三:架构升级详解
Posted 字节跳动数据平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了三:架构升级详解相关的知识,希望对你有一定的参考价值。
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
当使用 Notebook 的项目日渐增加时,火山引擎 DataLeap 研发团队发现运行中的 PaaS 服务实在太多了,之前的架构有如下缺点:
-
部署麻烦。全量升级 JupyterLab 较为痛苦。尽管有升级脚本,但是通过 API 操作升级服务,可能由于镜像构建失败等原因,会造成卡单现象。
-
JupyterLab 需要不断的根据用户增长(项目增长)进行扩容,一旦预先启动好的资源池不够,就会存在新项目里有用户打开 Notebook,需要经历整个 JupyterLab 服务创建、环境拉起的流程,速度较慢,影响体验。
-
运维困难。当用户 JupyterLab 可能出现问题,为了找到对应的 JupyterLab,我们需要先根据项目对应到 JupyterHub user,然后根据 user 找到 JupyterHub 记录的服务 id,再去 PaaS 平台找服务,进 webshell。
-
当然,还有资源的浪费。虽然每个实例很小(1c1g),但是数量很多;有些项目并不总是在使用 Notebook,但 JupyterLab 依然运行。
-
稳定性存在问题。一方面,JupyterHub 是一个单点,升级需要先起后停,挂了有风险。另一方面,EG 入流量经过特定负载均衡策略,本身是为了使 JupyterLab 固定往一个 EG 请求。在 EG 升级时,JupyterLab 请求的终端会随之改变,极端情况下有可能造成 Kernel 启动多次的情况。
基于简化运维成本、降低架构复杂性,以及提高用户体验的考虑,2021 上半年,火山引擎 DataLeap 研发团队对整体架构进行了一次改良。在新的架构中,火山引擎 DataLeap 研发团队主要做了以下改进,大致简化为下图:
-
移除 JupyterHub,将 JupyterLab 改为多实例无状态常驻服务,并实现对接火山引擎 DataLeap 的多用户鉴权。
-
