Python面向对象 | 继承
Posted summer-skr--blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python面向对象 | 继承相关的知识,希望对你有一定的参考价值。
一、初识继承
面向对象的三大特性:继承,多态,封装。这3大特性是所有面向对象语言特点
父类:又叫超类、基类 子类:又叫派生类 class Parent:pass class Son(Person):pass
继承一般有2种:单继承和多继承
class ParentClass1: #定义父类 pass class ParentClass2: #定义父类 pass class SubClass1(ParentClass1): #单继承,基类是ParentClass1,派生类是SubClass pass class SubClass2(ParentClass1,ParentClass2): #多继承,用逗号分隔开多个继承的类
查看继承:
__base__只查看从左到右继承的第一个子类;
__bases__则是查看所有继承的父类;
print(SubClass1.__bases__) # (<class ‘__main__.ParentClass1‘>,) print(SubClass2.__bases__) # (<class ‘__main__.ParentClass1‘>, <class ‘__main__.ParentClass2‘>)
如果没有指定基类,python默认继承object类,object是所有python类的基类,它提供了一些常见方法(如__str__)的实现
class SubClass1(): pass class SubClass2(): pass print(SubClass1.__bases__) # (<class ‘object‘>,) print(SubClass2.__bases__) # (<class ‘object‘>,)
继承的作用
1、继承与重用:父类中的所有属性和方法都可以被子类使用
2、继承与派生:子类在父类的基础上创建新的属性和方法
- 父类有的子类没有:子类对象直接调用,就会执行父类的方法
- 父类有的子类也有:子类对象调用就会直接执行子类中的方法,要想调用父类中的方法,用父类名.方法(要加self,.....),或super().方法(....)
二、object类
实例化的过程:
1.创建一个空对象
2.调用init方法
3.将初始化之后的对象返回调用处
任何类实例化都经历3步。如果类没有init,由object完成了。
class A:pass A()
那么问题来了,A调用了init方法了吗?答案是调用了.why?它明明没有啊?
所有的类都继承了object类. 查看object的源码,可以找到__init__方法 *****
def __init__(self): # known special case of object.__init__ """ Initialize self. See help(type(self)) for accurate signature. """ pass
既然A继承了object类,那么它肯定执行了父类object的__init__方法
加一段注释
class A: ‘‘‘ 这是一个类 ‘‘‘ pass a = A() print(A.__dict__) # 双下方法 魔术方法 ‘‘‘ 执行输出: {‘__doc__‘: ‘ 这是一个类 ‘, ‘__module__‘: ‘__main__‘, ‘__dict__‘: <attribute ‘__dict__‘ of ‘A‘ objects>, ‘__weakref__‘: <attribute ‘__weakref__‘ of ‘A‘ objects>} ‘‘‘
可以看到__doc__方法获取注释信息
object,带双下划线的方法,有2个名字,比如 双下方法,魔术方法
三、继承与派生
单继承
1. 类名,对象执行父类方法
class Aniaml(object): type_name = ‘动物类‘ def __init__(self,name,sex,age): self.name = name self.age = age self.sex = sex def eat(self): print(self) print(‘吃东西‘) class Person(Aniaml): pass # 类: print(Person.type_name) # 可以调用父类的属性,方法。 Person.eat(111)# 对象: p1 = Person(‘春哥‘,‘男‘,18) print(p1.__dict__) print(p1.type_name) # 对象执行类的父类的属性,方法。 print(p1) p1.eat() ‘‘‘ 执行输出: 动物类 111 吃东西 {‘name‘: ‘春哥‘, ‘age‘: 18, ‘sex‘: ‘男‘} 动物类 <__main__.Person object at 0x0000018615656808> <__main__.Person object at 0x0000018615656808> 吃东西 ‘‘‘
2. 传参
单继承实例
class Animal: role = ‘Animal‘ def __init__(self,name,hp,ad): self.name = name # 对象属性 属性 self.hp = hp #血量 self.ad = ad #攻击力 class Person(Animal):pass class Dog(Animal):pass tony = Person() ‘‘‘ 执行报错:TypeError: __init__() missing 3 required positional arguments: ‘name‘, ‘hp‘, and ‘ad‘ 缺少2个参数,继承了父类的init方法 ‘‘‘
再次实例化
class Animal: role = ‘Animal‘ def __init__(self,name,hp,ad): self.name = name # 对象属性 属性 self.hp = hp #血量 self.ad = ad #攻击力 class Person(Animal):pass class Dog(Animal):pass tony = Person(‘Tony‘,10,5) dog = Dog(‘teddy‘,100,20) print(tony) print(dog) print(tony.__dict__) print(dog.__dict__) ‘‘‘ 结果输出: <__main__.Person object at 0x000002DEAFAA6948> <__main__.Dog object at 0x000002DEAFAA6988> {‘name‘: ‘Tony‘, ‘hp‘: 10, ‘ad‘: 5} {‘name‘: ‘teddy‘, ‘hp‘: 100, ‘ad‘: 20} ‘‘‘
