hive on spark报错
Posted 凯文-高处不胜寒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive on spark报错相关的知识,希望对你有一定的参考价值。
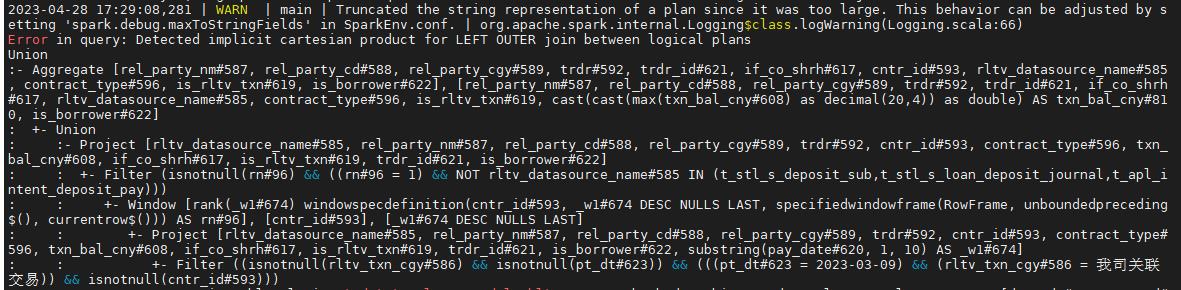
Error in query: Detected implicit cartesian product for LEFT OUTER join between logical plans
Union
Join condition is missing or trivial.
Either: use the CROSS JOIN syntax to allow cartesian products between these
relations, or: enable implicit cartesian products by setting the configuration
variable spark.sql.crossJoin.enabled=true;
解决:脚本是否有必要笛卡尔,如果确实需要的话设置:set spark.sql.crossJoin.enabled=true; --开启笛卡尔积,放在sql的第一句

Error in query: cannot resolve \'`tl.rgs_exp_dt`\' given input columns:[];line 137 pos 9;
解决:sql脚本问题,本次是因为order by字段没在group by里,出现这种问题是因为提示行附近的sql字段名没有定义准确
hive on spark hql 插入数据报错 Failed to create Spark client for Spark session Error code 30041
文章目录
一、遇到问题
离线数仓 hive on spark 模式,hive 客户端 sql 插入数据报错
Failed to execute spark task, with exception 'org.apache.hadoop.hive.ql.metadata.HiveException(Failed to create Spark client for Spark session 50cec71c-2636-4d99-8de2-a580ae3f1c58)'
FAILED: Execution Error, return code 30041 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Failed to create Spark client for Spark session 50cec71c-2636-4d99-8de2-a580ae3f1c58
以下是报错详情:
[hadoop@hadoop102 ~]$ hive
which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/datafs/module/jdk1.8.0_212/bin:/datafs/module/hadoop-3.1.3/bin:/datafs/module/hadoop-3.1.3/sbin:/datafs/module/zookeeper-3.5.7/bin:/datafs/module/kafka/bin:/datafs/module/flume/bin:/datafs/module/mysql-5.7.35/bin:/datafs/module/hive/bin:/datafs/module/spark/bin:/home/hadoop/.local/bin:/home/hadoop/bin)
Hive Session ID = 7db87c21-d9fb-4e76-a868-770691199377
Logging initialized using configuration in jar:file:/datafs/module/hive/lib/hive-common-3.1.2.jar!/hive-log4j2.properties Async: true
Hive Session ID = 24cd3001-0726-482f-9294-c901f49ace29
hive (default)> show databases;
OK
database_name
default
Time taken: 1.582 seconds, Fetched: 1 row(s)
hive (default)> show tables;
OK
tab_name
student
Time taken: 0.118 seconds, Fetched: 1 row(s)
hive (default)> select * from student;
OK
student.id student.name
Time taken: 4.1 seconds
hive (default)> insert into table student values(1,'abc');
Query ID = hadoop_20220728195619_ded278b4-0ffa-41f2-9f2f-49313ea3d752
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Failed to execute spark task, with exception 'org.apache.hadoop.hive.ql.metadata.HiveException(Failed to create Spark client for Spark session 50cec71c-2636-4d99-8de2-a580ae3f1c58)'
FAILED: Execution Error, return code 30041 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Failed to create Spark client for Spark session 50cec71c-2636-4d99-8de2-a580ae3f1c58
hive (default)> [hadoop@hadoop102 ~]$
二、排查过程:
0、确认 hive、spark 版本
hive3.1.2:apache-hive-3.1.2-bin.tar.gz (重新编译之后的)
spark3.0.0:
+spark-3.0.0-bin-hadoop3.2.tgz
+spark-3.0.0-bin-without-hadoop.tgz
兼容性说明
注意:官网下载的 Hive 3.1.2 和 Spark 3.0.0 默认是不兼容的。因为 Hive3.1.2 支持的Spark版本是2.4.5,所以需要我们重新编译Hive3.1.2版本。
编译步骤:
官网下载Hive3.1.2源码,修改pom文件中引用的Spark版本为3.0.0,如果编译通过,直接打包获取jar包。如果报错,就根据提示,修改相关方法,直到不报错,打包获取jar包。
1、确认 SPARK_HOME 环境变量
[hadoop@hadoop102 software]$ sudo vim /etc/profile.d/my_env.sh
# 添加如下内容
# SPARK_HOME
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin
source 使其生效
[hadoop@hadoop102 software]$ source /etc/profile.d/my_env.sh
2、hive 创建的 spark 配置文件
在hive中创建spark配置文件
[atguigu@hadoop102 software]$ vim /opt/module/hive/conf/spark-defaults.conf
# 添加如下内容(在执行任务时,会根据如下参数执行)
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
3、确认是否创建 hdfs 存储历史日志路径
确认存储历史日志路径是否创建
[hadoop@hadoop102 conf]$ hdfs dfs -ls /
Found 4 items
drwxr-xr-x - hadoop supergroup 0 2022-07-28 20:31 /spark-history
drwxr-xr-x - hadoop supergroup 0 2022-03-15 16:42 /test
drwxrwx--- - hadoop supergroup 0 2022-03-16 09:14 /tmp
drwxrwxrwx - hadoop supergroup 0 2022-07-28 18:38 /user
若不存在,则需要在HDFS创建如下路径
[hadoop@hadoop102 software]$ hadoop fs -mkdir /spark-history
4、确认 是否上传 Spark 纯净版 jar 包
说明1:由于Spark3.0.0非纯净版默认支持的是hive2.3.7版本,直接使用会和安装的Hive3.1.2出现兼容性问题。所以采用Spark纯净版jar包,不包含hadoop和hive相关依赖,避免冲突。
说明2:Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到。