改造原本落在 JupyterLab 本地的数据存储,包括用户自定义配置、Session 维护和代码文件读写。
-
EG 支持持久化 Kernel,将 Kernel 远程环境元信息持久化在远端存储(MySQL)上,使其重启时可以重连,且 JupyterLab 可以知道某个 Kernel 需要通过哪个 EG 连接。
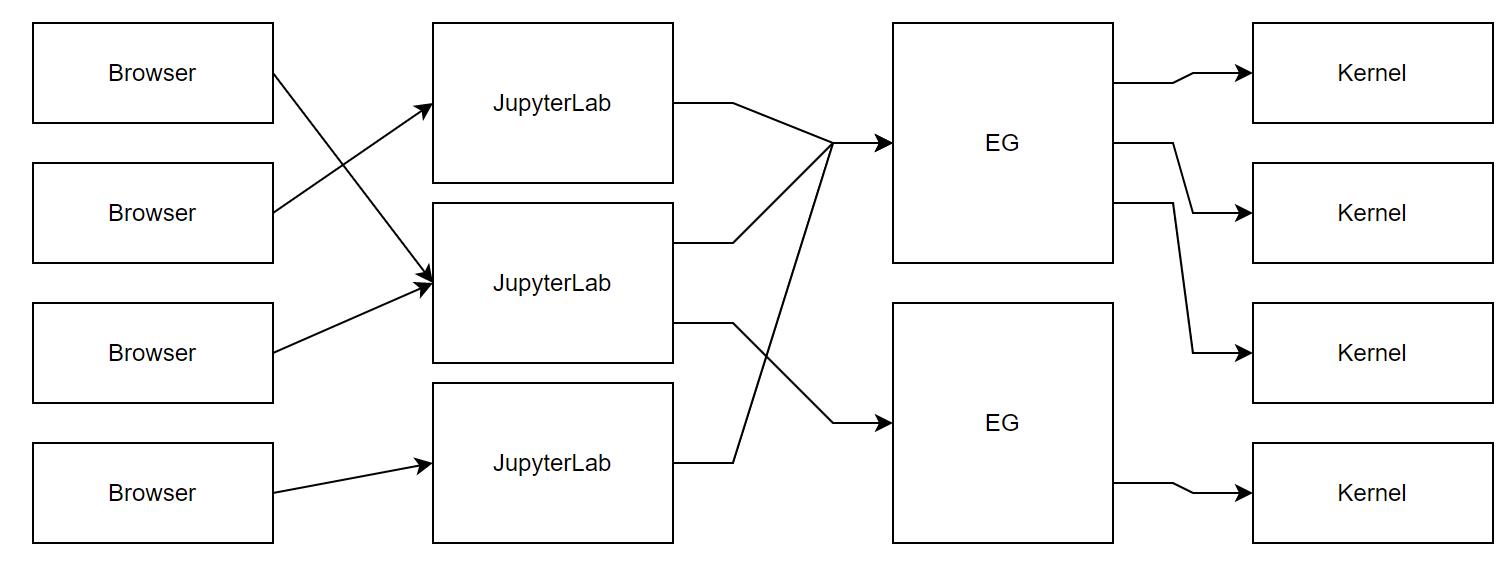
(图:火山引擎 DataLeap 下改进版 Notebook 整体架构)
单用户的 Jupyter Notebook / JupyterLab 的鉴权相对简单(实际上 JupyterLab 直接复用了 Jupyter Notebook 的这套代码)。例如,使用默认命令启动时,会自动生成一个 token,同时自动拉起浏览器。有了 token,就可以任意地访问这个 Notebook。
事实上,JupyterHub 也是起到了维护 Token 的作用。前端会发起一个获取 Token 的 API 请求,再拿着获取的 Token 请求通过 JupyterHub proxy 到真实的 Notebook 实例。
