jieba库应用 python
Posted 吴林祥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了jieba库应用 python相关的知识,希望对你有一定的参考价值。

应用实例:
准备一个txt文件
import jieba
txt = open("三国演义.txt","r", encoding = \'gbk\',errors=\'ignore\').read() #读取已存好的txt文档
words = jieba.lcut(txt) #进行分词
counts = {}
for word in words:
if len(word)== 1: #去掉标点字符和其它单字符
continue
else:
counts[word] = counts.get(word, 0) + 1 #计数
items = list(counts.items()) #把对象对象转化为列表形式,利于下面操作
#sort() 函数用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数
#reverse 排序规则,reverse = True 降序, reverse = False 升序(默认)
#key 是用来比较的参数
items.sort(key=lambda x: x[1], reverse = True)
for i in range(1000):
word, count= items[i]
print("{0:<10}{1:>5}".format(word, count))
结果
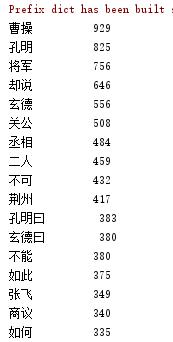
以上是关于jieba库应用 python的主要内容,如果未能解决你的问题,请参考以下文章