如何用bert模型做翻译任务
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用bert模型做翻译任务相关的知识,希望对你有一定的参考价值。
BERT不可以做翻译任务,因为翻译任务是NLP生成式任务,BERT目前是不可以做的。BERT主要可以做的任务有下面几种:
1 文本分类任务,比如情感分类
2 序列标注任务,比如分词 实体识别 词性标注
3 句子关系判断,比如QA,自然语言推理 参考技术A 没有bert模型的说法,只有玻尔原子模型的说法。
原子结构示意图是表示原子核电荷数和电子层排布的图示形式,也叫做玻尔原子模型。小圈和圈内的数字表示原子核和核内质子数,弧线表示电子层,弧线上的数字表示该层的电子数。
核外电子是分层排列的,从里到外K、L、M、N、O、P、Q。
第一层最多两个电子,第二层最多8个电子,当电子层达或超过到三层时,倒数第二层不超过18个电子;当电子层超过四层时,倒数第三层最多不超过32个电子,最外层不超过8个电子。
如果所有的电子层都已排满,最外层有8个电子,这个结构叫做稳定结构(特殊的是稀有气体中的氦是最外层有两个电子)。
金属原子最外层电子数<4,易失电子,最外层电子数越少,越不稳定。
每层最多排2×(n)^2个电子。
非金属原子最外层电子数≥4 容易得到电子. 化学性质不稳定,最外层电子数越多,越不稳定。
稀有气体最外层电子数是八个,但氦是两个,达到最稳定状态,所以稀有气体性质十分稳定。
不管是什么原子,核电荷数=质子数=电子数,电量相等,电性相反,整个原子呈电中性。
原子结构示意图不仅可以表示中性原子,还能表示带电的原子—离子(包括阳离子和阴离子)核外电子排布的情况。
什么是共价化合物?共价化合物是怎样形成的?共价化合物是依靠共用电子对形成分子的化合物。