3. 子类可以派生自己的属性和方法
class Animal: role = ‘Animal‘
def __init__(self,name,hp,ad): self.name = name # 对象属性 属性 self.hp = hp #血量 self.ad = ad #攻击力 def eat(self): print(‘%s吃药回血了‘%self.name) class Person(Animal): r = ‘Person‘
def attack(self,dog): # 派生方法 print("%s攻击了%s"%(self.name,dog.name)) def eat2(self): print(‘执行了Person类的eat方法‘) self.money = 100 self.money -= 10 self.hp += 10 class Dog(Animal): def bite(self,person): # 派生方法 print("%s咬了%s" % (self.name, person.name)) tony = Person(‘Tony‘,10,5) teddy = Dog(‘Teddy‘,100,20) tony.attack(teddy) #继承中的派生方法 tony.eat() #继承父类方法自己没有同名方法 tony.eat2() teddy.eat()
‘‘‘ 结果输出: Tony攻击了Teddy Tony吃药回血了 执行了Person类的eat方法 Teddy吃药回血了 ‘‘‘
对象使用名字顺序:先找对象自己内存空间中的,再找对象自己类中的,再找父类中的。
例
猫
属性 性别 品种
方法 吃 喝 爬树
狗
属性 性别 品种
方法 吃 喝 看门
从上面可以看出,狗和猫有共同的属性和方法,唯独有一个方法是不一样的。那么是否可以继承呢?
class Animal: # 动物 def __init__(self,name,sex,kind): self.name = name self.sex = sex self.kind = kind def eat(self): # 吃 print(‘%s is eating‘%self.name) def drink(self): # 喝 print(‘%s is drinking‘%self.name) class Cat(Animal): # 猫 def climb(self): # 爬树 print(‘%s is climbing‘%self.name) class Dog(Animal): # 狗 def watch_door(self): # 看门 print(‘%s is watching door‘%self.name) tom = Cat(‘tom‘,‘公‘,‘招财猫‘) # 实例化对象 hake = Dog(‘hake‘,‘公‘,‘藏獒‘)
print(Cat.__dict__) # Cat.__dict__ Cat类的命名空间中的所有名字 print(tom.__dict__) # tom.__dict__ 对象的命名空间中的所有名字
tom.eat() # 先找自己对象的内存空间 再找类的空间 再找父类的空间 tom.climb() # 先找自己的内存空间 再找类的空间 ‘‘‘ 执行输出: {‘__doc__‘: None, ‘climb‘: <function Cat.climb at 0x000001C95178AAE8>, ‘__module__‘: ‘__main__‘} {‘sex‘: ‘公‘, ‘name‘: ‘tom‘, ‘kind‘: ‘招财猫‘} tom is eating tom is climbing ‘‘‘
实例化猫,需要4个步骤
- 1.确认自己没有init方法
- 2.看看有没有父类
- 3.发现父类Animal有init
- 4.按照父类的init方法来传参数
__dict__只有对象的命名中的所有名字
比如人工大战,人类和狗有共同属性,比如名字,血量,攻击力。还有共同的方法吃药
class Animal: def __init__(self,name,hp,ad): self.name = name # 名字 self.hp = hp # 血量 self.ad = ad # 攻击力 def eat(self): print(‘%s吃药回血了‘ % self.name) class Person(Animal): def attack(self,dog): # 派生类 print(‘%s攻击了%s‘ %(self.name,dog.name)) class Dog(Animal): def bite(self,person): # 派生类 print(‘%s咬了%s‘ %(self.name,person.name)) tony = Person(‘Tony‘,100,10) print(tony.__dict__)
‘‘‘ 执行输出:{‘name‘: ‘Tony‘, ‘hp‘: 100, ‘ad‘: 10} ‘‘‘
但是还有不同的,比如人类有性别,狗类有品种. 可以在子类init里面加属性。Person增加init方法。
# Person增加init方法 class Animal: def __init__(self,name,hp,ad): self.name = name # 名字 self.hp = hp # 血量 self.ad = ad # 攻击力 def eat(self): print(‘%s吃药回血了‘ % self.name) class Person(Animal): def __init__(self,sex): self.sex = sex def attack(self,dog): # 派生类 print(‘%s攻击了%s‘ %(self.name,dog.name)) class Dog(Animal): def __init__(self,kind): self.kind = kind def bite(self,person): # 派生类 print(‘%s咬了%s‘ %(self.name,person.name)) tony = Person(‘male‘) print(tony.__dict__) ‘‘‘ 执行输出:{‘sex‘: ‘male‘} ‘‘‘
发现和上面的例子少了一些属性,animal继承的属性都没有了。what?因为子类自己有init方法了,它不会执行父类的init方法.
