your fault at all.
大意是499一般意味着客户端在HTTP请求还在处理时主动结束的处理过程--断开了对应的网络连接,499一般意味着客户端侧发生了一些问题,和服务端没有关系。
以下则是nginx源码中的注释说明:
/*
* HTTP does not define the code for the case when a client closed
* the connection while we are processing its request so we introduce
* own code to log such situation when a client has closed the connection
* before we even try to send the HTTP header to it
*/
#define NGX_HTTP_CLIENT_CLOSED_REQUEST 499
意思是nginx引入了自定义的code 499来记录客户端断开连接时nginx还没有处理完其请求的场景。
回想多年以前首次碰到499场景时在网络搜索资料也是看到了类似的解答,所以一直认为499和服务端关系不大,应该都是客户端的原因。
一个客户端主动行为导致499的例子
曾经遇到过一个搜索联想接口,其499比例比其他api高上几十倍--一骑绝尘,单看该api基本上长期位于告警阈值之上,也追踪过其具体异常原因,最后联合客户端小伙伴给出了结论:搜索联想接口的499比例偏高时正常的,因为:
- 该api的调用场景是用户在搜索框输入搜索词时,用户每输入一个字符都会立刻用最新的输入调用api并将返回的联想结果展示给用户,以此达到一个近实时搜索联想的功能。
- 既然每次用户输入新字符都触发了最新的api调用请求,那即便之前的调用请求还在进行中,客户端也应该直接结束这些已无实际作用的旧请求,这反映在nginx log上就是客户端主动断开了连接的499。
所以搜索联想api虽然有异于普通api的高比例499,却是完全合理的,客户端要负主动断开连接的责任,但是并没有做错任何事情,服务端也没有任何问题。
一个客户端被动行为导致499的例子
另一个之前认为客户端行为导致499的例子是推送高峰,部分用户在通过推送打开app后可能会秒杀app,而推送高峰时期一般服务端压力比较大本身响应就会比平峰时期慢一些,此时有些api请求可能还正在进行中,此时用户杀死了app--app含冤而死无能为力--对应连接自然就被OS断开回收了,于是也导致了499,这种场景下服务端也是没有问题的。
服务端问题可能导致499?
通过上面两个例子乍看下去,499都是客户端侧的原因,无论是其主动还是被动行为,也正是这两个例子加深了博主心中对于499服务端应该无责任的意识。
总结服务端出错可能导致的nginx错误码,主要应该是以下几个场景:
- 500: 内部错误,一般为请求参数直接导致了upstream 的处理线程执行代码出错,业务代码或者框架直接返回 Internal Error
- 502: 一般为upstream server直接挂了无法连接,nginx无法访问upstream所以返回 Bad Gateway
- 503: upstream负载过高--但是没挂,直接返回了Service Unavailable
- 504: upstream处理请求时间过长,nginx等待upstream返回超时返回Gateway Timeout
所以无论是代码执行出错、服务挂了、服务过于繁忙、请求处理耗时过长导致HTTP请求失败,都是返回的5XX,压根不会触发499。
一般情况来说确实是这样的,但是这次新出现的平峰499并非一般情况,在网上查找资料时时有人提出过nginx 499可能是服务端处理耗时过长导致客户端超时后主动断开,但是这种情况按照上面的描述不应该属于场景4-- upstream处理请求时间过长,nginx返回504才对吗?
所以看上去服务端处理耗时过长既可能导致客户端主动断开的499也可能导致nginx返回Gateway Timeout的504,那导致这个区别的关键因素是什么?
简单来说就是如果客户端先断开被nginx检测到那就是499,而如果upstream 耗时过长超时先被nginx判定就是504,所以关键就是nginx对于upstream 超时的时间设置,捋到这里赶紧去看了下nginx的超时相关配置,嗯,没有明确配置相关超时时间--!
nginx中的504判定相关超时配置
由于api与nginx是通过uwsgi协议通信,因此关键的超时配置参数如下:
Syntax: uwsgi_connect_timeout time;
Default:
uwsgi_connect_timeout 60s;
Context: http, server, location
Defines a timeout for establishing a connection with a uwsgi server. It should be noted that this timeout cannot usually exceed 75 seconds.
