Hadoop集群搭建总结
Posted ali_gaduo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop集群搭建总结相关的知识,希望对你有一定的参考价值。
对这两天搭建Hadoop集群做个经验总结
master节点:Ubuntu 22.04,也就是我的台式机主机
slave节点:Debian 11,通过VMware虚拟出来
(1)集群节点设置和角色分配
master namenode,datanode,resourcemanager,nodemanager
slave0 secondarynamenode,datanode,nodemanager
slave1 datanode,nodemanager
slave2 datanode,nodemanager
Hadoop体系的构成有三部分,分别是HDFS、YARN、MapReduce。分清楚它们的逻辑关系很重要。
其中HDFS充当的是文件系统的角色,笼统来讲就像你电脑里的文件管理器,由于它的存在,你只需扔给它文件就行了,至于存到哪块硬盘(对应HDFS就是datanode节点),你不需要操心。
YARN的角色就是资源协调方,在Hadoop2.0的时候引入的一个机制。hadoop1.0的时候YARN这部分的工作基本上是由namenode来完成的。YARN要做的工作,大概就是弄清楚集群中的存储资源分布情况,当你要向集群存储文件时,能够较好地把文件存到合适的位置。
MapReduce则相当于你电脑的应用程序,具体如何处理数据,就由MapReduce来弄。
其中,namenode、datanode、secondarynamenode是属于HDFS系统的,也就是这些节点共同构成分布式文件系统。resourcemanager和nodemanager是属于YARN的。在启动分布式系统时,可以分别启动HDFS系统(运行start-dfs.sh)和YARN系统(运行start-yarn.sh)
(2)配置过程
具体配置过程,网上已经有很多博客了,我不再赘述。
先说说走过的弯路
1. 关于Linux的User设置
master和slave节点运行Hadoop的用户,最好要取相同的名字,虽然不取相同的名字理论上也行得通,但是很麻烦。
这里主要是因为配置$HADOOP_HOME/etc/hadoop里的workers文件的问题,这里只定位到节点的ip地址,而不定位到具体节点运行Hadoop程序的用户。当master和slave节点运行Hadoop程序的用户名不一样时,在master节点上(比如master节点上用户名是mmm)通过ssh远程登陆slave节点(比如slave节点用户名是sss)时,它会默认登陆slave节点的mmm用户。我一直想在etc/hadoop下的masters文件里定位到具体节点的用户上,然而一直会有节点启动失败问题。
总结:为了免去不必要的麻烦,最好让各个节点上运行Hadoop程序的用户名一致
2.格式化和cluster-ID不一致问题
其实格式化就是重置文件系统,格式化之后之前存储的东西都没了。格式化的时候经常会碰到datanode和namenode的cluster-ID不一致问题
hdfs namenode -format
运行这个命令时,其实主要就是把namenode上面里存储HDFS的元数据删除了。那元数据存储在哪里呢?$HADOOP_HOME/etc/hadoop下的hdfs-site.xml文件里,通过配置dfs.namenode.name.dir,可以指定元数据的存储位置,其中cluster-ID数据就存在这里面。。在hdfs-site.xml里通过配置dfs.datanode.data.dir,还可以指定datanode存储具体数据的位置
那cluster-ID不一致是怎么回事呢?其实就是dfs.namenode.name.dir和dfs.datanode.data.dir下面的cluster-ID不一致,导致datanode启动不了。格式化之后,namenode的相关数据会删掉,在start-dfs.sh的时候重新生成,但是,datanode下面的相关数据不会删除!在启动文件系统的时候,由于检测到dfs.datanode.data.dir里面不是空的,它就不会给它同步生成cluster-ID,从而导致datanode的cluster-ID和namenode的cluster-ID不一致。
所以,格式化之后,一定要把datanode下dfs.datanode.data.dir里的文件删掉,再启动HSDFS
3.关于排错
其实主要就是查看日志文件。每次启动都会生成日志文件(就是.log文件,不是.out文件)。查看相关的日志文件就好了。
4.关于网段设置
说一个我遇上的诡异事件。我的台式机主机IP是公网IP,VMware上虚拟机设置的是NAT模式,IP地址是私域IP。一路配置下来,都没问题,免密登录、启动HDFS、启动YARN,看起来都好好的。但是!我发现HDFS的存储空间为0,而且也没法hdfs dfs -put文件。运行hdfs dfsadmin -report显示只有一个存活的节点(事实上四个datanode都启动了),我多次运行hdfs dfsadmin -report,发现存活的datanode还不一样。。????
