Python3标准库:urllib.parse分解URL
Posted 爱编程的小灰灰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python3标准库:urllib.parse分解URL相关的知识,希望对你有一定的参考价值。
1. urllib.parse分解URL
urllib.parse模块提供了一些函数,可以管理URL及其组成部分,这包括将URL分解为组成部分以及由组成部分构成URL。
1.1 解析
urlparse()函数的返回值是一个ParseResult对象,其相当于一个包含6个元素的tuple。
from urllib.parse import urlparse url = \'http://netloc/path;param?query=arg#frag\' parsed = urlparse(url) print(parsed)
通过元组接口得到的URL各部分分别是机制、网络位置、路径、路径段参数(由一个分号将路径分开)、查询以及片段。

尽管返回值相当于一个元组,但实际上它基于一个namedtuple,这是tuple的一个子类,除了可以通过索引访问,它还支持通过命名属性访问URL的各部分。属性API不仅更易于程序员使用,还允许访问tupleAPI中未提供的很多值。
from urllib.parse import urlparse url = \'http://user:pwd@NetLoc:80/path;param?query=arg#frag\' parsed = urlparse(url) print(\'scheme :\', parsed.scheme) print(\'netloc :\', parsed.netloc) print(\'path :\', parsed.path) print(\'params :\', parsed.params) print(\'query :\', parsed.query) print(\'fragment:\', parsed.fragment) print(\'username:\', parsed.username) print(\'password:\', parsed.password) print(\'hostname:\', parsed.hostname) print(\'port :\', parsed.port)
输入URL中可能提供用户名(username)和密码(password),如果没有提供就设置为None。主机名(hostname)与netloc值相同,全为小写并且去除端口值。如果有端口(port),则转换为一个整数,如果没有则设置为None。

urlsplit()函数可以替换urlparse(),但行为稍有不同,因为它不会从URL分解参数。
from urllib.parse import urlsplit url = \'http://user:pwd@NetLoc:80/p1;para/p2;para?query=arg#frag\' parsed = urlsplit(url) print(parsed) print(\'scheme :\', parsed.scheme) print(\'netloc :\', parsed.netloc) print(\'path :\', parsed.path) print(\'query :\', parsed.query) print(\'fragment:\', parsed.fragment) print(\'username:\', parsed.username) print(\'password:\', parsed.password) print(\'hostname:\', parsed.hostname) print(\'port :\', parsed.port)
由于没有分解参数,tuple API胡显示五个元素而不是6个,并且这里没有params属性。

要想从一个URL剥离出片段标识符,如从一个URL查找基页面名,可以使用urldefrag()。
from urllib.parse import urldefrag original = \'http://netloc/path;param?query=arg#frag\' print(\'original:\', original) d = urldefrag(original) print(\'url :\', d.url) print(\'fragment:\', d.fragment)
返回值是一个基于namedtuple的DefragResult,其中包含基URL和片段。

1.2 反解析
还可以利用一些方法把分解的URL的各个部分重新组装在一起,形成一个串。解析的URL对象有一个geturl()方法。
from urllib.parse import urlparse original = \'http://netloc/path;param?query=arg#frag\' print(\'ORIG :\', original) parsed = urlparse(original) print(\'PARSED:\', parsed.geturl())
geturl()只适用于urlparse()或urlsplit()返回的对象。

利用urlunparse()可以将包含串的普通元组重新组合为一个URL。
from urllib.parse import urlparse, urlunparse original = \'http://netloc/path;param?query=arg#frag\' print(\'ORIG :\', original) parsed = urlparse(original) print(\'PARSED:\', type(parsed), parsed) t = parsed[:] print(\'TUPLE :\', type(t), t) print(\'NEW :\', urlunparse(t))
尽管urlparse()返回的ParseResult可以作为一个元组,但这个例子却显式地创建了一个新元组,来展示urlunparse()也适用于普通元组。

如果输入URL包含多余的部分,那么重新构造的URL可能会将其去除。
from urllib.parse import urlparse, urlunparse original = \'http://netloc/path;?#\' print(\'ORIG :\', original) parsed = urlparse(original) print(\'PARSED:\', type(parsed), parsed) t = parsed[:] print(\'TUPLE :\', type(t), t) print(\'NEW :\', urlunparse(t))
在这里,原URL中没有参数、查询和片段。新URL看起来与原URL并不相同,不过按照标准它们是等价的。

1.3 连接
除了解析URL,urlparse还包括一个urljoin()方法,可以由相对片段构造绝对URL。
from urllib.parse import urljoin print(urljoin(\'http://www.example.com/path/file.html\', \'anotherfile.html\')) print(urljoin(\'http://www.example.com/path/file.html\', \'../anotherfile.html\'))
在这个例子中,计算第二个URL时要考虑路径的相对部分("../")。

非相对路径的处理与os.path.join()的处理方式相同。
from urllib.parse import urljoin print(urljoin(\'http://www.example.com/path/\', \'/subpath/file.html\')) print(urljoin(\'http://www.example.com/path/\', \'subpath/file.html\'))
如果连接到URL的路径以一个斜线开头(/),那么urljoin()会把URL的路径重置为顶级路径。如果不是以一个斜线开头,那么新路径值则追加到URL当前路径的末尾。

1.4 解码查询参数
参数在被增加到一个URL之前,需要先编码。
from urllib.parse import urlencode query_args = { \'q\': \'query string\', \'foo\': \'bar\', } encoded_args = urlencode(query_args) print(\'Encoded:\', encoded_args)
编码会替换诸如空格之类的特殊字符,以确保采用一种符合标准的格式将它们传递到服务器。
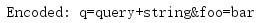
如果要利用查询串中的变量传递一个值序列,那么需要在调用urlencode()时将doseq设置为True。
from urllib.parse import urlencode query_args = { \'foo\': [\'foo1\', \'foo2\'], } print(\'Single :\', urlencode(query_args)) print(\'Sequence:\', urlencode(query_args, doseq=True))
结果是一个查询串,包含与一个名关联的多个值。

要解码这个查询串,可以使用parse_qs()或parse_qsl()。
from urllib.parse import parse_qs, parse_qsl encoded = \'foo=foo1&foo=foo2\' print(\'parse_qs :\', parse_qs(encoded)) print(\'parse_qsl:\', parse_qsl(encoded))
parse_qs()的返回值是一个将名映射到值的字典,而parse_qsl()返回一个元组列表,每个元组包含一个名和一个值。

查询参数中可能有一些特殊字符,会导致服务器端在解析URL时出问题,所以在传递到urlencode()时要对这些特殊字符“加引号”。要在本地对它们加引号以建立这些串的安全版本,可以直接使用quote()或quote_plus()函数。
from urllib.parse import quote, quote_plus, urlencode url = \'http://localhost:8080/~hellmann/\' print(\'urlencode() :\', urlencode({\'url\': url})) print(\'quote() :\', quote(url)) print(\'quote_plus():\', quote_plus(url))
quote_plus()中的加引号实现会更大程度的替换字符。

要完成加引号操作的逆过程,可以在适当的时候使用unquote()或unquote_plus()。
from urllib.parse import unquote, unquote_plus print(unquote(\'http%3A//localhost%3A8080/%7Ehellmann/\')) print(unquote_plus( \'http%3A%2F%2Flocalhost%3A8080%2F%7Ehellmann%2F\' ))
编码的值会转换回一个普通的URL串。

以上是关于Python3标准库:urllib.parse分解URL的主要内容,如果未能解决你的问题,请参考以下文章