当两种非金属元素的原子形成分子时,由于两个原子都有通过得电子形成八电子稳定结构的趋势,它们得电子的能力差不多,谁也不可能把对方的电子夺过来,结果两个原子只能各提供一个电子形成共用电子对,在两个原子的核外空间运动,电子带负电,原子核带正电。两个原子的原子核同时吸引共用电子对,产生作用力,从而形成了一个分子,分子是由原子构成的。
由于两个原子对电子的吸引能力不一样,共用电子对总是偏向得电子能力强的一方,这一方的原子略显负电性,另一方的原子略显正电性,作为整体,分子仍显电中性。
比较典型的共价化合物是水、氯化氢以及二氧化碳。共用电子对总是偏向氧原子(氯原子)的一方,偏离氢原子(碳原子)的一方。
共价化合物一般硬度小,熔沸点低。
各电子层最多容纳的电子数目是2n2。 其次,最外层电子数目不超过8个(K层为最外层时不超过2个)。 第三,次外层电子数目不超过18个,倒数第三层电子数目不超过32个。 核外电子总是尽先排布在能量最低的电子层里,然后再由里往外依次排布在能量逐步升高的电子层里,这叫做能量最低原理。一般来说,离核较近的电子具有较低的能量,随着电子层数的增加,电子的能量越来越大;同一层中,各亚层的能量是按s、p、d、f的次序增高的。
一个电子的运动状态要从四个方面来进行描述,即它所处的电子层、电子亚层、电子云的伸展方向以及电子的自旋方向。在同一个原子中不可能有运动状态完全相同的两个电子存在,这就是保里不相容原理所告诉大家的。根据这个规则,如果两个电子处于同一轨道,那么,这两个电子的自旋方向必定相反。也就是说,每一个轨道中只能容纳两个自旋方向相反的电子。
s亚层只有1个轨道,可以容纳两个自旋相反的电子;p亚层有3个轨道,总共可以容纳6个电子;f亚层有5个轨道,总共可以容纳10个电子。
电子在原子核外排布时,将尽可能分占不同的轨道,且自旋平行;对于同一个电子亚层,当电子排布处于全满、半满或全空时比较稳定。
