1.需求描述
爬取hao6v电影网的数据,先通过xpath解析第一个页面,获取到每部电影的url详情页地址,然后解析详情页地址,获取出所需的数据
页面如下:
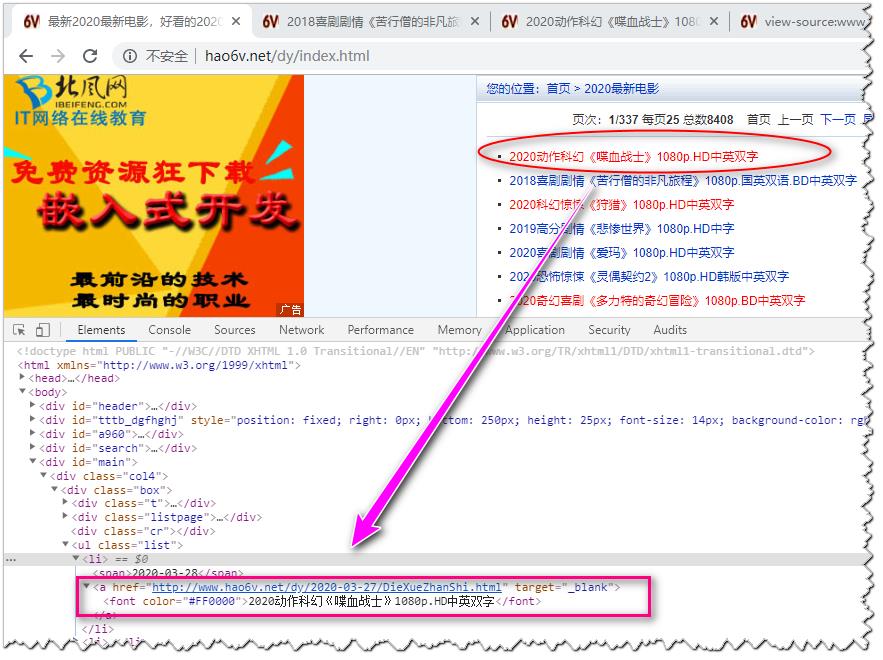
2.实现代码
# Author:Logan
import requests
from lxml import etree
HEADERS = {
\'User-Agent\':\'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36\'
}
def get_detail_urls(url):
response = requests.get(url, headers=HEADERS)
html_str = response.text
# 获取数据
html = etree.HTML(html_str)
ul = html.xpath("//ul[@class=\'list\']/li/a/@href")
urls_list =list()
for li in ul:
urls_list.append(li)
return urls_list
def parse_detail_page(detail_url):
response = requests.get(detail_url,headers=HEADERS)
html_str = response.content.decode(\'GBK\')
html = etree.HTML(html_str)
# 定义字典存储电影信息
movie = dict()
# 获取电影名字
movie[\'title\'] = html.xpath("//div[@id=\'endText\']/strong/a/text()")[0]
infos = html.xpath("//div[@id=\'endText\']/p/text()")
for index,info in enumerate(infos):
info = info.strip()
# print(\'=\' * 30)
# print(index,info)
if info.startswith("◎年 代"):
movie[\'year\'] = info.replace(\'◎年 代\',\'\').strip()
elif info.startswith("◎IMDb评分"):
movie[\'IMDBscore\'] = info.replace(\'◎IMDb评分\', \'\').strip()
elif info.startswith("◎片 长"):
movie[\'duration\'] = info.replace(\'◎片 长\', \'\').strip()
elif info.startswith("◎导 演"):
movie[\'direction\'] = info.replace(\'◎导 演\', \'\').strip()
elif info.startswith("◎主 演"):
info = info.replace(\'◎主 演\', \'\').strip()
actors = [info]
for x in range(index+1, len(infos)):
actor = infos[x].strip()
if actor.startswith("◎"):
break
actors.append(actor)
movie[\'actors\'] = actors
return movie
def main():
# 1.构造url地址
base_url = \'http://www.hao6v.net/dy/index_{}.html\'
for i in range(1,2):
if i == 1:
url = base_url.replace(\'_{}\',\'\')
else:
url = base_url.format(i)
# 2.获取详细地址
urls_list = get_detail_urls(url)
# 3.解析详情页面
movie_detail_info = list()
for detail_url in urls_list:
movie = parse_detail_page(detail_url)
movie_detail_info.append(movie)
print(movie_detail_info)
if __name__ == \'__main__\':
main()
运行结果如下:
