python爬虫 mozillacookiejar
Posted zhaoxinhui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫 mozillacookiejar相关的知识,希望对你有一定的参考价值。
MozillaCookiejar
保存百度得Cookiejar信息:
from urllib import request from urllib import parse from http.cookiejar import MozillaCookieJar # 保存在本地 cookiejar=MozillaCookieJar(\'cookie.txt\') handler=request.HTTPCookieProcessor(cookiejar) opener=request.build_opener(handler) # 打开百度,此时已将信息保存在了cookiejar中 resp=opener.open(\'http://www.baidu.com/\') # 下载在本地 cookiejar.save()

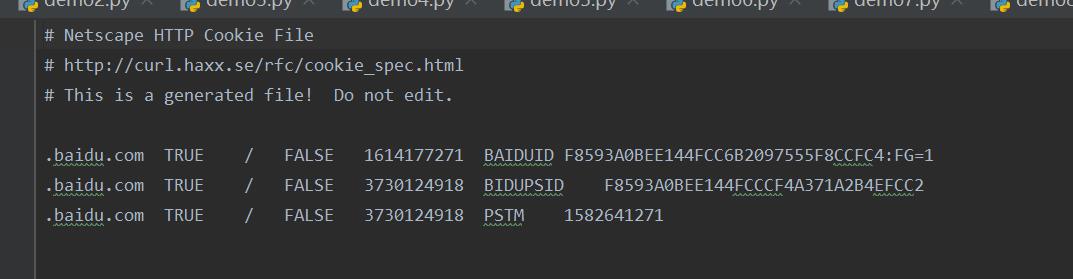
如果通过网址:hyypbin.org中得一个连接来自定义cookie信息,然后再代码中引用这个新的网址,那么下载在本地得cookie.txt为空,因为在cookie信息会在我们结束浏览时过期,如果想浏览刚刚使用得cookie信息,我们可以在代码得save函数中写
cookiejar.save(ignore_discard=True)
如果想把我们过期得cookie得信息打印出来,使用load函数
cookiejar.load(ignore_discard=True)
然后再加上
for cookie in cookiejar: print(cookie)
以上是关于python爬虫 mozillacookiejar的主要内容,如果未能解决你的问题,请参考以下文章