python 字符编码
Posted 战斗小人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 字符编码相关的知识,希望对你有一定的参考价值。
前置知识点:
1、程序执行的三大核心硬件(***):
cpu
内存
硬盘
正常执行一个程序的要点:
1、将硬盘中的数据读到内存
2、由cpu读内存中的数据进行执行
3、在执行程序的时候,生成的数据,优先存入内存
2、python解释器执行一个py文件过程(***)
如果没有python解释器,py文件单纯就是一个文本文件
所以说,想执行py文件,必须先执行python解释器
1、将python解释器的代码由硬盘读到内存
2、将py文件以普通文本文件的格式由硬盘读到内存
3、python解释器去内存中读取py文件的数据
4、识别python语法,执行相应的操作
ps:任何一个文本编辑器的执行,前两部都一样
字符编码:
字符:世界上一切语言、文字
文件的输入和输出是两个过程
人类输入的内容都是人类自己可以识别的字符
计算机只能识别0101010二进制字符
将人类的字符,存入内存和硬盘,要经历一个过程:
人类的字符 >>>>>>> (字符编码表) >>>> 计算机二进制
ASCII码表(美国)
用八位二进制来代表一个英文字符(所有的英文字符+符号一共大概128左右)
0000 0000
1111 1111
最多只能表示255位
GBK(中国)
用2个bytes来代表一个字符,兼容英文字符
0000 0000 0000 0000
1111 1111 1111 1111
最多可以表示65535位
万国码(unicode)
为了兼容所有的国家的字符,生成unicode
所有的字符都用2bytes
0110 0001 a字母对应ASKII
0000 0000 0110 0001 a字母对应unicode
1、占用存储空间
2、io次数增加,程序运行速度变慢(最致命)
在unicode二进制数据存入硬盘的时候,做优化
utf-8:
utf-8只与unicode有对应关系
unicode transformation format
所有的英文字符用1个bytes表示
所有的中文字符用3个bytes表示
现在的计算机:
内存都是:unicode
硬盘都是:utf-8
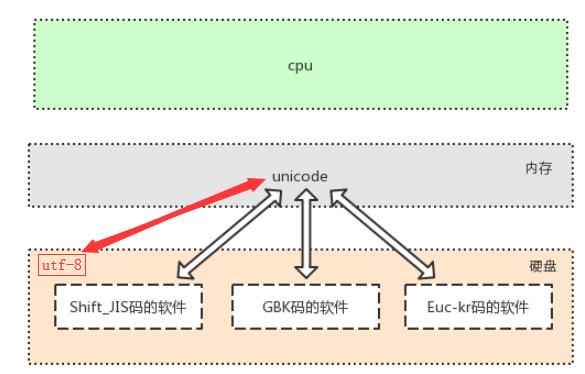
需要掌握:
1、用户无论输入什么字符,存入内存,unicode都可以兼容
2、硬盘中无论是什么编码的文件,读到内存,都可以兼容unicode
数据的传输:
优先以自己的本国字符编码进行传递
必须掌握(******)
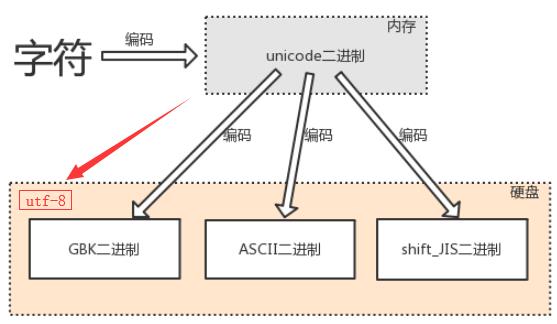
(内存)unicode二进制字符 >>> 编码(encode) >>> (硬盘)utf-8二进制字符
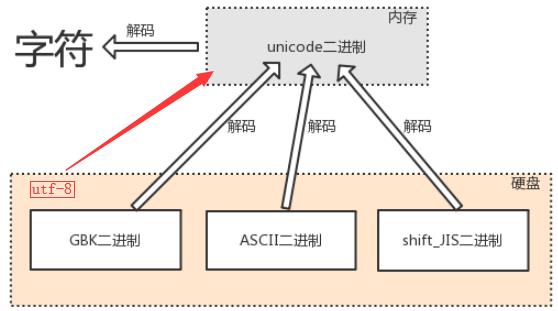
(硬盘)utf-8二进制字符 >>> 解码(decode) >>> (内存)unicode二进制字符
(******)
保证不乱码核心:
用什么编码存的数据,就用什么编码取
pycharm默认的字符编码是:
utf-8
windows操作系统默认字符编码:
gbk
----------------------------------------
python2 :
默认的字符编码ascii码(因为当时的unicode还没盛行)
python3:
默认的字符编码utf-8
文件头:
# coding:utf-8 (pycharm自动切换字符编码。python2要加文件头,不然为ascii码)
用英文字符,是为了让所有的计算机都可以识别
pycharm默认的字符编码是:
utf-8
windows操作系统默认字符编码:
gbk
编码,解码:
编码encode
解码decode
x = \'蝙蝠侠\' #在python3,\'蝙蝠侠\'被存为unicode res =x.encode(\'gbk\') # (编码)默认给它当成二进制 print(\'unicode转gbk\',res) # unicode转gbk b\'\\xf2\\xf9\\xf2\\xf0\\xcf\\xc0\' print(\'gbk类型为:\',type(res)) # gbk类型为: <class \'bytes\'> res1 = res.decode(\'gbk\') # 解码 print(\'gbk转unicode:\',res1) # gbk转unicode: 蝙蝠侠
字符串:
python2:str本质其实是一个拥有8个bit位的序列
python3:str本质其实是unicode序列
注:python2的盛行早于unicode,因此在python2中是按照文件头指定的编码来存储字符创类型的(如果文件头没有指定编码,那么解释器会按照它自己默认的编码方式来存储),所以,这就可能导致乱码问题

以上是关于python 字符编码的主要内容,如果未能解决你的问题,请参考以下文章