后来我只好让namenode和datanode全都处于私域,或者全都处于公网,才正常了。
所以,一定要让节点要么都在公网,要么都在私域其实,从后面对hadoop的设计初衷也知道,这个问题是很显然的。
集群配置还有好多问题,要弄懂整个集群,还有很多要学。加油!!!
这里推荐一篇很值得读的文章:Hadoop和网络 有时间我对这篇博客做个总结。
hadoop原生集群搭建
hello大家好,今天为大家分享一篇hadoop原生集群搭建的文章,今天也是花了小个把小时又重新搭建了一遍环境,总结成文,分享于此,也希望大家以后自学的时候能够少爬点坑。
首先呢给大家先说说我的整体环境,由于个人经济有限只能在VM虚拟机里面创建三台虚拟机(安装虚拟机此处不做详解),因为我是直接PXE引导安装的,所以我一次性创建了三台,若大家会PXE也可以效仿,不过大家也可以先安装一台主机,做完基础配置后,可以通过复制或克隆得到其他俩台主机;只不过克隆后是不能上网的,你还需要修改网卡设置,注释网卡硬件信息等。
本人环境如下:
虚拟主机如下:
注意:
首先在vmware主界面,单击"编辑"——"虚拟网络编辑"
进入后选中nat网络,单击nat设置:
本人配置如下:
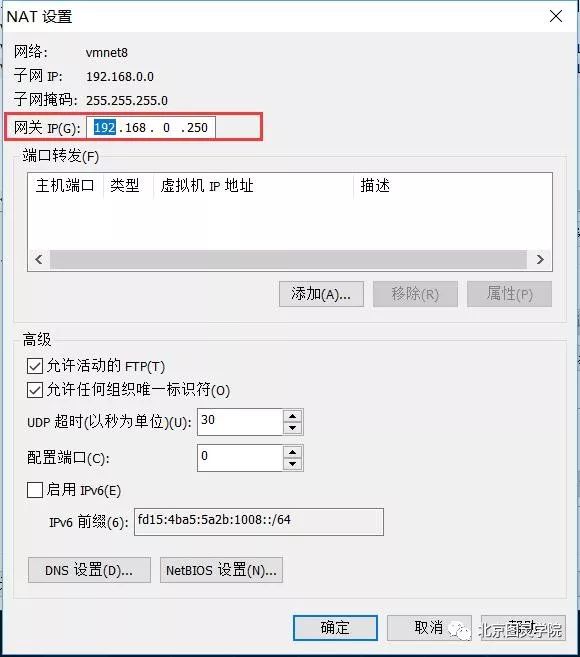
修改完成后,分别在三台主机做如下操作,本人只在master主机下演示,其余主机请自行操作完成:
第一步:修改主机名
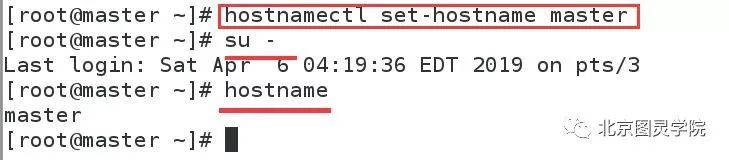
nmcli connection add con-name eno16777728 type ethernet ifname eth0nmcli connection modify eth0 ipv4.address "192.168.0.10/24 192.168.0.250"nmcli connection modify eth0 ipv4.dns 8.8.8.8nmcli connection modify eth0 ipv4.method manualnmcli connection modify eth0 connection.autoconnect yesnmcli connection up eth0
第三步:创建hadoop用户并赋予权限与密码