Syntax: uwsgi_send_timeout time;
Default:
uwsgi_send_timeout 60s;
Context: http, server, location
Sets a timeout for transmitting a request to the uwsgi server. The timeout is set only between two successive write operations, not for the transmission of the whole request. If the uwsgi server does not receive anything within this time, the connection is closed.
Syntax: uwsgi_read_timeout time;
Default:
uwsgi_read_timeout 60s;
Context: http, server, location
Defines a timeout for reading a response from the uwsgi server. The timeout is set only between two successive read operations, not for the transmission of the whole response. If the uwsgi server does not transmit anything within this time, the connection is closed.
在未明确指定的情况下其超时时间均默认为60s,简单来说(实际情况更复杂一些但这里不进一步探讨)只有在upstream处理请求耗时超过60s的情况下nginx才能判定其Gateway Timeout 并按照504处理,然而客户端设置的HTTP请求超时时间其实只有15s--这其中还包括外网数据传输的时间,于是问题来了:每一个服务端处理耗时超过15s的请求,nginx由于还没达到60s的超时阈值不会判定504,而客户端则会由于超过本地的15s超时时间直接断开连接,nginx于是就会记录为499。
通过回查nginx log,非高峰期的499告警时段确实是存在单台upstream 请求处理缓慢,耗时过长,于是可能导致:
- 用户在需要block等待请求的页面等待虽然不到15s但是已经不耐烦了,直接采取切页面或者杀死app重启的方式结束当前请求。
- 用户耐心等待了15s、或者非阻塞的后台HTTP请求超过了15s超过超时阈值主动断开连接结束了当前请求。
服务端耗时过长导致的499
上面已经知道近期新出现的单台upstream 偶发499是由于响应缓慢引起的,既然是由于客户端超时时间(15s)远小于nginx upstream超时时间(60s)引起的,这应该属于一个明显的配置不当,会导致三个明显的问题:
- 将用户由于各种原因(如杀app)很快主动断开连接导致的499与客户端达到超时时间(这里是15s)导致的499混在了一起,无法区分客户端责任与服务端责任导致499问题。
- 对于nginx判定为499的请求,由于认为是客户端主动断开,不会被认为是服务端导致的unsuccessful attempt而被计入用于failover判定的max_fails计数中,所以即便一个upstream大量触发了499,nginx都不会将其从可用upstream中摘除,相当于摘除不可用节点的功能失效,而由于负载过高导致499的upstream收到的请求依然不断增加最终可能导致更大的问题。
- 对于判定为499的请求,也是由于不会被认为是unsuccessful attempt,所以uwsgi_next_upstream这一配置也不会work,于是当第一个处理请求的upstream耗时过长超时后,nginx不会尝试将其请求转发为下一个upstream尝试处理后返回,只能直接失败。
那是不是把客户端超时时间调大?或者把nginx upstream超时时间调小解决呢?
调大客户端超时时间当然是不合理的,任何用户请求15s还未收到响应肯定是有问题的,所以正确的做法应该是调小upstream的超时时间,一般来说服务端对于客户端请求处理时间应该都是在数十、数百ms之间,超过1s就已经属于超长请求了,所以不但默认的60s不行,客户端设置的15s也不能用于upstream的超时判定。
最终经过综合考虑服务端各api的耗时情况,先敲定了一个upstream 5s的超时时间配置--由于之前没有经验首次修改步子不迈太大,观察一段时间后继续调整,这样做已经足以很大程度解决以上的3个问题:
- 将用户由于各种原因(如杀app)很快主动断开连接导致的499与nginx达到upstream超时时间时主动结束的504区分开了。
- 504会被纳入max_fails计算,触发nginx摘除失败节点逻辑,在单台机器故障响应缓慢时可以被识别出来暂时摘除出可用节点列表,防止其负载进一步加大并保证后续请求均被正常可用节点处理返回。
- 当nginx等待upstream处理达到5s触发超时时,其会按照uwsgi_next_upstream配置尝试将请求(默认仅限幂等的GET请求)转交给下一个upstream尝试处理后返回,这样在单一upstream由于异常负载较高超时时,其他正常的upstream可以作为backup兜底处理其超时请求,这里客户端原本等待15s超时的请求一般在5~10s内可以兜底返回。
通过proxy_ignore_client_abort配置解决499问题?
