Python实现简易HTTP服务器与MINI WEB框架(利用WSGI实现服务器与框架解耦)
Posted 风间悠香
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python实现简易HTTP服务器与MINI WEB框架(利用WSGI实现服务器与框架解耦)相关的知识,希望对你有一定的参考价值。
本文描述如果简单实现自定义Web服务器与自定义简易框架,并且不断进行版本迭代,从而清晰的展现服务器与Web框架之间是如何结合、如何配合工作的。以及WSGI是什么。
本文帖的代码有点多,但基本每次迭代修改的地方很少(为了每一节相对完整,所以重复代码比较多),注意看代码中黄色背景的部分,即是修改的部分。
一、选取一个自定义的服务器版本
参照 https://www.cnblogs.com/leokale-zz/p/11957768.html 中的各种服务器实现版本,我们选择比较简单的多进程版本作为演示版本。
代码如下:
import socket import re import multiprocessing def handle_request(new_socket): # 接收请求 recv_msg = "" recv_msg = new_socket.recv(1024).decode("utf-8") if recv_msg == "": print("recv null") new_socket.close() return # 从请求中解析出URI recv_lines = recv_msg.splitlines() print(recv_lines.__len__()) # 使用正则表达式提取出URI ret = re.match(r"[^/]+(/[^ ]*)", recv_lines[0]) if ret: # 获取URI字符串 file_name = ret.group(1) # 如果URI是/,则默认返回index.html的内容 if file_name == "/": file_name = "/index.html" try: # 根据请求的URI,读取相应的文件 fp = open("." + file_name, "rb") except: # 找不到文件,响应404 response_msg = "HTTP/1.1 404 NOT FOUND\\r\\n" response_msg += "\\r\\n" response_msg += "<h1>----file not found----</h1>" new_socket.send(response_msg.encode("utf-8")) else: html_content = fp.read() fp.close() # 响应正确 200 OK response_msg = "HTTP/1.1 200 OK\\r\\n" response_msg += "\\r\\n" # 返回响应头 new_socket.send(response_msg.encode("utf-8")) # 返回响应体 new_socket.send(html_content) # 关闭该次socket连接 new_socket.close() def main(): # 创建TCP SOCKET实例 tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # # 设置重用地址 # tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) # 绑定地址(默认本机IP)和端口 tcp_server_socket.bind(("", 7890)) # 监听 tcp_server_socket.listen(128) # 循环接收客户端连接 while True: new_socket, client_addr = tcp_server_socket.accept() # 启动一个子进程来处理客户端的请求 sub_p = multiprocessing.Process(target=handle_request, args=(new_socket,)) sub_p.start() # 这里要关闭父进程中的new_socket,因为创建子进程会复制一份new_socket给子进程 new_socket.close() # 关闭整个SOCKET tcp_server_socket.close() if __name__ == "__main__": main()
二、将代码用面向对象思想改写
import socket import re import multiprocessing class WSGIServer(object): def __init__(self): # 创建socket实例 self.tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 设置资源重用 self.tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) # 绑定IP端口 self.tcp_server_socket.bind(("", 7890)) # 开始监听 self.tcp_server_socket.listen(128) # 请求处理函数 def handle_request(self, new_socket): # 接收请求 recv_msg = "" recv_msg = new_socket.recv(1024).decode("utf-8") if recv_msg == "": print("recv null") new_socket.close() return # 从请求中解析出URI recv_lines = recv_msg.splitlines() # 使用正则表达式提取出URI ret = re.match(r"[^/]+(/[^ ]*)", recv_lines[0]) if ret: # 获取URI字符串 file_name = ret.group(1) # 如果URI是/,则默认返回index.html的内容 if file_name == "/": file_name = "/index.html" try: # 根据请求的URI,读取相应的文件 fp = open("." + file_name, "rb") except: # 找不到文件,响应404 response_msg = "HTTP/1.1 404 NOT FOUND\\r\\n" response_msg += "\\r\\n" response_msg += "<h1>----file not found----</h1>" new_socket.send(response_msg.encode("utf-8")) else: html_content = fp.read() fp.close() # 响应正确 200 OK response_msg = "HTTP/1.1 200 OK\\r\\n" response_msg += "\\r\\n" # 返回响应头 new_socket.send(response_msg.encode("utf-8")) # 返回响应体 