useradd hadooppasswd hadoopchmod u+w /etc/sudoersvim /etc/sudoers此处进入该文件找到root ALL=(ALL) ALL 这一行并在该行下添加hadoop ALL=(ALL) ALL操作完成后取消sudoers文件w权限chmod u-w /etc/sudoers

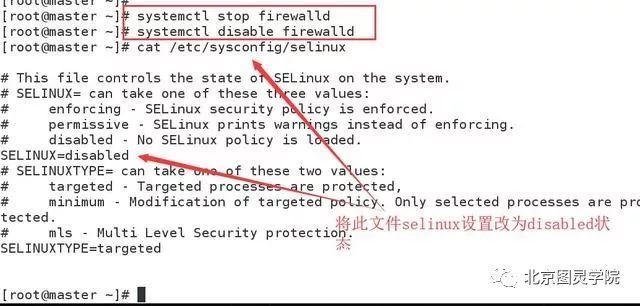
第四步:关闭防火墙,关闭selinux
[root@master ~]# systemctl stop firewalld[root@master ~]# systemctl disable firewalld

第六步:配置yum源为阿里源
wget -O /etc/yum.repos.d/CentOS-Base.repohttp://mirrors.aliyun.com/repo/Centos-7.repo

此处下载完成后需要将文件里面的$releaseserve替换为7, 双击CentOS-Base.repo文件打开后按ctr+h键 查找后全部替换
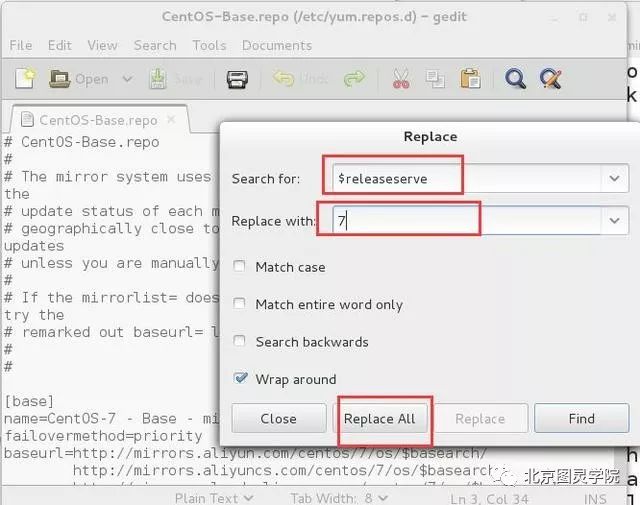
切记保存后退出
然后接下来执行俩条命令如下:
yum clean all #清除yum缓存yum makecache #建立元数据缓存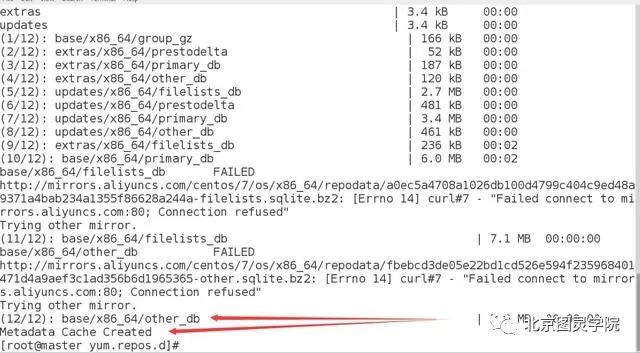
第七步:安装JDK
此处我们直接用yum安装,你也可以将jdk源码下载进行安装,切记记住自己的安装位置,方便下一步配置java环境
#第一步:yum search java寻找java软件版本#第二步:yum install安装自己选择的版本yum search javayum install -y java-1.7.0-openjdk-devel.x86_64
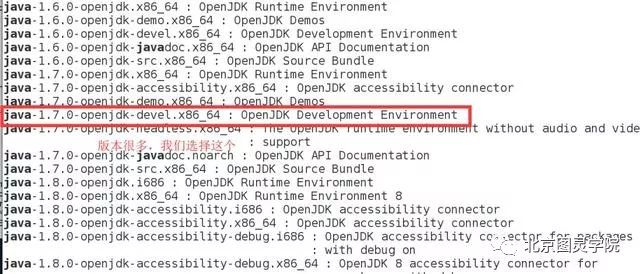
第八步:配置java环境变量
在这步中,因为我们是yum安装的,所以得去找找java在什么地方,执行命令如下:
[root@master ~]# whereisjava[root@master ~]# ll /usr/bin/java[root@master ~]# ll/etc/alternatives/java#此时就可以发现你的JDK路径啦