4. 同时执行本类以及父类方法
执行父类的init,同时保证自己的init方法也能执行
class Animal: def __init__(self, name, hp, ad): self.name = name # 名字 self.hp = hp # 血量 self.ad = ad # 攻击力 def eat(self): # 吃药 print(‘%s吃药回血了‘ % self.name) self.hp += 20 class Person(Animal): def __init__(self, name, hp, ad, sex): Animal.__init__(self, name, hp, ad) # 执行父类方法 super(Person, self).__init__(name, hp, ad) # 完整写法.在单继承中,super负责找到当前类所在的父类,不需要再手动传self super().__init__(name, hp, ad) # 简写.效果同上。它不需要传参数Person,self。因为它本来就在类里面,自动获取参数 self.sex = sex def attack(self, dog): # 派生类 print(‘%s攻击了%s‘ % (self.name, dog.name)) class Dog(Animal): def __init__(self, name, hp, ad, kind): super().__init__(name, hp, ad) self.kind = kind def bite(self, person): # 派生类 print(‘%s咬了%s‘ % (self.name, person.name)) tony = Person(‘Tony‘, 100, 10, ‘male‘) # 实例化 print(tony.__dict__) ‘‘‘ 执行输出:{‘name‘: ‘Tony‘, ‘hp‘: 100, ‘ad‘: 10, ‘sex‘: ‘male‘} ‘‘‘
父类方法,如果子类有个性化需求,可以重新定自己方法。比如人吃药要扣钱,狗吃药,不要钱。在Animal类中,eat方法,执行时,没有扣钱。那么就需要在人类中添加eat 方法,定义扣钱动作。定义同名函数
class Animal: def __init__(self,name,hp,ad): self.name = name # 名字 self.hp = hp # 血量 self.ad = ad # 攻击力 def eat(self): print(‘%s吃药回血了‘ % self.name) class Person(Animal): def __init__(self,name,hp,ad,sex): super().__init__(name, hp, ad) self.sex = sex # 性别 self.money = 0 # 增加默认属性money def attack(self,dog): # 派生类 print(‘%s攻击了%s‘ %(self.name,dog.name)) def eat(self): # 重新定义eat方法 super().eat() # 执行父类方法eat,放前面就先执行,放后面就后执行 print(‘eating in Person‘) self.money -= 50 # 扣钱 class Dog(Animal): def __init__(self,name,hp,ad,kind): super().__init__(name, hp, ad) self.kind = kind def bite(self,person): # 派生类 print(‘%s咬了%s‘ %(self.name,person.name)) tony = Person(‘Tony‘,100,10,‘male‘) # 实例化 tony.eat() # 子类有eat 不管父类中有没有,都执行子类的 ‘‘‘ 执行输出: Tony吃药回血了 eating in Person ‘‘‘
在类外面, 当子类中有,但是想要调父类的。一般不会在类外面,执行super方法。都是在类里面调用父类方法,super是帮助寻找父类的,在外部,super没有简写。
class Animal: def __init__(self,name,hp,ad): self.name = name # 名字 self.hp = hp # 血量 self.ad = ad # 攻击力 def eat(self): print(‘%s吃药回血了‘ % self.name) class Person(Animal): def __init__(self,name,hp,ad,sex): super().__init__(name, hp, ad) self.sex = sex # 性别 self.money = 0 # 增加默认属性money def attack(self,dog): # 派生类 print(‘%s攻击了%s‘ %(self.name,dog.name)) def eat(self): # 重新定义eat方法 super().eat() # 执行父类方法eat,放前面就先执行,放后面就后执行 print(‘eating in Person‘) self.money -= 50 # 扣钱 class Dog(Animal): def __init__(self,name,hp,ad,kind): super().__init__(name, hp, ad) self.kind = kind def bite(self,person): # 派生类 print(‘%s咬了%s‘ %(self.name,person.name)) tony = Person(‘Tony‘,100,10,‘male‘) # 实例化 tony.eat() # 子类有eat 不管父类中有没有,都执行子类的 Animal.eat(tony) # 指名道姓 super(Person, tony).eat() # 效果同上,super(子类名,子类对象)方法,一般不用 ‘‘‘ 执行输出: Tony吃药回血了 eating in Person Tony吃药回血了 Tony吃药回血了 ‘‘‘
经典题
class Parent(): def func(self): print(‘in parent func‘) def __init__(self): self.func() class Son(Parent): def func(self): print(‘in son func‘) s = Son() # in son func
分析:查找顺序,自己->自己的类->父类
- 1. s = Son() 创建实例命名空间s ;
- 2. Son继承了Parent,类对象指针指向Son和Parent,Son没有__init__方法,它继承了Parent的__init__方法。
- 3. 执行__init__方法,此时self是指向Son的,执行self.func()。
总结:self.名字的时候,不要看self当前在哪个类里,要看这个self到底是谁的对象
单继承练习题:
 View Code
View Code
派生方法和派生属性
super 只有在子父类拥有同名方法的时候,想使用子类的对象调用父类的方法时,才使用super
super在类内 : super().方法名(arg1,..)。父类名.方法名(self,arg1,..),指名道姓
四、钻石继承
父类是新式类,那么子类全是新式类
经典类 :在python2.*版本才存在,且必须不继承object
- 遍历的时候遵循深度优先算法
- 没有mro方法
- 没有super()方法
新式类 :在python2.X的版本中,需要继承object才是新式类
- 遍历的时候遵循广度优先算法
- 在新式类中,有mro方法
- 有super方法,但是在2.X版本的解释器中,必须传参数(子类名,子类对象)
1. 深度优先
深度优先是“一路摸到黑”,也就是说深度优先搜索会不假思索地一直扩展一个状态直到到达不能被扩展的叶子状态。
要用Python2测试,代码如下:
class A: def func(self): print(‘A‘) class B(A): def func(self): print(‘B‘) class C(A): def func(self): print(‘C‘) class D(B,C): def func(self): print(‘D‘) d = D() d.func() # D
在python2里面,不手动继承object,比如class A(object)就是经典类. 在这个例子中B继承了A,B再去找A,执行输出A . 所有的路线,不走重复的
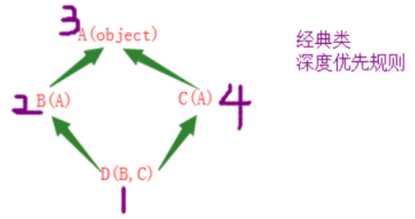
深度优先,一条路走到黑,找不到,就会回来找其他的.