new_socket.send(html_content) # 关闭该次socket连接 new_socket.close() # 开始无限循环,接受请求 def run_forever(self): while True: new_socket, client_addr = self.tcp_server_socket.accept() # 启动一个子进程来处理客户端的请求 sub_p = multiprocessing.Process(target=self.handle_request, args=(new_socket,)) sub_p.start() # 这里要关闭父进程中的new_socket,因为创建子进程会复制一份new_socket给子进程 new_socket.close() # 关闭整个SOCKET tcp_server_socket.close() def main(): wsgi_server = WSGIServer() wsgi_server.run_forever() if __name__ == "__main__": main()
在构造函数内创建监听socket实例,然后使用run_forever开始运行。
三、静态资源和动态资源
静态资源:例如html页面、css文件、js文件、图片等都属于静态资源。
动态资源:每次请求返回的数据都不一样,例如从数据库中获取的数据,或者变化的时间等,都叫动态资源。
如下图所示:
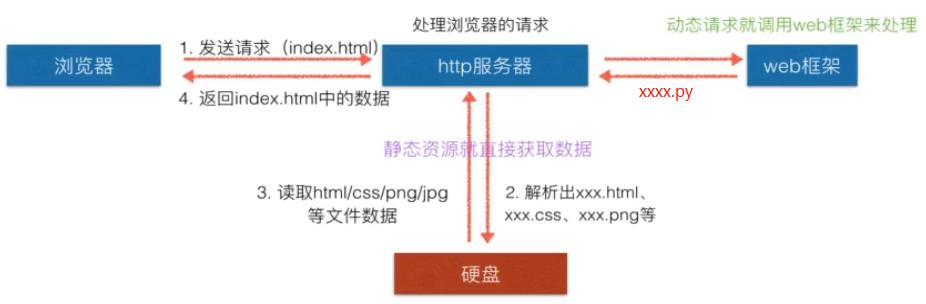
解释:
1.当服务器收到请求,判断请求内容为xxx.html、xxxx.css、xxxx.js、xxxx.png等,则直接从磁盘获取静态文件,读取并返回。
2.当服务器收到请求,判断请求内容为xxx.py(或其他自定义的特殊形式),则会调用web框架中的函数来获取数据。
3.HTTP服务器除了返回静态数据,以及从web框架获取reponse header和reponse body,将两者组装起来返回给客户端,他不做其他事情。
四、给HTTP服务器加上处理动态请求的逻辑
import socket import re import multiprocessing class WSGIServer(object): def __init__(self): # 创建socket实例 self.tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 设置资源重用 self.tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) # 绑定IP端口 self.tcp_server_socket.bind(("", 7890)) # 开始监听 self.tcp_server_socket.listen(128) # 请求处理函数 def handle_request(self, new_socket): # 接收请求 recv_msg = "" recv_msg = new_socket.recv(1024).decode("utf-8") if recv_msg == "": print("recv null") new_socket.close() return # 从请求中解析出URI recv_lines = recv_msg.splitlines() # 使用正则表达式提取出URI ret = re.match(r"[^/]+(/[^ ]*)", recv_lines[0]) if ret: # 获取URI字符串 file_name = ret.group(1) # 如果URI是/,则默认返回index.html的内容 if file_name == "/": file_name = "/index.html" if not file_name.endswith(".py"): try: # 根据请求的URI,读取相应的文件 fp = open("." + file_name, "rb") except: # 找不到文件,响应404 response_msg = "HTTP/1.1 404 NOT FOUND\\r\\n" response_msg += "\\r\\n" response_msg += "<h1>----file not found----</h1>" new_socket.send(response_msg.encode("utf-8")) else: html_content = fp.read() fp.close() # 响应正确 200 OK response_msg = "HTTP/1.1 200 OK\\r\\n" response_msg += "\\r\\n" # 返回响应头 new_socket.send(response_msg.encode("utf-8")) # 返回响应体 new_socket.send(html_content) else: header = "HTTP/1.1 200 OK\\r\\n" header += "\\r\\n" body = "dynamic request" + " %s" % time.ctime() response = header + body new_socket.send(response.encode("utf-8")) # 关闭该次socket连接 new_socket.close() # 开始无限循环,接受请求 def run_forever(self): while True: new_socket, client_addr = self.tcp_server_socket.accept() # 启动一个子进程来处理客户端的请求 sub_p = multiprocessing.Process(target=self.handle_request, args=(new_socket,)) sub_p.start() # 这里要关闭父进程中的new_socket,因为创建子进程会复制一份new_socket给子进程 new_socket.close() # 关闭整个SOCKET tcp_server_socket.close() def main(): wsgi_server = WSGIServer() wsgi_server.run_forever() if __name__ == "__main__": main()
添加判断分支,如果请求内容以.py结尾,则判断为动态数据,返回dynamic request + 时间。如下图:

五、服务器与动态请求解耦
另外实现一个py模块,叫mini_frame.py
import time def login(): return "----login page----\\r\\n %s" % time.ctime() def register(): return "----register page----\\r\\n %s" % time.ctime() def application(file_name): if file_name == "/login.py": return login() elif file_name == "register.py": return register() else: return "Not Found You Page..."