在网上查找资料时还有网友提出解除nginx 499问题的一个思路是设置proxy_ignore_client_abort参数,该参数默认为off,将其设置为on 后,对于客户端主动断开请求的情况,nginx会ignore而以upstream实际返回的状态为准,nginx官方文档说明如下:
Syntax: proxy_ignore_client_abort on | off;
Default:
proxy_ignore_client_abort off;
Context: http, server, location
Determines whether the connection with a proxied server should be closed when a client closes the connection without waiting for a response.
但是在客户端主动断开连接时,设置这个参数的意义除了使nginx log中记录的状态码完全按照upstream返回确定,而非表示客户端断连的499之外,对于实际问题解决完全没有任何帮助,感觉颇有把头埋进沙子的鸵鸟风格,不知道这个参数设置到底会有什么实用的场景。
非高峰时期单个upstream偶发响应缓慢、导致超时的原因
这是个好问题,这个问题是近期才出现的,在解决了上面说的nginx错配问题后尝试排查这个问题,从现象上看应该是某些特定请求触发了upsteam CPU飙升,响应缓慢后进一步影响了后续请求的处理,最终导致所有请求响应缓慢触发客户端499。
在nginx错配问题解决后,再次出现这种单台upstream缓慢超时情况后,nginx会很快通过failover摘除掉问题upstream避免情况进一步恶化,而对于首次访问问题upstream超时的GET请求也会backup转发至其他可用upstream处理后返回,已经很大程度上降低了此类异常情况的影响。
最终,修正配置后单upstream的偶发异常会以几天一次的频率触发部分POST api的少量504阈值告警,其问题的根本原因还在探寻中。
总结
人生有太多错误的想当然,nginx 499一般是客户端责任便是一个例证,对于线上长期存在的少量异常告警,还是要怀有一丝敬畏之心,小心温水煮青蛙,在时间允许的情况下多探究、多思考。
转载请注明出处,原文地址:https://www.cnblogs.com/AcAc-t/p/nginx_499_and_504_for_uwsgi.html
参考
https://www.belugacdn.com/499-error-code/
https://juejin.cn/post/6844903876315873293
http://nginx.org/en/docs/http/ngx_http_uwsgi_module.html#uwsgi_read_timeout
https://www.cnblogs.com/AcAc-t/p/nginx_499_and_504_for_uwsgi.html
http://nginx.org/en/docs/http/ngx_http_upstream_module.html
http://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_ignore_client_abort
记一次生产环境Nginx日志骤增的问题排查过程
摘要:众所周知,Nginx是目前最流行的Web Server之一,也广泛应用于负载均衡、反向代理等服务,但使用过程中可能因为对Nginx工作原理、变量含义理解错误,或是参数配置不当导致Nginx工作异常。本文介绍的就是开机广告Nginx的参数location处理静态文件配置不当引发的nginx日志骤增到14G的问题排期过程。
一、问题现象及系统介绍
现象:12月15日 21:02分,正在外面吃宵夜,手机收到监控平台的一条“服务器磁盘空间<20%”报警短信。

系统介绍:为了看此文的童鞋更好理解我下面介绍的东西,这里我先简单介绍下福建开机广告系统。

整个系统可以分为管理平台与API两个部分:
管理平台完成素材(包括下面提到素材图片名也是有放到缓存里的)、广告、策略、排期制作和下发等工作,提供接口将广告策略、用户分组等信息同步到API;
API向机顶盒/EPG提供广告接口,采集广告请求日志,当STB访问EPG,EPG调用广告请求接口获取广告策略(地区、分组、平台、黑白名单等策略),并在匹配到策略的时候进行展示;
API节点我们是放在其中6台服务器的23个tomcat里面,使用nginx实现负载请求分发;图片服务器我们是放在另外的3台服务器,也是使用的nginx实现的负载请求分发。相信大家对nginx都不陌生,这里我就不在赘述。
二、问题排查过程
2.1 初步分析
判断一:可能是crontab未执行
一看是Nginx所在服务器,初步判断可能是crontab异常,没有定期清除5天以前的日志导致(这里说明下:我们线上的nginx日志是每天凌晨切割access.log日志,然后通过crontab实现只保留最近五天日志)。
2.2 深入分析
判断二:可能图片同步出问题
回到家,打开SHH客户端 查看/data/nginx_log目录查看,发现access.log只有近五天的日志,「排除原以为是crontab异情况」。
然后发现error_log很大,命令du -h error_log一看都有14G了,tail -200 error_log发现全是“/usr/local/nginx/html/resources/material/img/1511488532192.JPG”图片请求失败的记录,于是赶紧清空error_log,排除短信空间报警。

心想,难道是图片没有同步?
为验证我的猜想,我打开浏览器访问这张图片:http://IP:port/resources/material/img/1511488532192.JPG(上面IP指的是nginx所在服务器IP,port是nginx.conf配置图片分发端口),请求几次返回都是404。
于是切换到主图片服务器查看,发现这张大写图片存在,切换到其他两台从图片服务器,发现也是存在的(这里说明下:我们系统的素材图片都是通过管理平台以接口的形式下发主图片服务器,主图片服务器再通过inotify+sync同步到其他两台从图片服务器),「排除图片同步异常情况」。
判断三:可能是请求不到大写后缀图片导致
因为看到图片服务器目录下,唯有这几张大写后缀图片是请求异常的,那改成小写会怎么样呢?接着改了下三台图片服务器的图片大写后缀为小写后缀。再打开浏览器请求,发现请求正常了,继而判断可能运营人员在管理平台制作广告的时候上传了大写后缀的格式的图片,同步到API和数据库的缓存,那么导致有广告请求的从缓存查询到的图片地址也就是大写的了。
顺着这个思路,我先到登录到数据库改了下素材表图片大写后缀为小写后缀,再登录redis,准备改缓存,info命令一看,傻眼了,136万的key数量,而我又不记得具体广告策略key,

由于没办法查找,那就只能flushall清空缓存,重启ad-cache工程(这里说明下:ad-cache工程的作用主要就是两个,一是把当前符合要求的用户、广告策略等相关信息初始加载到缓存,另一个是启一个定时任务,每小时加载当前时段的策略到缓存),然后在查看tail -f error_log查看日志,发现还在增加之前那种大写后缀图片请求失败的错误,「排除图片后缀大写情况」。
判断四:可能是nginx配置不当导致
这么操作完还是不行,当时着实有点懵逼,我心想当时已经把广告请求所有涉及到会查询图片大写后缀的地方改过来了,为什么还是会有大写后缀图片请求失败的记录?但转念一想会不是nginx的配置有问题?