对于某元素原子的核外电子排布情况,先确定该原子的核外电子数(即原子序数、质子数、核电荷数),如24号元素铬,其原子核外总共有24个电子,然后将这24个电子从能量最低的1s亚层依次往能量较高的亚层上排布,只有前面的亚层填满后,才去填充后面的亚层,每一个亚层上最多能够排布的电子数为:s亚层两个,p亚层六个,d亚层十个,f亚层十四个。d亚层处于半充满时较为稳定,所以,24号元素铬的原子结构示意图应该是:小圈里写+24,各个电子层(弧线)上的电子数分别是2、8、13、1。
希望我能帮助你解疑释惑。
BERT实战:使用DistilBERT进行文本情感分类
这次根据一篇教程Jay Alammar: A Visual Guide to Using BERT for the First Time学习下如何在Pytorch框架下使用BERT。
主要参考了中文翻译版本
教程提供了可用的代码,可以在colab或者github获取。
1. huggingface/transformers
Transformers提供了数千个预训练的模型来执行文本任务,如100多种语言的分类、信息提取、问答、摘要、翻译、文本生成等。
文档:https://huggingface.co/transformers/
模型:https://huggingface.co/models
huggingface团队用pytorch复现许多模型,本次要使用它们提出的DistilBERT模型。
2. 数据集
本次使用的数据集是 SST2,是一个电影评论的数据集。用标签 0/1 代表情感正负。

3. 模型
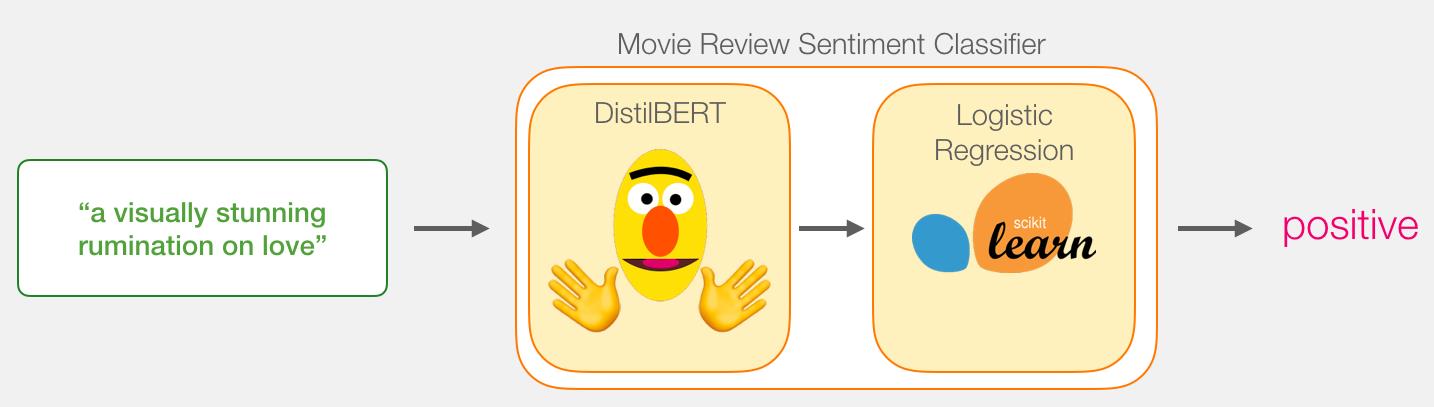
句子的情感分类模型由两部分组成:
- DistilBERT处理输入的句子,并将它从句子中提取的一些信息传递给下一个模型。 DistilBERT 是一个更小版本的 BERT 模型,是由 HuggingFace 团队开源的。它保留了 BERT 能力的同时,比 BERT 更小更快。