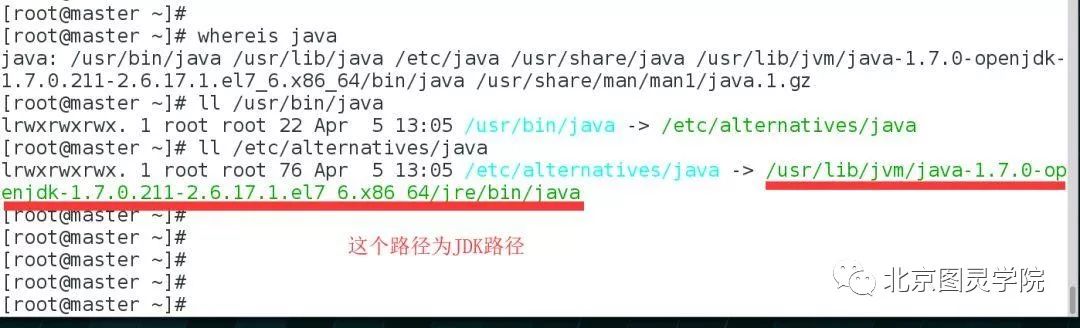
那么接着修改全局环境变量:/etc/profile文件
vim /etc/profile#在该文件中追加如下几行:
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.211-2.6.17.1.el7_6.x86_64export MAVEN_HOME=/home/hadoop/local/opt/apache-maven-3.3.1export JRE_HOME=$JAVA_HOME/jreexport PATH=$JAVA_HOME/bin:$MAVEN_HOME/bin:$PATHexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
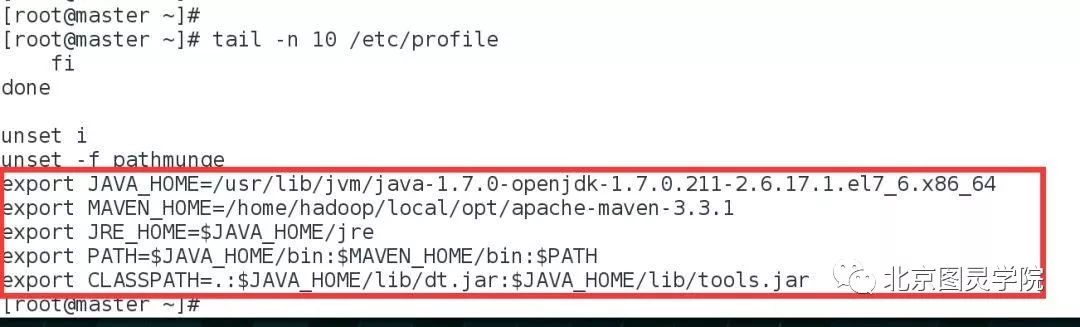
最后让该配置文件立即生效
source /etc/profile第九步:验证java环境变量是否配置成功
分别执行如下命令:javajavacjava -version#如果前俩条命令都出现提示信息,说明配置成功,尤其是javac一般配置错误javac会提示找不到

到这为止,我们的准备工作基本做完成,切记,以上步骤为三台主机都必须执行的过程的。配置完成后建议大家重启我们的系统,并保存快照,你懂得~接下来我们开始我们hadoop集群的具体搭建。
重启系统,并以hadoop用户登陆,谨记,以下操作,若无特殊说明,一律只在master主机进行操作,切记~
第一步:配置ssh免密登陆
造master主机上使用hadoop用户登陆(确保以下操作都为hadoop用户),执行ssh-keygen -t rsa命令:
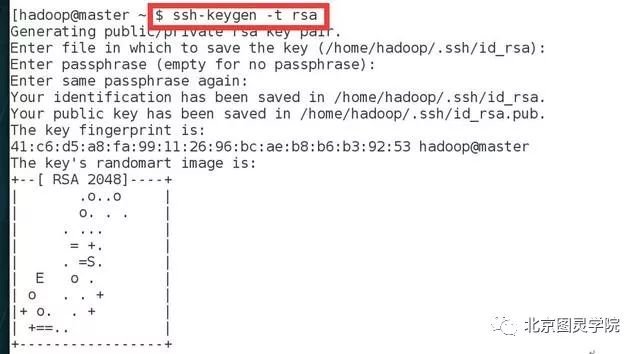
接着将公钥复制到slave_1和slave_2俩台主机
[hadoop@master ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub slave_1#输入hadoop@slave_1的密码[hadoop@master ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub slave_2#输入hadoop@slave_2的密码再次登陆slave_1和slave_2,发现已经不需要密码啦