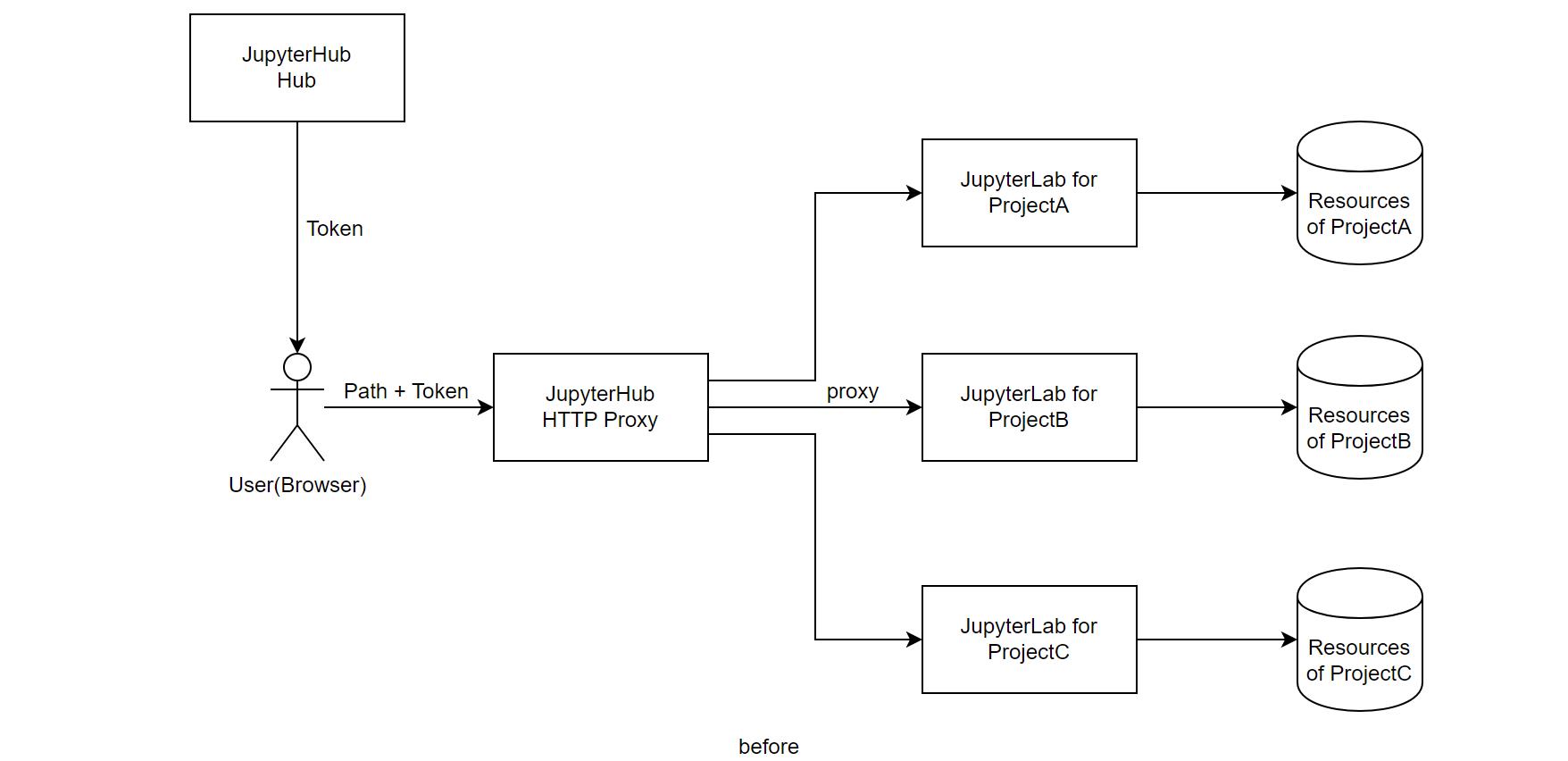
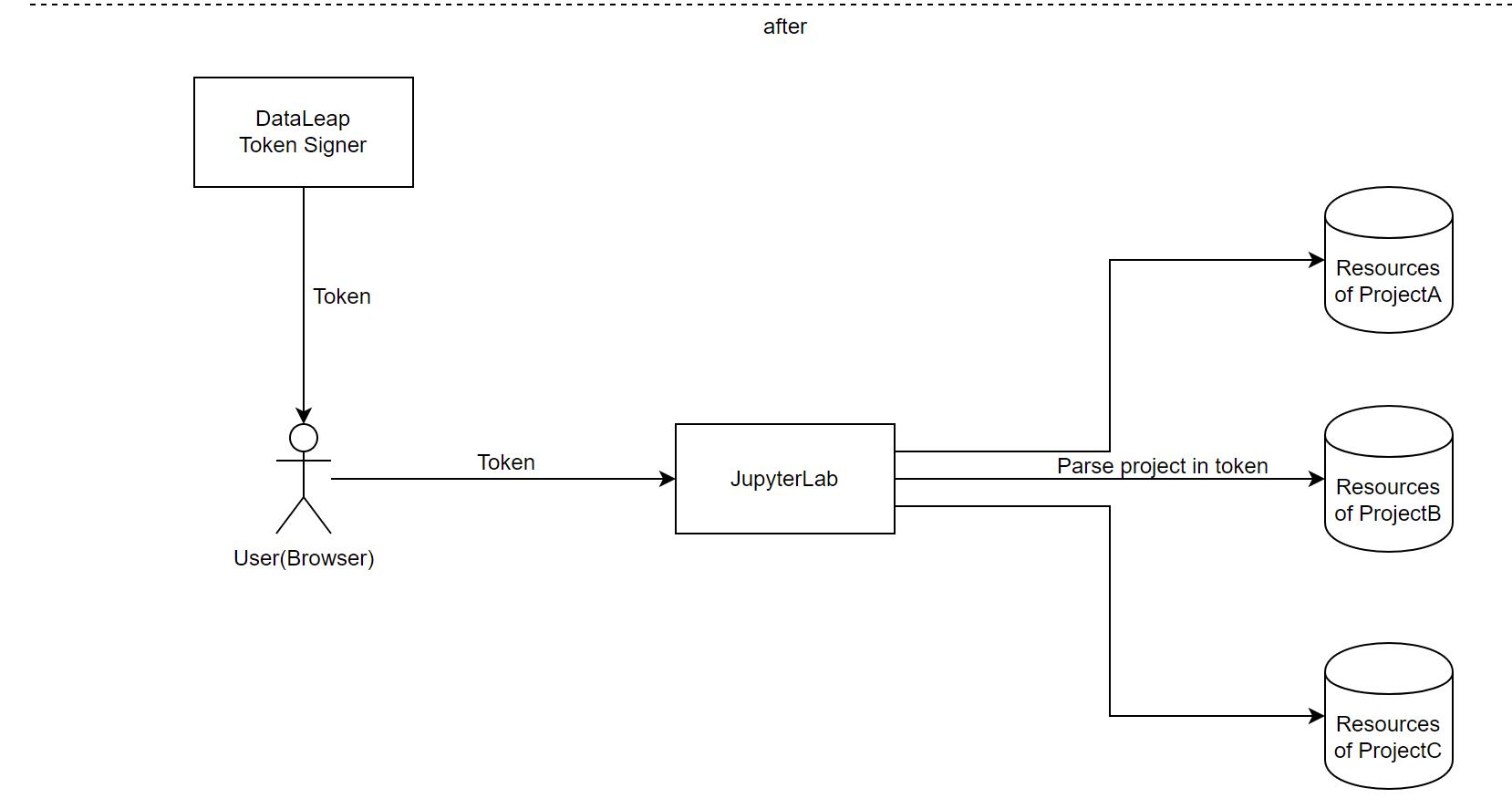
(图:前: JupyterHub 提供的 auth 能力;后:实现了 auth 功能的 JupyterLab)
最后,由于所有用户会共享同一组 JupyterLab,火山引擎 DataLeap 研发团队还需要禁止一些接口的调用,以保证系统的安全。最典型的接口包括关闭服务(Shutdown),以及修改配置等。后续 Notebook 所需的配置,转由前端保存在浏览器内。
Jupyter Notebook 使用 File Manager (https://github.com/jupyter-server/jupyter_server/blob/main/jupyter_server/services/contents/filemanager.py)管理 Contents 相关读写,原生行为是将代码存储在本地,多个服务实例之间无法共享同一份代码,而且迁移时可能造成代码丢失。