[hadoop@hadoop102 software]$ tar -zxvf /opt/software/spark-3.0.0-bin-without-hadoop.tgz
上传Spark纯净版jar包到HDFS
[hadoop@hadoop102 software]$ hadoop fs -mkdir /spark-jars
[hadoop@hadoop102 software]$ hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars
5、确认 hive-site.xml 配置文件
[hadoop@hadoop102 ~]$ vim /opt/module/hive/conf/hive-site.xml
添加如下内容
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop102:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
三、解决问题
在 hive/conf/hive-site.xml中追加:
(这里延长了 hive 和 spark 连接的时间,可以有效避免超时报错)
<!--Hive和spark连接超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>100000ms</value>
</property>
这时,重新打开 hive 客户端,插入数据正常无报错
[hadoop@hadoop102 conf]$ hive
which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/datafs/module/jdk1.8.0_212/bin:/datafs/module/hadoop-3.1.3/bin:/datafs/module/hadoop-3.1.3/sbin:/datafs/module/zookeeper-3.5.7/bin:/datafs/module/kafka/bin:/datafs/module/flume/bin:/datafs/module/mysql-5.7.35/bin:/datafs/module/hive/bin:/datafs/module/spark/bin:/home/hadoop/.local/bin:/home/hadoop/bin)
Hive Session ID = b7564f00-0c04-45fd-9984-4ecd6e6149c2
Logging initialized using configuration in jar:file:/datafs/module/hive/lib/hive-common-3.1.2.jar!/hive-log4j2.properties Async: true
Hive Session ID = e4af620a-8b6a-422e-b921-5d6c58b81293
hive (default)>
插入第一条数据,需要初始化 spark session 所以慢
hive (default)> insert into table student values(1,'abc');
Query ID = hadoop_20220728201636_11b37058-89dc-4050-a4bf-1dcf404bd579
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Running with YARN Application = application_1659005322171_0009
Kill Command = /datafs/module/hadoop-3.1.3/bin/yarn application -kill application_1659005322171_0009
Hive on Spark Session Web UI URL: http://hadoop104:38030
Query Hive on Spark job[0] stages: [0, 1]
Spark job[0] status = RUNNING
--------------------------------------------------------------------------------------
STAGES ATTEMPT STATUS TOTAL COMPLETED RUNNING PENDING FAILED
--------------------------------------------------------------------------------------
Stage-0 ........ 0 FINISHED 1 1 0 0 0
Stage-1 ........ 0 FINISHED 1 1 0 0 0
--------------------------------------------------------------------------------------
STAGES: 02/02 [==========================>>] 100% ELAPSED TIME: 40.06 s
--------------------------------------------------------------------------------------
Spark job[0] finished successfully in 40.06 second(s)
WARNING: Spark Job[0] Spent 16% (3986 ms / 25006 ms) of task time in GC
Loading data to table default.student
OK
col1 col2
Time taken: 127.46 seconds
hive (default)>
下面再插入数据就快了
hive (default)> insert into table student values(2,'ddd');
Query ID = hadoop_20220728202000_1093388b-3ec6-45e5-a9f1-1b07c64f2583
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Running with YARN Application = application_1659005322171_0009
Kill Command = /datafs/module/hadoop-3.1.3/bin/yarn application -kill application_1659005322171_0009
Hive on Spark Session Web UI URL: http://hadoop104:38030
Query Hive on Spark job[1] stages: [2, 3]
Spark job[1] status = RUNNING
--------------------------------------------------------------------------------------
STAGES ATTEMPT STATUS TOTAL COMPLETED RUNNING PENDING FAILED
--------------------------------------------------------------------------------------
Stage-2 ........ 0 FINISHED 1 1 0 0 0
Stage-3 ........ 0 FINISHED 1 1 0 0 0
--------------------------------------------------------------------------------------
STAGES: 02/02 [==========================>>] 100% ELAPSED TIME: 2.12 s
--------------------------------------------------------------------------------------
Spark job[1] finished successfully in 3.20 second(s)
Loading data to table default.student
OK
col1 col2
Time taken: 6.0 seconds
hive (default)>
查询数据
hive (default)> select * from student;
OK
student.id student.name
1 abc
2 ddd
Time taken: 0.445 seconds, Fetched: 2 row(s)
hive (default)> [hadoop@hadoop102 conf]$
四、后记
遇到问题,不放弃
网上搜索了很多解决方案,不靠谱的很多
靠谱的是这个大佬在 https://b23.tv/hzvzdJc 评论区写的


尝试到第三种思路,瞬间解决
第一条数据插入成功的那一刻,是久违的成就感,开心
分享这篇 blog,一是记录解决问题的过程,二是帮助萌新小白
我们下期见,拜拜!
以上是关于hive on spark报错的主要内容,如果未能解决你的问题,请参考以下文章