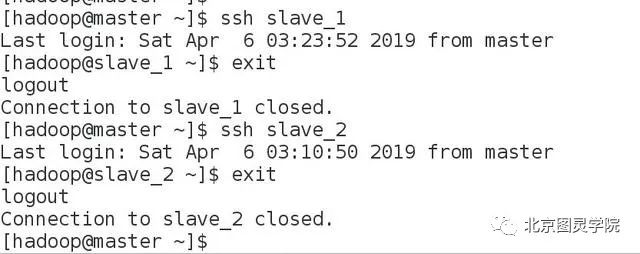
第二步:安装hadoop
首先在hadoop官网下载稳定版本的并且已经编译好的二进制包,并解压
[hadoop@master ~]$ mkdir ~/local/opt #此目录为hadoop解压目录,提前创建好
#接着下载hadoop(该操作建议在用户家目录下)
[hadoop@master ~]$ wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz#然后对该压缩文件进行解压缩
[hadoop@master ~]$ tar -xzvf hadoop-2.6.5.tar.gz -C local/opt/[hadoop@master ~]$ cd local/opt/hadoop-2.6.5/第三步:配置hadoop环境变量(此操作在三台主机都执行)
vim ~/.bash_profile#在该文件内追加如下几行
export HADOOP_HOME=/home/hadoop/local/opt/hadoop-2.6.5export PATH=$HADOOP_HOME/bin:$PATHexport HADOOP_PREFIX=$HOME/local/opt/hadoop-2.6.5export HADOOP_COMMON_HOME=$HADOOP_PREFIXexport HADOOP_HDFS_HOME=$HADOOP_PREFIXexport HADOOP_MAPRED_HOME=$HADOOP_PREFIXexport HADOOP_YARN_HOME=$HADOOP_PREFIXexport HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoopexport PATH=$PATH:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin
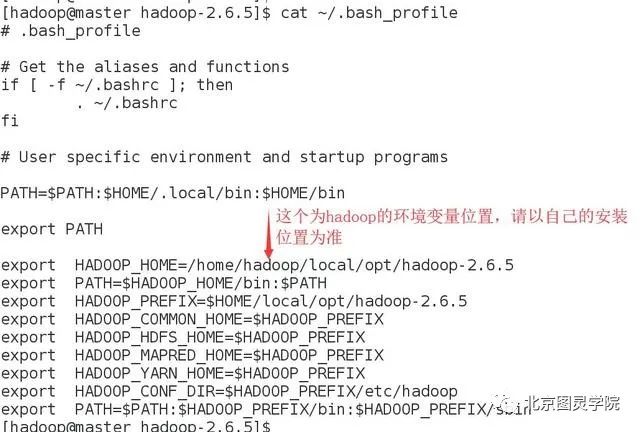