为了避免代码丢失,火山引擎 DataLeap 研发团队的做法是,把代码按项目分别存储在 OSS 上并直接读写,同时解决了一些由于代码文件元信息丢失,并发编辑导致的其他问题。
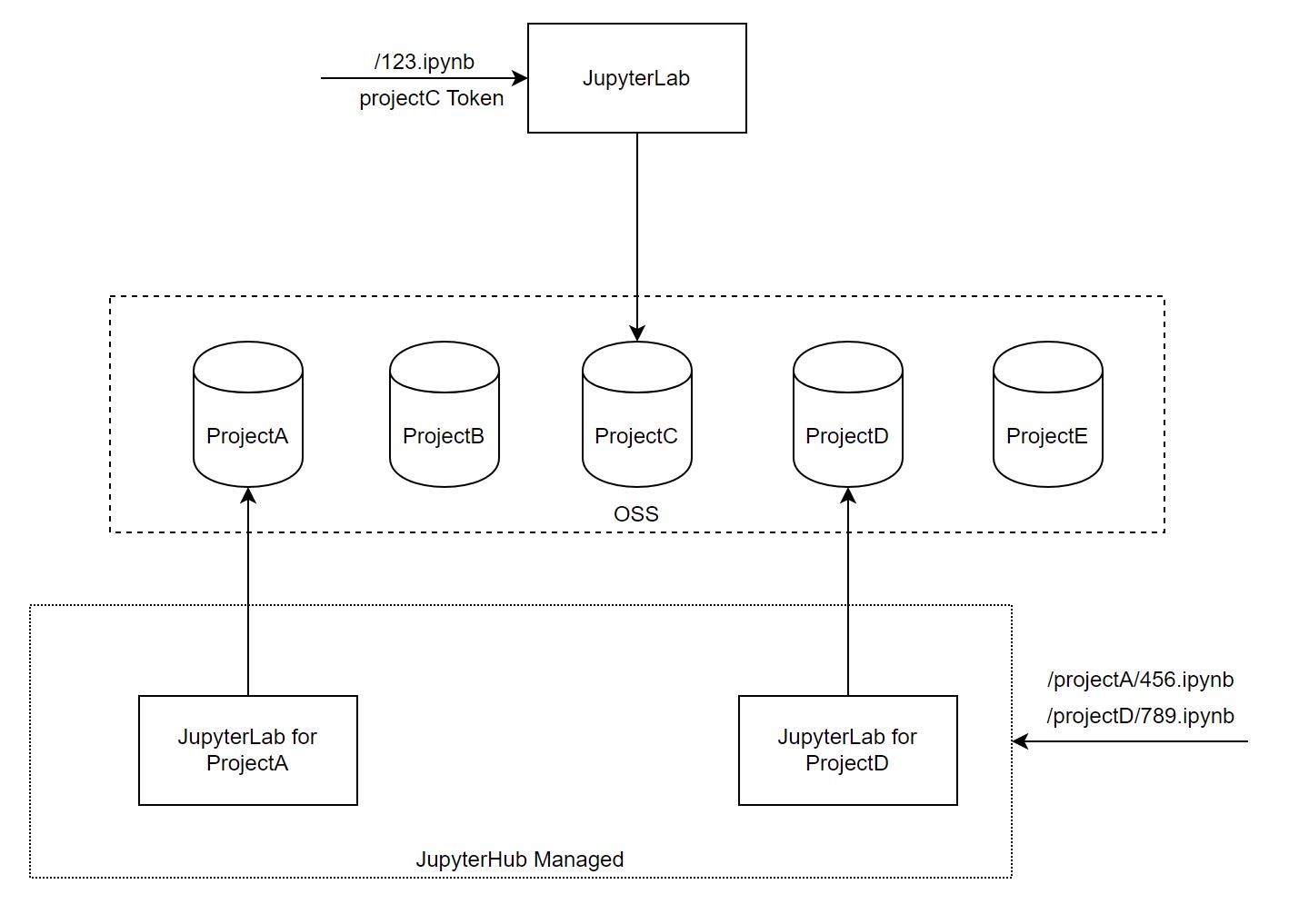
(图:按项目分别持久化代码到 OSS)
Notebook 使用 Session 管理用户到 Kernel 的连接,例如前端通过 POST /session 接口启动 Kernel,GET /session 查看当前运行中的 Kernel。在 Session 处理方面,原生的 Notebook 使用了原生的 sqlite(in memory),见代码(https://github.com/jupyter-server/jupyter_server/blob/main/jupyter_server/services/sessions/sessionmanager.py)。
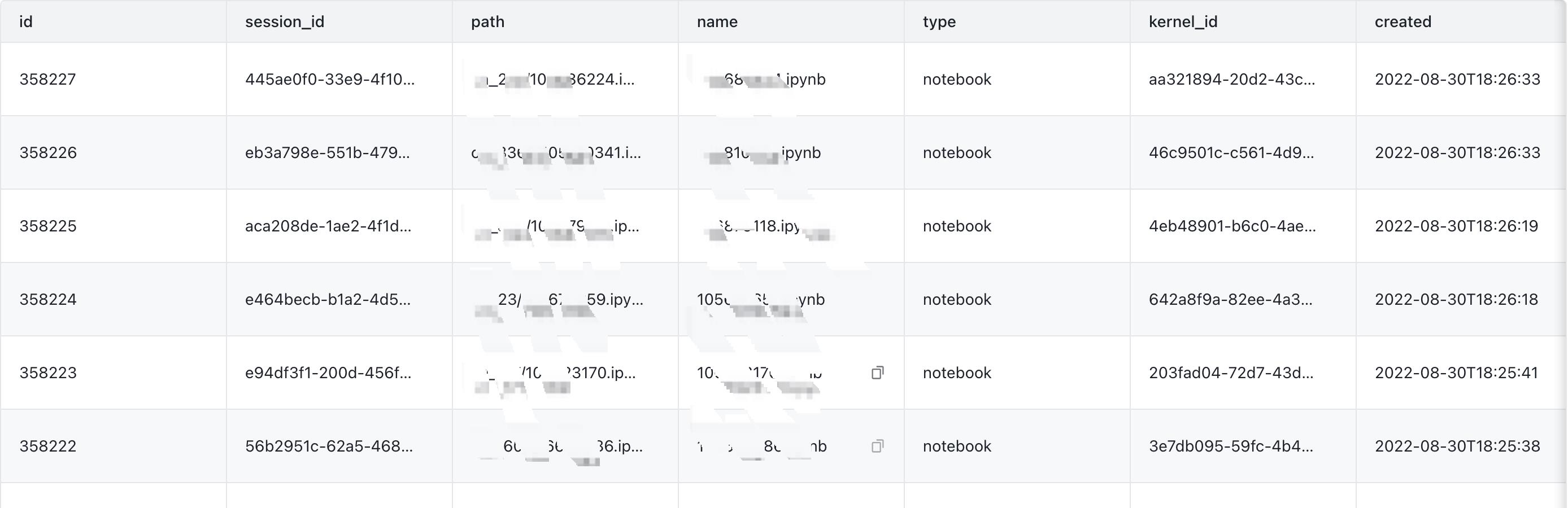
(图:Session 表)