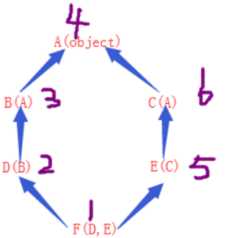
2. 广度优先
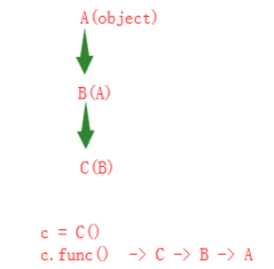
单继承新式类
多继承新式类
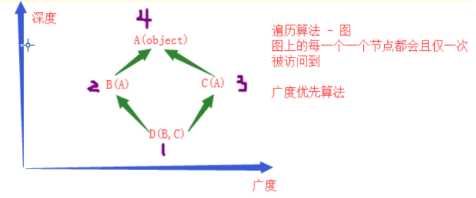
这个形状,像一个钻石. 老外喜欢浪漫,有些书籍写的叫钻石继承
再看一个龟壳模型
class A: def func(self): print(‘A‘) class B(A): pass def func(self): print(‘B‘) class C(A): pass def func(self): print(‘C‘) class D(B): pass def func(self): print(‘D‘) class E(C): pass def func(self): print(‘E‘) class F(D,E): pass def func(self): print(‘F‘) f = F() f.func() # F
看图,查看顺序
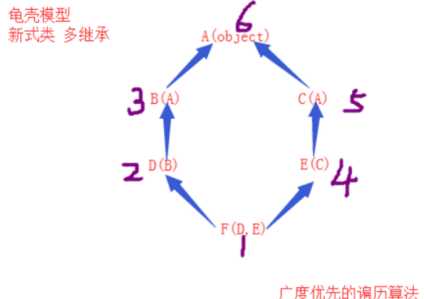
在这个例子中,A为顶点,因为有2个类继承了A,在执行第3步时,由于B继承了A,B并没有直接去找A。而是在这这一层中断查找。由同层的E去查找,然后到C,最后到A。这就是广度优先算法
广度优先搜索算法(英语:Breadth-First-Search,缩写为BFS),又译作宽度优先搜索,或横向优先搜索,是一种图形搜索算法。简单的说,BFS是从根节点开始,沿着树的宽度遍历树的节点。如果所有节点均被访问,则算法中止。
宽度优先搜索,请参考链接
https://baike.baidu.com/item/%E5%AE%BD%E5%BA%A6%E4%BC%98%E5%85%88%E6%90%9C%E7%B4%A2/5224802?fr=aladdin&fromid=542084&fromtitle=BFS
广度优先算法有点复杂,Python直接提供了方法mro,可以查看搜索循环
f = F() f.func() print(F.mro()) ‘‘‘ 执行输出: F [<class ‘__main__.F‘>, <class ‘__main__.D‘>, <class ‘__main__.B‘>, <class ‘__main__.E‘>, <class ‘__main__.C‘>, <class ‘__main__.A‘>, <class ‘object‘>] ‘‘‘
新式类 多继承 寻找名字的顺序 遵循广度优先
经典面试题
class A: def func(self): print(‘A‘) class B(A): def func(self): super().func() print(‘B‘) class C(A): def func(self): super().func() print(‘C‘) class D(B,C): def func(self): super().func() print(‘D‘) d = D() d.func() ‘‘‘ 执行输出: A C B D ‘‘‘
3. super()
- 在单继承中,就是单纯的寻找父类
- 在多继承中,就是根据子节点所在图的mro循环找寻下一个类
在上的例子中,super不是找父类的,它是找下一个节点的
遇到多继承和super
对象.方法
找到这个对象对应的类,将这个类的所有父类都找到画成一个图,根据图写出广度优先的顺序
再看代码,看代码的时候,要根据广度优先顺序图来找对应的super
super()深入了解
super是严格按照类的继承顺序执行!!!
(1) super可以找下一个类的其他方法
class A: def f1(self): print(‘in A f1‘) def f2(self): print(‘in A f2‘) class Foo(A): def f1(self): super().f2() print(‘in A Foo‘) obj = Foo() obj.f1() ‘‘‘ 执行输出: in A f2 in A Foo ‘‘‘
(2) super()严格按照类的mro顺序执行
class A: def f1(self): print(‘in A‘) class Foo(A): def f1(self): super().f1() print(‘in Foo‘) class Bar(A): def f1(self): print(‘in Bar‘) class Info(Foo,Bar): def f1(self): super().f1() print(‘in Info f1‘) obj = Info() obj.f1() print(Info.mro()) ‘‘‘ 执行输出: in Bar in Foo in Info f1 [<class ‘__main__.Info‘>, <class ‘__main__.Foo‘>, <class ‘__main__.Bar‘>, <class ‘__main__.A‘>, <class ‘object‘>] ‘‘‘
(3) 再来
class A: def f1(self): print(‘in A‘) class Foo(A): def f1(self): super().f1() print(‘in Foo‘) class Bar(A): def f1(self): print(‘in Bar‘) class Info(Foo,Bar): def f1(self): super(Foo,self).f1() # 这样就不继承Foo,而继承Bar print(‘in Info f1‘) obj = Info() obj.f1() ‘‘‘ 执行输出:注意查看结果 in Bar in Info f1 ‘‘‘
4. mro序列
MRO是一个有序列表L,在类被创建时就计算出来。
通用计算公式为:
mro(Child(Base1,Base2)) = [ Child ] + merge( mro(Base1), mro(Base2), [ Base1, Base2] )
(其中Child继承自Base1, Base2)
如果继承至一个基类:class B(A) , 这时B的mro序列为
mro( B ) = mro( B(A) ) = [B] + merge( mro(A) + [A] ) = [B] + merge( [A] + [A] ) = [B,A]
如果继承至多个基类:class B(A1, A2, A3 …) , 这时B的mro序列
mro(B) = mro( B(A1, A2, A3 …) ) = [B] + merge( mro(A1), mro(A2), mro(A3) ..., [A1, A2, A3] ) = ...
