Python两招轻松爬取美团评论
Posted shannian999
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python两招轻松爬取美团评论相关的知识,希望对你有一定的参考价值。
结果很多读者对爬数据的过程比较感兴趣,那么今天就讲一下我是怎样获取美团数据,其实并不难,甚至还因为需要手动干预而显得有点不太聪明的样子。

店铺评论数据
在重庆火锅的文章中,我们一共爬取了每个店铺基本信息与对应评价两种数据,那么较为简单的就是评论数据,我们进入一个店铺的详情页 , F12查找数据包 就能轻松找到对应的评论数据
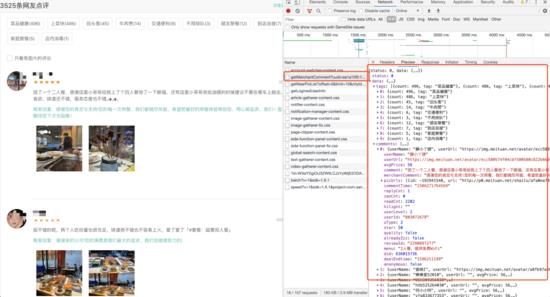
所以想拿下这一页的评论只要将 headers 中一些参数加进去使用 Requests.get 请求即可,注意 Cookie 是必须要添加的
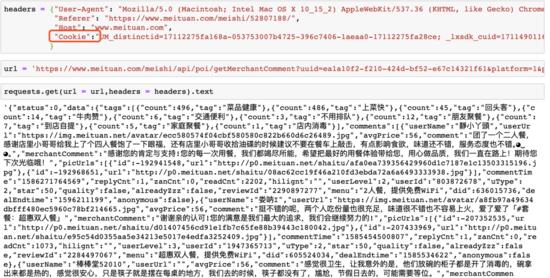
那么返回的json数据无论直接提取数据还是使用正则查找数据都不是困难的,提取之后使用Pandas保存即可,此处就不在赘述,如果需要 爬取多页评论 怎么办,先手动加载多页评论发现URL中仅有 offset 参数变了,每页增加10

所以只要 写个简单的循环生成多页URL就能拿下指定页数 的评论,OK这仅是一家店铺的评论爬取办法,那怎么获得多家店铺的评论呢?如果我们多找几家店铺的评论数据查看会发现,不同店铺对应的Request URL其实 变化的只有店铺的ID

所以下面的问题就转换为 如何拿到多家店铺的ID ,而这些ID都在搜索页面下的 店铺基本数据中。
店铺基本数据
为了找到店铺ID,让 我们回到搜索页面中(美团首页—美食—火锅)
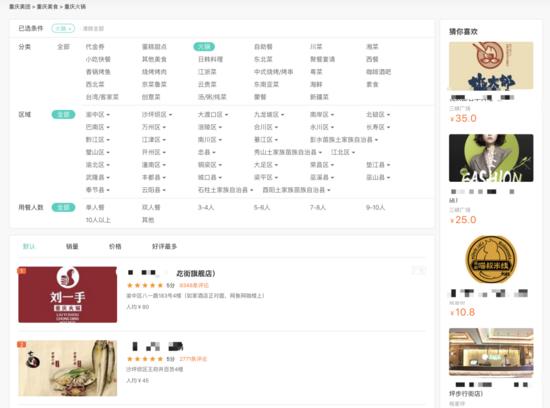
上面的页面中就是重庆火锅的第一页,还是 F12刷新很容易就能找到包含店铺ID、均价等相关信息的数据包
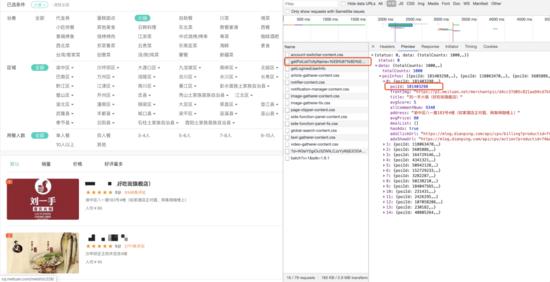
所以也能轻松的获取 Request URL

和上一节取评论的方法一样,修改对应的headers信息再使用requests请求即可,然后将店铺基本信息存下来用于分析,再将 ID单独存储用于组合评论页URL
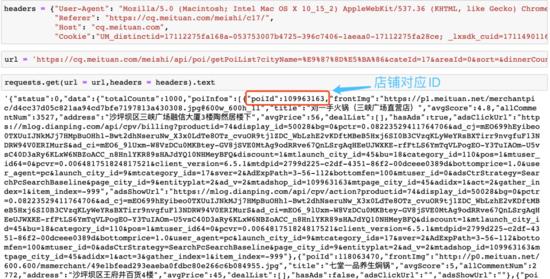
当然这只是第一页的url的返回数据,只要 修改其中的 page 参数 就能生成多页URL从而获取多页数据

以为这就结束了?并不是, 评论页的URL是不变的,但是这里的URL过几分钟就会变一下 ,也就是说如果你一次性生成10页或更多的URL去循环请求很有可能在中间这个URL就挂掉了,所以你直接在浏览器中打开这个URL 提示请求被拒绝 ,而不是显示对应的json值,就说明URL换了,解决办法只有 在URL更换的时候重新手动获取最新的URL并重新组合剩下需要爬取的页面 ,有点蠢但是因为更换的部分并没啥规律所以好像也没什么更好的办法......
结束语
以上就是我如何爬取美团店铺和评论数据的一些说明,看上去也并不难无非就是 Requests爬取+Pandas清洗 即可,由于变化的URL甚至没法开一个线程取ID另一个线程取评论而显得不太聪明。回顾一下不就是在一级搜索页面 通过代码+手动调整 取一些店铺的ID和其他基本信息,再去店铺详情页用同样的方法 利用刚刚取得的ID来爬取不同店铺的评论数据 即可。并没有什么高级操作,所以我不再提供具体爬取与清洗数据的相关代码(事实上也很容易失效)!
注1:爬下来的数据仅限学习研究使用!
注2:爬取过程请一定记得设置请求频率以及代理池,不然很容易封IP!
以上是关于Python两招轻松爬取美团评论的主要内容,如果未能解决你的问题,请参考以下文章