Kernel Gateway 在启动 Kernel 时,记录了关于 Kernel 的一些元信息,包括启动参数、连接 Kernel 使用的 IP/Port 等。有了这些信息,当一个 Kernel Gateway 重启且 Remote Kernel 不关闭,就有办法重新连接上。 原本这些信息默认在内存 dict 中维护,开源仓库中有一套存储在本地文件的方案;基于这套方案,火山引擎 DataLeap 研发团队扩展了自研的存储到 MySQL 的方案。
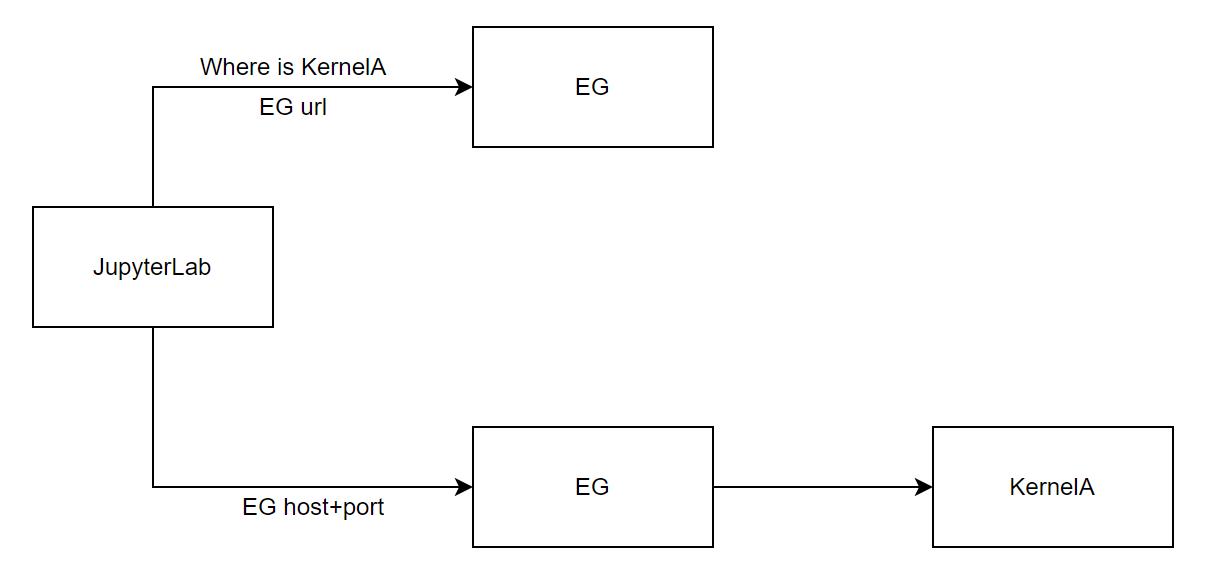
(图:EG 访问流程示意图)
当 EG 服务本身重启或者升级时,会在进程退出之前去清除接管信息。当页面继续访问时,JupyterLab 服务将会随机分发相应请求,由其它的 EG 服务继续接管。
架构升级简化后,整套火山引擎 DataLeap 下的 Notebook 服务的稳定性获得了极大的提升。由于实现了用户无感知的升级,不仅提升了用户的使用体验,运维的成本也同时降低了。
点击跳转 大数据研发治理DataLeap 了解更多
三层架构详解
目录
一、什么是三层架构?