为验证我的判断,我先sz命令从图片服务器上下载了一张名为“1511488578911.JPG”的大写后缀格式的图片,然后通过管理平台上传这个“1511488578911.JPG”图片素材,发现这张图片是可以预览的。由此更加确信就是nginx某些参数配置不当导致。vim命令查看配置nginx.conf,当定位到图片请求配置这里的时候,
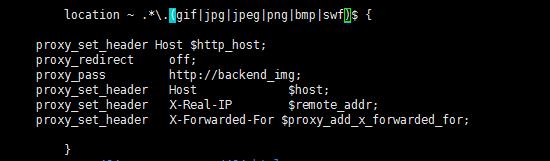
发现location ~是表示区分大小写的,而后面全是配置小写后缀格式,于是加上JPG,使用/usr/local/nginx/sbin/nginx -s reload命令重载nginx的配置,打开浏览器发现可以查看到这张图片了,再切换到nginx日志目录,tail -f error_log,发现日志没有再增加,至此问题终于解决。
三、问题反思
反思一:要做到知其然并且知其所以然
对Nginx工作原理、参数含义理解不深,从而参数配置不当,导致产生nginx日志骤增这种问题产生。
反思二:缺少一个快速定位问题的系统或工具,导致排查的时间比较长。
当时在作出判断三的时候,因为没在公司,不记得广告策略缓存key,导致不得不直接执行flushall命令直接清空缓存,再重新刷入缓存,这样做其实是有风险的,因为把广告策略、用户、分组等信息从缓存清空之后,用户的广告请求只能直接去查询数据库,这样响应的时间肯定会慢了,而且缓存中还存了广告请求的日志记录,直接flushall就会丢失部分的广告请求数据,影响到PV、UV统计。所以当时也是想就是有一个系统,在浏览器直接输入一个用户名或是图片名,就能从数据库和缓存查询到中涉及到相关联的数据,以可视化的形式在页面展示,这样定位问题也就可以更快定位问题了。于是也就是后期跟老大确认做一个问题定位辅助系统,这样方便定位问题
四、引申
语法规则: location [=|~|~*|^~] /uri/ { … }
= 开头表示精确匹配
^~ 开头表示uri以某个常规字符串开头,理解为匹配 url路径即可。nginx不对url做编码,因此请求为/static/20%/aa,可以被规则^~ /static/ /aa匹配到(注意是空格)。
~ 开头表示区分大小写的正则匹配
~* 开头表示不区分大小写的正则匹配
!~和!~*分别为区分大小写不匹配及不区分大小写不匹配 的正则
/ 通用匹配,任何请求都会匹配到。
多个location配置的情况下匹配顺序为(参考资料而来,还未实际验证,试试就知道了,不必拘泥,仅供参考):
首先匹配 =,其次匹配^~, 其次是按文件中顺序的正则匹配,最后是交给 / 通用匹配。当有匹配成功时候,停止匹配,按当前匹配规则处理请求。
例子,有如下匹配规则:
[plain] view plain copy
location = / {
#规则A
}
location = /login {
#规则B
}
location ^~ /static/ {
#规则C
}
location ~ \\.(gif|jpg|png|js|css)$ {
#规则D
}
location ~* \\.png$ {
#规则E
}
location !~ \\.xhtml$ {
#规则F
}
location !~* \\.xhtml$ {
#规则G
}
location / {
#规则H
}
那么产生的效果如下:
访问根目录/, 比如http://localhost/ 将匹配规则A
访问 http://localhost/login 将匹配规则B,http://localhost/register 则匹配规则H
访问 http://localhost/static/a.html 将匹配规则C
访问 http://localhost/a.gif, http://localhost/b.jpg 将匹配规则D和规则E,但是规则D顺序优先,规则E不起作用,而 http://localhost/static/c.png 则优先匹配到 规则C
访问 http://localhost/a.PNG 则匹配规则E, 而不会匹配规则D,因为规则E不区分大小写。
访问 http://localhost/a.xhtml 不会匹配规则F和规则G,http://localhost/a.XHTML不会匹配规则G,因为不区分大小写。规则F,规则G属于排除法,符合匹配规则但是不会匹配到,所以想想看实际应用中哪里会用到。
访问 http://localhost/category/id/1111 则最终匹配到规则H,因为以上规则都不匹配,这个时候应该是nginx转发请求给后端应用服务器,比如FastCGI(php),tomcat(jsp),nginx作为方向代理服务器存在。
学习本就是一个不断模仿、练习、再到最后面自己原创的过程。
虽然可能从来不能写出超越网上通类型同主题博文,但为什么还是要写?
于自己而言,博文主要是自己总结。假设自己有观众,毕竟讲是最好的学(见下图)。于读者而言,笔者能在这个过程get到知识点,那就是双赢了。
当然由于笔者能力有限,或许文中存在描述不正确,欢迎指正、补充!
感谢您的阅读。如果本文对您有用,那么请点赞鼓励。

以上是关于记一次nginx配置不当引发的499与failover 机制失效的主要内容,如果未能解决你的问题,请参考以下文章