服务器一旦判断收到的请求为动态数据请求,则调用application(file_name),并将请求交给mini_frame来处理。
服务器端代码:
import socket import re import multiprocessing import time import mini_frame class WSGIServer(object): def __init__(self): # 创建socket实例 self.tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 设置资源重用 self.tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) # 绑定IP端口 self.tcp_server_socket.bind(("", 7890)) # 开始监听 self.tcp_server_socket.listen(128) # 请求处理函数 def handle_request(self, new_socket): # 接收请求 recv_msg = "" recv_msg = new_socket.recv(1024).decode("utf-8") if recv_msg == "": print("recv null") new_socket.close() return # 从请求中解析出URI recv_lines = recv_msg.splitlines() # 使用正则表达式提取出URI ret = re.match(r"[^/]+(/[^ ]*)", recv_lines[0]) if ret: # 获取URI字符串 file_name = ret.group(1) # 如果URI是/,则默认返回index.html的内容 if file_name == "/": file_name = "/index.html" if not file_name.endswith(".py"): try: # 根据请求的URI,读取相应的文件 fp = open("." + file_name, "rb") except: # 找不到文件,响应404 response_msg = "HTTP/1.1 404 NOT FOUND\\r\\n" response_msg += "\\r\\n" response_msg += "<h1>----file not found----</h1>" new_socket.send(response_msg.encode("utf-8")) else: html_content = fp.read() fp.close() # 响应正确 200 OK response_msg = "HTTP/1.1 200 OK\\r\\n" response_msg += "\\r\\n" # 返回响应头 new_socket.send(response_msg.encode("utf-8")) # 返回响应体 new_socket.send(html_content) else: header = "HTTP/1.1 200 OK\\r\\n" header += "\\r\\n" body = mini_frame.application(file_name) response = header + body new_socket.send(response.encode("utf-8")) # 关闭该次socket连接 new_socket.close() # 开始无限循环,接受请求 def run_forever(self): while True: new_socket, client_addr = self.tcp_server_socket.accept() # 启动一个子进程来处理客户端的请求 sub_p = multiprocessing.Process(target=self.handle_request, args=(new_socket,)) sub_p.start() # 这里要关闭父进程中的new_socket,因为创建子进程会复制一份new_socket给子进程 new_socket.close() # 关闭整个SOCKET tcp_server_socket.close() def main(): wsgi_server = WSGIServer() wsgi_server.run_forever() if __name__ == "__main__": main()
服务器只需调用mini_frame.application(file_name),获取body数据即可。
六、WSGI介绍
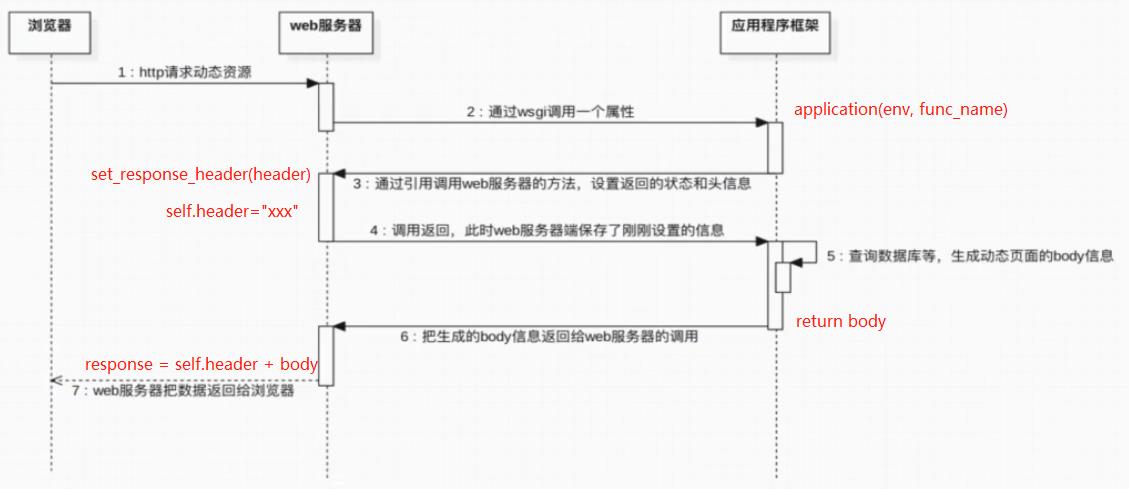
如图,WSGI主要有以下流程:
1.服务器默认调用WEB 框架提供的application函数,参数为env和func_name,env是一个字典,用于存放请求中的一些数据,例如"/login.py"等,func_name是函数引用,这个函数的服务器WSGIServer类的一个成员函数,用于提供给application调用,从而将response header先返回给服务器,并保存在self.header中。
2.Web框架再调用func_name指向的函数之后,再准备response body数据,并通过return返回给服务器。
3.服务器将self.header和body数据组合起来,返回给客户端,完成一次完整的请求流程。
七、WSGI标准接口
def application(environ, start_response): start_response(\'200 OK\',[(\'Content-Type\',\'text/html\')]) return \'Hello World...\'
上述代码是一个最简单符合WSGI标准的HTTP处理函数,接收两个参数,environ是包含所有HTTP请求信息的dict对象,start_response提供给web框架调用的函数。
将我们的nimi_frame框架代码修改一下:
def application(env, start_response): start_response(\'200 OK\', [(\'Content-Tpye\', \'text/html\')]) return "Hello World.."