- UI(表现层): 主要是指与用户交互的界面。用于接收用户输入的数据和显示处理后用户需要的数据。
- BLL:(业务逻辑层): UI层和DAL层之间的桥梁。实现业务逻辑。
- DAL:(数据访问层): 与数据库打交道。主要实现对数据的增、删、改、查。将存储在数据库中的数据提交给业务层,同时将业务层处理的数据保存到数据库。(当然这些操作都是基于UI层的。用户的需求反映给界面(UI),UI反映给BLL,BLL反映给DAL,DAL进行数据的操作,操作后再一一返回,直到将用户所需数据反馈给用户)
- Entity(实体层):它不属于三层中的任何一层,但是它是必不可少的一层。
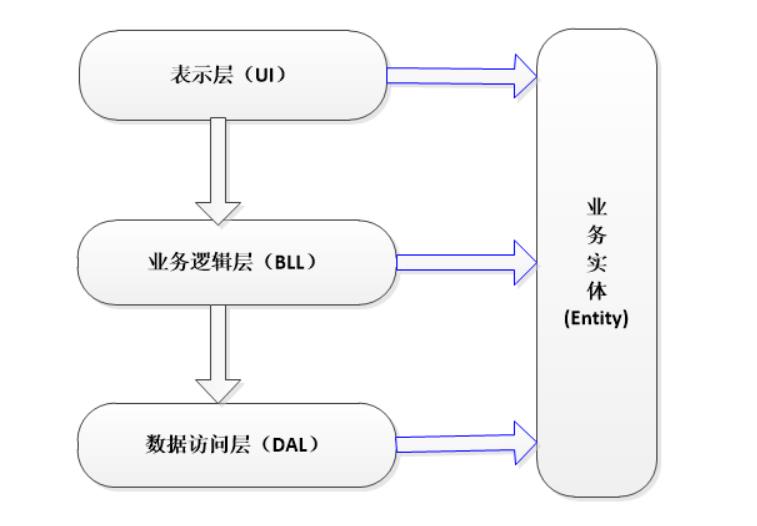
Entity在三层架构中的作用:
-
1、实现面向对象思想中的"封装";
-
2、贯穿于三层,在三层之间传递数据;(注:确切的说实体层贯穿于三层之间,来连接三层)
-
3、每一条数据就相当于一个对象,每个字段对应对象相应的属性(ORM思想)。
-
4、每一层(UI—>BLL—>DAL)之间的数据传递(单向)是靠变量或实体作为参数来传递的,这样就构造了三层之间的联系,完成了功能的实现。
二、为什么使用三层架构?
目的很简单,实现 ”高内聚,低耦合“。
内聚:一个模块内各个元素彼此结合的紧密程度,高内聚就是一个模块内各个元素彼此结合的紧密程度高。
耦合:一个完整的系统,模块与模块之间,尽可能的使其独立存在,也就是说,让每个模块,尽可能的独立完成某个特定的子功能,模块与模块之间的接口,尽量少而简单,如果某两个模块间的关系比较复杂的话,最好首先进行模块划分,有利于修改和组合。
三、与两层的区别
两层:
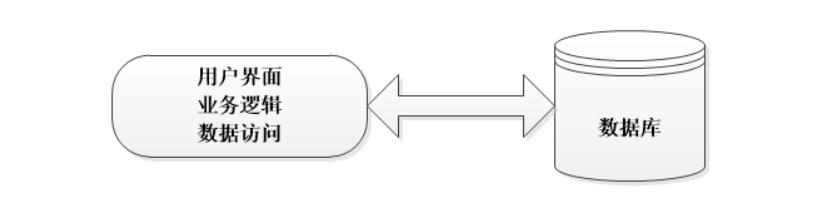
(当任何一个地方发生变化时,都需要重新开发整个系统。"多层"放在一层,分工不明确耦合度高——难以适应需求变化,可维护性低、可扩展性低)
三层:

(发生在哪一层的变化,只需更改该层,不需要更改整个系统。层次清晰,分工明确,每层之间耦合度低——提高了效率,适应需求变化,可维护性高,可扩展性高)
三层架构的优势:
-
1,结构清晰、耦合度低
-
2,可维护性高,可扩展性高
-
3,利于开发任务同步进行, 容易适应需求变化
三层架构的劣势:
-
1、降低了系统的性能。这是不言而喻的。如果不采用分层式结构,很多业务可以直接造访数据库,以此获取相应的数据,如今却必须通过中间层来完成。
-
2、有时会导致级联的修改。这种修改尤其体现在自上而下的方向。如果在表示层中需要增加一个功能,为保证其设计符合分层式结构,可能需要在相应的业务逻辑层和数据访问层中都增加相应的代码
-
3、增加了代码量,增加了工作量
以上是关于三:架构升级详解的主要内容,如果未能解决你的问题,请参考以下文章