计算结果为列表,列表中至少有一个元素(类自己),如上述示例[A1,A2,A3]。merge操作是C3算法的核心。
表头和表尾
表头:
列表的第一个元素
表尾:
列表中表头以外的元素集合(可以为空)
示例
列表:[A, B, C]
表头是A,表尾是B和C
列表之间的+操作
[A] + [B] = [A, B]
(以下的计算中默认省略)
merge操作示例:
如计算merge( [E,O], [C,E,F,O], [C] ) 有三个列表 : ① ② ③ 1 merge不为空,取出第一个列表列表①的表头E,进行判断 各个列表的表尾分别是[O], [E,F,O],E在这些表尾的集合中,因而跳过当前当前列表 2 取出列表②的表头C,进行判断 C不在各个列表的集合中,因而将C拿出到merge外,并从所有表头删除 merge( [E,O], [C,E,F,O], [C]) = [C] + merge( [E,O], [E,F,O] ) 3 进行下一次新的merge操作 ......
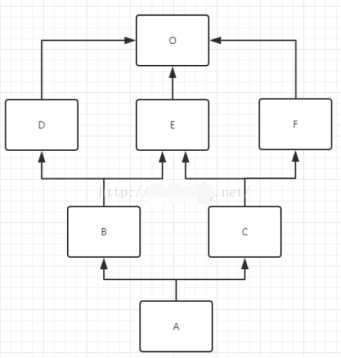
mro(A) = mro( A(B,C) ) 原式= [A] + merge( mro(B),mro(C),[B,C] ) mro(B) = mro( B(D,E) ) = [B] + merge( mro(D), mro(E), [D,E] ) # 多继承 = [B] + merge( [D,O] , [E,O] , [D,E] ) # 单继承mro(D(O))=[D,O] = [B,D] + merge( [O] , [E,O] , [E] ) # 拿出并删除D = [B,D,E] + merge([O] , [O]) = [B,D,E,O] mro(C) = mro( C(E,F) ) = [C] + merge( mro(E), mro(F), [E,F] ) = [C] + merge( [E,O] , [F,O] , [E,F] ) = [C,E] + merge( [O] , [F,O] , [F] ) # 跳过O,拿出并删除 = [C,E,F] + merge([O] , [O]) = [C,E,F,O] 原式= [A] + merge( [B,D,E,O], [C,E,F,O], [B,C]) = [A,B] + merge( [D,E,O], [C,E,F,O], [C]) = [A,B,D] + merge( [E,O], [C,E,F,O], [C]) # 跳过E = [A,B,D,C] + merge([E,O], [E,F,O]) = [A,B,D,C,E] + merge([O], [F,O]) # 跳过O = [A,B,D,C,E,F] + merge([O], [O]) = [A,B,D,C,E,F,O]
这个说完了. 那C3到底怎么看更容易呢? 其实很简单. C3是把我们多个类产?的共同继承留到最后去找. 所以. 我们也可以从图上来看到相关的规律. 这个要?家??多写多画图就能感觉到了. 但是如果没有所谓的共同继承关系. 那?乎就当成是深度遍历就可以了
以上是关于Python面向对象 | 继承的主要内容,如果未能解决你的问题,请参考以下文章