- 一个基本的 Logistic Regression 模型,它将处理 DistilBERT 的输出结果并且将句子进行分类,输出0或1。
在这两个模型之间传递的数据是一个 768 维的向量。
假设句子长度为n,那及一个句子经过BERT应该得到n个768 维的向量。
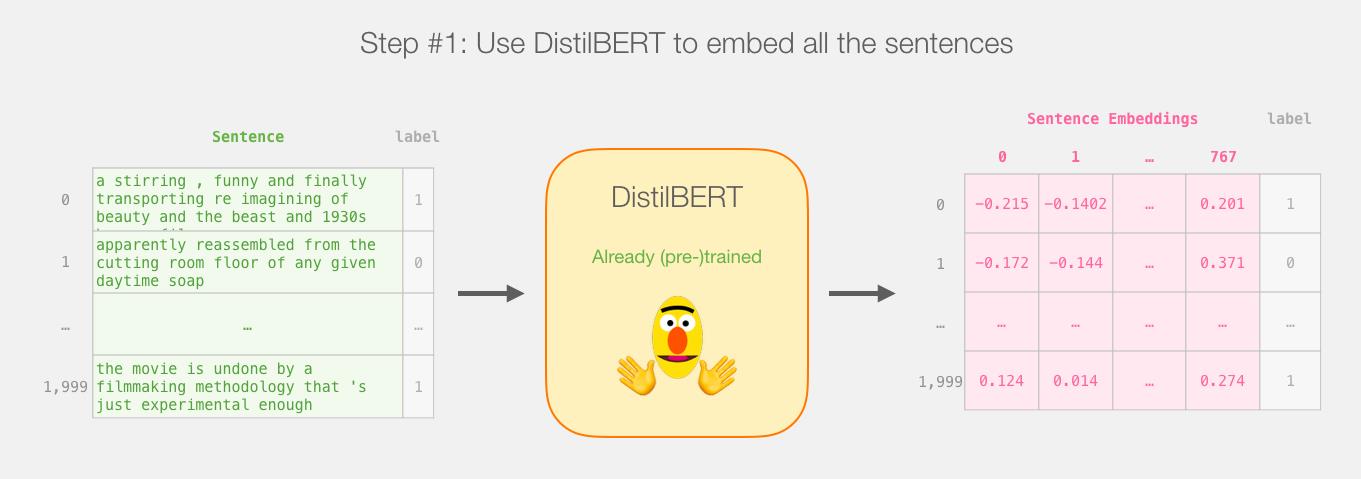
实际上只使用[CLS]位置的向量看作是我们用来分类的句子的embedding向量。
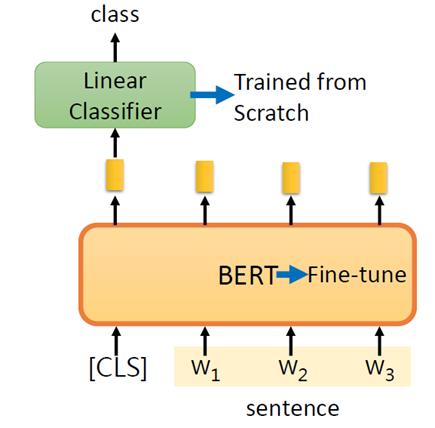
4. 训练与预测
4.1 训练
虽然我们使用了两个模型,但是只需要训练回归模型(Logistic Regression)即可。
对于 DistilBERT 模型,使用该模型预训练的参数即可,这个模型没有被用来做句子分类任务的训练和微调。
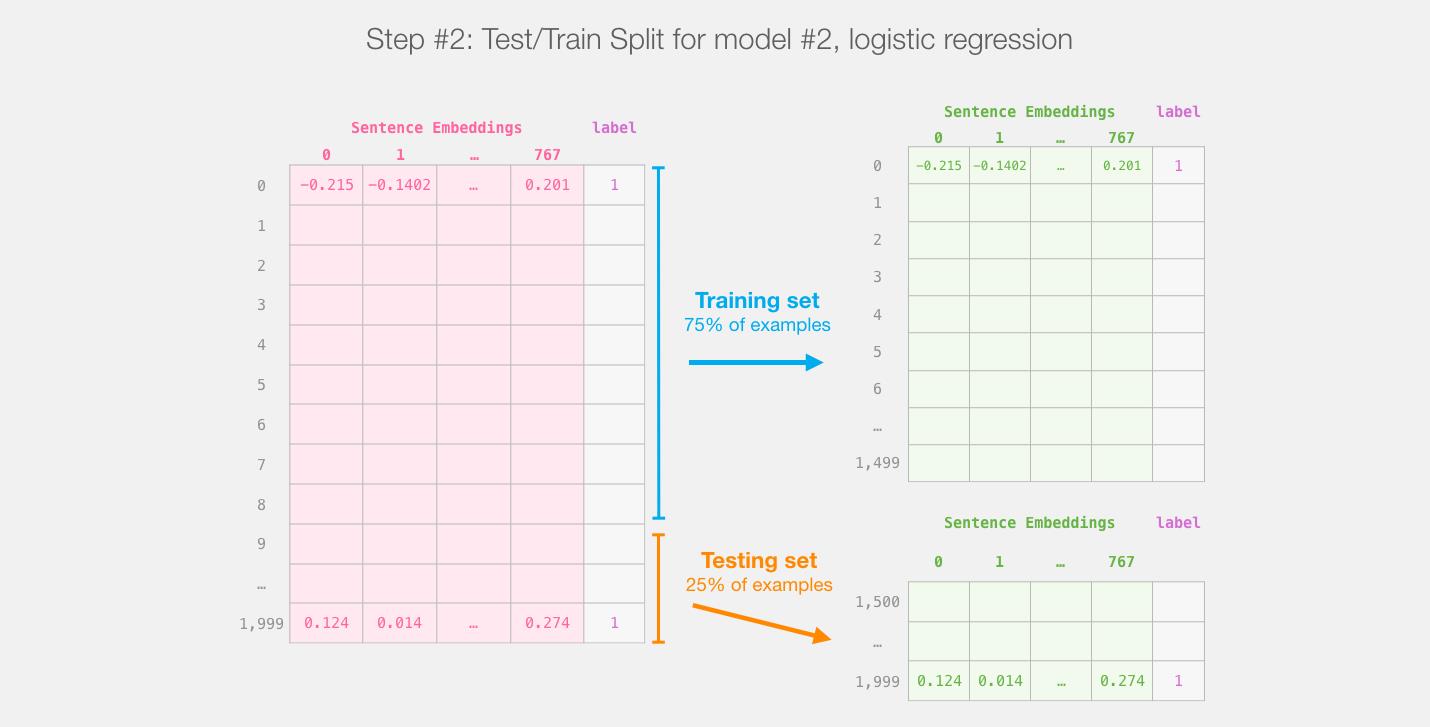
使用 Scikit Learn 工具包进行操作。将整个BERT输出的数据分成 train/test 数据集。
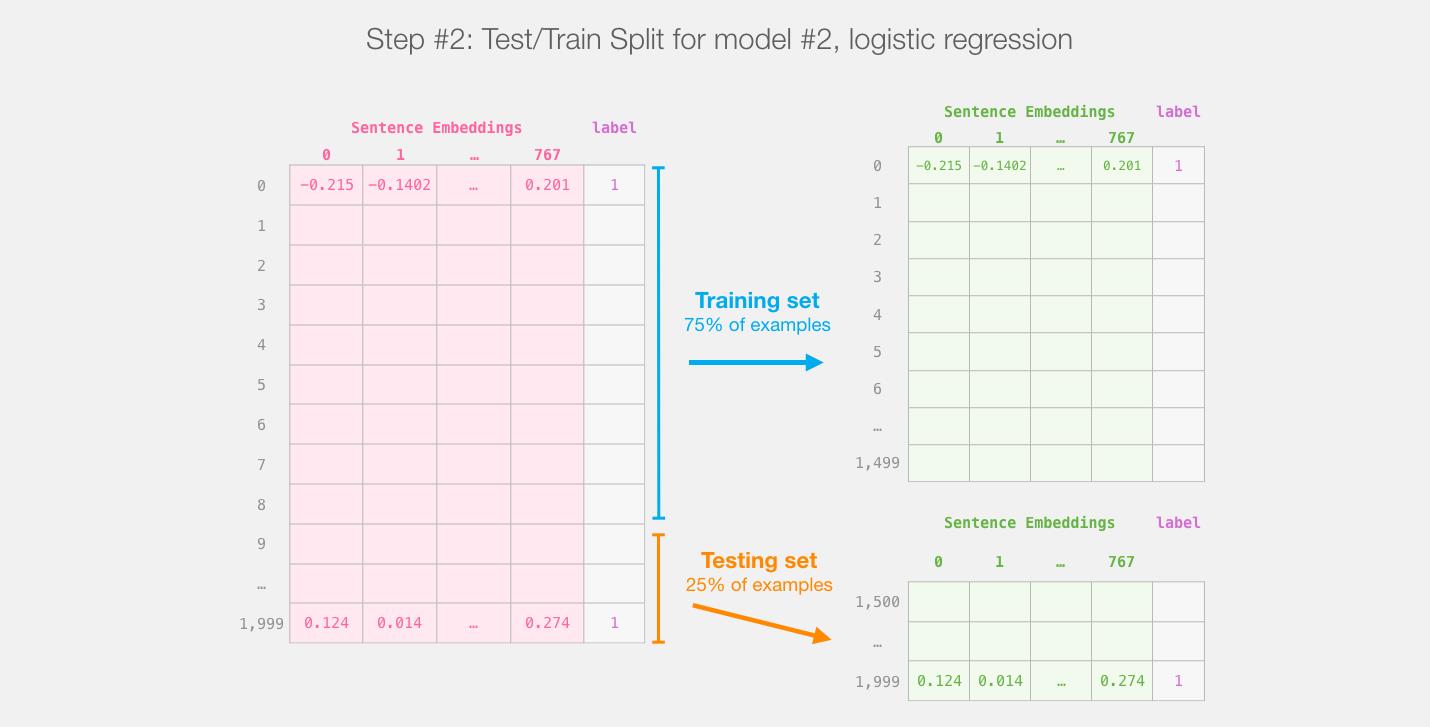
将75%的数据划为训练集,将25%的数据划分为测试集。
sklearn的train/test split在进行分割之前会对示例进行shuffles。
接下来就用机器学习的方法训练回归模型就行了。
4.2 预测
如何使用模型进行预测呢?
比如,我们要对句子 “a visually stunning rumination on love” 进行分类
第一步,用 BERT 的分词器(tokenizer)将句子分成 tokens;
第二步,添加特殊的 tokens 用于句子分类任务(在句子开头加上 [CLS],在句子结尾加上 [SEP]);