让该文件立即生效,请sourece一下
[hadoop@master hadoop-2.6.5]$ source ~/.bash_profile第四步:修改hadoop配置文件etc/hadoop/hadoop-env.sh
注意此处的etc目录是hadoop目录下的etc目录,千万别搞错~
在该文件中找到export JAVA_HOME=${JAVA_HOME}这一行,将其注释,并将下一行内容加入export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.211-2.6.17.1.el7_6.x86_64#此内容指的是java环境变量,请以自己的为主。


第五步:修改hadoop配置文件etc/hadoop/core-site.xml,内容如下:
[hadoop@master hadoop-2.6.5]$ vim etc/hadoop/core-site.xml<configuration><property><name>fs.defaultFS</name><value>hdfs://master</value></property><property><name>hadoop.tmp.dir</name><value>/home/hadoop/local/var/hadoop/tmp/hadoop-${user.name}</value></property></configuration>
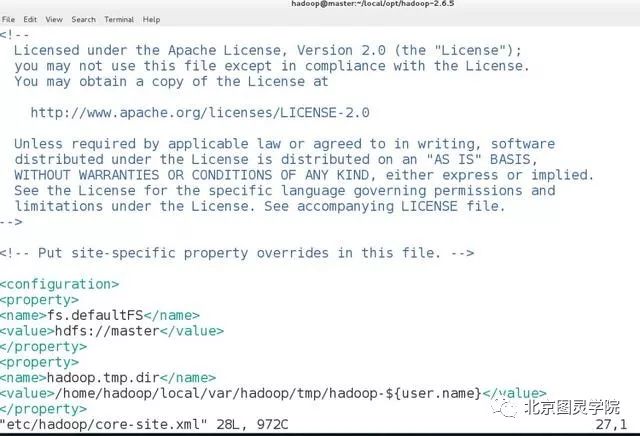
第六步:修改配置文件: etc/hadoop/hdfs-site.xml,内容如下:
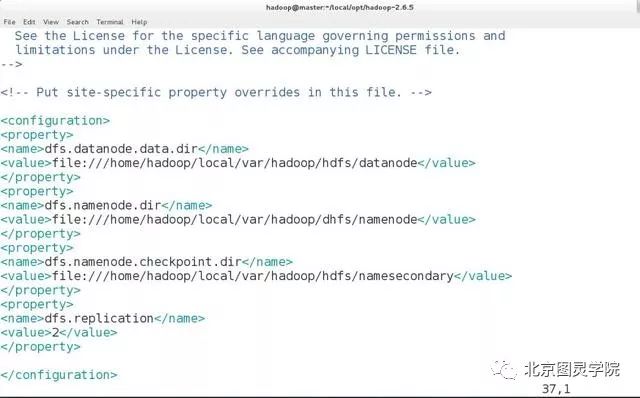
[hadoop@master hadoop-2.6.5]$ vim etc/hadoop/hdfs-site.xml<configuration><property><name>dfs.datanode.data.dir</name><value>file:///home/hadoop/local/var/hadoop/hdfs/datanode</value></property><property><name>dfs.namenode.dir</name><value>file:///