将服务器代码修改一下:
import socket import re import multiprocessing import time import mini_frame class WSGIServer(object): def __init__(self): self.headers = list() self.status = "" # 创建socket实例 self.tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 设置资源重用 self.tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) # 绑定IP端口 self.tcp_server_socket.bind(("", 7890)) # 开始监听 self.tcp_server_socket.listen(128) # 请求处理函数 def handle_request(self, new_socket): # 接收请求 recv_msg = "" recv_msg = new_socket.recv(1024).decode("utf-8") if recv_msg == "": print("recv null") new_socket.close() return # 从请求中解析出URI recv_lines = recv_msg.splitlines() # 使用正则表达式提取出URI ret = re.match(r"[^/]+(/[^ ]*)", recv_lines[0]) if ret: # 获取URI字符串 file_name = ret.group(1) # 如果URI是/,则默认返回index.html的内容 if file_name == "/": file_name = "/index.html" if not file_name.endswith(".py"): try: # 根据请求的URI,读取相应的文件 fp = open("." + file_name, "rb") except: # 找不到文件,响应404 response_msg = "HTTP/1.1 404 NOT FOUND\\r\\n" response_msg += "\\r\\n" response_msg += "<h1>----file not found----</h1>" new_socket.send(response_msg.encode("utf-8")) else: html_content = fp.read() fp.close() # 响应正确 200 OK response_msg = "HTTP/1.1 200 OK\\r\\n" response_msg += "\\r\\n" # 返回响应头 new_socket.send(response_msg.encode("utf-8")) # 返回响应体 new_socket.send(html_content) else: env = dict() body = mini_frame.application(env, self.set_response_header) # 将框架返回的status组合进response header中 header = "HTTP/1.1 %s\\r\\n" % self.status # 将框架返回的响应头键值对加入到header中 for temp in self.headers: header += "%s:%s\\r\\n" % (temp[0], temp[1]) # 最后加上一个分割行 header += "\\r\\n" # 将响应体数据加在header后面 response = header + body # 返回给客户端 new_socket.send(response.encode("utf-8")) # 关闭该次socket连接 new_socket.close() # 该成员函数提供给web框架的applicaiton函数调用,并将status,headers设置到服务器中 def set_response_header(self, status, headers): self.status = status self.headers = headers # 开始无限循环,接受请求 def run_forever(self): while True: new_socket, client_addr = self.tcp_server_socket.accept() # 启动一个子进程来处理客户端的请求 sub_p = multiprocessing.Process(target=self.handle_request, args=(new_socket,)) sub_p.start() # 这里要关闭父进程中的new_socket,因为创建子进程会复制一份new_socket给子进程 new_socket.close() # 关闭整个SOCKET tcp_server_socket.close() def main(): wsgi_server = WSGIServer() wsgi_server.run_forever() if __name__ == "__main__": main()
解释:
1.代码的开头导入了mini_frame模块,这样导入显然是不太合理的,因为我们使用开源的服务器,不可能直接导入我们的框架代码。我们在后续版本中会解决这个问题。
2.动态请求的逻辑代码中,服务器调用mini_frame.application,这里传递了一个空的env字典(后续版本会将请求信息通过env传递给mini_frame)。
3.服务器定义了一个成员函数,set_response_header(),并将其引用传递给了application函
4.在mini_frame.application中,框架通过set_response_header()函数向服务器返回了response header(分为status和headers列表)。
5.服务器通过拼接self.status和self.headers,得到真正的response header。
6.application返回了一个固定的字符串(Hello World..这个字符串模拟response body),并将其串接在response header后,形成最终的响应数据。
八、通过environ字典传递请求头信息给web框架
mini_frame代码修改为:
import time def login(): return "----login page----\\r\\n %s" % time.ctime() def register(): return "