第三步,分词器(tokenizer)会将每个 token 替换成 embedding 表中的ID,embedding 表是我们预训练模型自带的;

下面这一行代码就完成了上述3步。
tokenizer.encode("a visually stunning rumination on love", add_special_tokens=True)
每个token的输出都是一个一个768维的向量。
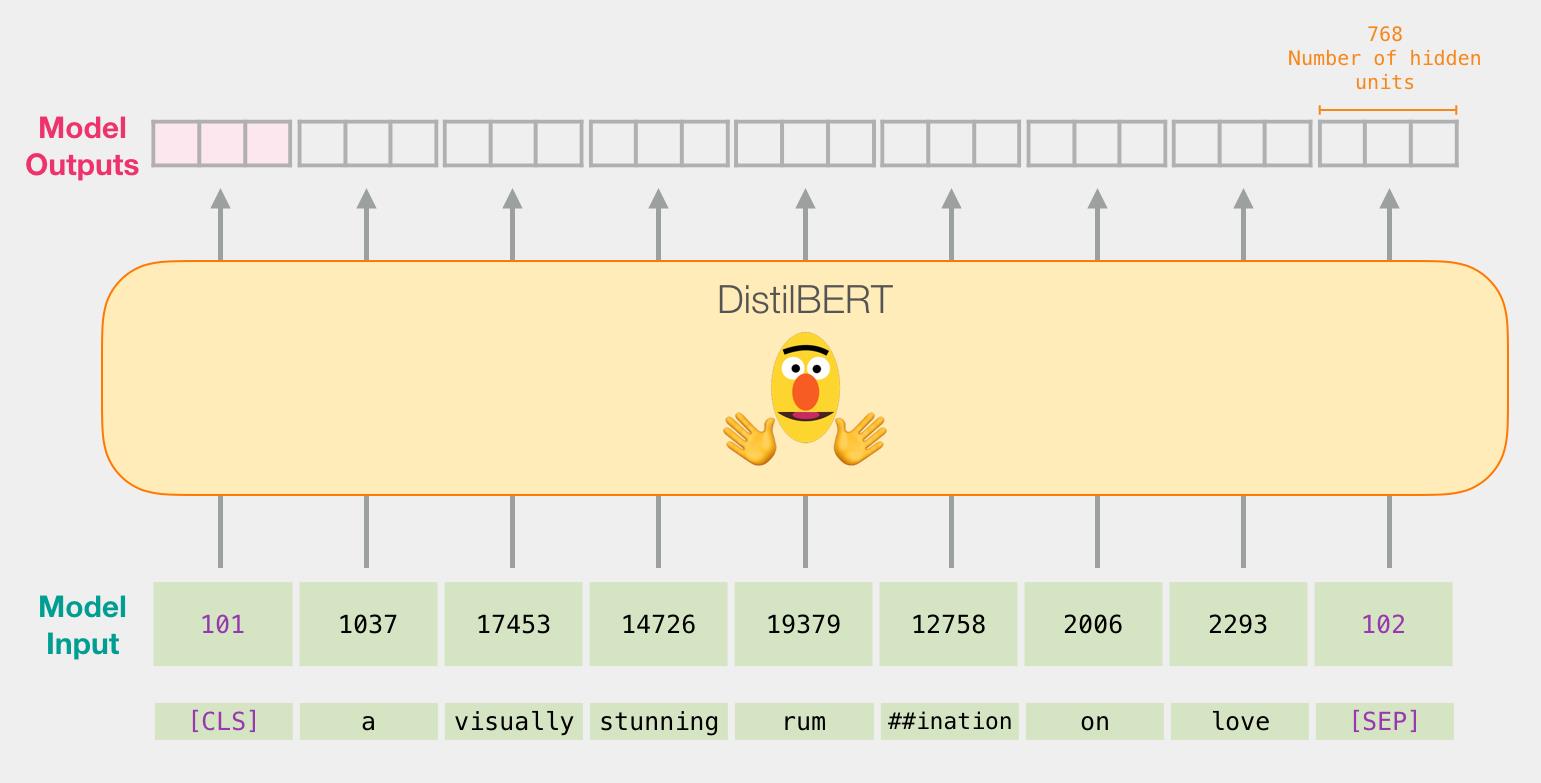
由于这是一个句子分类任务,我们只取第一个向量(与 [CLS] token有关的向量)而忽略其他的 token 向量。
将该向量作为 逻辑回归的输入。
5. 代码(加入图片注释)
环境的配置就不细说了,可以在transformers的github页面查阅
5.1 导入所需的工具包
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import torch
import transformers as ppb
import warnings
warnings.filterwarnings('ignore')
5.2 导入数据集
数据集的链接,这里我已经提前下载到本地了。
df = pd.read_csv('./train.tsv', delimiter='\\t', header=None)
# 为做示例只取前2000条数据
batch_1 = df[:2000]
# 查看正负例的数量
batch_1[1].value_counts()
5.3 导入预训练模型
下载大概花费了40s
# For DistilBERT:
model_class, tokenizer_class, pretrained_weights = (ppb.DistilBertModel, ppb.DistilBertTokenizer, 'distilbert-base-uncased')
## Want BERT instead of distilBERT? Uncomment the following line:
#model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
# Load pretrained model/tokenizer
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)
5.4 数据预处理
包括token化和padding
token化的过程与4.2中图片相同
tokenized = batch_1[0].apply((lambda x:tokenizer.encode(x, add_special_tokens = True)))
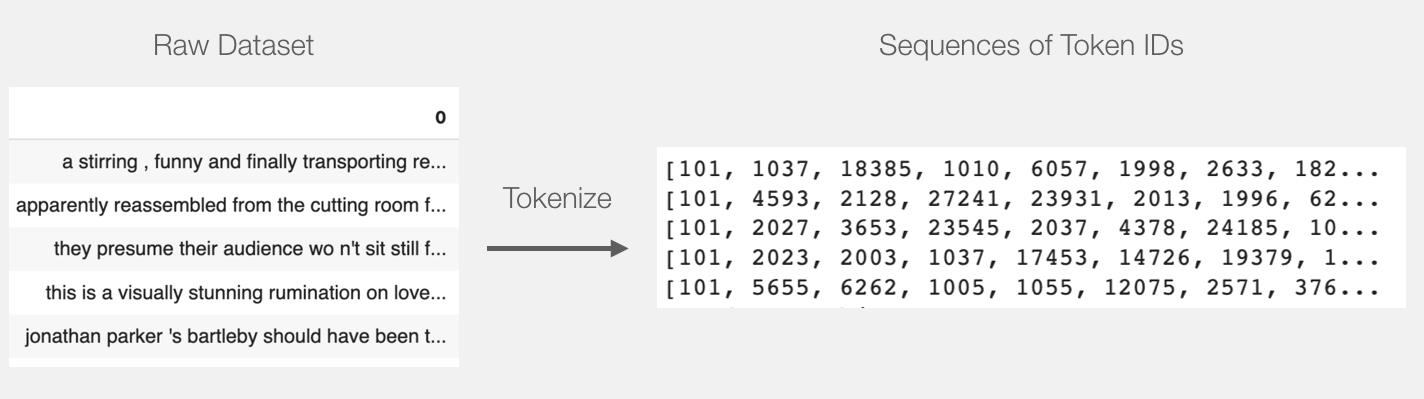
需要把所有的向量用 id 0 来填充较短的句子到一个相同的长度。
max_len = 0
for i in tokenized.values:
if len(i) > max_len:
max_len = len(i)
padded = np.array([i + [0] * (max_len - len(i)) for i in tokenized.values])
np.array(padded).shape
# Masking
# attention_mask(也就是input_mask)的0值只作用在padding部分
# np.where(condition, x, y) 满足条件(condition),输出x,不满足输出y
attention_mask = np.where(padded != 0, 1, 0)