home/hadoop/local/var/hadoop/dhfs/namenode</value></property><property><name>dfs.namenode.checkpoint.dir</name><value>file:///home/hadoop/local/var/hadoop/hdfs/namesecondary</value></property><property><name>dfs.replication</name><value>2</value></property></configuration>
第七步:修改配置文件:etc/hadoop/yarn-site.xml,内容如下:
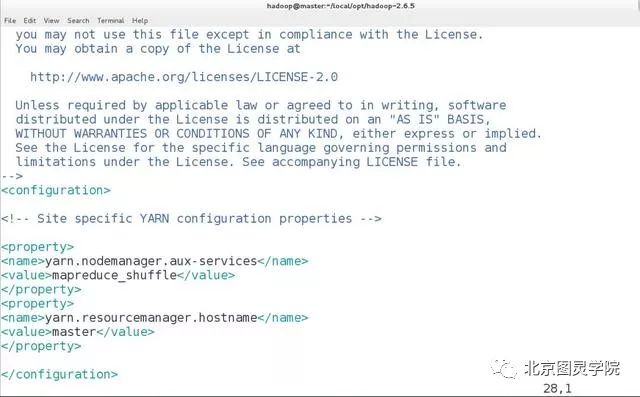
[hadoop@master hadoop-2.6.5]$ vim etc/hadoop/yarn-site.xml<configuration><!-- Site specific YARN configuration properties --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name><value>master</value></property></configuration>
第八步:修改配置文件: etc/hadoop/mapred-site.xml,内容如下:
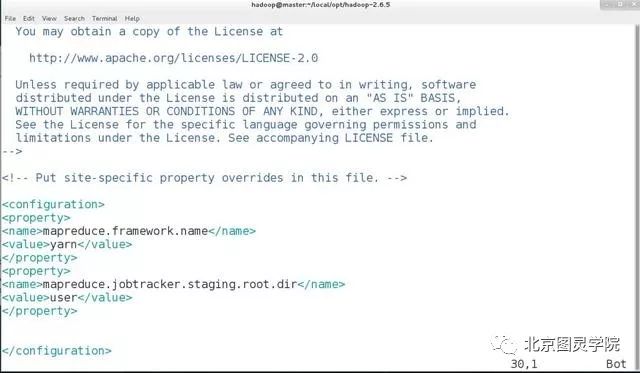
[hadoop@master hadoop-2.6.5]$ cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml[hadoop@master hadoop-2.6.5]$ vim etc/hadoop/mapred-site.xml<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobtracker.staging.root.dir</name><value>user</value></property></configuration>
第九步:将hadoop的配置文件分别拷贝到slave_1和slave_2俩台主机,命令如下:
切记,此处我们在master主机hadoop用户的家目录下拷贝[hadoop@master ~]$ scp -r local/ slave_1:~/[hadoop@master ~]$ scp -r local/ slave_2:~/
第十步:格式化HDFS
[hadoop@master ~]$ hdfs namenode -format
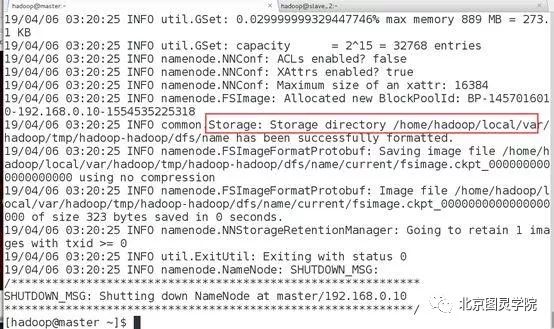
如图状态,说明格式化成功
第十一步:启动hadoop集群
进入到hadoop的sbin目录下,执行如下脚本:
[hadoop@master sbin]$ ./start-all.sh#此过程会让你输入密码
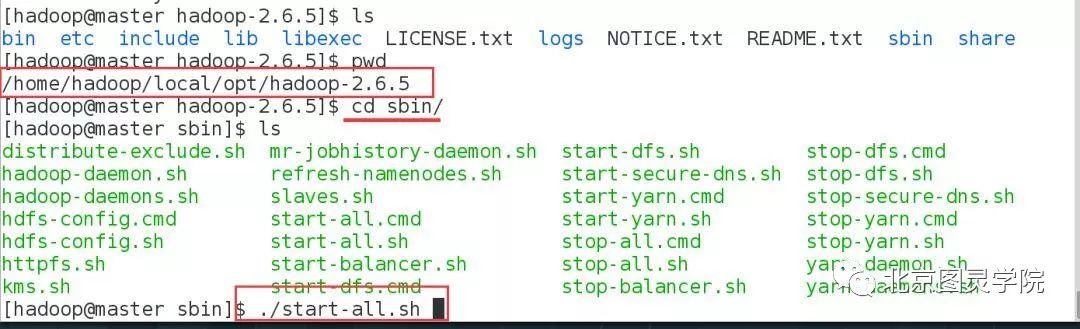
第十二步:验证集群是否启动成功
jps#直接输入java携带的jps命令查看集群节点

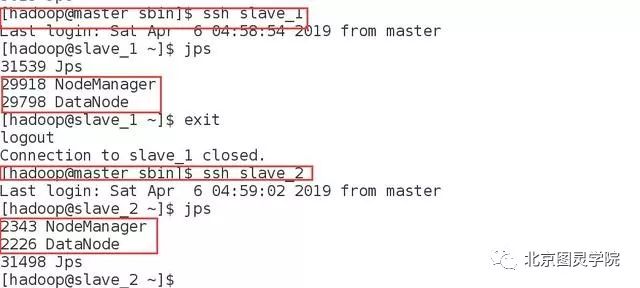
在master主机与俩台slave主机上都看到了节点,说明我们的集群启动正常。哈哈,小小的激动一下,好久没搭建该集群啦~
第十三步:通过WebUI查看集群是否成功启动
在hadoop master端启动firefox浏览器,输入master:50070验证:
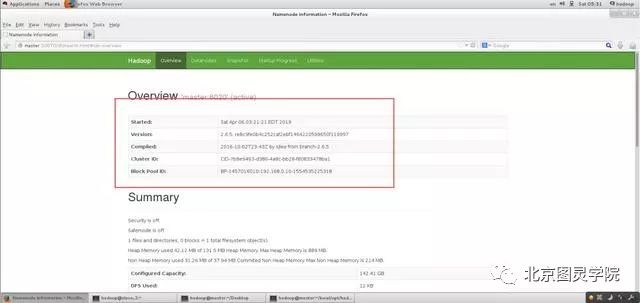
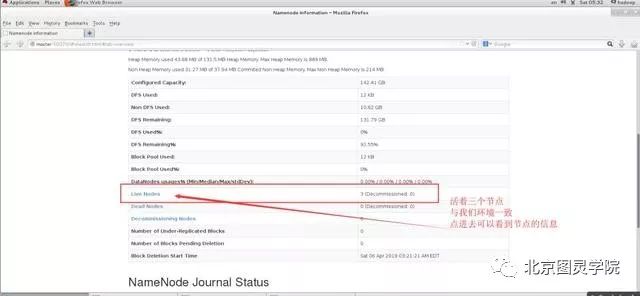
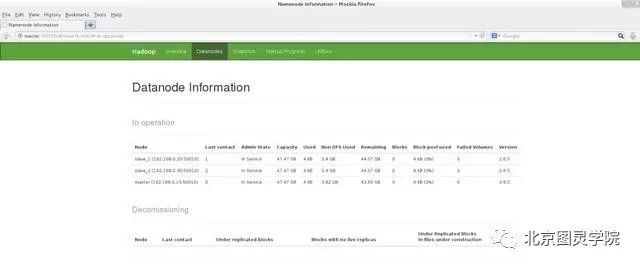
第十四步:通过WebUI验证yarn是否正常
在浏览器中输入http://master:8088进行查看
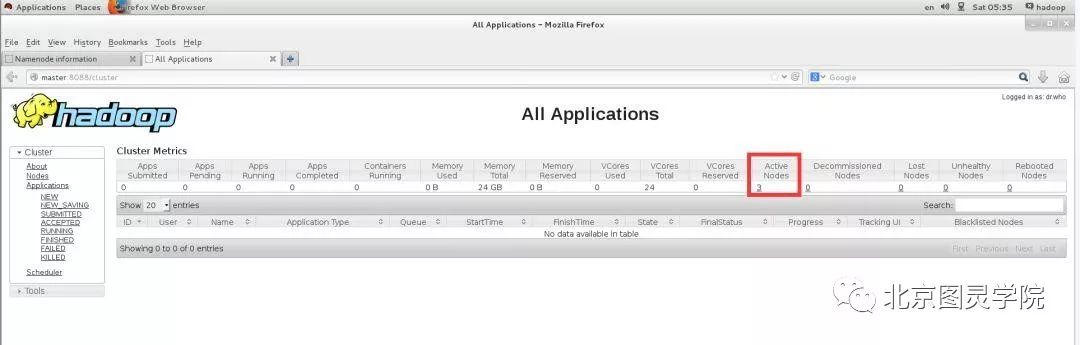
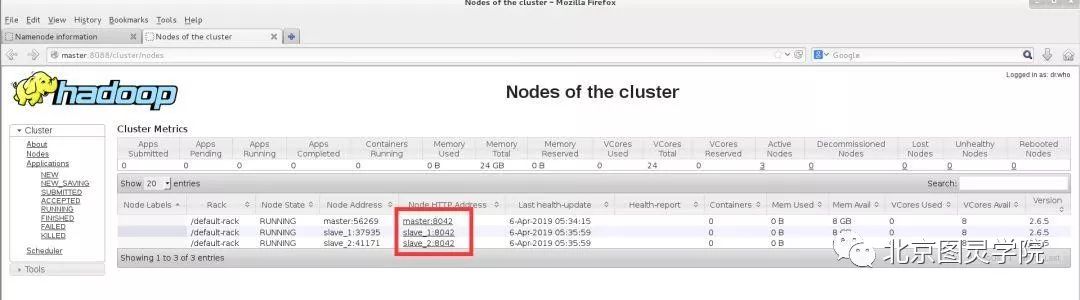
哈哈,说明我们集群一切正常~~~
第十五步:停止集群
#还是在sbin目录下[hadoop@master sbin]$ ./stop-all.sh
请注意观察具体过程~~
嗯,今天的环境搭建就到此结束啦~后续会为大家继续分享hadoop的使用,谢谢大家的支持~~
以上是关于Hadoop集群搭建总结的主要内容,如果未能解决你的问题,请参考以下文章