attention_mask.shape
padding的过程如下图所示,值得注意的是
如果我们直接把padded发给BERT,那会让它有点混乱。
我们需要创建另一个变量,告诉它在处理输入时忽略(屏蔽)我们添加的填充。这就是attention_mask:

5.5 使用BERT
# 基本可以看作又进行了一次embedding
input_ids = torch.LongTensor(padded)
attention_mask = torch.tensor(attention_mask)
with torch.no_grad():
last_hidden_states = model(input_ids, attention_mask=attention_mask)
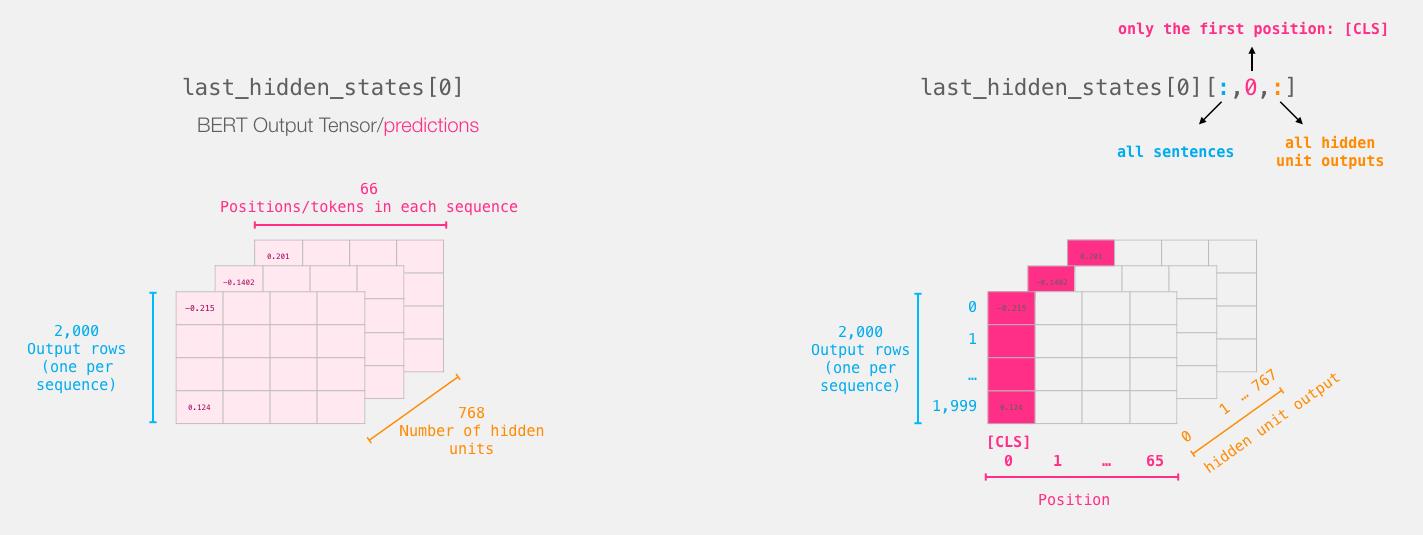
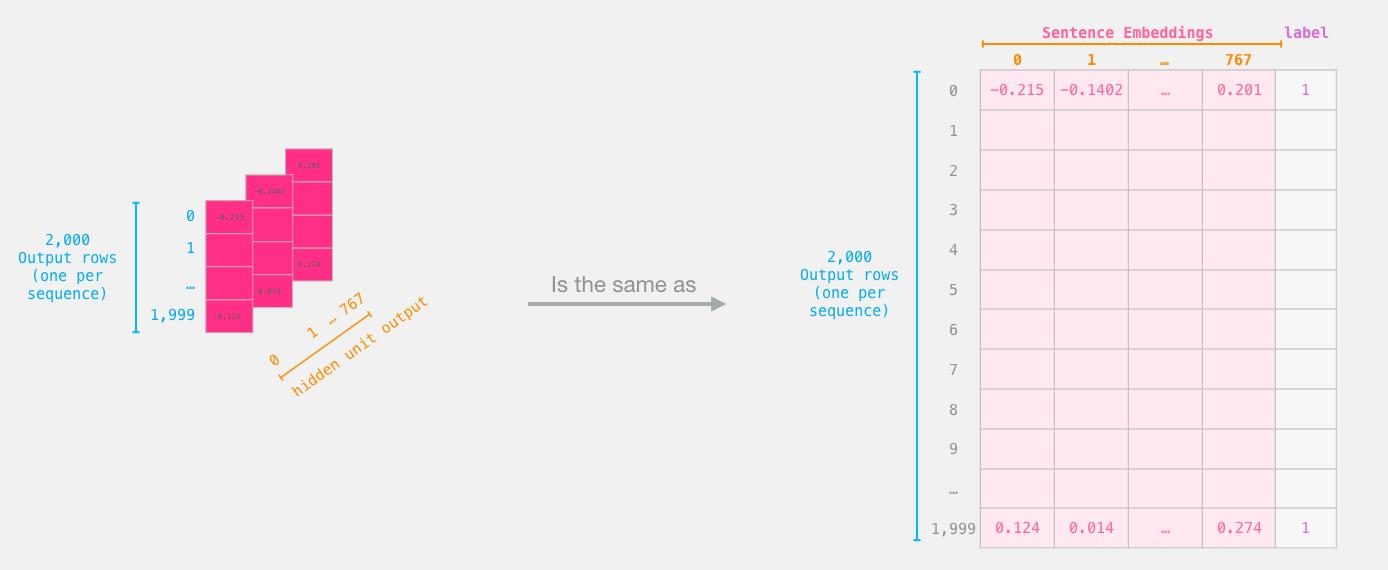
# BERT模型输出的张量尺寸为[2000, 59, 768]
# 取出[CLS]token对应的向量
features = last_hidden_states[0][:,0,:].numpy()
labels = batch_1[1] # 取出标签
5.5 训练一个Logistic回归模型
# 划分训练集和测试集
train_features, test_features, train_labels, test_labels = train_test_split(features, labels)
# 搜索正则化强度的C参数的最佳值。
parameters = {'C': np.linspace(0.0001, 100, 20)}
grid_search = GridSearchCV(LogisticRegression(), parameters)
grid_search.fit(train_features, train_labels)
print('best parameters: ', grid_search.best_params_)
print('best scrores: ', grid_search.best_score_)
lr_clf = LogisticRegression(C = 10.526405263157894)
lr_clf.fit(train_features, train_labels)
lr_clf.score(test_features, test_labels)
在使用完整数据集的时候,准确率约为0.847。
6.结果评估
from sklearn.dummy import DummyClassifier
clf = DummyClassifier()
scores = cross_val_score(clf, train_features, train_labels)
print("Dummy classifier score: %0.3f (+/- %0.2f)" % (scores.mean(), scores.std() * 2))
可以发现训练出的分类器的结果明显好于随即预测的结果。
但这个例子恐怕完全没有体现出BERT的性能,缺少了fine-tuning阶段。
该数据集上最高的准确率是 96.8. (根据19年的教程)
通过fine-tuning 更新 BERT 的参数权重, 可以提升DistilBERT 模型在句子分类任务(称为下游任务)上得到的分数。
通过对 DistilBERT 进行 fine-tuned 之后达到了 90.7 的准确率。
全尺寸的 BERT 模型能达到 94.9 的分数。
以上是关于如何用bert模型做翻译任务的主要内容,如果未能解决你的问题,请参考以下文章